本地显存池
数据结构
因为kv cache有MHA,MLA,DoubleSparse 等多种自定义类型,需要进行一步抽象将框架和cache类型做隔离, 所以有了2级内存池的设计. 一级保存和cache类型无关的数据(token位置),跟具体业务隔离,二级给出抽象类接口, 不同的cache类型按需继承实现interface, 就能通过配置来进行管理.
二级显存池
req_to_token_pool
python
class ReqToTokenPool:
"""A memory pool that maps a request to its token locations."""
def __init__(
self,
size: int,
max_context_len: int,
device: str,
enable_memory_saver: bool,
):
memory_saver_adapter = TorchMemorySaverAdapter.create(
enable=enable_memory_saver
)
self.size = size #size对应的是server_args.max_running_requests
self.max_context_len = max_context_len #对应的是从模型配置里读出来的支持最大的上下文长度
self.device = device
with memory_saver_adapter.region():
self.req_to_token = torch.zeros( #2维, 第一维偏移代表是第几个req, 第二位偏移记录在req中token在二级池的索引
(size, max_context_len), dtype=torch.int32, device=device
)
self.free_slots = list(range(size)) #1维, 用于记录哪些req被释放掉了, 在后续的请求可以复用token_to_kv_pool
功能: 将 token 的 KV Cache索引映射到其 KV Cache数据, 实际的实现中这个依然是2大类组合形成的, 包括PagedTokenToKVPoolAllocator与KVCache接口类和其对应的子类 (只看了page_size>1的实现)
PagedTokenToKVPoolAllocator主要负责kv分页后的页表管理, 存储的数据是free_pages, 假设page_size=4. 初始化状态如下:
markdown
+---------+---------+---------+---------+
| Page 1 | Page 2 | Page 3 | Page 4 |
| 4~7 | 8~11 | 12~15 | 16~19 |
+---------+---------+---------+---------+
free_pages: [1, 2, 3, 4]
alloc:
分配8个token后:
free_pages: [3, 4]
分配到的索引: [4,5,6,7,8,9,10,11]
free:
传入要回收的 token 索引(如 [4,5,6,7,8,9,10,11]),会通过idx / page_size转换为页索引 [1,2],并加回free_pages,变为 [1,2,3,4]KVCache子类, 以MLA为例, kv_buffer为layer_num个torch.Tensor, 存储了k_buffer 的 cache_k 和 v_buffer 的 cache_v, 每个tensor的dim分别表示: (最大token数 + page_size, head_dim(MLA里是1),head维度)
在MLA里, head维度是 LoRA相关的KV维度(低秩适配部分) + QK经过RoPE后的维度
第一维要加page_size的原因是: 如果不加, 某些操作(如buffer[start_idx : start_idx + page_size])会越界, 加上page_size后可以避免这些越界情况的判断, 简化逻辑
python
with memory_saver_adapter.region():
# The padded slot 0 is used for writing dummy outputs from padded tokens.
self.kv_buffer = [
torch.zeros(
(size + page_size, 1, kv_lora_rank + qk_rope_head_dim),
dtype=self.store_dtype,
device=device,
)
for _ in range(layer_num)
]HostKVCache
Hierarchical Caching(分层缓存)机制, 支持一部分kvcache通过offload方式放到内存里. 由于会影响推理速度暂没用到. 待有需求的时候再细看.
显存alloc/free
alloc
从二级显存池申请空间逻辑都在forwardBatch.prepare_for_extend/prepare_for_decode里面, 以extend为例, 分为几步:
alloc_req_slots: 根据batch_size, 从req_to_token_pool中申请bs个free_req对应的token索引.- 遍历reqs, 把刚才申请到的
req_pool_indices[i]填到对应req的req_pool_idx成员里, 使其能够一一对应get_last_loc: 获取每个请求前缀最后一个token在req_pool_indicesi中的索引token_to_kv_pool_allocator.alloc_extend: 计算逻辑在alloc_extend_kernel里,- 第一步: 因为之前算出了最后一个token在显存中的偏移, 根据这个偏移和page_size能拿到最后token所在页和还有多少剩余空间, 先把这页没满的空间填满.
