1st author: Ryutaro Tanno
video: Video from London ML meetup
paper: Adaptive Neural Trees ICML 2019
code: rtanno21609/AdaptiveNeuralTrees: Adaptive Neural Trees
背景
在机器学习领域,神经网络(NNs)凭借其强大的表示学习能力,在诸多应用中取得了显著成果,然而其"黑箱"特性和预设架构的局限性也常为人诟病。与之相对,决策树(DTs)以其良好的可解释性、自适应结构和轻量级推理等优势受到青睐,但在特征工程和决策函数简单性方面存在不足。
本文旨在深入解析 2019 年国际机器学习大会 (ICML) 论文《自适应神经树 (Adaptive Neural Trees, ANTs)》,该研究提出了一种创新性的方法,旨在融合这两类模型的优点。ANTs 将神经网络的表示学习能力深度融入决策树的结构中,体现在以下几个方面:
- 边的特征转换: 数据在树的路径上传递过程中,通过神经网络进行特征转换。
- 内部节点的路由函数: 神经网络学习如何将数据路由到合适的子节点。
- 叶子节点的最终预测: 神经网络负责进行最终的预测。
ANTs 引入了一种基于反向传播的自适应架构生长算法。这意味着树的结构并非预先设定,而是能够根据数据的特性进行动态生长和调整。
这种融合模式带来的优势显而易见:
- 表示学习的深度渗透: 神经网络在边缘和路由函数中的应用,使得数据在树的层层传递中,其表示(representation)得以不断优化和深化。与传统决策树在原始特征空间进行划分不同,ANTs 在学习到的特征空间上进行划分,显著提升了模型的表达能力。
- 架构的自适应性: 这是 ANTs 的核心优势。传统的神经网络架构固定,需要人工设计和调参;决策树虽然结构自适应,但其"硬划分"的贪婪性质可能导致局部最优。ANTs 的生长算法结合了决策树的局部决策和神经网络的端到端优化,使得模型能够根据数据的规模和复杂性动态调整其深度和宽度,避免在小数据集上过度参数化,同时在大数据集上充分挖掘深层结构。
- 轻量级推理(条件计算): 类似于决策树,ANTs 在推理时仅激活从根节点到叶子节点路径上的少量参数。与需要激活所有参数的传统全连接神经网络相比,这在资源受限的场景下具有显著优势。
ANTs 的核心机制
模型组件
ANTs 的核心抽象是一个二元组 ( T , O ) (T, O) (T,O),其中 T T T 定义了模型的拓扑结构(一棵二叉树),而 O O O 则是一组作用于这棵树上的可微分操作。
-
拓扑结构 T = ( N , E ) T = (\mathcal{N}, \mathcal{E}) T=(N,E):
- N \mathcal{N} N: 所有节点的集合,分为内部节点 N i n t \mathcal{N}{int} Nint 和叶子节点 N l e a f \mathcal{N}{leaf} Nleaf。
- E \mathcal{E} E: 边的集合。特别地,每条边上承载着对数据进行变换的"生产线"。
- 每个内部节点 j ∈ N i n t j \in \mathcal{N}_{int} j∈Nint 有两个子节点 l e f t ( j ) left(j) left(j) 和 r i g h t ( j ) right(j) right(j)。
-
核心操作 O = ( R , T , S ) O = (\mathcal{R}, \mathcal{T}, \mathcal{S}) O=(R,T,S): 这是 ANTs 最特别的设计,它突破了传统决策树的简化模式,将神经网络的能力注入到树的每一个关键环节。
-
路由函数 r j θ ∈ R r_j^\theta \in \mathcal{R} rjθ∈R : 每个内部节点 j ∈ N i n t j \in \mathcal{N}_{int} j∈Nint 都配备一个路由器。图 Figure 1 中白色节点。
