1.简介
朴素贝叶斯(Naive Bayes)是一类基于贝叶斯定理(之后讲)并假设特征之间相互独立的概率分类算法 ,是机器学习中应用广泛的分类模型。以下为您详细介绍:
核心原理
- 贝叶斯定理:描述后验概率与先验概率和似然概率之间的关系。通过已知的先验概率、类条件概率等,计算在给定特征条件下样本属于某一类别的后验概率。例如在判断邮件是否为垃圾邮件时,利用先验的垃圾邮件概率、邮件中出现某些关键词的条件概率等计算该邮件是垃圾邮件的后验概率。
- 特征条件独立假设 :假定所有特征在给定类别条件下相互独立。比如判断新闻文本类别时,假设文本中的不同词语(特征)在类别确定时相互独立,不考虑词语间关联。但实际中该假设往往不完全成立,不过在很多场景下仍有不错效果。
常见类型
- 高斯朴素贝叶斯:假设特征服从高斯分布(正态分布) ,适用于处理连续型特征数据,如根据人的身高、体重等连续特征进行分类。
- 多项式朴素贝叶斯:以多项分布作为似然度概率模型,常用于文本分类场景,通过计算文本中词频等特征来分类 。
- 伯努利朴素贝叶斯:基于伯努利分布(二值分布 ),要求数据特征为二元类型(如文档中是否包含某个词)。
应用场景
- 文本分类:垃圾邮件检测、新闻分类等,通过分析文本中词汇特征判断类别。
- 情感分析:分析社交媒体评论、商品评价等文本的情感倾向(积极、消极、中性)。
- 疾病诊断:依据患者症状、检查指标等特征判断疾病类别。
优缺点
- 优点:算法实现简单,计算效率高,适合大规模数据集;能提供类别的后验概率,可评估预测置信度;对高维特征数据友好,在特征独立性假设成立或关联性较弱时性能好;不易过拟合,尤其数据量大时;模型参数直观,可解释性强。
- 缺点 :特征条件独立假设在实际中常不满足,会影响分类准确性;对输入数据的表达形式敏感,需进行合适预处理 。
2.概率论的基础知识

3.朴素贝叶斯公式

其实就是一个条件概率公式和全概率公式的应用 
但是比如说计算p(a/b,c)时 :看一个案例
就是如果不假设特征相互独立,会出现某些部分为0的情况,这样是不合理的,也是因为样本有点太少了,所以假设相互独立,联合概率我们直接相乘即可。 现在我们可以看如果朴素贝叶斯用于文本分类的情况下(分母都一样一般不计算):在应用于不同情况中主要公式一样,只不过具体内容不一样。

但是还会引出一个问题就是当统计太少时,分母偶然会有一部分为0,这样会丢失信息,我们引入拉普拉斯平滑系数解决,看这个案例:
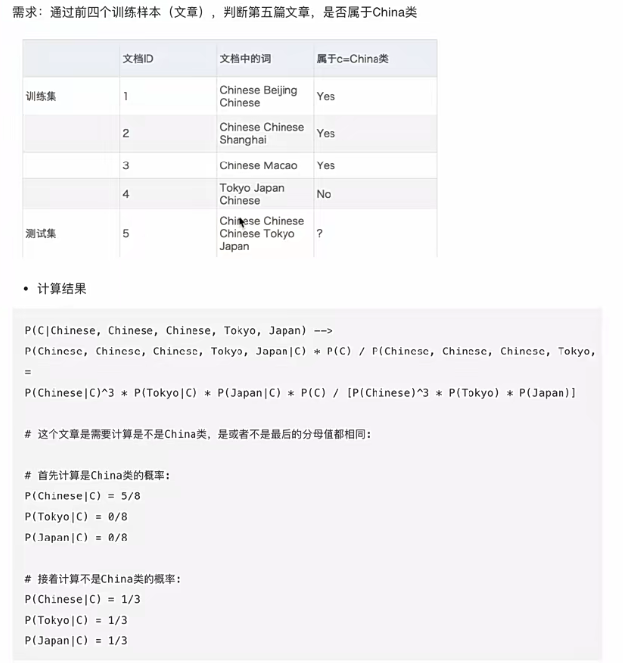
问题:从上面的例子我们得到 P (Tokyo|C) 和 P (Japan|C) 都为 0,这是不合理的,
如果词频列表里面有很多出现次数都为 0,很可能计算结果都为零。 我们引入拉普拉斯平滑系数即可:

