25年5月来自 CMU 的论文"DexWild: Dexterous Human Interactions for In-the-Wild Robot Policies"。
大规模、多样化的机器人数据集已成为将灵巧操作策略泛化到新环境的一条有效途径,但获取此类数据集面临诸多挑战。虽然遥操作可以提供高保真度的数据集,但其高昂的成本限制了其可扩展性。如果人们能够像在日常生活中一样用自己的双手来收集数据,情况会怎样?在 DexWild 中,一个由多元化数据收集人员组成的团队用双手收集了跨越众多环境和物体的数小时交互数据。为了记录这些数据,创建 DexWild 系统,这是一款低成本、移动且易于使用的设备。DexWild 学习框架基于人类和机器人的演示进行协同训练,与单独训练每个数据集相比,其性能有所提升。这种组合能够生成强大的机器人策略,使其能够以最少的额外机器人特定数据泛化到新的环境、任务和具身中。
模仿学习的泛化
机器人操作的泛化策略学习取得了快速进展,这主要得益于视觉表征学习和大规模数据集模仿学习的进步。在视觉方面,具身表征学习受益于以自我为中心的数据集,例如 Ego4D 15 和 EPIC-KITCHENS 10,最近的方法 27, 11, 47, 39 利用这些数据集来训练可扩展的视觉编码器。然而,这些方法仍然需要大量的下游机器人演示来训练控制策略。
与此同时,仅限机器人的演示数据集在规模和多样性方面也显著增长 21, 8, 54,这推动了行为克隆的研究,并促成了泛化策略架构的构建 49, 8, 22。虽然这些策略在许多任务中表现出色,但它们往往难以泛化到未知的目标类别、场景布局或环境条件 25。这种鲁棒性的缺乏仍然是当前系统的一个关键限制。
机器人操作的数据生成
克服机器人数据瓶颈已成为机器人学习的核心挑战。一种方法是利用互联网视频提取动作信息。一些研究,例如 VideoDex 40 和 HOP 42,利用大规模真人视频通过重定向学习动作先验,并以此引导策略训练。其他研究,例如 LAPA 57,则使用未标记的视频生成可用于下游任务的潜动作表征。虽然这些基于视频的方案拥有丰富的视觉多样性,但它们通常无法捕捉现实世界操作所需的精确、低级运动指令。
模拟能够快速生成大规模动作数据。然而,为许多任务创建多样化、逼真的环境并解决模拟与现实之间的差距是一项挑战。近期在将操作策略从模拟 43 迁移方面取得的成功仅限于桌面环境,缺乏在不同环境中部署所需的泛化能力。
在实体机器人上进行直接遥操作可以获得最高的保真度,但扩展性较差。最近的研究已在固定场景中展现出令人印象深刻的灵活性和高效的学习能力 59, 56, 41, 19,然而,收集足够多的演示样本以推广到不同场景的成本很快就会变得高昂。
最近,越来越多的研究利用有针对性地收集的高质量人体具身数据,而无需繁琐的遥操作。
