1.简介
LSNet(Large-Small Network)是一种新型的轻量级视觉网络,旨在通过高效的感知和聚合策略实现高性能与低计算成本的平衡。它受到人类视觉系统"看大,聚焦小"策略的启发,提出了一种结合大核感知(Large-Kernel Perception, LKP)和小核聚合(Small-Kernel Aggregation, SKA)的LS卷积操作。通过这种独特的设计,LSNet能够高效地捕获广泛的上下文信息,并对小范围内的特征进行精细聚合,从而在多种视觉任务中展现出卓越的性能和效率。
-
LS卷积:LS卷积是LSNet的核心操作,通过大核感知和小核聚合相结合的方式,模拟人类视觉系统的动态异尺度视觉能力。大核感知利用大核深度可分离卷积捕获广泛的上下文信息,而小核聚合则通过动态卷积对小范围内的特征进行精细聚合。
-
轻量级设计:LSNet基于LS卷积构建,通过深度可分离卷积和分组机制,显著降低了计算复杂度,使其适用于实时应用和移动设备。
-
高效感知与聚合:LS卷积通过异尺度上下文信息的利用,提高了模型对复杂视觉场景的理解能力,同时保持了高效的计算性能。
LSNet在多个视觉任务中表现出色,包括图像分类、目标检测、实例分割和语义分割。在ImageNet-1K数据集上,LSNet达到了与现有轻量级模型相比更高的准确率和更快的推理速度。此外,在COCO和ADE20K数据集上,LSNet也展现了优越的性能和效率。
github地址:GitHub - THU-MIG/lsnet: LSNet: See Large, Focus Small CVPR 2025
论文地址:2503.23135 LSNet: See Large, Focus Small
权重地址:https://huggingface.co/jameslahm/lsnet/tree/main
2.论文
视觉网络设计一直是计算机视觉领域的研究重点,其中卷积神经网络(CNNs)和视觉变换器(ViTs)在多种计算机视觉任务中取得了显著进展。然而,这些网络通常计算成本高昂,对实际部署尤其是实时应用构成了挑战。
-
自注意力机制:虽然能够进行全局感知和聚合,但容易在不重要的区域引入过多注意力,导致计算复杂度高,且感知和聚合范围固定,难以在低计算预算下扩展上下文。
-
卷积:虽然计算效率高,但缺乏对不同上下文的敏感性,限制了模型的表达能力。
受人类视觉系统的启发,提出一种新的轻量级视觉网络设计策略,通过大核感知和小核聚合来高效捕获视觉信息。作者设计了一种新的LS(Large-Small)卷积操作,结合大核感知和小核聚合,能够在有限的计算成本下实现高效的感知和聚合。基于LS卷积,提出了一种新的轻量级模型家族LSNet。通过广泛的实验验证,LSNet在多种视觉任务中表现出色,优于现有的轻量级网络。
回顾自注意力和卷积
自注意力通过计算输入特征图中每个token与全局特征图的成对相关性来获得注意力分数,这些分数经过softmax归一化处理。然后通过加权求和的方式聚合特征,权重由注意力分数决定。公式表示为:
卷积利用输入特征图中token的相对位置关系来建模局部上下文信息。然后通过卷积操作聚合特征,权重由卷积核决定。
其中
自注意力和卷积的对比:
-
自注意力能够进行全局感知和聚合,但计算复杂度高,且在不重要的区域引入过多注意力。
-
卷积能够高效地进行局部感知和聚合,但感知范围有限,缺乏对不同上下文的适应性。
LS卷积通过结合大核感知和小核聚合,旨在克服这两种机制的局限性,实现更高效和有效的token混合。
LS (Large-Small) Convolution
