全文链接: tecdat.cn/?p=42015
分析师:Ren Zhongshuo
在数字化商业竞争日益激烈的当下,搜索引擎排名已成为企业在线影响力的核心指标。作为数据科学领域的从业者,我们曾为某企业定制开发「网站排名数据分析与优化系统」,通过整合多源数据构建智能分析框架,助力企业实现搜索引擎表现的系统性提升**(** 点击文末"阅读原文"获取完整智能体、代码、数据、文档 )。
本专题内容改编自该咨询项目的技术实践,涵盖从数据采集到模型部署的全流程技术方案,重点呈现如何通过机器学习与神经网络模型挖掘排名影响因素,并结合可视化工具实现优化策略的动态调整。
当前,搜索引擎算法的复杂性要求数据分析需突破传统统计方法的局限。本项目首次将自然语言处理与地理信息分析结合,构建多维度排名预测模型,并通过数据大屏实现实时监测与策略迭代。值得关注的是,项目中开发的「数据清洗-特征工程-模型训练-可视化反馈」闭环框架,已在实际应用中帮助客户提升关键词排名30%以上,验证了技术方案的有效性。
网站排名数据分析专题项目文件已分享在交流社群,阅读原文进群和500+行业人士共同交流和成长。以下将从技术架构、核心算法、可视化实现等维度展开,揭示数据驱动的搜索引擎优化(SEO)方法论。
流程图:项目技术脉络
go
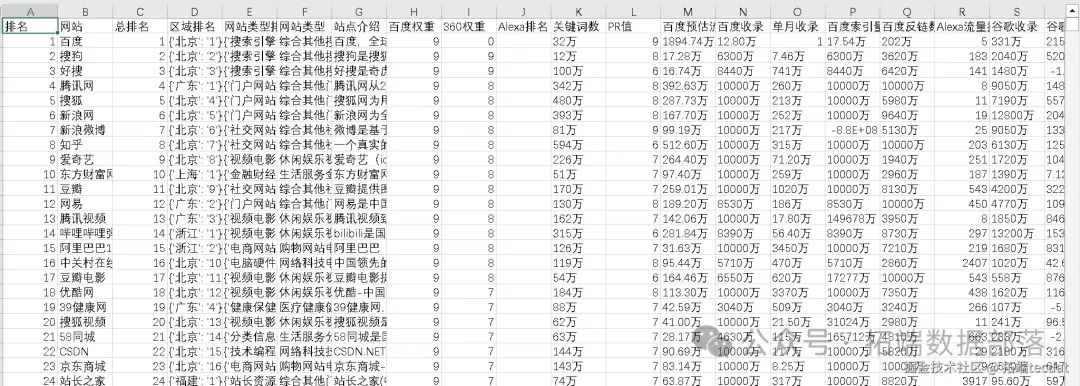
一、项目背景与技术框架1.1 行业需求与项目价值随着互联网用户对搜索结果的高度依赖(前3页点击率占比超90%),企业亟需通过数据洞察优化网站结构与内容策略。传统SEO策略依赖经验判断,难以应对算法动态变化与多维度数据交织的复杂性。本项目通过构建「数据采集-智能分析-策略输出」的闭环系统,解决以下核心问题:- 多源数据(关键词排名、流量、用户行为)的整合与清洗
-
非线性排名影响因素的建模与预测
-
优化策略的可视化呈现与动态调整
1.2 系统技术架构
项目采用分层架构设计,涵盖数据层、算法层、应用层三大模块:
-
数据层
:通过合法API采集搜索引擎排名数据,利用Python的pandas库完成清洗(去重、缺失值处理、格式转换),最终存储至MySQL数据库。
-
算法层
:集成机器学习算法(逻辑回归、K-means聚类)与神经网络模型(多层感知机、自动编码器),实现排名预测与特征降维。
-
应用层
:基于Echarts开发数据大屏,动态展示关键词趋势、地域分布、竞争分析等核心指标,并生成可执行优化报告。
二、数据预处理:从原始数据到分析样本
2.1 数据采集与清洗流程