人体动作追踪系统
为了获取高质量的人体运动数据,准确的手部和腕部追踪至关重要。为了规避手势估计的复杂性,一些研究为用户配备手持式机器人夹持器 7, 12, 46。虽然这种方法简化重定向操作,但它将用户限制在机器人夹持器的特定形态上,从而限制捕获行为的多样性。此外,许多此类系统依赖于基于 SLAM 的腕部追踪,这在特征稀疏的环境中或出现遮挡时可能会失效 7, 23------例如在打开抽屉或使用工具时。
其他方法旨在直接根据视觉输入估计手部和腕部姿势 29, 35, 5, 45, 28, 20, 32。这些方法易于部署且无需仪器,但在遮挡(操作过程中不可避免的情况)的情况下,其性能会显著下降。其他腕部追踪策略,例如基于 IMU 的 9, 50 和由外向内的光学系统 30,也各有局限性:IMU 轻巧便携但容易漂移;光学系统精准,但需要繁琐的标定和受控环境。
DexWild 利用无需标定的 Aruco 追踪技术,显著提高了可靠性并最大限度地缩短了设置时间,因为它只需要一个单目摄像头。
虽然基于视觉的方法通常尝试同时追踪腕部和手指,但许多近期系统将两者分离以提高准确性。运动外骨骼手套可以提供高保真关节测量甚至触觉反馈 58,但体积庞大,长期佩戴不舒适。
相反,DexWild 与先前的研究 41, 55 一样,采用了一种基于轻量级手套的解决方案,该方案利用电磁场 (EMF) 感应来估计指尖位置。这可以实现准确、实时的手部追踪,并且对遮挡具有鲁棒性,并且可以轻松地重定位到各种机械手上。
许多人认为,利用海量高质量数据集是创建具有泛化能力的灵巧机器人策略的关键 8, 49, 40, 11。DexWild 系统是一个用户友好、高保真度的平台,用于高效地收集各种真实世界中的自然人手演示。与传统的基于遥操作方法相比,DexWild 系统的数据采集速度提高了 4.6 倍。
在此系统的基础上,DexWild,一个模仿学习框架,基于大规模 DexWild 系统的人类演示和少量机器人演示进行协同训练。这种方法将人类交互的多样性和丰富性与机器人实例的扎实基础相结合,使策略能够稳健地泛化到新目标、环境和实例中。如图展示DexWild 方法:

数据收集系统
一个可扩展的灵巧机器人学习数据收集系统必须能够在各种环境中进行自然、高效和高保真度的收集。为此,DexWild-System,作为一款便携、用户友好的系统,只需极少的设置和训练即可捕捉人类的灵巧行为。以往的野外数据收集方法通常依赖于带传感器的抓取器,而本文目标是创建一个更直观的硬件界面,以真实还原人类与世界自然互动的方式。从精细的精细动作到强大的抓握,人类在各种操控任务中都拥有灵巧的操控能力。通过学习这种内在能力,DexWild-System 能够捕捉丰富多样的数据,适用于各种机器人应用场景。
DexWild-System 的设计围绕三个核心目标:
