【深度学习|学习笔记】 Generalized additive model广义可加模型(GAM)详解,附代码
【深度学习|学习笔记】 Generalized additive model广义可加模型(GAM)详解,附代码
文章目录
- [【深度学习|学习笔记】 Generalized additive model广义可加模型(GAM)详解,附代码](#【深度学习|学习笔记】 Generalized additive model广义可加模型(GAM)详解,附代码)
- 前言
-
- [1 起源与发展](#1 起源与发展)
- [2 模型原理](#2 模型原理)
- [3 应用领域](#3 应用领域)
- [4 Python 实现示例](#4 Python 实现示例)
-
- [4.1 使用 pyGAM](#4.1 使用 pyGAM)
- [4.2 使用 statsmodels.gam](#4.2 使用 statsmodels.gam)
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX "
学术会议小灵通"或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/146957966
前言
下面先给出对 GAM(Generalized Additive Model)关键要点的综合概述,然后依次从起源与发展、模型原理、应用领域,以及 Python 实现四个方面详细展开。
- 广义可加模型(GAM)由 Hastie 和 Tibshirani 于 1990 年提出,是对广义线性模型(GLM)的非参数扩展 ,通过对每个自变量施加未知平滑函数来捕捉非线性关系,同时保持模型的可解释性。
- 随着平滑样条、惩罚参数选择(GCV/REML)和背拟合算法的发展,GAM 在生态学、医学、金融、风险管理等领域得到广泛应用。
- 在 Python 中,可通过
pyGAM、statsmodels.gam等库方便地构建和调优 GAM,实现可视化与预测。
1 起源与发展
- 1990 年,Trevor Hastie 与 Robert Tibshirani 在其同名专著中首次系统提出 GAM,将 GLM 与加性模型融合,允许对每个协变量估计未知的平滑函数,从而兼顾灵活性与可解释性。
- 在此之前,20 世纪50年代的 Kolmogorov--Arnold 表示定理就已证明任意连续函数可分解为单变量函数之和与复合,但其构造函数过于复杂,不适用于统计建模 ;GAM 则通过简化假设和背拟合算法给出了可行的构造方案。
- 2005 年,Rigby 和 Stasinopoulos 在 GAMLSS 框架中将 GAM 扩展到位置--尺度--形状建模,允许响应分布的多参数(均值、方差、偏度、峰度)均由加性平滑函数表示。
- 2015 年,Yee 和 Mackenzie 推出向量化 GAM(VGAM),进一步推广至多元响应与向量协变量情形。
- 2016 年,Wood 等人研究了多重二次惩罚下的平滑参数估计与模型选择,为大型 GAM 的稳定高效拟合奠定了理论基础。
2 模型原理
GAM 通过对响应变量 Y Y Y 指定指数族分布及连接函数 g g g,将其条件期望线性地表示为若干未知平滑函数之和:
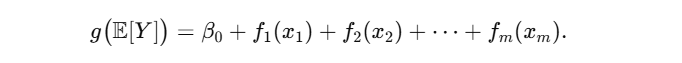
其中每个 f i f_i fi 可用样条(B-splines、自然样条)、局部加权回归等方法非参数估计。
- 为了估计这些平滑函数,GAM 引入背拟合算法(backfitting),在固定其它函数的情况下交替更新每个 f i f_i fi ,直到收敛。
- 平滑函数的复杂度由惩罚项控制,常用的平滑参数选择方法包括广义交叉验证(GCV)和限制最小二乘(REML),以防止过拟合。
- 在理论上,GAM 可被看作对 GLM 的半参数推广,既保留了线性可加的可解释性,又通过平滑函数获得对非线性关系的建模能力。
3 应用领域
- 生态学与物种分布:利用 GAM 考察环境因子对鱼类、浮游生物等分布的平滑影响,如对日本鳀鱼分布的渔业调查分析。
- 统计生态学:在物种分布模型(SDM)中嵌入空间平滑项,评估栖息地特征与物种多样性的非线性关系。
- 医疗与公共卫生:用 GAM 探索酒精消费量与炎症标志物(如 IL-6)间的复杂关联,避免简单线性假设导致的信息损失。
- 金融与风险管理:在信贷评分、保险理赔率等场景下,用平滑函数捕捉年龄、体重等变量对风险的非线性效应,提高预测精度与可解释性。
- 时间序列与动态预测:动态 GAM(DGAM)结合潜在时间过程与平滑项,用于生态和经济时间序列的长短期预测。
- 互联网与搜索引擎:微软 Bing 采用基于 GAM 的可解释排序模型,实现了可解释性与性能的平衡。
4 Python 实现示例
4.1 使用 pyGAM
csharp
pip install pygam # 安装 pyGAM​:contentReference[oaicite:18]{index=18}
csharp
import numpy as np
from pygam import LinearGAM, s
# 构造示例数据
np.random.seed(0)
X = np.random.rand(200, 1) * 10
y = np.sin(X).ravel() + np.random.normal(0, 0.3, 200)
# 定义并训练 GAM:对第 0 号特征使用平滑样条
gam = LinearGAM(s(0, n_splines=20)).fit(X, y) # 拟合模型​:contentReference[oaicite:19]{index=19}
# 模型总结
print(gam.summary())
# 预测与可视化
import matplotlib.pyplot as plt
XX = np.linspace(0, 10, 500).reshape(-1,1)
YY = gam.predict(XX)
plt.scatter(X, y, alpha=0.3)
plt.plot(XX, YY, linewidth=2)
plt.xlabel("X"); plt.ylabel("y"); plt.title("GAM 拟合结果")
plt.show()LinearGAM(s(0))定义了对第一个特征的平滑项;.fit与.predictAPI 与 scikit-learn 类似。
4.2 使用 statsmodels.gam
csharp
import statsmodels.api as sm
from statsmodels.gam.api import GLMGam, BSplines
# 载入 UCI 汽车数据示例
from statsmodels.gam.datasets import df_autos
data = df_autos[['city_mpg','weight','hp']]
# 构造样条基
bs = BSplines(data[['weight','hp']], df=[10,10], degree=[3,3])
# 定义并拟合模型
gam = GLMGam.from_formula('city_mpg ~ 1', data=data, smoother=bs)
res = gam.fit()
print(res.summary()) # 查看系数与光滑项统计​:contentReference[oaicite:21]{index=21}
# 预测
pred = res.predict(exog=data[['weight','hp']])GLMGam支持 Gaussian、Poisson 等分布;BSplines定义每个协变量的样条基与自由度。
通过上述起源、原理、应用与代码演示,您可以在实际项目中灵活运用 GAM 进行非线性建模与解释,为科研与工程提供兼具精度与透明度的解决方案。