1.理解硬件
1.1磁盘
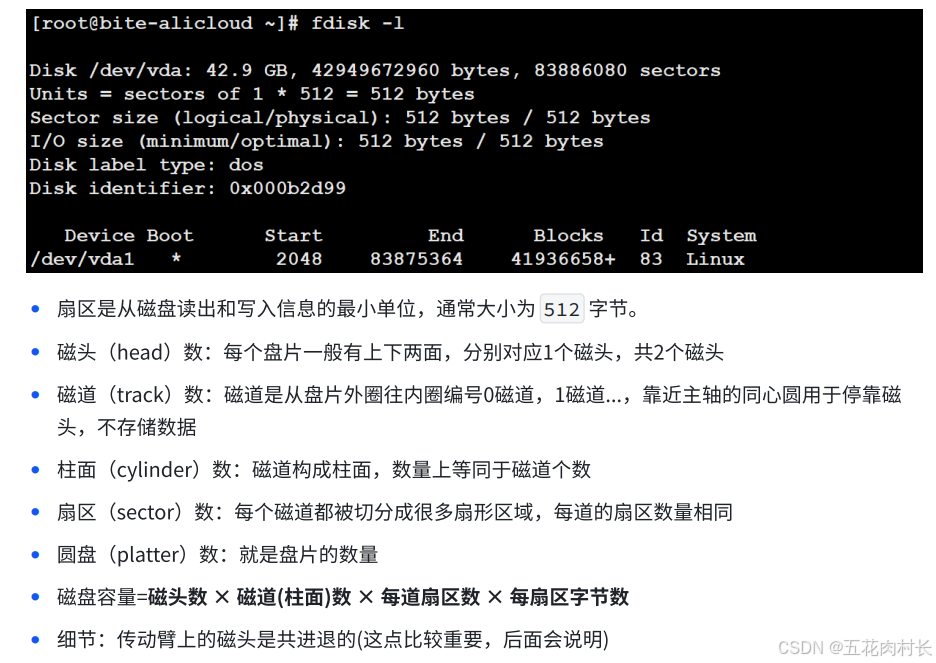
机械磁盘是计算机中唯⼀的⼀个机械设备
磁盘---外设
慢
容量⼤,价格便宜

1.2磁盘的物理结构

1.3磁盘的存储结构
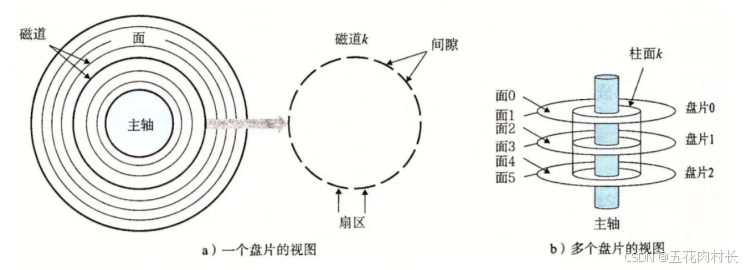
扇区:是磁盘存储数据的基本单位,512字节,块设备
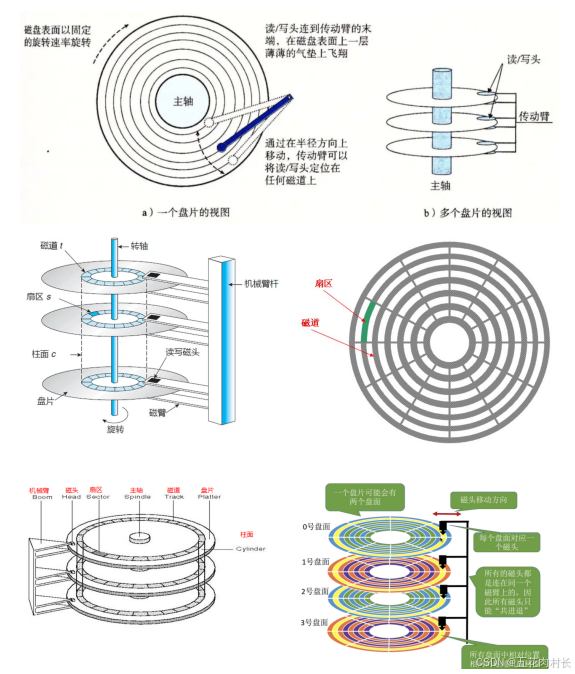
如何定位⼀个扇区呢?