• 便携性:无需复杂的标定程序,即可在不同环境中快速、大规模地收集数据。
• 高保真度:准确捕捉精细的手部与环境交互,这对于训练精准的灵巧策略至关重要。
• 不依赖具体形态:能够从人类演示无缝重定向到各种机器人手。
可移植性:
为了在各种现实环境中收集数据,系统必须便携、稳定且易于任何人使用。在设计 DexWild 系统时秉持以下目标:它重量轻、易于携带,并且只需几分钟即可完成设置,从而能够在多个地点进行可扩展的数据收集。
如图所示,DexWild 系统仅包含三个组件:用于腕部姿势估计的单追踪摄像头、用于板载数据采集的电池供电微型 PC,以及由动作捕捉手套和同步掌上摄像头组成的定制传感器盒。
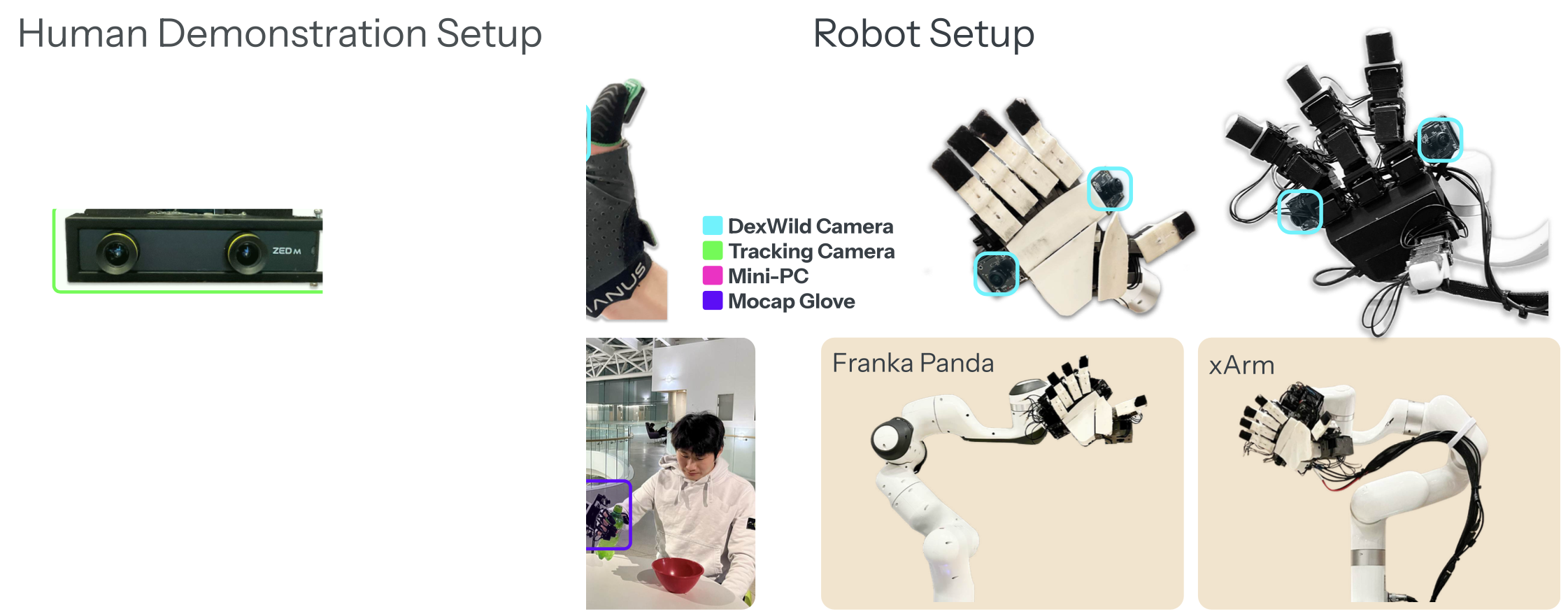
与通常依赖于需要标定、复杂的、由外向内追踪设置的传统动作捕捉系统 60, 13, 4, 52 不同,DexWild 系统真正实现了无需标定,使其适用于任何场景,即使未经培训的操作员也能轻松操作。
这是通过采用相对状态-动作表示来实现的,其中每个状态和动作都被捕获为与前一时间步的姿势的相对差异。这消除了对全局坐标系的任何需求,允许跟踪摄像头自由放置------无论是以自我为中心还是以外部为中心。此外,掌上摄像头在人类和机器人的实体上都牢固地安装在固定位置。这确保了视觉观察在不同域中保持一致,无需在部署时进行进一步标定。外部跟踪摄像头在精心定位后,还可以捕捉有助于学习稳健策略的补充环境信息。
高保真度:
为了学习灵巧的行为,必须在训练数据集中捕捉精细、细微的动作。尽管 DexWild 系统仅包含少量便携式组件,但在数据保真度方面毫不妥协。系统旨在精准捕捉手部和腕部动作,并提供高质量的视觉观测。
对于腕部和手部追踪,纯视觉方法易于设置。然而,它们在便携性方面的优势往往牺牲了准确性和鲁棒性------导致姿势估计噪声较大,从而降低策略学习的效果 41, 14, 32, 7。
对于手部姿势估计,用动作捕捉手套,它具有高精度、低延迟和抗遮挡鲁棒性 41。对于腕部追踪,在手套上安装 ArUco 标记点,并使用外部摄像头进行追踪。这避免了基于 SLAM 腕部追踪的脆弱性,这种追踪在特征稀疏的环境中或在遮挡严重的任务(例如打开抽屉)中经常失败。
与许多依赖于以自我为中心或远距离外部摄像头的数据集不同,在此将两个全局快门摄像头直接放置在手掌上。如上图所示,这些立体双目摄像头能够捕捉到细致的局部交互视图,同时最大程度地减少运动模糊并拥有宽广的视野。这种宽广的视野使得策略能够仅使用板载手掌摄像头进行操作,而无需依赖任何静态视点。
与具身无关:
为了确保 DexWild 数据的持久性和多功能性,在此目标是使其能够在不同的机器人具体形态中保持可用性------即使硬件平台不断发展。实现这一目标需要仔细协调人机之间的观察空间和动作空间。