- 第二步: 从free_page里拿出新页继续填充
- 第三步: 分配最后一页, 如果填不满, 就把剩下的token填到这一页的前几个里面
free
在Cache复用中决定这些cache何时被回收, 通过调用token_to_kv_pool_allocator.free和req_to_token_pool.free处理. 核心逻辑:
python
free_page_indices = torch.unique(free_index // self.page_size) #会把所有 token 索引转换为页号(同一页的 token 都会变成同一个页号)。
self.free_pages = torch.cat((free_page_indices, self.free_pages)) #塞回free_pages只要页内有任意 token 被回收,这一整页就会被回收
KVCache读写
在attn_backend的forward函数中
P阶段把kv写到kv_buffer里, 即根据cache_loc到KVCache子类中对应的偏移中将torch.Tensor的值复制过去
D阶段根据layer_id读出对应layer的cache.
python
if k is not None:
assert v is not None
if save_kv_cache:
forward_batch.token_to_kv_pool.set_kv_buffer(
layer, cache_loc, k, v, layer.k_scale, layer.v_scale
)
# Call the wrapped function
o = decode_wrapper.forward(
q.contiguous().view(-1, layer.tp_q_head_num, layer.head_dim),
forward_batch.token_to_kv_pool.get_kv_buffer(layer.layer_id),