可以先定位磁头(header)
确定磁头要访问哪⼀个柱⾯(磁道)(cylinder)
定位⼀个扇区(sector)
CHS地址定位
⽂件=内容+属性都是数据,⽆⾮就是占据那⼏个扇区的问题!能定位⼀个扇区了,能不能定位多个扇 区呢?

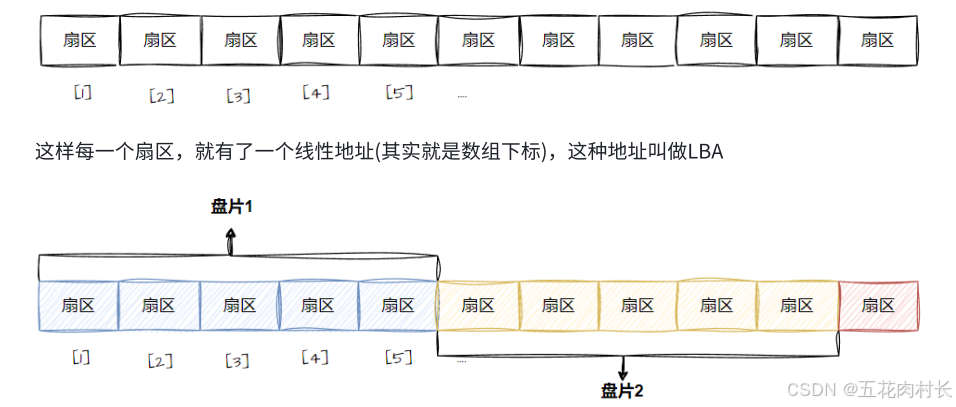
1.4磁盘的逻辑结构
那么磁盘本质上虽然是硬质的,但是逻辑上我们可以把磁盘想象成为卷在⼀起的磁带,那么磁盘的逻 辑存储结构我们也可以类似于:
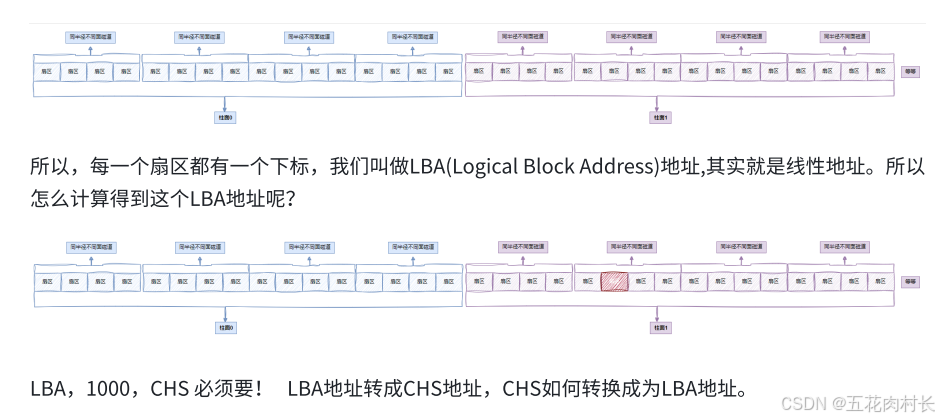
1.5 CHS && LBA地址
CHS转成LBA:
磁头数*每磁道扇区数=单个柱⾯的扇区总数
LBA=柱⾯号C*单个柱⾯的扇区总数+磁头号H*每磁道扇区数+扇区号S-1
即:LBA=柱⾯号C*(磁头数*每磁道扇区数)+磁头号H*每磁道扇区数+扇区号S-1
扇区号通常是从1开始的,⽽在LBA中,地址是从0开始的
柱⾯和磁道都是从0开始编号的
总柱⾯,磁道个数,扇区总数等信息,在磁盘内部会⾃动维护,上层开机的时候,会获取到这些参 数。
LBA转成CHS:
• 柱⾯号C=LBA//(磁头数*每磁道扇区数)【就是单个柱⾯的扇区总数】
• 磁头号H=(LBA%(磁头数*每磁道扇区数))//每磁道扇区数
• 扇区号S=(LBA%每磁道扇区数)+1
• "//":表⽰除取整
所以:从此往后,在磁盘使⽤者看来,根本就不关⼼CHS地址,⽽是直接使⽤LBA地址,磁盘内部⾃⼰ 转换。所以: 从现在开始,磁盘就是⼀个元素为扇区的⼀维数组,数组的下标就是每⼀个扇区的LBA地址。OS使⽤ 磁盘,就可以⽤⼀个数字访问磁盘扇区了。
2.引入文件系统
2.1块的概念
其实硬盘是典型的"块"设备,操作系统读取硬盘数据的时候,其实是不会⼀个个扇区地读取,这样 效率太低,⽽是⼀次性连续读取多个扇区,即⼀次性读取⼀个"块"(block)。
硬盘的每个分区是被划分为⼀个个的"块"。⼀个"块"的⼤⼩是由格式化的时候确定的,并且不可 以更改,最常⻅的是4KB,即连续⼋个扇区组成⼀个"块"。"块"是⽂件存取的最⼩单位。