首先要标准化观察空间。虽然掌上摄像头拥有广阔的视野,但特意将它们定位在主要聚焦于环境的位置,从而最大限度地降低手部本身的可见性。重要的是,摄像头在人手和机器人手上的放置位置是镜像的。如图所示,这种设计在不同具身中产生视觉上一致的观察结果,从而使策略能够学习到一种可在人类和机器人域泛化的共享视觉表征。

对于动作空间对齐,基于先前研究 17, 44 的洞见,优化机器人手的运动学,使其与人类演示中观察到的指尖位置相匹配。这种方法具有通用性,适用于任何机器人手的具身。它在不同用户中使用固定的超参数,并且对手部尺寸的变化具有鲁棒性,无需针对特定用户进行调整。
使用自然人手收集数据除了易于使用之外,还具有其他优势。人类演示者手部形态的多样性带来了有用的变异,这有助于策略学习更具泛化的抓取策略------鉴于人类和机器人手部运动学之间固有的不匹配,这一点尤为重要。
总而言之,DexWild 是一款便携式、高质量、以人为本的系统,任何操作员都可以佩戴,在现实环境中收集人体数据。接下来,将解释如何利用 DexWild 收集的数据,使灵巧策略能够泛化到自然场景中。
训练数据模态与预处理
灵巧操作的泛化需要规模化和具体化基础。为此,DexWild 收集两个互补的数据集:一个使用 DexWild 系统的大规模人类演示数据集 D_H,以及一个规模较小的遥控机器人数据集 D_R。
人类数据具有广泛的任务多样性,并且在现实环境中易于收集,但缺乏具体化一致性。机器人数据虽然规模有限,但却为机器人的动作和观察空间提供了至关重要的基础。为了充分利用两者的优势,用一个批次中固定比例的人类和机器人数据 (w_h, w_r) 共同训练策略------在多样性和具身基础之间取得平衡,从而在部署期间实现稳健的泛化。
在每次训练迭代中,根据共同训练权重分别从 D_H 和 D_R 中采样一个包含转换 x_h 和 x_r 的批次。时间步 i 的每个转换 x_i 包含:
• 观测值 o_i:给定时间步的观测值包含当前时间步捕获的两个同步手掌摄像头图像 I_pinky 和 I_thumb,以及一系列历史状态,这些状态以给定时间范围 H 的步长采样,包含 {∆p_i, ∆p_i−step, ..., ∆p_i−H}。每个 ∆p 包含相对的历史末端执行器位置。
• 动作 a_i:i+n−1:大小为 n 的动作块,包含动作 {a_i, a_i+1, ..., a_i+n−1},其中 a_i 是当前时间步的动作。具体而言,a_i 是一个 26 维向量,包含:
-- a_arm:一个 9 维向量,描述末端执行器相对位置(3D)和方向(6D)。
-- a_hand:一个 17 维向量,描述机器人手的手指关节位置目标。
对于双手任务,观察和动作空间会被复制,并将双手间的姿势附加到观察结果中,以促进协调。