实现API:
4.案例:商品评论情感分析:就是通过内容去分析属于差评还是好评。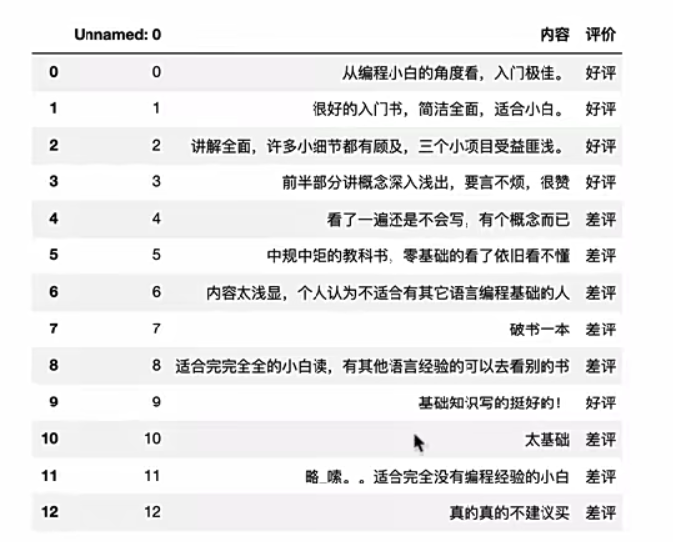
主要是数据基本处理比较繁琐,因为我们需要将内容转化为处理的标准格式(jieba分词+停用词),并且统计个数用于朴素贝叶斯的计算概率(文本特征提取)。
 代码:
代码:
(1)数据获取
python
import pandas as pd
import numpy as np
import jieba
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
#导入pandas用于数据处理,numpy用于数值计算,jieba用于中文分词,
#matplotlib.pyplot用于绘图(代码中#未实际使用绘图功能 ),
#CountVectorizer用于将文本转换为词频矩阵,MultinomialNB用于实现多项式朴素#贝叶斯分类。
data = pd.read_csv("./data/书籍评价.csv", encoding="gbk")
data(2.1)
python
content = data["内容"]
content.head()当然也可以
content = data"内容".values()
content.head()
(2.2)这部分没有用到,但其实在现实中经常用,把特征转化为机器可以处理的特征
python
data.loc[data.loc[:, '评价'] == "好评", "评论标号"] = 1
data.loc[data.loc[:, '评价'] == '差评', '评论标号'] = 0
good_or_bad = data['评价'].values
print(good_or_bad). loc也可以接受第一个参数是布尔型的,如下图
(2.3)从本地文件stopwords.txt中读取停用词,去除重复后存于stopwords列表中。停用词是文本中无实际意义、对情感分析帮助不大的词,如 "的""了" 等,去除它们可减少数据噪声。
python
stopwords=[]
with open('./data/stopwords.txt','r',encoding='utf-8') as f:
lines=f.readlines()
print(lines)
for tmp in lines:
line=tmp.strip()
print(line)
stopwords.append(line)
stopwords = list(set(stopwords))
print(stopwords)解释细节: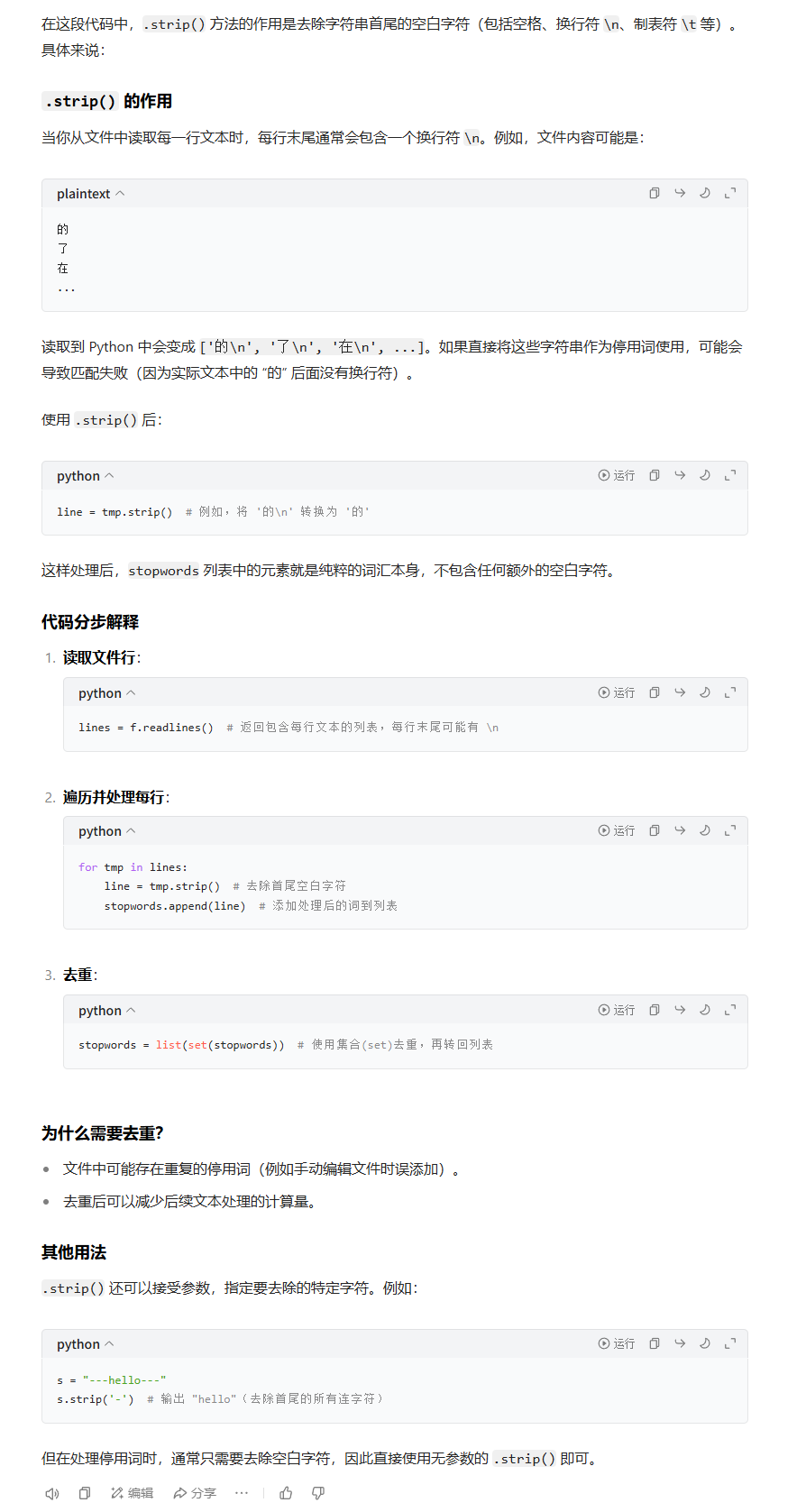 (2.4)对 "内容" 列的每条文本进行分词(使用
(2.4)对 "内容" 列的每条文本进行分词(使用jieba的精确模式 ),将分词结果用逗号连接成字符串,并存入comment_list列表。