磁盘就是⼀个三维数组,我们把它看待成为⼀个"⼀维数组",数组下标就是LBA,每个元素都是扇 区。每个扇区都有LBA,那么8个扇区⼀个块,每⼀个块的地址我们也能算出来。
知道LBA:块号=LBA/8
知道块号:LAB=块号*8+n.(n是块内第⼏个扇区)
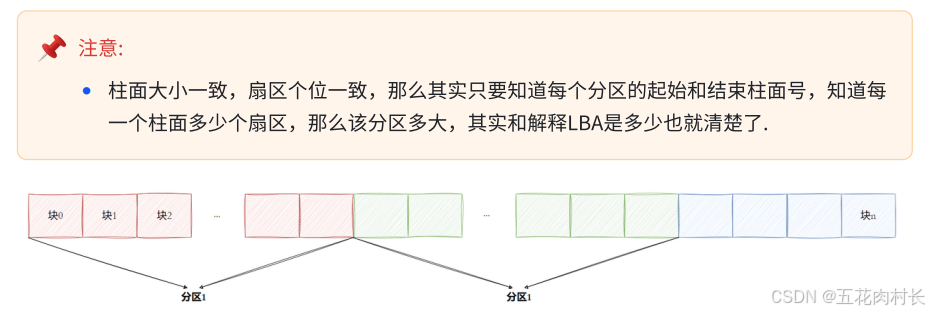
2.2分区的概念
其实磁盘是可以被分成多个分区(partition)的,以Windows观点来看,你可能会有⼀块磁盘并且将 它分区成C,D,E盘。那个C,D,E就是分区。分区从实质上说就是对硬盘的⼀种格式化。但是Linux的设备 都是以⽂件形式存在,那是怎么分区的呢?
柱⾯是分区的最⼩单位,我们可以利⽤参考柱⾯号码的⽅式来进⾏分区,其本质就是设置每个区的起 始柱⾯和结束柱⾯号码。此时我们可以将硬盘上的柱⾯(分区)进⾏平铺,将其想象成⼀个⼤的平 ⾯,如下图所⽰:
2.3 inode概念
之前我们说过 ⽂件=数据+属性 ,我们使⽤ ls -l 的时候看到的除了看到⽂件名,还能看到⽂件元 数据(属性)。
到这我们要思考⼀个问题,⽂件数据都储存在"块"中,那么很显然,我们还必须找到⼀个地⽅储存 ⽂件的元信息(属性信息),⽐如⽂件的创建者、⽂件的创建⽇期、⽂件的⼤⼩等等。这种储存⽂件 元信息的区域就叫做inode,中⽂译名为"索引节点"。
每⼀个⽂件都有对应的inode,⾥⾯包含了与该⽂件有关的⼀些信息。为了能解释清楚inode,我们需 要是深⼊了解⼀下⽂件系统。

⽂件名属性并未纳⼊到inode数据结构内部
inode的⼤⼩⼀般是128字节或者256,我们后⾯统⼀128字节
任何⽂件的内容⼤⼩可以不同,但是属性⼤⼩⼀定是相同的
3.ext2文件系统
3.1宏观认识
所有的准备⼯作都已经做完,是时候认识下⽂件系统了。我们想要在硬盘上储⽂件,必须先把硬盘格 式化为某种格式的⽂件系统,才能存储⽂件。⽂件系统的⽬的就是组织和管理硬盘中的⽂件。在Linux系统中,最常⻅的是ext2系列的⽂件系统。其早期版本为ext2,后来⼜发展出ext3和ext4。 ext3和ext4虽然对ext2进⾏了增强,但是其核⼼设计并没有发⽣变化,我们仍是以较⽼的ext2作为 演⽰对象。