sm_scale=layer.scaling,
logits_soft_cap=layer.logit_cap,
k_scale=layer.k_scale,
v_scale=layer.v_scale,
)Cache复用
RadixCache
数据结构
基于基数树RadixTree数据结构实现的Cache, 其实就是压缩版的前缀树. 一看图就能弄清楚:
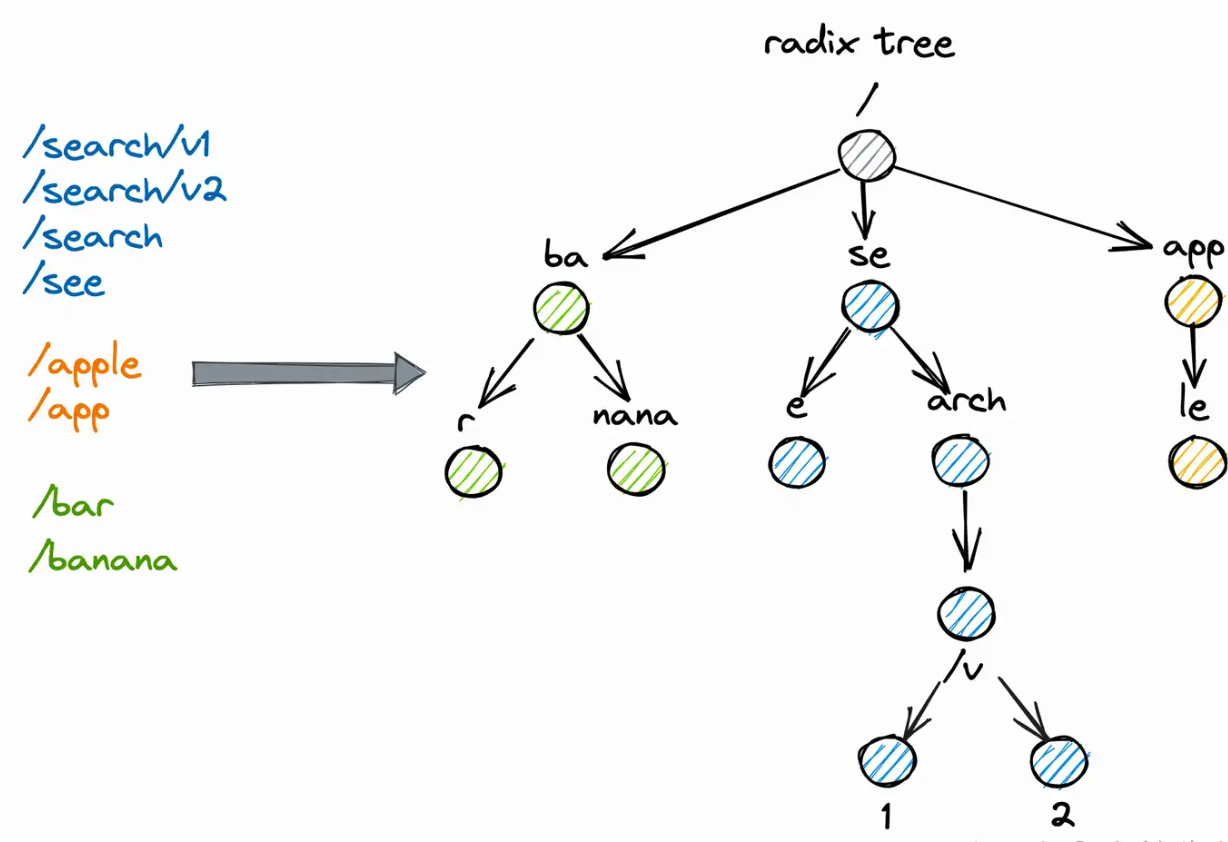
查询: 一直DFS到没有公共前缀为止.
插入:以root为起点遍历, 对当前节点做前缀匹配, 长度>0就进入子树否则进入兄弟节点. 一直DFS到没有公共前缀为止, 把不相同的str插入到新叶节点上.
插入与驱逐
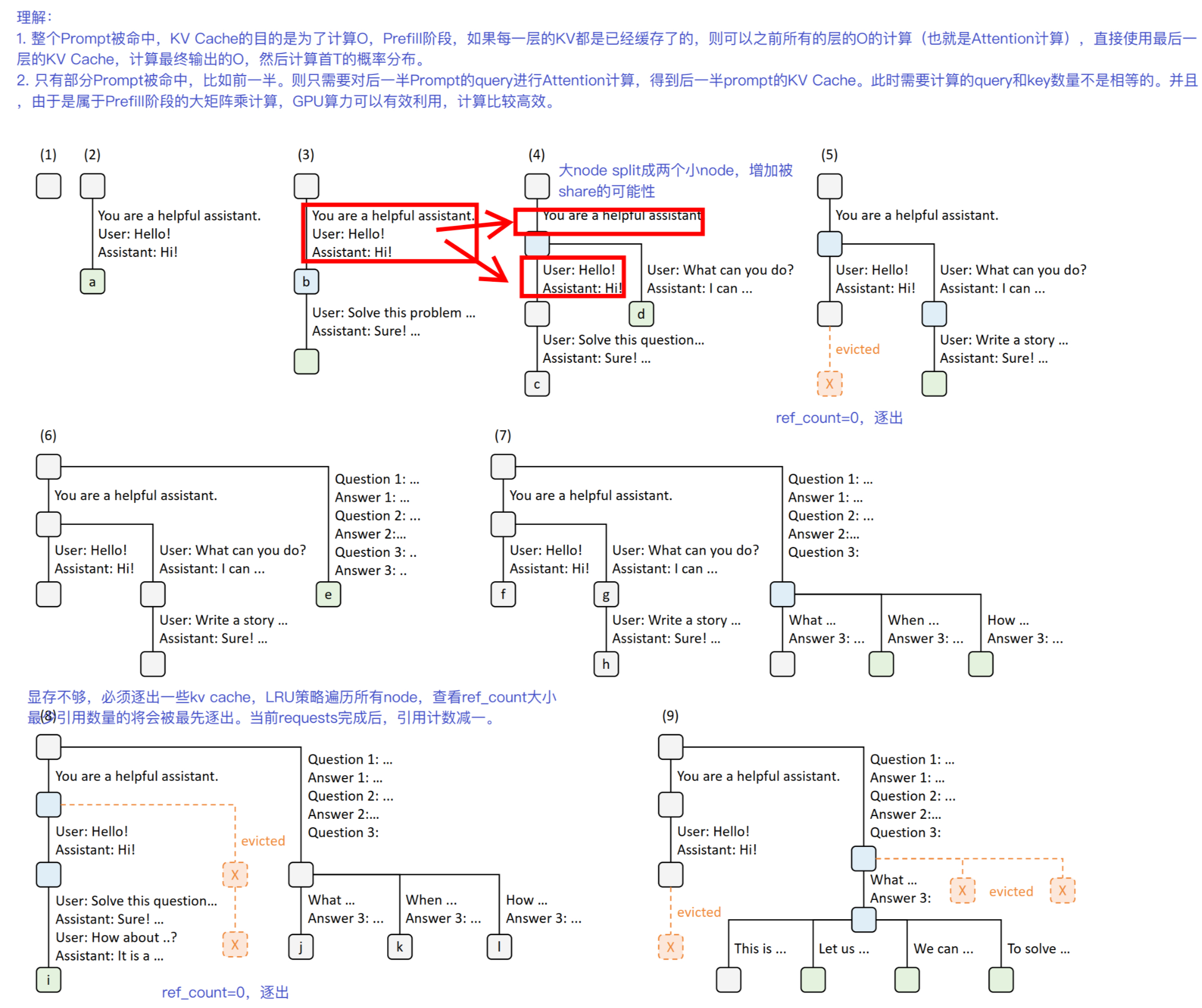
前缀匹配代码解析:
python
def _match_prefix_helper(self, node: TreeNode, key: List): #传入的node就是root
node.last_access_time = time.time()
child_key = self.get_child_key_fn(key)
value = []
while len(key) > 0 and child_key in node.children.keys(): #非递归版dfs, 非page时当key中的第一个不在node的child中退出.(即完全不匹配)
child = node.children[child_key]
child.last_access_time = time.time()
prefix_len = self.key_match_fn(child.key, key) #树节点和当前token_id list进行前缀匹配
if prefix_len < len(child.key): #部分匹配