- 功能 : 接收来自父节点的特征表示 x j ∈ X j x_j \in \mathcal{X}_j xj∈Xj,输出一个 0 , 1 0, 1 0,1 范围内的标量,表示样本流向左子节点的概率。
- 参数 : 由 θ \theta θ 参数化。
- 决策方式 : 采用随机路由(Stochastic Routing) ,即决策是根据伯努利分布 B e r n o u l l i ( r j θ ( x j ) ) Bernoulli(r_j^\theta(x_j)) Bernoulli(rjθ(xj)) 采样得出(1 去左,0 去右)。这保证了路由函数是可微分的,允许梯度流过。
- 实现: 论文中提到可以是小型卷积神经网络(CNN)或多层感知机(MLP)。这与传统决策树中简单的轴对齐(axis-aligned)划分函数形成鲜明对比,使得路由决策本身也能学习到复杂的特征表示。
-
变换函数 t ψ ∈ T t^\psi \in \mathcal{T} tψ∈T : 树的每一条边 e ∈ E e \in \mathcal{E} e∈E 都带有一个或一组变换模块。图 Figure 1 中边上的黑色小点。
- 功能: 对流经的特征表示进行非线性变换。例如,一个卷积层加 ReLU 激活函数。
- 参数 : 由 ψ \psi ψ 参数化。
- 核心意义 : 这是 ANTs 与传统决策树(如 SDTs)最显著的区别之一。传统决策树的边通常是恒等函数,数据在树中传递时其特征表示不变。而 ANTs 的边能够"加深"(deepen),学习到更丰富、更抽象的分层表示(Hierarchical Representations)。这意味着每一条从根到叶的路径,本身就是一条"深度神经网络流水线"。
-
求解器 s l ϕ ∈ S s_l^\phi \in \mathcal{S} slϕ∈S : 每个叶子节点 l ∈ N l e a f l \in \mathcal{N}_{leaf} l∈Nleaf 配备一个求解器。图 Figure 1 中叶子节点。
- 功能 : 接收来自父节点的变换后的特征 x l ∈ X l x_l \in \mathcal{X}_l xl∈Xl,并输出对目标变量 y y y 的预测分布 p ( y ∣ x ) p(y|x) p(y∣x)。
- 参数 : 由 ϕ \phi ϕ 参数化。
- 实现 : 对于分类任务,可以是特征空间上的线性分类器。
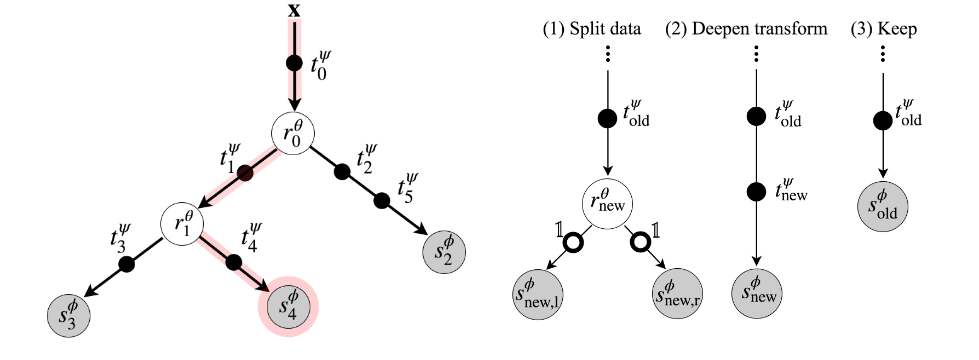 Figure 1
Figure 1
-
图 Figure 1 左图中红色阴影表示了数据 x x x 经过一系列路由函数,最终到求解器 s 4 ϕ s_4^\phi s4ϕ 的路径。
前向预测
ANTs 将条件分布 p ( y ∣ x ) p(y|x) p(y∣x) 建模为一个分层混合专家模型(Hierarchical Mixture of Experts, HMEs) ,每个"专家"对应一条从根到叶的路径。模型的总参数集为 Θ = ( θ , ψ , ϕ ) \Theta = (\theta, \psi, \phi) Θ=(θ,ψ,ϕ)。
给定输入 x x x,预测分布为:
p ( y ∣ x , Θ ) = ∑ l = 1 L π l θ , ψ ( x ) p l ϕ , ψ ( y ) p ( y ∣ x , Θ ) = ∑ l = 1 L p ( z l = 1 ∣ x , θ , ψ ) ⏟ Leaf-assignment prob. π l θ , ψ p ( y ∣ x , z l = 1 , ϕ , ψ ) ⏟ Leaf-specific prediction. p l ϕ , ψ ( 1 ) p(y|x, \Theta) = \sum_{l=1}^{L} \pi_l^{\theta,\psi}(x) p_l^{\phi,\psi}(y)\\ \begin{aligned} &p(\mathbf{y}|\mathbf{x},\Theta)=\sum_{l=1}^L\underbrace{p(z_l=1|\mathbf{x},\boldsymbol{\theta},\boldsymbol{\psi})}{\text{Leaf-assignment