ext2⽂件系统将整个分区划分成若⼲个同样⼤⼩的块组(Block Group),如下图所⽰。只要能管理⼀个 分区就能管理所有分区,也就能管理所有磁盘⽂件。
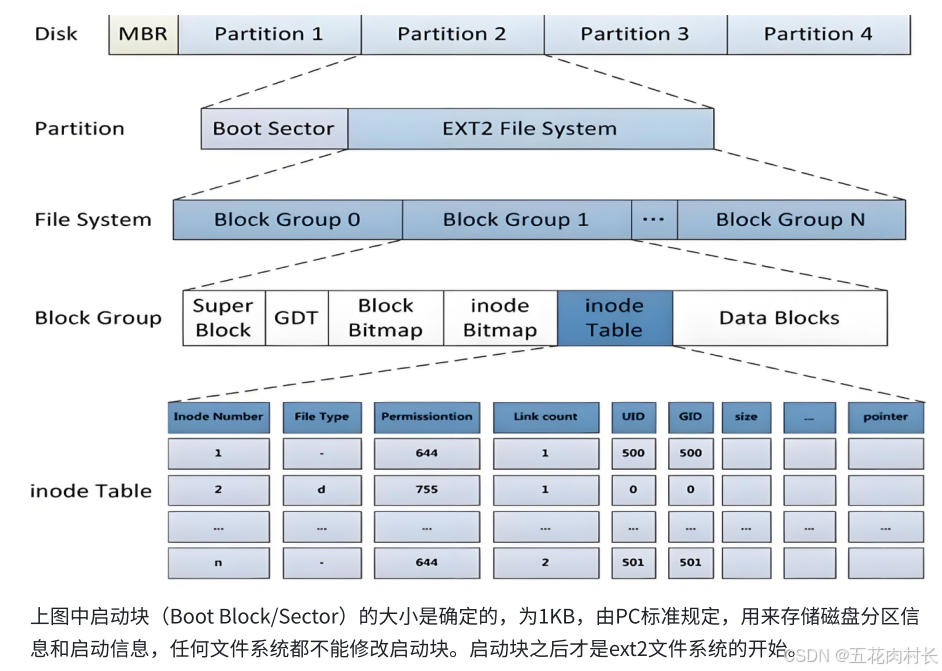
3.2 Block Group
ext2⽂件系统会根据分区的⼤⼩划分为数个Block Group。⽽每个Block Group都有着相同的结构组 成。
3.3块组内部构成
3.3.1超级快(Super Block)
存放⽂件系统本⾝的结构信息,描述整个分区的⽂件系统信息。记录的信息主要有:bolck和inode的 总量,未使⽤的block和inode的数量,⼀个block和inode的⼤⼩,最近⼀次挂载的时间,最近⼀次写 ⼊数据的时间,最近⼀次检验磁盘的时间等其他⽂件系统的相关信息。Super Block的信息被破坏,可 以说整个⽂件系统结构就被破坏了
3.3.2GDT(Group Descriptor Table)
块组描述符表,描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描 述符存储⼀个块组的描述信息,如在这个块组中从哪⾥开始是inodeTable,从哪⾥开始是Data Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有⼀份拷⻉。
3.3.3块位图(Block Bitmap)
BlockBitmap中记录着Data Block中哪个数据块已经被占⽤,哪个数据块没有被占⽤
3.3.4inode位图(Inode Bitmap)
每个bit表⽰⼀个inode是否空闲可⽤。
3.3.5 i节点表(Inode Table)
存放⽂件属性如⽂件⼤⼩,所有者,最近修改时间等
当前分组所有Inode属性的集合
inode编号以分区为单位,整体划分,不可跨分区
3.3.6Data Block
数据区:存放⽂件内容,也就是⼀个⼀个的Block。根据不同的⽂件类型有以下⼏种情况:
对于普通⽂件,⽂件的数据存储在数据块中.