new_node = self._split_node(child.key, child, prefix_len) #分裂不匹配的那部分, 挂到当前节点下面作为child
value.append(new_node.value)
node = new_node
break
else:
value.append(child.value) #完全匹配, 进入子节点继续遍历, 把已经匹配成功的节点加到结果里
node = child
key = key[prefix_len:] #去掉已经匹配过的前缀
if len(key):
child_key = self.get_child_key_fn(key)
return value, node驱逐使用了引用计数(lock_ref)用于记录当前cache有没有在使用, 当叶子的引用计数为0时可以驱逐释放. 参考函数dec_lock_ref, 注意这里lock_ref在减这个node时, 会把他的所有父节点路径全都减1. 驱逐代码解析:
python
def evict(self, num_tokens: int):
if self.disable:
return
leaves = self._collect_leaves() #通过BFS方式获取到树上的所有节点
heapq.heapify(leaves) #把树list转成堆, 通过TreeNode中的__lt__进行比较排序, 其实就是比last_access_time
num_evicted = 0
while num_evicted < num_tokens and len(leaves): #循环pop heap
x = heapq.heappop(leaves)
if x == self.root_node:
break
if x.lock_ref > 0: #引用计数>0的叶子跳过
continue
self.token_to_kv_pool_allocator.free(x.value) #释放ref_count=0的kvcache
num_evicted += len(x.value)
self._delete_leaf(x) #在树上删掉这个叶节点
if len(x.parent.children) == 0: #如果这个叶节点的父节点, 被删除这个child后也变成了叶节点, 把他push进heap
heapq.heappush(leaves, x.parent)cache_request(req)
- 从
req_to_token_pool.req_to_token获取kv_indices - 把当前这条请求更新到Radix Cache (
insert()) - finished: 释放这条请求的KV Cache, unfinished: 更新这条请求在req_to_token_pool中的偏移
- finished: 把这条请求的last_node引用计数-1, 标识可以evict, unfinished: 如果开了page, 把req里的last_node 引用计数-1, 把页对齐的last_node 引用计数+1
ChunkCache
对于过长的token请求, 如果在一个batch内处理除了会及其占用显存资源导致显存超限外, 还有可能因为单请求无法并行处理严重影响其他请求的TTFT, 所以有了chunked_prefill这个功能, 主要作用就是将过长请求切分成多个chunk分别进行处理
sglang的实现在同一时期只能有一个请求在chunk, 而chunk请求在处理时和其他请求的不同点在于: 当前chunk在进行attention计算时, 需要依赖此前的chunk计算的kvcache. 如下图:
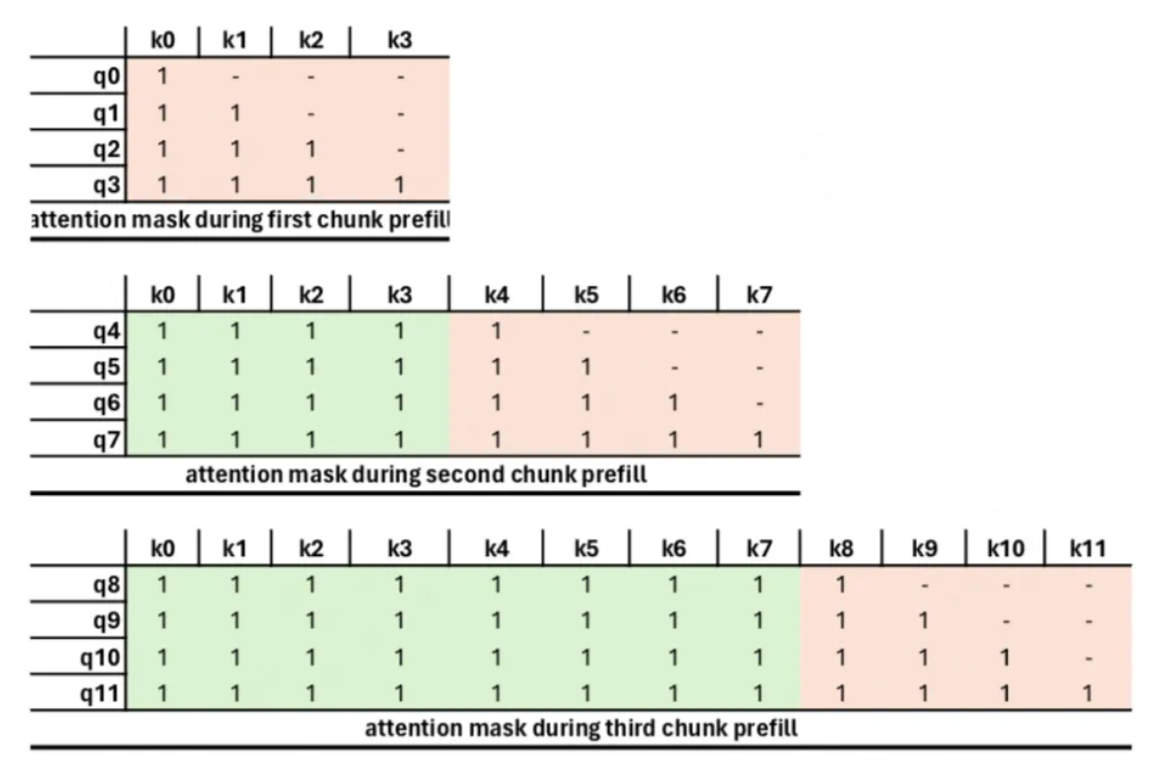
因此就有ChunkCache这么个东西, 专门用来处理图中绿色部分的kvcache.