python
comment_list = []
for tmp in content:
print(tmp)
seg_list = jieba.cut(tmp, cut_all=False)
print(seg_list)
seg_str = ','.join(seg_list)
print(seg_str)
comment_list.append(seg_str) 解释细节: (2.5)实例化
(2.5)实例化CountVectorizer对象,传入停用词列表,将comment_list中的文本转换为词频矩阵X ,获取词袋中的关键字name ,并打印词频矩阵和关键字。
python
con = CountVectorizer(stop_words=stopwords)
X = con.fit_transform(comment_list)
name = con.get_feature_names()
print(X.toarray())
print(name)(2.6) 简单地将前 10 行数据作为训练集,后 3 行作为测试集,分别划分词频矩阵数据和对应的标签数据。
python
x_train = X.toarray()[:10, :]
y_train = good_or_bad[:10]
x_text = X.toarray()[10:, :]
y_text = good_or_bad[10:](3)实例化多项式朴素贝叶斯分类器mb ,设置拉普拉斯平滑系数alpha为 1 ,使用训练集数据进行训练,然后对测试集数据进行预测,并打印预测值和真实值。
python
mb = MultinomialNB(alpha=1)
mb.fit(x_train, y_train)
y_predict = mb.predict(x_text)
print('预测值: ',y_predict)
print('真实值: ',y_text)(4)使用测试集数据评估模型性能,score方法返回模型在测试集上的准确率。
python
mb.score(x_text, y_text)5.朴素贝叶斯算法总结
- 优缺点
- 优点 :
- 理论基础与效率:源于古典数学理论,分类效率稳定。像在文本分类场景中,能快速处理大量文本并分类。
- 数据适应性:对缺失数据敏感度低,算法简单。实际应用中,即使数据存在部分缺失,也不影响整体分类效果(因为我们计算的是属于某一类的概率,概率比较大小即可,缺失数据不影响)。
- 分类性能:分类准确度较高且速度快,在文本处理等领域广泛应用。
- 缺点 :
- 特征关联问题:基于样本属性独立性假设,当特征属性存在关联时,分类效果不佳。例如在分析金融数据时,一些经济指标间存在内在联系,朴素贝叶斯假设会导致偏差。
- 先验概率依赖:需计算先验概率,先验概率假设模型多样,若假设不合理,预测效果受影响 。
- 优点 :

一个例子看懂生成模型和判别模型,马上发现朴素贝叶斯是生成模型,lr是判别模型。