对于⽬录,该⽬录下的所有⽂件名和⽬录名存储在所在⽬录的数据块中,除了⽂件名外,ls-l命令 看到的其它信息保存在该⽂件的inode中。
Block号按照分区划分,不可跨分区
3.4目录与文件名
问题:
我们访问⽂件,都是⽤的⽂件名,没⽤过inode号啊?
⽬录是⽂件吗?如何理解
答案:
⽬录也是⽂件,但是磁盘上没有⽬录的概念,只有⽂件属性+⽂件内容的概念。
⽬录的属性不⽤多说,内容保存的是:⽂件名和Inode号的映射关系
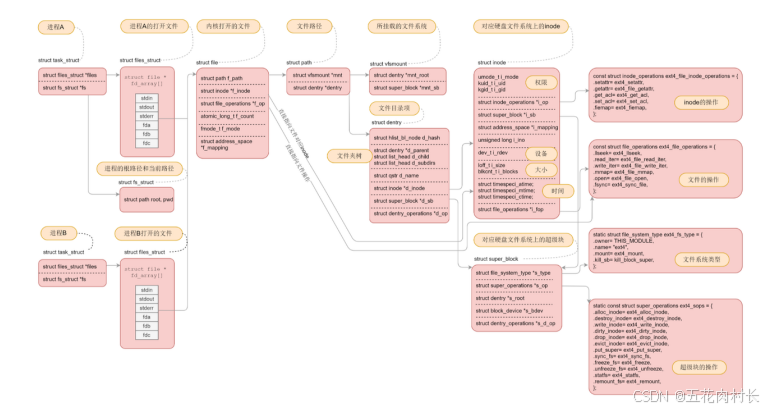
所以,访问⽂件,必须打开当前⽬录,根据⽂件名,获得对应的inode号,然后进⾏⽂件访问
所以,访问⽂件必须要知道当前⼯作⽬录,本质是必须能打开当前⼯作⽬录⽂件,查看⽬录⽂件的 内容!
3.5路径解析
问题:打开当前⼯作⽬录⽂件,查看当前⼯作⽬录⽂件的内容?当前⼯作⽬录不也是⽂件吗?我们访问 当前⼯作⽬录不也是只知道当前⼯作⽬录的⽂件名吗?要访问它,不也得知道当前⼯作⽬录的inode 吗?
答案1:所以也要打开:当前⼯作⽬录的上级⽬录,额....,上级⽬录不也是⽬录吗??不还是上⾯的问 题吗?
答案2:所以类似"递归",需要把路径中所有的⽬录全部解析,出⼝是"/"根⽬录。 最终答案3:⽽实际上,任何⽂件,都有路径,访问⽬标⽂件,⽐如:
/home/whb/code/test/test/test.c
都要从根⽬录开始,依次打开每⼀个⽬录,根据⽬录名,依次访问每个⽬录下指定的⽬录,直到访问 到test.c。这个过程叫做Linux路径解析。
所以,我们知道了:访问⽂件必须要有⽬录+⽂件名=路径的原因
根⽬录固定⽂件名,inode号,⽆需查找,系统开机之后就必须知道
可是路径谁提供?
你访问⽂件,都是指令/⼯具访问,本质是进程访问,进程有CWD!进程提供路径。
你open⽂件,提供了路径
可是最开始的路径从哪⾥来?
所以Linux为什么要有根⽬录,根⽬录下为什么要有那么多缺省⽬录?
你为什么要有家⽬录,你⾃⼰可以新建⽬录?
上⾯所有⾏为:本质就是在磁盘⽂件系统中,新建⽬录⽂件。⽽你新建的任何⽂件,都在你或者系 统指定的⽬录下新建,这不就是天然就有路径了嘛!
系统+⽤⼾共同构建Linux路径结构.
3.6路径缓存
问题1:Linux磁盘中,存在真正的⽬录吗?