cache_unfinished_req: 把没处理完的req当前chunk的显存池的偏移量取出来, 塞到prefix_indices里用于下一个chunkReq的构建.
cache_finished_req: 把当前chunk和之前的prefix chunk kvcache直接全部free掉
PD分离,KVCache通信
相关代码在python/sglang/srt/disaggregation中. 包括5种class:
TransferBackend: 枚举类, 用于记录server_args指定的kvTransfer后端, 把不同的KVCache通信后端封装到相同的接口内方便框架兼容(mooncake/nixl)BaseKVManager: 抽象类接口, 每个后端自己实现. 管理KV通信线程, 以及P和D的连接关系. 绑定ZMQ用于D节点和P节点的TCP通信. P节点有两个ZMQ监听线程(Bootstrap和transfer), D节点只有一个decode线程.BaseKVBootstrapServer: 抽象类接口, 每个后端自己实现. 用于P节点接收 D节点alloc完成后发送的Notify请求. 在这个类中起一个新线程, 通过event_loop监听一个端口接收请求.KVSender: 抽象类接口, 用于P节点的请求发送(send接口)和状态查询(poll)KVReceiver: 抽象类接口, 用于D节点的请求接收(recv接口)和状态查询(poll)
注意在代码中会看到除了KV本身还有一类叫aux data, 是 auxiliary 的缩写,表示"辅助数据", 比如位置编码、mask、attention map、LoRA 相关参数等.
通信步骤
建立连接
-
P节点注册自身信息到
MooncakeKVBootstrapServer- 每个P 节点启动时,会通过 HTTP PUT 请求,把自己的 rank_ip、rank_port等信息注册到 bootstrap server。
- bootstrap server 会把这些信息按 DP/TP 分组存入prefill_port_table,以便后续 decode 查询
-
D节点查询需要连接的P节点
- D节点初始化时,会根据自己的 engine_rank、dp_group 等参数,通过 HTTP GET 请求向 bootstrap server 查询自己应该连接的 P 节点信息
_get_bootstrap_info_from_server - 查询参数为 engine_rank 和 target_dp_group,bootstrap server 返回对应 P节点的 IP 和端口
- D节点初始化时,会根据自己的 engine_rank、dp_group 等参数,通过 HTTP GET 请求向 bootstrap server 查询自己应该连接的 P 节点信息
-
D节点拿到P节点的 IP/端口后,通过 ZeroMQ 建立 socket 连接, 然后把自己的KVCache相关信息通过 ZeroMQ 发送给P节点(KVReceiver里init方法),完成后续的数据同步和传输
发送数据
python
def _init_kv_manager(self) -> BaseKVManager:
kv_args = KVArgs()
kv_args.engine_rank = self.tp_rank
kv_data_ptrs, kv_data_lens, kv_item_lens = ( #从显存池里拿到token KV Value的起始地址
self.token_to_kv_pool.get_contiguous_buf_infos()
)
kv_args.kv_data_ptrs = kv_data_ptrs #把这个显存地址传到BaseKVManager里用于初始化
kv_args.kv_data_lens = kv_data_lens #从而在send的时候只传kv_indices, TranferEngine也能知道从哪里取出kv value
kv_args.kv_item_lens = kv_item_lens
#...- P节点从bootstrap队列拿出已经变成WaitForInput状态的请求, 即到达下图的Notify收到的状态. 初始化
req.disagg_kv_sender - 完成forward后, 通过
send_kv_chunk->disagg_kv_sender.send()函数把kv_indicescopy到内存添加到通信队列里. - tranfer异步线程从队列里取KVCache索引,
send_kvcache,group_concurrent_contiguous先把连续的内存块进行切分. 根据每个layer从线程池里取一个独立的线程进行并发通信, 最后等所有layer完成通信. (engine.transfer_sync 调用的是mooncake的内部方法, 需要后续细看mooncake代码, 记个TODO)
接收数据
之前在notify的时候把D节点要接收的显存地址也传过去了, 通过TransferEngine直接完成从显存到显存的copy.