人类视觉系统具有动态异尺度视觉能力,能够"看大"(通过周边视觉感知广阔场景)和"聚焦小"(通过中央视觉对特定元素进行详细理解)。这种能力使得人类能够高效地处理视觉信息。
LS卷积旨在模拟人类视觉系统的"看大,聚焦小"策略,通过大核感知和小核聚合来高效地捕获视觉信息。
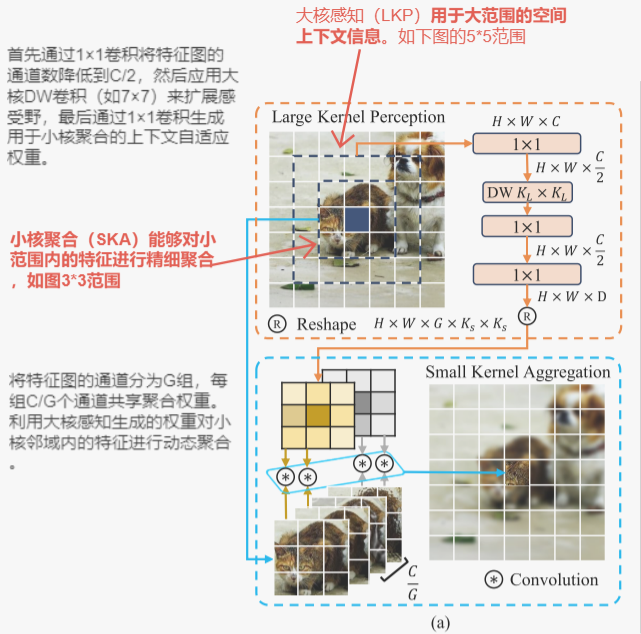
大核感知(LKP) :捕获大范围的空间上下文信息。类似于人类的周边视觉系统。
- 过程:首先通过1×1卷积将特征图的通道数降低到C/2,然后应用大核DW卷积(如7×7)来扩展感受野,最后通过1×1卷积生成用于小核聚合的上下文自适应权重。
小核聚合(SKA) :类似于人类的中央视觉系统,能够对小范围内的特征进行精细聚合,捕获复杂的视觉模式。
-
过程 :将特征图的通道分为G组,每组C/G个通道共享聚合权重。利用大核感知生成的权重对小核邻域内的特征进行动态聚合。使用小核动态卷积(如3×3)进行特征聚合,通过分组机制减少计算成本。
说白了:SKA是将LKP生成的特征图变成卷积核,来给图片做卷积操作。 -
关键区别:SKA使用的卷积核权重 W 是基于输入特征图的上下文信息动态生成的,而不是固定的卷积核。这些权重反映了输入特征图中不同位置之间的关系。
通过大核感知和小核聚合,LS卷积能够同时利用大范围和小范围的上下文信息,提高模型对复杂视觉场景的理解能力。
复杂性分析 。LS卷积的计算主要包含三个部分:在中的逐点卷积,核大小为
的深度卷积,以及在
中核大小为
的卷积聚合。它们对应的计算分别为
、
和
。因此,总的计算量为
,相对于输入分辨率,LSNet享有线性计算复杂度。
LSNet
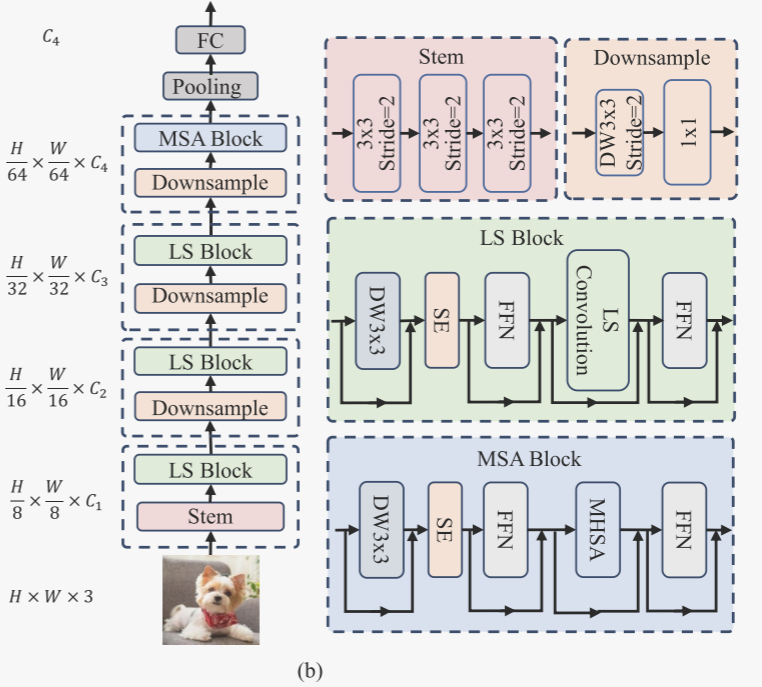
LSNet是一种新型的轻量级视觉网络,基于LS卷积(Large-Small Convolution)构建。LS卷积通过结合大核感知(LKP)和小核聚合(SKA),能够在有限的计算成本下高效地捕获广泛的上下文信息,并对小范围内的特征进行精细聚合。LSNet的设计目标是在保持高效计算的同时,提升模型对复杂视觉信息的处理能力。
LSNet的整体架构采用多阶段设计,包含四个阶段,每个阶段对应不同的空间分辨率和通道数。输入图像首先通过重叠patch embedding投影到视觉特征图,然后通过深度可分离卷积和点卷积(PW卷积)的结合进行下采样,降低空间分辨率并调整通道维度。前三个阶段堆叠了多个LS块以增强特征提取能力,而最后一个阶段则使用多头自注意力(MSA)模块捕捉长距离依赖关系,适用于低分辨率特征图。
实验
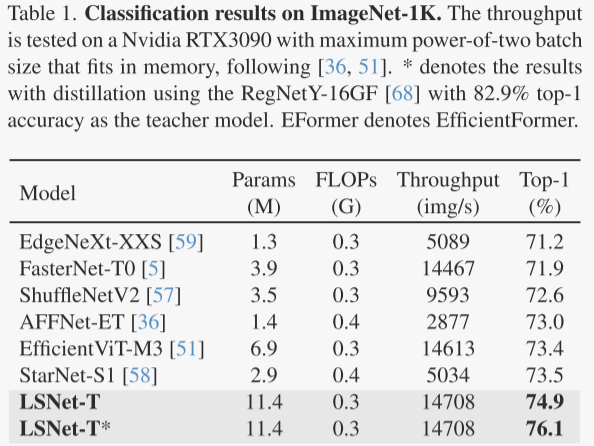
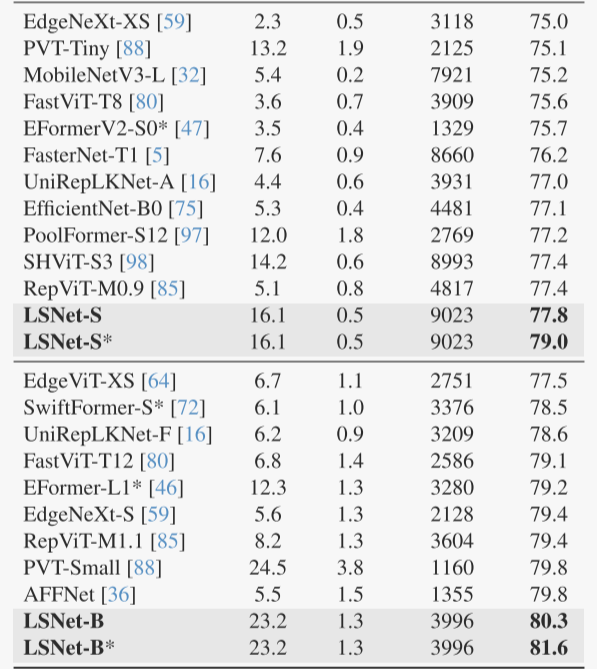
首先,在图像分类任务中,LSNet在ImageNet-1K数据集上展现了卓越的表现,不同变体(LSNet-T、LSNet-S和LSNet-B)均在各自的计算成本下实现了高准确率,并且在推理速度上优于现有的轻量级模型,例如AFFNet、RepViT-M1.1和FastViT等。这表明LSNet在保持高效计算的同时,能够有效地处理复杂的视觉信息。
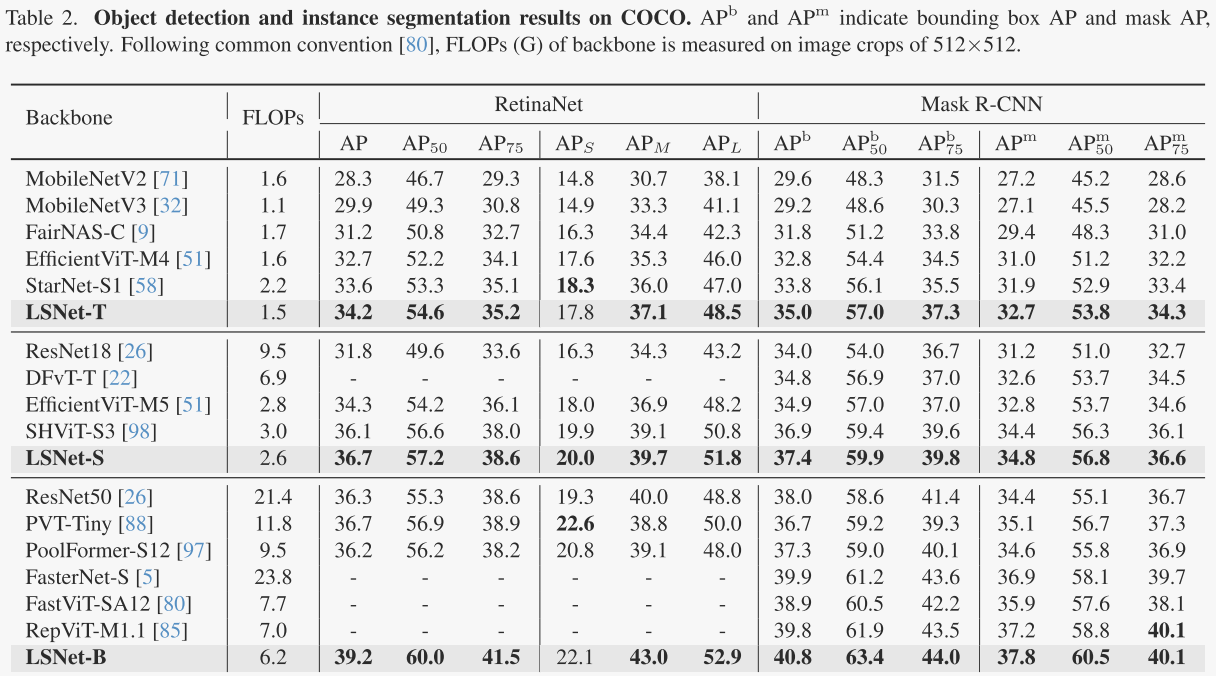
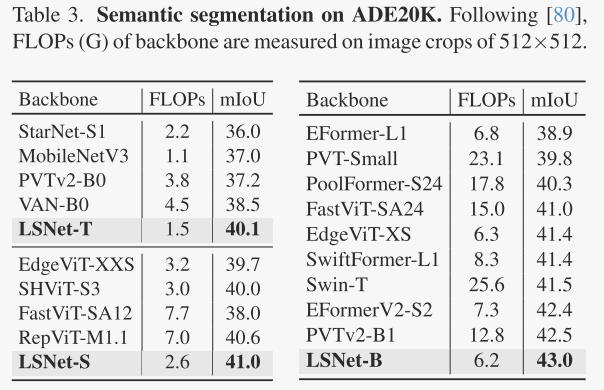