答案:不存在,只有⽂件。只保存⽂件属性+⽂件内容
问题2:访问任何⽂件,都要从/⽬录开始进⾏路径解析?
答案:原则上是,但是这样太慢,所以Linux会缓存历史路径结构
问题2:Linux⽬录的概念,怎么产⽣的?
答案:打开的⽂件是⽬录的话,由OS⾃⼰在内存中进⾏路径维护
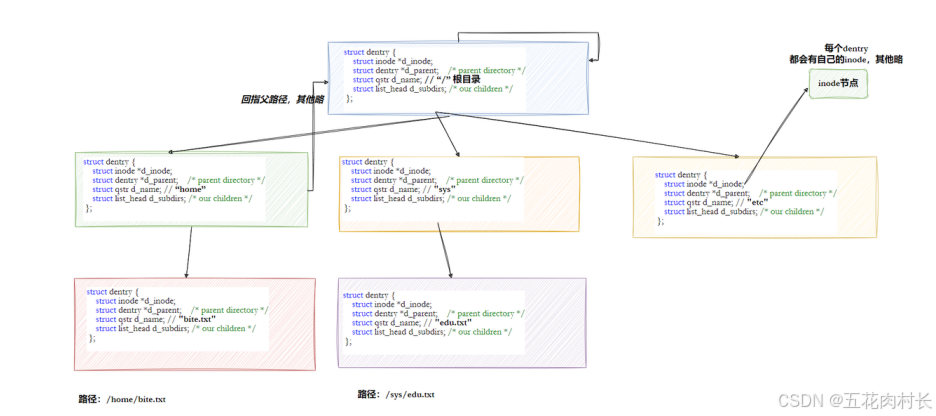
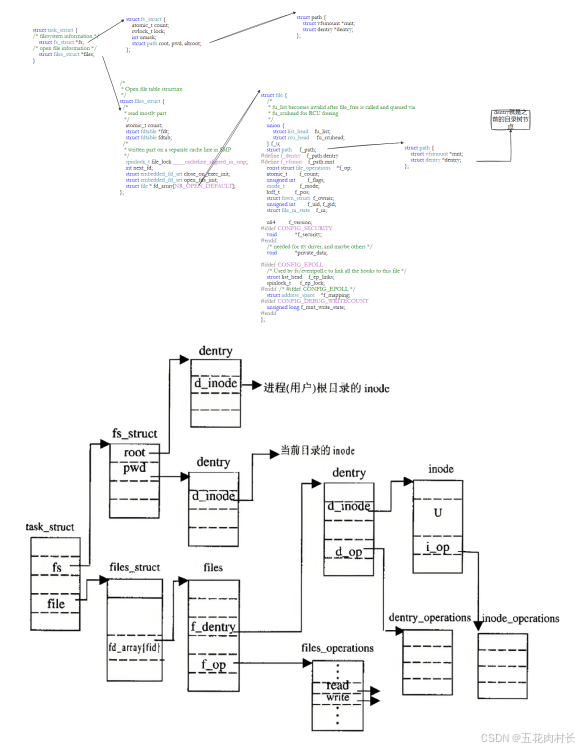
Linux中,在内核中维护树状路径结构的内核结构体叫做: struct dentry
注意:
1.每个⽂件其实都要有对应的dentry结构,包括普通⽂件。这样所有被打开的⽂件,就可以在内存中 形成整个树形结构
2.整个树形节点也同时会⾪属于LRU(Least Recently Used,最近最少使⽤)结构中,进⾏节点淘汰
3.整个树形节点也同时会⾪属于Hash,⽅便快速查找
4.更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何⽂件,都在先在这 棵树下根据路径进⾏查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry 结构,缓存新路径