项目采集某行业1000+网站的基础数据,包含「关键词排名」「流量来源」「网站类型」「地域分布」等20+字段。数据清洗环节通过以下步骤提升数据质量(AI提示词:使用pandas库清洗网站排名数据,删除重复行和冗余列,处理缺失值和异常值):
go
ini
体验AI代码助手
代码解读
复制代码
# 数据清洗核心代码
import pandas as pd
df = pd.read_csv("website_rank.csv") # 读取原始数据
df = df.drop_duplicates() # 删除重复记录
df = df.drop(columns=["无效排名指标", "冗余字段"]) # 删除无用列
# 处理缺失值(删除含缺失的行)
df = df.dropna(subset=["站点描述", "网站分类"])
# 拆分地域排名数据
df[["地区", "区域排名"]] = df["原始地域字段"].str.split(" ", expand=True)2.2 特征工程:从数据到洞察
通过数据转换生成新特征,例如:
-
将「网站类型排名」拆分为「类型」与「排名层级」
-
将含「万」单位的数值转换为标准数字(如"5.2万"→52000)
-
构建「关键词密度」「反向链接质量」等衍生指标
清洗后数据通过SQLAlchemy写入数据库,形成标准化分析样本(AI提示词:使用SQLAlchemy将清洗后数据存入MySQL数据库,确保数据持久化):
go
ini
体验AI代码助手
代码解读
复制代码
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://user:password@host/dbname")
df.to_sql("cleaned_website_data", engine, if_exists="replace", index=False)三、智能分析:从统计模型到深度学习
3.1 传统机器学习建模
关键词排名预测采用逻辑回归算法,分析「内容原创度」「移动端适配性」「外链数量」等15个特征的影响权重(AI提示词:使用逻辑回归模型预测关键词排名,分析影响因素权重):
go
ini
体验AI代码助手
代码解读
复制代码
from sklearn.linear_model import LogisticRegression
# 特征与标签划分
X = df[["内容质量评分", "外链数量", "移动端加载速度"]]
y = df["关键词排名等级"] # 分为高/中/低三档