在下游任务中,LSNet进一步证明了其泛化能力。在目标检测和实例分割任务中,LSNet与RetinaNet和Mask R-CNN框架结合,在COCO-2017数据集上取得了显著优于其他轻量级模型的性能。例如,LSNet-T在RetinaNet框架下不仅提高了平均精度(AP),还降低了计算成本。在语义分割任务中,LSNet与Semantic FPN结合,在ADE20K数据集上也展现了优越的性能,不同变体均在低计算成本下实现了高mIoU值,这进一步证明了LSNet在处理像素级任务时的有效性。
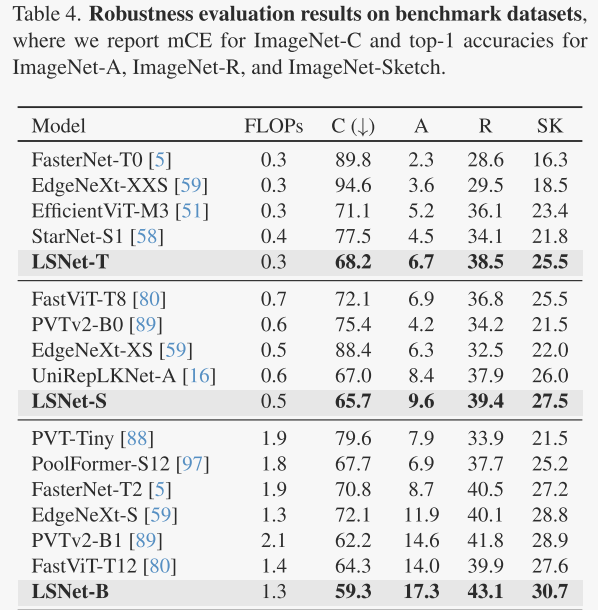
 此外,LSNet在鲁棒性评估中也表现出色。在多个基准数据集(如ImageNet-C、ImageNet-A、ImageNet-R和ImageNet-Sketch)上,LSNet展现了强大的泛化能力和对不同数据分布的适应性。LSNet-B在这些数据集上均取得了优异的性能,与现有模型相比,在鲁棒性方面表现突出。
此外,LSNet在鲁棒性评估中也表现出色。在多个基准数据集(如ImageNet-C、ImageNet-A、ImageNet-R和ImageNet-Sketch)上,LSNet展现了强大的泛化能力和对不同数据分布的适应性。LSNet-B在这些数据集上均取得了优异的性能,与现有模型相比,在鲁棒性方面表现突出。
实验结果充分证明了LSNet作为一种新型轻量级视觉网络,在多种视觉任务中的高效性和有效性。LSNet的设计不仅在计算成本上实现了优化,还在性能上达到了新的高度,为轻量级视觉网络的发展提供了新的方向。
3.代码详解
LSConv
LSConv模块的定义如下:
python
class LSConv(nn.Module):
def __init__(self, dim):
super(LSConv, self).__init__()
self.lkp = LKP(dim, lks=7, sks=3, groups=8) # LKP
self.ska = SKA() # SPA
self.bn = nn.BatchNorm2d(dim)
def forward(self, x):
return self.bn(self.ska(x, self.lkp(x))) + x其中,LKP模块如下:
python
class LKP(nn.Module):
def __init__(self, dim, lks, sks, groups):
super().__init__()
self.cv1 = Conv2d_BN(dim, dim // 2)
self.act = nn.ReLU()
self.cv2 = Conv2d_BN(dim // 2, dim // 2, ks=lks, pad=(lks - 1) // 2, groups=dim // 2)
self.cv3 = Conv2d_BN(dim // 2, dim // 2)
self.cv4 = nn.Conv2d(dim // 2, sks ** 2 * dim // groups, kernel_size=1)
self.norm = nn.GroupNorm(num_groups=dim // groups, num_channels=sks ** 2 * dim // groups)
self.sks = sks
self.groups = groups
self.dim = dim
def forward(self, x):
x = self.act(self.cv3(self.cv2(self.act(self.cv1(x))))) # 输入 x 经过一系列卷积层(cv1 → 激活函数 act → cv2 → cv3)提取特征
w = self.norm(self.cv4(x)) # 输出特征再通过 cv4 卷积和归一化层 norm 生成权重张量 w
