1. 核心调度组件
-
DAGScheduler:负责将Job拆分为Stage,处理Stage间的依赖关系。
-
TaskScheduler:将Task分配到Executor,监控任务执行。
-
SchedulerBackend:与集群管理器(如YARN、K8s)通信,管理Executor资源。
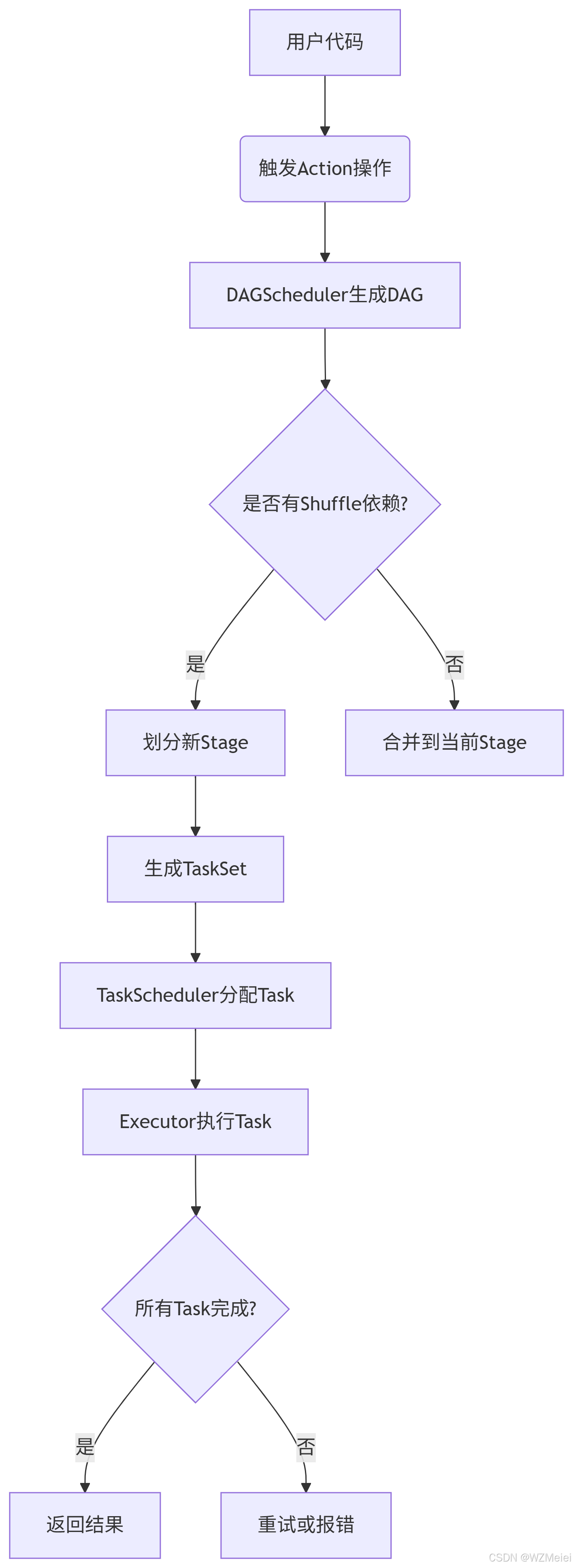
2. 调度流程分步拆解
步骤1:用户提交代码
Scala
val rdd = sc.textFile("hdfs://data.txt")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
rdd.collect() // 触发Job提交步骤2:生成DAG(有向无环图)
-
RDD血缘(Lineage) :记录RDD的转换过程(
textFile→flatMap→map→reduceByKey)。 -
宽依赖(Shuffle) :
reduceByKey导致Stage划分。
步骤3:划分Stage
-
Stage 0 :
textFile→flatMap→map(窄依赖,合并为一个Stage)。 -
Stage 1 :
reduceByKey(宽依赖,单独一个Stage)。
步骤4:提交Task
-
Stage 0 生成多个
MapTask,Stage 1 生成多个ReduceTask。 -
TaskScheduler根据数据本地性(Data Locality)分配Task到Executor。
步骤5:执行与监控
-
Executor执行Task,向Driver汇报状态。
-
失败Task自动重试(默认重试3次)。
3. 关键概念详解
| 概念 | 说明 | 示例 |
|---|---|---|
| Job | 由行动操作(如collect)触发的完整计算任务 |
一次collect()生成一个Job |
| Stage | 由一组无Shuffle依赖的Task组成(分为ResultStage和ShuffleMapStage) |
reduceByKey前为一个Stage |
| Task | Stage中每个分区的计算单元(ShuffleMapTask或ResultTask) |
处理一个分区的数据 |
| Shuffle | 跨Stage数据重分布(如groupByKey、join) |
reduceByKey触发Shuffle |
| 数据本地性 | 优先将Task调度到数据所在节点(PROCESS_LOCAL > NODE_LOCAL > ANY) |
读取HDFS块时优先分配到数据所在节点 |
4. 调度流程示意图
5. 性能优化点
-
减少Shuffle:
-
用
reduceByKey替代groupByKey(提前局部聚合)。 -
使用
Broadcast Join代替Shuffle Join。
-
-
调整并行度:
- 通过
spark.default.parallelism或repartition()控制分区数。
- 通过
-
数据本地性:
- 确保输入数据与Executor在同一节点(如HDFS副本策略)。
-
资源分配:
- 合理设置Executor内存(
spark.executor.memory)和CPU核心数(spark.executor.cores)。
- 合理设置Executor内存(
6. 容错机制
-
Stage重试:若某个Stage失败,重新提交该Stage的所有Task。
-
Task重试:单个Task失败后,TaskScheduler会重新调度(默认最多3次)。
-
血缘恢复:若Executor丢失数据,根据RDD血缘重新计算。
总结
Spark的调度机制通过DAG优化、本地性优先和容错设计,实现了高效的大数据处理。理解其原理后,可通过调整分区策略、优化Shuffle操作等手段显著提升性能。