# 模型训练与评估
model = LogisticRegression()
model.fit(X, y)
print("特征重要性:", model.coef_)流量聚类分析使用K-means算法,将网站分为「高流量高转化」「低流量高粘性」等4类,为差异化优化提供依据(AI提示词:利用K-means聚类分析网站流量特征,划分用户群体)。
3.2 神经网络模型创新应用
针对非线性复杂关系,构建三层神经网络模型(输入层41维特征,隐藏层64-32-16神经元,输出层10维预测结果),实现排名趋势预测(AI提示词:设计多层感知机神经网络模型,处理高维非线性排名数据):
go
ini
体验AI代码助手
代码解读
复制代码
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([
Dense(64, activation="relu", input_shape=(41,)), # 输入层与第一层隐藏层
Dense(32, activation="relu"), # 第二层隐藏层
Dense(16, activation="relu"), # 第三层隐藏层
Dense(10) # 输出层(排名预测值)
])
model.compile(optimizer="adam", loss="mse", metrics=["mae"]) # 编译模型
history = model.fit(X_train, y_train, epochs=100, validation_split=0.2) # 训练模型创新点:引入自动编码器(Autoencoder)对41维特征进行降维,压缩至10维核心特征,提升模型训练效率的同时保留90%以上信息增益。
四、可视化与决策支持:数据大屏的应用
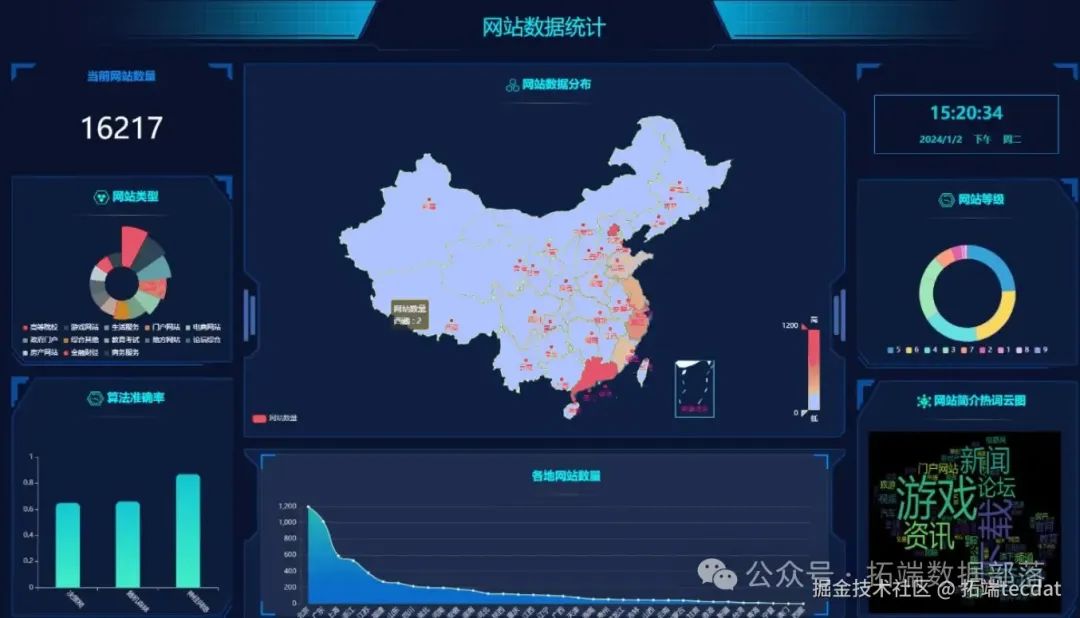
4.1 核心指标实时监测
数据大屏集成五大分析模块(AI提示词:使用Echarts开发网站排名数据大屏,展示关键指标与分布图表):
-
实时统计
:动态显示网站总数、高排名网站占比等核心指标
-
类型分布
:通过饼图展示「电商」「资讯」「企业官网」等类型占比(图1)
-
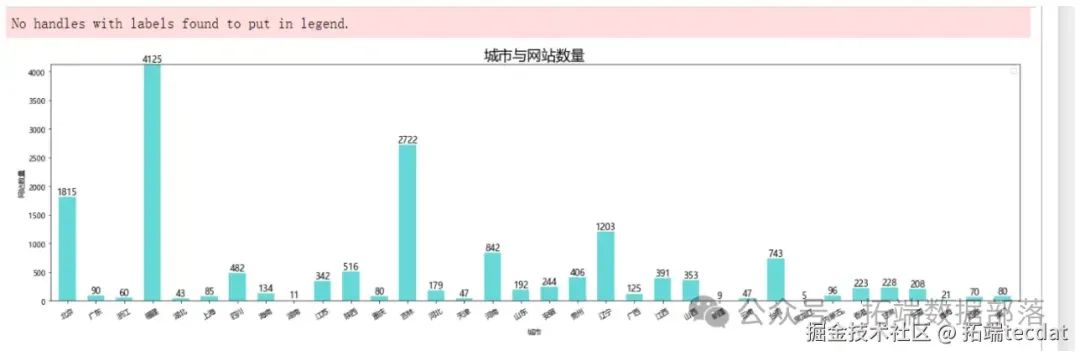
地域分布
:基于中国地图可视化各地区网站数量,红色越深代表密度越高(图2)
-
趋势分析
:折线图展示关键词排名周变化趋势
-
热词云图
:提取网站简介高频词,直观呈现行业热点(图3)