b, _, h, width = w.size()
w = w.view(b, self.dim // self.groups, self.sks ** 2, h, width) # 将 w 张量 reshape 成分组卷积所需的形状
return w其中SKA模块的定义如下:这段代码定义了一个 高效的空间注意力机制或动态卷积操作,它使用了 PyTorch 的自定义 Function 和 Triton 加速的 CUDA 内核来实现高性能前向与反向传播。
python
class SkaFn(Function):
@staticmethod
@custom_fwd(device_type='cuda')
def forward(ctx, x: torch.Tensor, w: torch.Tensor) -> torch.Tensor:
ks = int(math.sqrt(w.shape[2])) # 卷积核大小 ks
pad = (ks - 1) // 2 # 卷积核填充 pad
ctx.ks, ctx.pad = ks, pad # 将非张量的信息(例如卷积核大小 ks、填充 pad)直接作为属性赋值给 ctx
n, ic, h, width = x.shape
wc = w.shape[1]
o = torch.empty(n, ic, h, width, device=x.device, dtype=x.dtype) # 准备输出张量 o
numel = o.numel() # 返回张量(tensor)中的元素总数。
x = x.contiguous() # 保证输入张量的连续内存
w = w.contiguous()
grid = lambda meta: _grid(numel, meta["BS"]) # 定义网格函数 grid 用于 Triton 内核调度
# 根据输入数据类型选择 Triton 中的计算类型 ct 和累加类型 at
ct = tl.float16 if x.dtype == torch.float16 else (tl.float32 if x.dtype == torch.float32 else tl.float64)
at = tl.float32 if x.dtype == torch.float16 else ct
ska_fwd[grid](x, w, o, n, ic, h, width, ks, pad, wc, BS=1024, CT=ct, AT=at) # 调用 Triton 内核执行卷积操作
ctx.save_for_backward(x, w) # 保存上下文信息用于反向传播
ctx.ct, ctx.at = ct, at
return o
@staticmethod
@custom_bwd(device_type='cuda')
def backward(ctx, go: torch.Tensor) -> tuple:
ks, pad = ctx.ks, ctx.pad
x, w = ctx.saved_tensors
n, ic, h, width = x.shape
wc = w.shape[1]
go = go.contiguous()
gx = gw = None
ct, at = ctx.ct, ctx.at
if ctx.needs_input_grad[0]: # 使用 ska_bwd_x 计算输入 x 的梯度
gx = torch.empty_like(x)
numel = gx.numel()