3.7挂载分区
分区写⼊⽂件系统,⽆法直接使⽤,需要和指定的⽬录关联,进⾏挂载才能使⽤。
所以,可以根据访问⽬标⽂件的"路径前缀"准确判断我在哪⼀个分区。
3.8文件系统总结
4.软硬链接
4.1硬链接
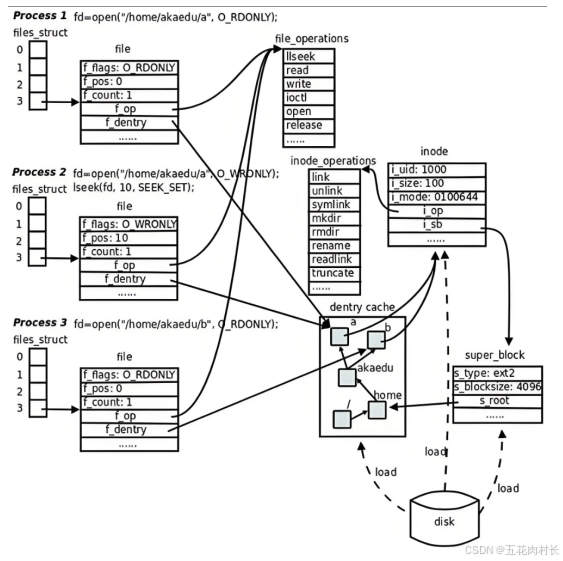
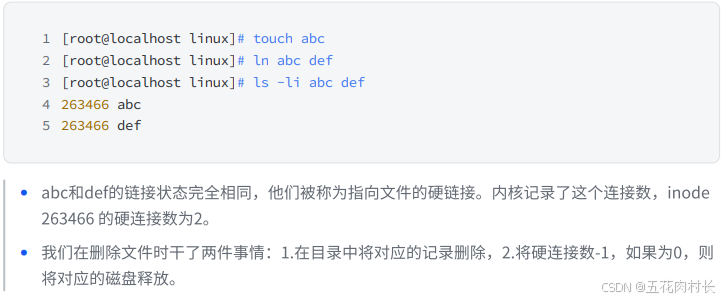
我们看到,真正找到磁盘上⽂件的并不是⽂件名,⽽是inode。其实在linux中可以让多个⽂件名对应 于同⼀个inode。
4.2软连接
硬链接是通过inode引⽤另外⼀个⽂件,软链接是通过名字引⽤另外⼀个⽂件,但实际上,新的⽂件和 被引⽤的⽂件的inode不同,应⽤常⻅上可以想象成⼀个快捷⽅式。在shell中的做法
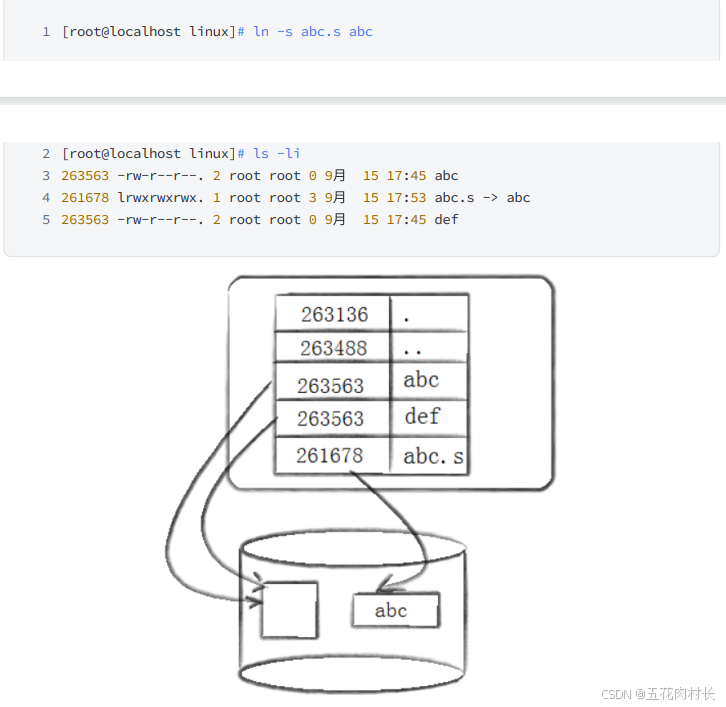
acm:
下⾯解释⼀下⽂件的三个时间:
Access 最后访问时间
Modify ⽂件内容最后修改时间
Change 属性最后修改时间
4.3软硬链接对比
软连接是独⽴⽂件
硬链接只是⽂件名和⽬标⽂件inode的映射关系
4.4软硬链接的用途
硬链接:
.和.. 就是硬链接
⽂件备份
软连接:
类似快捷⽅式