虽然重定向程序将人类和机器人的轨迹带入共享的动作空间,但仍需要一些额外的步骤来使人类和机器人的数据集兼容以进行联合训练:
• 动作规范化:对人类和机器人数据的动作分别进行规范化,以解决固有的分布不匹配问题。
• 演示过滤:由于人类演示是由未经训练的操作员在不受控制的环境中收集的,应用基于启发式的过滤流程来自动检测并移除低质量或无效的轨迹。此过滤步骤无需人工标记即可显著提高数据集质量。
策略训练
通过精心设计硬件、观察和动作接口,能够使用简单的行为克隆 (BC) 目标 31, 37, 36 来训练灵巧机器人策略。为了有效地从多模态、多样化的数据中学习,训练流程利用大规模预训练的视觉编码器,并在不同的策略架构中展现出强大的性能。
视觉编码器:在 DexWild 数据上进行训练,使策略能够应对场景、物体和光照等显著的视觉多样性,这需要一个能够良好泛化到这种多样性的编码器。为了解决这个问题,采用预训练的 Vision Transformer (ViT) 主干网络,该网络在野外操控任务中表现出优于基于 ResNet 编码器的性能 16, 23。预训练的 ViT,尤其是在大型互联网规模数据集上训练的 ViT,在提取丰富、可迁移的特征方面尤为有效 27, 33, 47, 11,因此非常适合本文的设置。
策略类别:虽然最近已经提出几种模仿学习架构 59, 6,但采用基于扩散的策略。扩散模型特别适合灵巧操作,因为它们比高斯混合模型 (GMM) 或 Transformer 等替代方案更有效地捕捉多模态动作分布。这种能力在 DexWild 中变得越来越重要,因为 DexWild 会从多个使用不同策略的人类身上收集演示,从而产生固有的多模态行为。随着数据集规模的扩大,对这种可变性进行建模对于稳健的策略学习至关重要。具体而言,DexWild 使用扩散 U-Net 模型 6 来生成动作块。
具体来说,训练过程概述在算法 1 中。

训练框架的一个重要发现是,调整人机数据权重会显著影响现实世界的表现。
实验的硬件系统部署于 10 位未经训练的用户,用于收集各种真实环境中的数据。这些环境包括室内和室外、白天和夜晚、拥挤的自助餐厅和安静的学习区,其中摆放着各种桌子、物品和灯光设置。收集者本身的手掌大小和演示风格也各不相同,这能够从各种各样的环境和互动中学习。
通过收集工作构建两个数据集:D_H(人工收集数据)和 D_R(机器人收集数据)。人工数据集 D_H 包含五项任务的 9,290 个演示:喷雾瓶任务和玩具清理任务分别包含来自 30 个不同环境的 3,000 个演示;倾倒任务包含来自 6 个环境的 621 条轨迹;花店任务包含来自 15 个环境的 1,545 个演示;折叠衣服任务包含来自 12 个环境的 1,124 个演示。