ska_bwd_x[lambda meta: _grid(numel, meta["BS"])](go, w, gx, n, ic, h, width, ks, pad, wc, BS=1024, CT=ct, AT=at)
if ctx.needs_input_grad[1]: # 使用 ska_bwd_w 计算权重 w 的梯度
gw = torch.empty_like(w)
numel = gw.numel() // w.shape[2]
ska_bwd_w[lambda meta: _grid(numel, meta["BS"])](go, x, gw, n, wc, h, width, ic, ks, pad, BS=1024, CT=ct, AT=at)
return gx, gw, None, None
class SKA(torch.nn.Module):
def forward(self, x: torch.Tensor, w: torch.Tensor) -> torch.Tensor:
return SkaFn.apply(x, w) # type: ignore在反向传播backward()中:
1.获取前向信息:
python
ks, pad = ctx.ks, ctx.pad
x, w = ctx.saved_tensors
ct, at = ctx.ct, ctx.at- 对
x的梯度计算:调用ska_bwd_x计算输入x的梯度。
python
if ctx.needs_input_grad[0]:
gx = torch.empty_like(x)
ska_bwd_x[grid](go, w, gx, ...)- 对
w的梯度计算: 调用ska_bwd_w计算权重w的梯度。
python
if ctx.needs_input_grad[1]:
gw = torch.empty_like(w)
ska_bwd_w[grid](go, x, gw, ...)- 返回梯度:仅对
x和w求梯度,其余参数无梯度需求。
python
return gx, gw, None, NoneCUDA内核
这段代码是使用 Triton 编写的三个核心 CUDA 内核函数,分别用于实现:
- 前向传播 (
ska_fwd) - 对输入
x的反向梯度 (ska_bwd_x) - 对权重
w的反向梯度 (ska_bwd_w)
这些内核实现了一个高效、可微分的 局部空间注意力机制(或动态卷积)。
python
@triton.jit
def ska_fwd(
x_ptr, w_ptr, o_ptr,
n, ic, h, w, ks, pad, wc,
BS: tl.constexpr,
CT: tl.constexpr, AT: tl.constexpr
): # 实现了一个基于 Triton 的卷积前向计算 kernel
pid = tl.program_id(0)
start = pid * BS
offs = start + tl.arange(0, BS)
ni, ci, hi, wi, m = _idx(offs, n, ic, h, w) # 通过 _idx 函数将一维偏移量 offs 转换为 (ni, ci, hi, wi) 四维索引,并判断是否在有效范围内 m。
val = tl.zeros((BS,), dtype=AT)
for kh in range(ks):
hin = hi - pad + kh
hb = (hin >= 0) & (hin < h)
for kw in range(ks):
win = wi - pad + kw