prob. }\pi_l^{\boldsymbol{\theta},\boldsymbol{\psi}}}\underbrace{p(\mathbf{y}|\mathbf{x},z_l=1,\boldsymbol{\phi},\boldsymbol{\psi})}{\text{Leaf-specific prediction. }p_l^{\boldsymbol{\phi},\boldsymbol{\psi}}} \quad (1) \end{aligned} p(y∣x,Θ)=l=1∑Lπlθ,ψ(x)plϕ,ψ(y)p(y∣x,Θ)=l=1∑LLeaf-assignment prob. πlθ,ψ p(zl=1∣x,θ,ψ)Leaf-specific prediction. plϕ,ψ p(y∣x,zl=1,ϕ,ψ)(1)
其中:
- L L L 是叶子节点的总数, z = { 0 , 1 } L \mathbf z =\{0,1\}^L z={0,1}L 是 L L L 维的 onehot 向量, z l = 1 z_l=1 zl=1 表示使用 z l z_l zl 为叶节点。
- π l θ , ψ ( x ) : = p ( z l = 1 ∣ x , ψ , θ ) \pi_l^{\theta,\psi}(x) := p(z_l=1|x, \psi, \theta) πlθ,ψ(x):=p(zl=1∣x,ψ,θ) 是输入 x x x 被分配到叶子节点 l l l 的路径概率 ,由从根到叶 l l l 的唯一路径 P l \mathcal{P}l Pl 上所有路由器的决策概率的乘积给出。
π l ψ , θ ( x ) = ∏ r j θ ∈ P l r j θ ( x j ψ ) I l is left child of j ⋅ ( 1 − r j θ ( x j ψ ) ) 1 − I l is left child of j \pi_l^{\psi,\theta}(x) = \prod{r_j^{\theta} \in \mathcal{P}l} r_j^{\theta}(x_j^{\psi})^{ \mathbb{I}l \\text{ is left child of } j} \cdot (1-r_j^{\theta}(x_j^{\psi}))^{1 - \mathbb{I}l \\text{ is left child of } j} πlψ,θ(x)=rjθ∈Pl∏rjθ(xjψ)Il is left child of j⋅(1−rjθ(xjψ))1−Il is left child of j
这里的 x j ψ x_j^{\psi} xjψ 是输入 x x x 经过从根到节点 j j j 的所有变换函数组合后得到的特征表示。如果从根到节点 j j j 的路径上的变换函数序列是 t e 1 ψ , t e 2 ψ , ... , t e n ψ t{e_1}^\psi, t_{e_2}^\psi, \dots, t_{e_n}^\psi te1ψ,te2ψ,...,tenψ,那么:
x j ψ : = ( t e n ψ ∘ ⋯ ∘ t e 2 ψ ∘ t e 1 ψ ) ( x ) x_j^{\psi} := (t_{e_n}^{\psi} \circ \dots \circ t_{e_2}^{\psi} \circ t_{e_1}^{\psi})(x) xjψ:=(tenψ∘⋯∘te2ψ∘te1ψ)(x)
∘ \circ ∘ 是函数的复合运算。 - p l ϕ , ψ ( y ) : = p ( y ∣ x , z l = 1 , ϕ , ψ ) p_l^{\phi,\psi}(y) := p(y|x, z_l=1, \phi, \psi) plϕ,ψ(y):=p(y∣x,zl=1,ϕ,ψ) 是叶子节点 l l l 的局部预测 ,由其求解器 s l ϕ s_l^\phi slϕ 在变换后的输入特征 x p a r e n t ( l ) ψ x_{parent(l)}^\psi xparent(l)ψ (或 x l ψ x_l^\psi xlψ)上计算得出。