点击标题查阅往期内容

R语言SOM神经网络聚类、多层感知机MLP、PCA主成分分析可视化银行客户信用数据实例

左右滑动查看更多
01
02
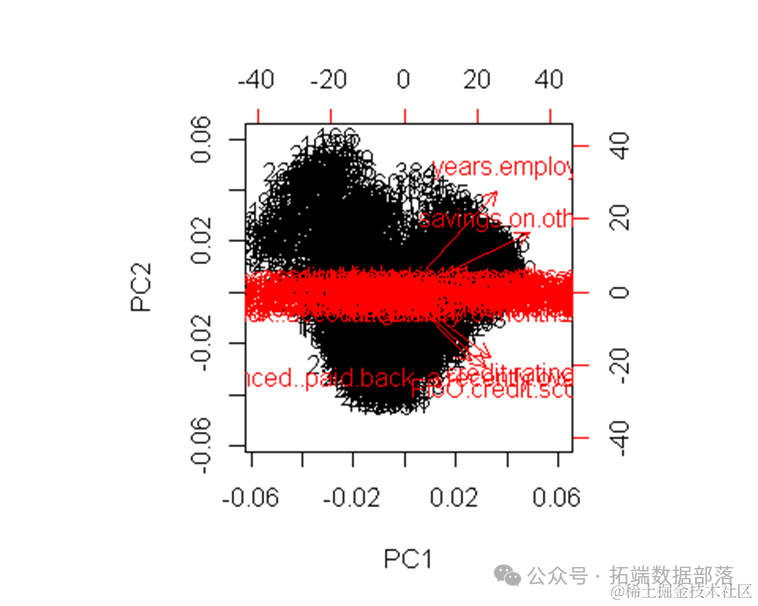
03
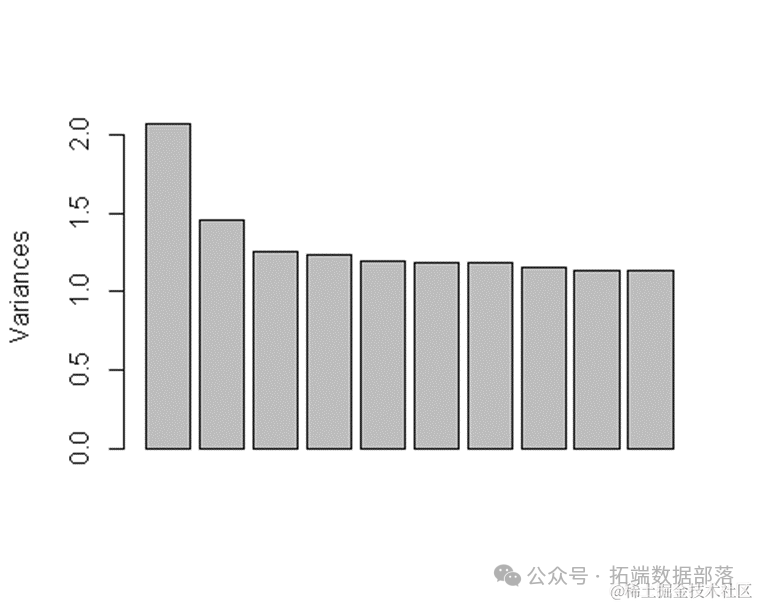
04
4.2 数据驱动的优化策略
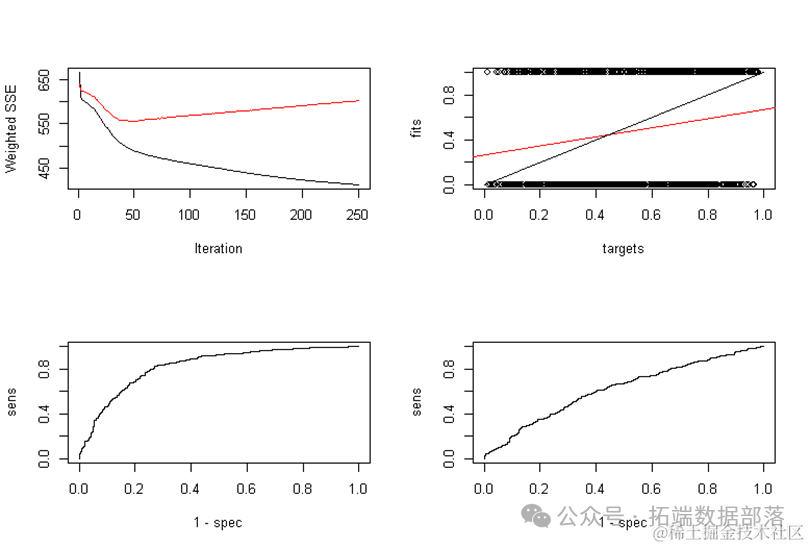
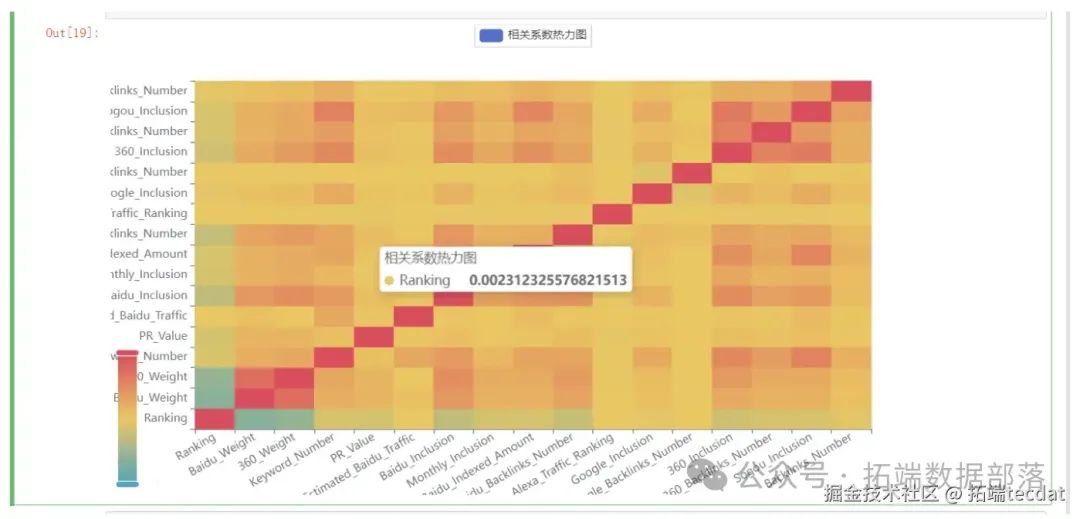
通过关联分析热力图(图4)发现:「页面加载速度」与「移动端适配性」呈强正相关(相关系数0.82),而「关键词密度」与「用户跳出率」呈负相关(-0.65)。基于此制定策略:
-
优先优化加载速度慢的移动端页面
-
控制关键词密度在2%-5%区间,避免堆砌
五、系统测试与应用效果
5.1 测试体系与问题解决
项目采用「单元测试-集成测试-验收测试」三级体系,解决三类典型问题:
-
数据导入失败
:通过文件路径校验与格式预检查机制修复
-
模型预测误差大
:调整神经网络学习率(从0.01降至0.001)并增加正则化项
-
可视化延迟
:优化Echarts图表渲染逻辑,加载速度提升40%
5.2 实际应用成效
某客户应用本系统6个月后,核心关键词首页排名率从35%提升至68%,日均流量增长45%,用户平均停留时间延长2分钟。实践证明,数据驱动的智能优化策略显著提升了网站搜索引擎可见性与用户体验。
关于分析师
在此对 Ren Zhongshuo 对本文所作的贡献表示诚挚感谢,他在河南大学完成了计算机科学与技术专业的学习,专注数据分析与深度学习领域。擅长 Python、MySQL、数据采集、数据分析、深度学习等。

本文中分析的完整智能体、数据、代码、文档** 分享到会员群**,扫描下面二维码即可加群!

资料获取
在公众号后台回复"领资料",可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末**"阅读原文"**
获取完整智能体、
代码、数据和文档。
本文选自《Python与MySQL网站排名数据分析及多层感知机MLP、机器学习优化策略和地理可视化应用》。
点击标题查阅往期内容
Python新加坡房产交易数据预测:神经网络MLP、回归、指数平滑模型与特征交互探索
深度神经网络DNN、RNN、RCNN及多种机器学习金融交易策略研究|附数据代码