b = hb & (win >= 0) & (win < w) # 对卷积核的每个位置 (kh, kw),计算输入图像中对应的坐标 (hin, win) 并判断是否越界。
# 内存寻址计算
x_off = ((ni * ic + ci) * h + hin) * w + win
w_off = ((ni * wc + ci % wc) * ks * ks + (kh * ks + kw)) * h * w + hi * w + wi
x_val = tl.load(x_ptr + x_off, mask=m & b, other=0.0).to(CT)
w_val = tl.load(w_ptr + w_off, mask=m, other=0.0).to(CT)
val += tl.where(b & m, x_val * w_val, 0.0).to(AT) # 根据掩码加载输入和权重值,进行乘法累加运算,结果保存在 val 中
tl.store(o_ptr + offs, val.to(CT), mask=m) # 将计算结果 val 写回到输出指针 o_ptr 指定的位置。
@triton.jit
def ska_bwd_x(
go_ptr, w_ptr, gi_ptr,
n, ic, h, w, ks, pad, wc,
BS: tl.constexpr,
CT: tl.constexpr, AT: tl.constexpr
): # 卷积层的反向传播对输入的梯度计算(dx)
pid = tl.program_id(0)
start = pid * BS
offs = start + tl.arange(0, BS)
ni, ci, hi, wi, m = _idx(offs, n, ic, h, w) # 将一维偏移量转换为对应的四维张量索引 (n, c, h, w);
val = tl.zeros((BS,), dtype=AT)
for kh in range(ks):
ho = hi + pad - kh # 计算经过填充后在原始输入上的有效位置
hb = (ho >= 0) & (ho < h)
for kw in range(ks):
wo = wi + pad - kw
b = hb & (wo >= 0) & (wo < w)
# 分别计算输出梯度和权重的内存偏移
go_off = ((ni * ic + ci) * h + ho) * w + wo
w_off = ((ni * wc + ci % wc) * ks * ks + (kh * ks + kw)) * h * w + ho * w + wo
go_val = tl.load(go_ptr + go_off, mask=m & b, other=0.0).to(CT)
w_val = tl.load(w_ptr + w_off, mask=m, other=0.0).to(CT)
val += tl.where(b & m, go_val * w_val, 0.0).to(AT) # 通过遍历卷积核窗口累加梯度
tl.store(gi_ptr + offs, val.to(CT), mask=m) # 将结果写回输入梯度内存
@triton.jit
def ska_bwd_w(
go_ptr, x_ptr, gw_ptr,
n, wc, h, w, ic, ks, pad,
BS: tl.constexpr,
CT: tl.constexpr, AT: tl.constexpr
): # 卷积操作的权重梯度反向传播