机器人数据集 D_R 包含 1,395 个演示:388 个喷雾瓶演示、370 个玩具清理演示、111 个倾倒演示、236 个花店演示以及 290 个折叠衣服演示。机器人数据由 xArm 和 LEAP 机械手 V2 Advanced 收集。
训练和测试目标如图所示:

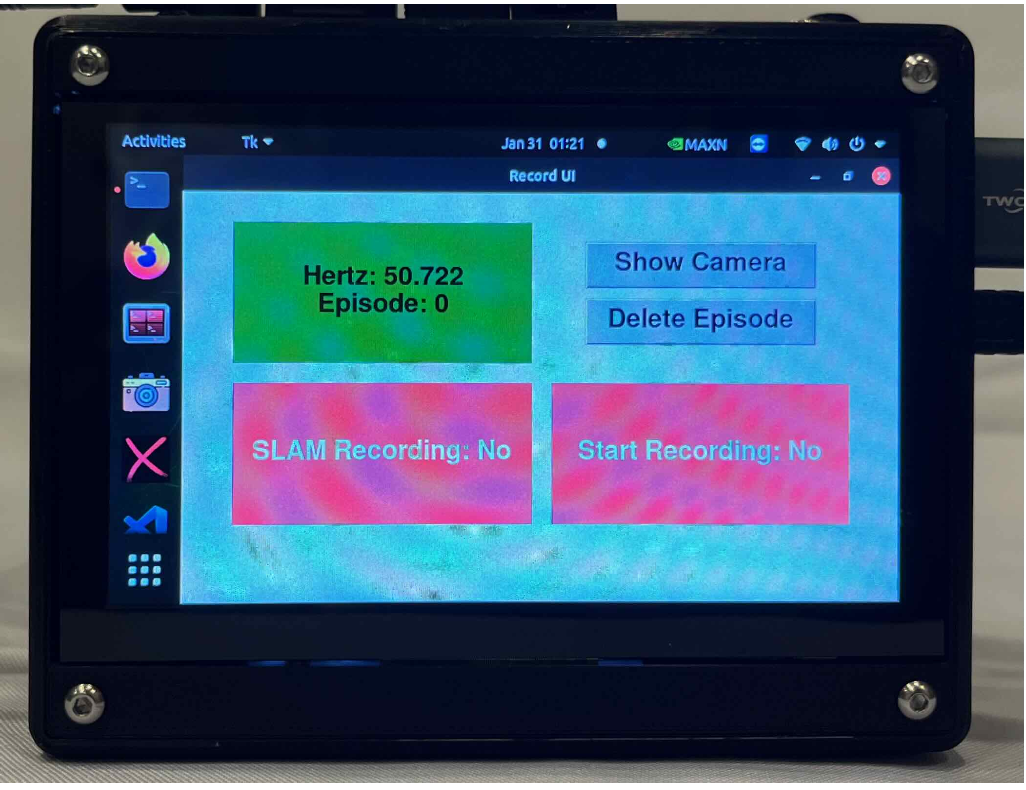
DexWild 系统包含三个核心组件:腕式追踪摄像头、用于机载数据采集的电池供电 mini 电脑,以及一个带有动作捕捉手套和掌上摄像头的定制传感器盒。在新地点,用户只需佩戴动作捕捉手套,并使用提供的移动电源为迷你电脑供电即可。对于以自我为中心的追踪,头带可固定追踪摄像头;对于以外部为中心的追踪,提供可折叠三脚架。启动后,用户启动定制的桌面应用程序,并通过蓝牙遥控器或脚踏板控制录制。用户界面(如图所示)显示传感器状态、SLAM 录制和数据采集指示灯,以及用于查看追踪摄像头反馈和删除最后一集的按钮。采集人员每个地点收集 100 集数据。一天结束后,会将数据上传到远程机器进行处理。
每个 episode 都存储在其自己的文件夹中,子文件夹用于组织各个动作和观察结果。来自 Zed Mini 相机的 SVO 记录(用于 SLAM 和腕部姿势追踪)单独保存,每个文件涵盖五个episodes。为了开始数据处理,用 Zed SDK 解码这些 SVO 文件,重建相机的运动,并使用左图和立体深度数据执行 ArUco 立方体追踪和腕部姿势估计。然后,应用过滤流程来评估追踪质量;如果超过 75% 的持续时间内无法可靠地追踪腕部姿势,则丢弃该episode。接下来,计算动作分布,并裁剪第 2 和第 97 个百分位数之外的异常值。用插值和高斯滤波来平滑轨迹,以确保流畅的运动。然后,按照 41 中的方法,使用 PyBullet 中的逆运动学重定位手部动作。为了提高效率,整个流程使用 Ray 并行化。
行为克隆策略以 RGB 图像和相对状态历史作为输入。通过 ViT 获取图像观测的tokens,并通过线性层获取相对状态的tokens。ViT 的权重由 11 中的 Soup 1M 模型初始化。其包含相对状态,因为它能显著提高策略的鲁棒性,并使运动更加流畅。特别是对于双手操作任务,包含双手间姿势(左手相对于右手的姿势)能显著提高诸如花店之类的任务的成功率。将 Action Chunking Transformer 59 和 Diffusion U-Net 6 实现为策略类,它们输出一系列动作。网络输出的动作由相对末端执行器动作和绝对手部关节角度组成。
为了确保策略的平滑度和安全性,采用 Isaac Lab 26 中实现的黎曼运动策略 (RMP) 34,其中 RMP 根据末端执行器目标动态生成关节空间目标。 RMP 还具有实时防碰撞功能,可防止机械臂与设定的桌面高度发生自碰撞。