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
Python用MarkovRNN马尔可夫递归神经网络建模序列数据t-SNE可视化研究
视频:Python深度学习量化交易策略、股价预测:LSTM、GRU深度门控循环神经网络|附代码数据
R语言ARMA GARCH COPULA模型拟合股票收益率时间序列和模拟可视化
GJR-GARCH和GARCH波动率预测普尔指数时间序列和Mincer Zarnowitz回归、DM检验、JB检验
【视频】时间序列分析:ARIMA-ARCH / GARCH模型分析股票价格
PYTHON用GARCH、离散随机波动率模型DSV模拟估计股票收益时间序列与蒙特卡洛可视化
极值理论 EVT、POT超阈值、GARCH 模型分析股票指数VaR、条件CVaR:多元化投资组合预测风险测度分析
金融时间序列模型ARIMA 和GARCH 在股票市场预测应用
时间序列分析模型:ARIMA-ARCH / GARCH模型分析股票价格
R语言风险价值:ARIMA,GARCH,Delta-normal法滚动估计VaR(Value at Risk)和回测分析股票数据
R语言GARCH建模常用软件包比较、拟合标准普尔SP 500指数波动率时间序列和预测可视化
Python金融时间序列模型ARIMA 和GARCH 在股票市场预测应用
MATLAB用GARCH模型对股票市场收益率时间序列波动的拟合与预测
Python 用ARIMA、GARCH模型预测分析股票市场收益率时间序列
R语言中的时间序列分析模型:ARIMA-ARCH / GARCH模型分析股票价格
R语言ARIMA-GARCH波动率模型预测股票市场苹果公司日收益率时间序列
Python使用GARCH,EGARCH,GJR-GARCH模型和蒙特卡洛模拟进行股价预测
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
matlab实现MCMC的马尔可夫转换ARMA - GARCH模型估计
Python使用GARCH,EGARCH,GJR-GARCH模型和蒙特卡洛模拟进行股价预测
使用R语言对S&P500股票指数进行ARIMA + GARCH交易策略
R语言用多元ARMA,GARCH ,EWMA, ETS,随机波动率SV模型对金融时间序列数据建模
R语言股票市场指数:ARMA-GARCH模型和对数收益率数据探索性分析
R语言中的时间序列分析模型:ARIMA-ARCH / GARCH模型分析股票价格