pid = tl.program_id(0) # 使用Triton按程序ID划分线程块处理的数据范围。
start = pid * BS
offs = start + tl.arange(0, BS)
ni, ci, hi, wi, m = _idx(offs, n, wc, h, w) # 将一维偏移转换为四维索引
for kh in range(ks): # 遍历卷积核的每个位置 (kh, kw),并计算输入图像中对应的填充后的位置 (hin, win)。
hin = hi - pad + kh
hb = (hin >= 0) & (hin < h) # 计算卷积核窗口在原始输入上的有效位置
for kw in range(ks):
win = wi - pad + kw
b = hb & (win >= 0) & (win < w)
w_off = ((ni * wc + ci) * ks * ks + (kh * ks + kw)) * h * w + hi * w + wi
val = tl.zeros((BS,), dtype=AT)
steps = (ic - ci + wc - 1) // wc
for s in range(tl.max(steps, axis=0)):
cc = ci + s * wc
cm = (cc < ic) & m & b
x_off = ((ni * ic + cc) * h + hin) * w + win
go_off = ((ni * ic + cc) * h + hi) * w + wi
x_val = tl.load(x_ptr + x_off, mask=cm, other=0.0).to(CT)
go_val = tl.load(go_ptr + go_off, mask=cm, other=0.0).to(CT)
val += tl.where(cm, x_val * go_val, 0.0).to(AT) # 将输入与输出梯度相乘累加到 val 中
tl.store(gw_ptr + w_off, val.to(CT), mask=m) # 将计算出的权重梯度写入 gw_ptr下面我们来逐个解析每个 kernel 的逻辑,并总结其整体功能与意义。
ska_fwd()
线程划分:
- 每个线程块处理
BS(block size)个输出元素。 - 使用
pid确定当前线程块负责的起始位置。
python
def ska_fwd(...):
pid = tl.program_id(0)
start = pid * BS
offs = start + tl.arange(0, BS)索引转换:
- 将一维偏移
offs转换为(n, c, h, w)四维索引。 m是掩码,表示该索引是否在有效范围内。
python
ni, ci, hi, wi, m = _idx(offs, n, ic, h, w)局部感受野遍历:
- 遍历大小为
ks x ks的局部窗口。 - 判断坐标是否越界,生成掩码
b。
python
for kh in range(ks):
hin = hi - pad + kh
hb = (hin >= 0) & (hin < h)
for kw in range(ks):
win = wi - pad + kw
b = hb & (win >= 0) & (win < w)内存寻址计算:
- 计算输入
x和权重w的内存地址偏移。 - 权重
w按照空间位置(kh, kw)和输出位置(hi, wi)存储。
python
x_off = ((ni * ic + ci) * h + hin) * w + win