P节点在通信完成后调用sync_status_to_decode_endpoint, 通过ZMQ告知D节点完成传输
D节点的start_decode_thread在收到传输完成通知后, 更新status. 这样就完成了KVCache的整体传输
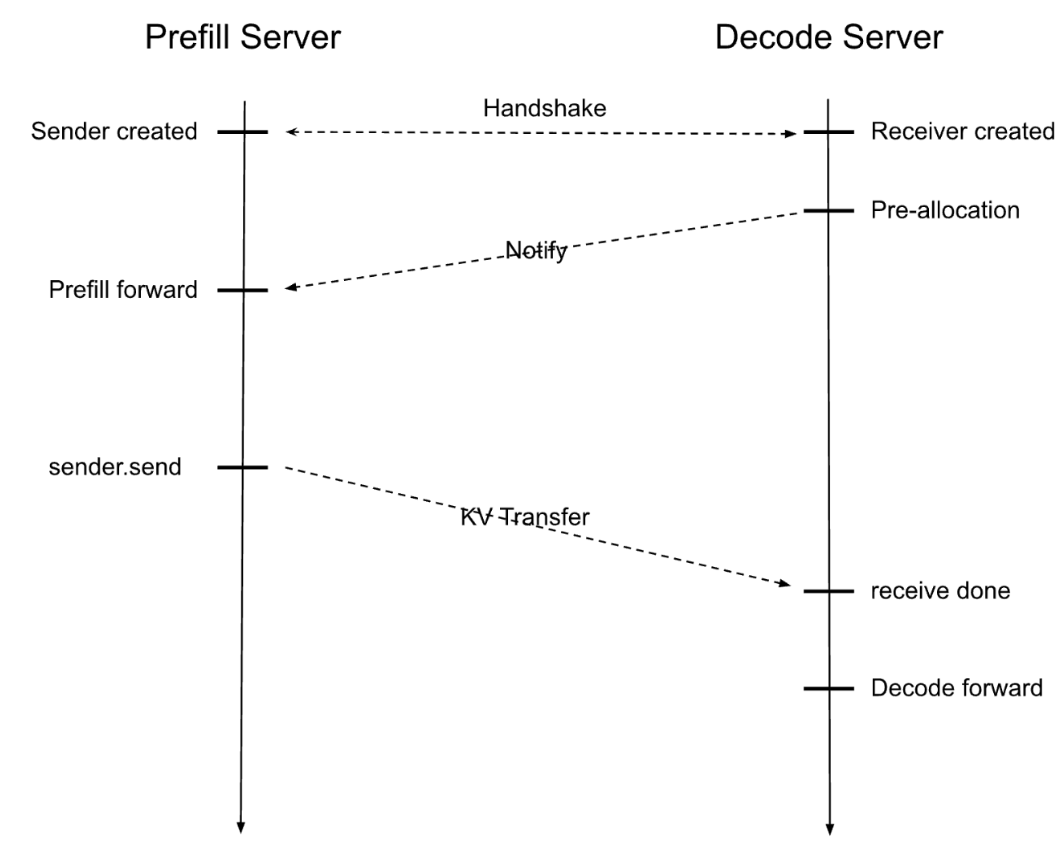
参考: https://zhuanlan.zhihu.com/p/31160183506
Sglang kvcache code walkThrough: https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/main/sglang/kvcache-code-walk-through/readme-CN.md
MLA细节解析: https://zhuanlan.zhihu.com/p/19585986234
RadixAttenion解析: https://zhuanlan.zhihu.com/p/693556044