推断策略:
- 多路径推断(Multi-path inference): 使用公式 (1) 计算所有叶子节点的加权平均预测。计算成本较高,因为它需要遍历树的所有分支。
- 单路径推断(Single-path inference): 只根据路由器最高置信度的路径(贪婪遍历)选择一条从根到叶的路径进行计算和预测,只激活模型参数的一个子集。实验证明,由于路由器置信度通常接近 0 或 1,单路径推断能很好地近似多路径推断。
训练与优化
ANTs 的训练分为两个阶段,这体现了模型对架构自适应性的追求。
-
生长阶段(Growth phase) : 学习模型架构 T T T。
- 初始化: 从一个简单的根节点开始。
- 迭代过程: 采用广度优先搜索(BFS),对当前所有叶子节点逐一进行评估。
- 三种生长选项 : 对于每个叶子节点,模型评估三种可能的局部架构修改,如 Figure 1 右图所示:
- (1) "Split data"(分裂数据): 添加一个新的路由器和两个新的叶子节点(左右子节点)。新分支上的变换函数初始化为恒等函数。
- (2) "Deepen transform"(深化变换): 在当前叶子节点对应的传入边上添加一个新的变换模块,并替换旧的求解器为一个新的求解器。
- (3) "Keep"(保持): 不对当前节点进行任何修改。
- 局部优化: 对于选项 (1) 和 (2) 产生的新的模块,仅对其参数进行局部优化(通过最小化验证集上的 NLL)。固定已有模块的参数,减少计算量。
- 选择标准: 选择验证集 NLL 表现最好的选项。如果性能提升,则接受修改并继续生长;否则,执行 "Keep" 选项。
- 终止条件: 直到没有更多的"分裂数据"或"深化变换"操作能通过验证测试。
生长阶段是 ANTs 的核心。它赋予了模型在"变得更深"或"变得更宽"(划分数据)之间进行选择的自由。局部优化虽然可能导致次优决策,但效率高,尤其适用于大型模型,并可被后续精炼阶段修正。这可以看作是一种受约束的神经架构搜索(NAS)过程,只不过搜索空间被限定在树形结构上,且搜索是增量的。
-
精炼阶段(Refinement phase) : 调优全局参数 O O O。
- 目标 : 一旦树的拓扑结构 T T T 在生长阶段确定,进入精炼阶段。
- 优化方式 : 对整个 ANT 模型的所有参数 ( θ , ψ , ϕ ) (\theta, \psi, \phi) (θ,ψ,ϕ) 进行全局优化。同样使用 NLL (负对数似然) 作为目标函数,通过端到端的反向传播和梯度下降进行。
- 意义: 修正生长阶段中由于局部优化可能导致的次优参数。实验表明,精炼阶段能显著改善模型的泛化误差,甚至能"剪枝"掉一些冗余或不必要的路径,使路由器决策更加集中。
损失函数 (NLL) :
− log p ( Y ∣ X , Θ ) = − ∑ n = 1 N log ( ∑ l = 1 L π l θ , ψ ( x ( n ) ) p l ϕ , ψ ( y ( n ) ) ) -\log p(\mathbf{Y}|\mathbf{X},\Theta)=-\sum_{n=1}^N\log\:(\sum_{l=1}^L\pi_l^{\boldsymbol{\theta},\boldsymbol{\psi}}(\mathbf{x}^{(n)})\:p_l^{\boldsymbol{\phi},\boldsymbol{\psi}}(\mathbf{y}^{(n)})) −logp(Y∣X,Θ)=−n=1∑Nlog(l=1∑Lπlθ,ψ(x(n))plϕ,ψ(y(n)))由于所有组件(路由器、变换器、求解器)都是可微分的,因此可以使用标准的基于梯度的优化算法。