w_off = ((ni * wc + ci % wc) * ks * ks + (kh * ks + kw)) * h * w + hi * w + wi加载数据并计算:
- 加载
x和w的值。 - 相乘后累加到输出
val中。
python
x_val = tl.load(x_ptr + x_off, mask=m & b, other=0.0).to(CT)
w_val = tl.load(w_ptr + w_off, mask=m, other=0.0).to(CT)
val += tl.where(b & m, x_val * w_val, 0.0).to(AT)写回结果:
python
tl.store(o_ptr + offs, val.to(CT), mask=m)ska_bwd_x()
**关键点:**卷积核的翻转操作,这是在进行卷积转置(transpose convolution)操作,即反向传播中常见的"翻转卷积核"。
python
ho = hi + pad - kh
wo = wi + pad - kwska_bwd_w()
通过局部窗口遍历完成梯度计算:
python
hin = hi - pad + kh
win = wi - pad + kw多通道聚合:
- 对于每个通道组
wc,遍历所有输入通道ic。 - 计算
x * go,并将结果累加到对应权重w的位置上。
python
steps = (ic - ci + wc - 1) // wc
for s in range(tl.max(steps, axis=0)):
cc = ci + s * wc
cm = (cc < ic) & m & b
...
x_val * go_val → val写回权重梯度:
python
tl.store(gw_ptr + w_off, val.to(CT), mask=m)4.总结
本文提出了一种新型的轻量级视觉网络架构------LSNet(Large-Small Network),旨在通过高效的感知和聚合策略,在有限的计算成本下实现高性能的视觉信息处理。LSNet的设计灵感来源于人类视觉系统的"看大,聚焦小"策略,通过结合大核感知(Large-Kernel Perception, LKP)和小核聚合(Small-Kernel Aggregation, SKA)的LS卷积操作,实现了对广泛上下文信息的高效捕获和对小范围特征的精细聚合。
LS卷积是LSNet的核心操作,通过以下两个步骤实现高效的感知和聚合:
-
大核感知(LKP):利用大核深度可分离卷积捕获广泛的上下文信息,生成用于小核聚合的权重。
-
小核聚合(SKA):通过动态卷积对小范围内的特征进行聚合,利用分组机制降低计算成本,同时保持对不同上下文的适应性。
LS卷积的设计不仅保留了卷积的高效性,还通过动态权重引入了对不同上下文的适应性,显著提高了模型的表达能力和性能。
通过广泛的实验,LSNet在多种视觉任务中展现了优异的性能和效率。LSNet作为一种新型轻量级视觉网络,通过结合大核感知和小核聚合的LS卷积操作,在多种视觉任务中实现了高性能和高效率的平衡。其设计不仅在计算成本上进行了优化,还在性能上达到了新的高度,为轻量级视觉网络的发展提供了新的方向。
在信息的海洋里,每一次点赞都是对我努力的认可,每一次收藏都是对我内容的肯定,每一次关注都是对我持续创作的支持!您的支持是我不断前进的动力,您的鼓励是我不断进步的源泉。感谢您的阅读,希望我的内容能为您带来价值!如果您喜欢,请不吝点赞、收藏和关注,让我们共同成长,一起探索更多知识的奥秘!