通过这两阶段的优化,ANTs 不仅能找到适应数据的树形结构,还能精细地调整结构内各个神经网络组件的参数,从而在表示学习和架构学习之间实现协同。这种"结构生成"与"参数优化"的解耦再耦合,是其区别于一般混合模型的关键。
实验测评
论文在 SARCOS(多元回归)、MNIST 和 CIFAR-10(图像分类)这三个不同类型的数据集上进行了实验。核心结论清晰而有力:
-
竞争力:ANTs 在 SARCOS 数据集上实现了最低的均方误差(MSE),即便与最先进的基于树的模型(如梯度提升树 GBTs)和各种 MLP 相比,也展现出领先地位。在图像分类任务上,ANTs 显著优于传统随机森林(RFs)和梯度提升树(GBTs),并且与一些轻量级、非残差连接的 CNN 模型性能相当,甚至更优。
-
效率与权衡:
- 单路径推理 :一个关键的发现,ANTs 的单路径推理(仅激活从根到叶的一条路径)与多路径推理(聚合所有叶子节点的预测)在准确性上差异极小(分类误差通常小于 0.1%),但在计算开销(FLOPS)和激活参数量上则大幅降低。这得益于路由器学习到的高置信度拆分概率 (即 r j θ ( x j ) r_j^\theta(x_j) rjθ(xj) 趋近于 0 或 1),使得模型在推断时能果断地"选择"一条路径。
- 参数效率:在某些配置下,ANTs 甚至能以更少的参数量达到甚至超越 LeNet-5 等传统 CNN 模型在 MNIST 上的性能。这表明树状的层级共享和分离机制,能够有效地增强计算和预测性能。
-
消融实验:
- "无路由器"(no R):此时 ANTs 退化为某种形式的自适应生长的纯神经网络。在所有数据集上,其性能均显著低于完整的 ANTs。
- "无变换器"(no T):此时 ANTs 退化为一种带有可学习路由器的软决策树(SDT/HME)。其性能下降更为剧烈,特别是在图像数据集上,误差大幅飙升。
总结
ANTs 不仅仅是一个性能优秀的模型,更重要的是,它提供了一种看待深度学习和决策树的新视角,并引出了许多值得深思的问题。
- 可解释的特征分离:论文中提及,ANTs 能够学习到"有意义的层级划分",例如将图像分为"自然物体"和"人造物体"等。这为"黑箱"的神经网络提供了一扇窥探内部决策逻辑的窗户。树的结构本身就具有一定的可解释性,而学习到的路由函数进一步增强了这种可解释性。这对于许多对模型透明度有要求的领域(如医疗、金融)具有重要意义。
- 架构自适应性:奥卡姆剃刀的实践 :ANTs 的生长机制使其能够根据训练数据的大小和复杂性自适应地构建模型架构。这意味着对于小数据集,它不会过度生长导致过拟合;对于大数据集,它能够探索更深、更复杂的结构。这本质上是在实践机器学习的奥卡姆剃刀原理:用最简单的模型解释数据。
- "软"划分的胜利:传统决策树训练难点在于"硬划分"导致的损失函数不可微。ANTs 通过将路由器输出解释为伯努利分布的概率,并使用混合专家模型(HMEs)的框架,巧妙地避开了这一难题,使得整个树结构都可微,从而能够进行端到端的梯度下降优化。这为传统决策树的扩展开辟了新的道路。
局限与展望
- 贪婪生长与全局最优 :虽然生长阶段比预设架构更灵活,但其本质仍是局部贪婪搜索。每次只在当前叶子节点进行局部最优决策。这可能导致模型陷入局部最优,无法发现全局上更优异的架构。未来的工作可以探索更全局的架构搜索策略,例如基于强化学习或进化算法的树结构搜索,或者像决策森林那样,训练多个 ANTs 进行集成。
- 计算成本:生长阶段的局部优化虽然效率相对高,但对于非常大的数据集和复杂的模块,每次评估三个选项并进行局部训练仍然是计算密集型的。如何在保持自适应性的同时,进一步提高架构搜索的效率,仍是挑战。
- 模块的通用性:论文中使用的基础模块(如卷积层、MLP)是通用的。未来是否可以设计更适合树状结构、更轻量、更具表达力的神经模块,以进一步提升效率和性能?
- 可解释性与复杂性的平衡:虽然 ANTs 比纯粹的 NNs 更具解释性,但随着树的深度和复杂度的增加,特别是每个节点和边都包含深层 NN 时,完全理解特定输入在树中的决策路径和特征转换仍可能面临挑战。如何在增加模型能力的同时,维持甚至增强其可解释性,是一个持续的研究方向。