基于前三章的内容,开发AI 对话框语音识别输入功能:
Tailwind css实战,基于Kooboo构建AI对话框页面(一)-CSDN博客
Tailwind css实战,基于Kooboo构建AI对话框页面(二):实现交互功能-CSDN博客
Tailwind CSS 实战,基于 Kooboo 构建 AI 对话框页面(三):实现暗黑模式主题切换-CSDN博客
在当今的 AI 应用中,语音交互已经成为提升用户体验的重要组成部分。通过语音识别技术,用户可以更自然、便捷地与 AI 助手进行沟通,无需手动输入文字。本文将详细介绍如何在基于 Kooboo 平台 构建的 AI 对话框页面中集成语音识别功能,结合 Tailwind CSS 实现美观且交互友好的语音输入体验。实现界面如下:
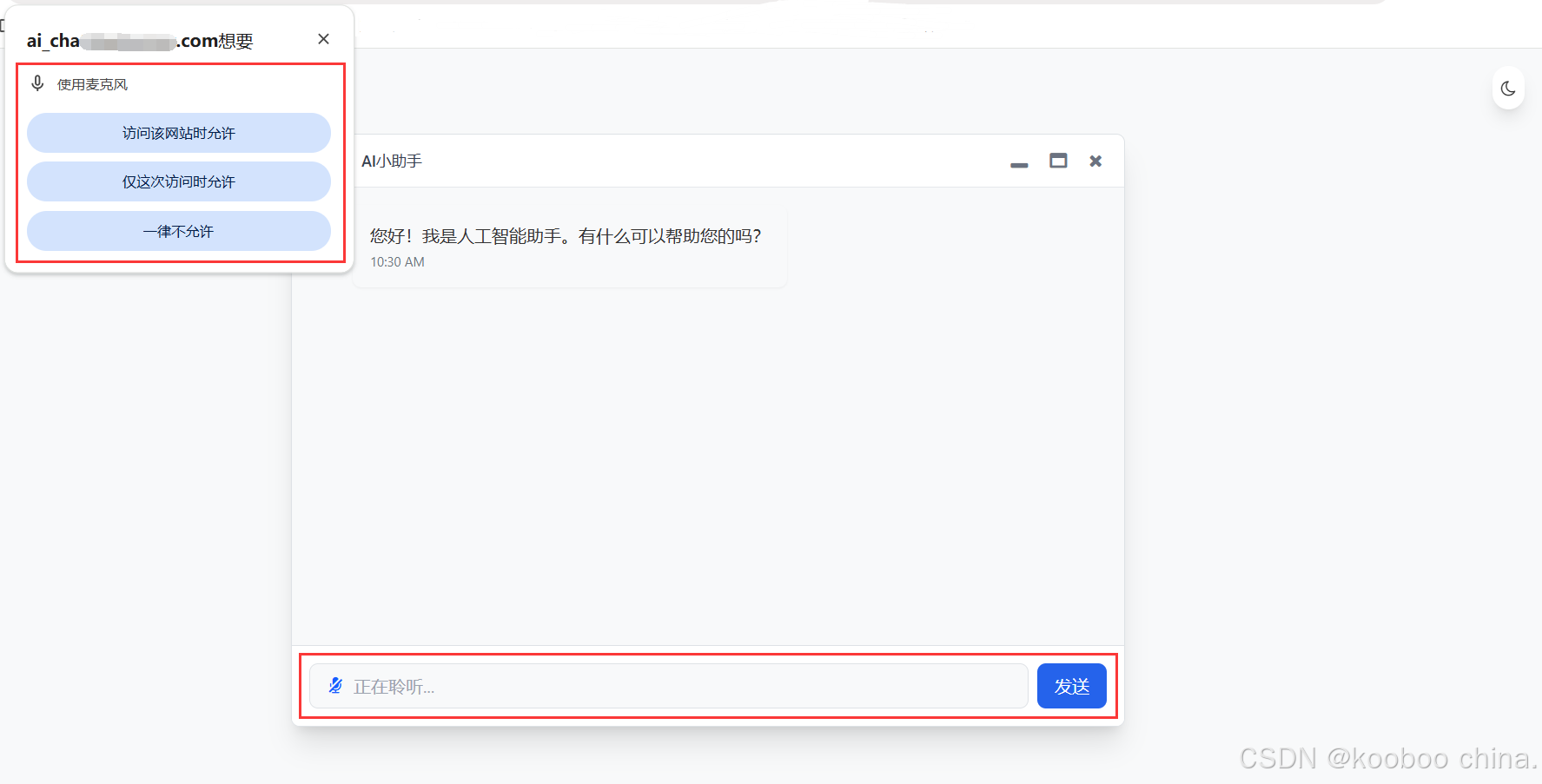
一、语音识别功能概述
语音识别技术允许用户通过麦克风讲话,系统将其转换为文本并显示在输入框中 。在 AI 对话框场景中,语音识别可以大大提高输入效率,特别是对于长篇内容或移动设备用户。我们将实现以下**++核心功能++**:
- 点击麦克风图标访问权限,允许访问权限后支持语音输入
- 说话时,识别内容会实时显示在输入框中
- 再次点击麦克风图标停止录音,此时内容会保留在输入框中
- 点击 "发送" 按钮或按 Enter 键发送内容
二、语音识别基础概念
1. 什么是 Web Speech API?
Web Speech API 是浏览器提供的一组 JavaScript 接口,用于处理语音数据。它主要包含两个部分:
- SpeechRecognition:将语音转换为文本(语音识别)
- SpeechSynthesis:将文本转换为语音(语音合成)
在本文中,我们主要使用SpeechRecognition实现语音输入功能。
2. 兼容性说明
目前主流浏览器(Chrome、Edge、Safari)均支持 Web Speech API,但需要注意:
- Chrome/Edge :完全支持,但必须在安全上下文(HTTPS)或 localhost 环境下使用
- Firefox:部分支持,需要用户手动启用实验性标志
- Safari :支持但语法略有不同(使用
webkitSpeechRecognition)
本案例通过以下方式处理兼容性:
javascript
const recognition = new (window.SpeechRecognition || window.webkitSpeechRecognition)();三、实现语音识别功能
1. 基础代码结构
javascript
// 初始化语音识别对象
const recognition = new (window.SpeechRecognition || window.webkitSpeechRecognition)();
// 配置识别参数
recognition.lang = 'zh-CN'; // 设置识别语言为中文
recognition.interimResults = true; // 启用临时结果,实时显示识别内容
recognition.maxAlternatives = 1; // 只返回最可能的结果
// 状态变量
let isListening = false;
// DOM 元素
const voiceButton = document.getElementById('voiceButton');
const messageInput = document.getElementById('messageInput');
// 开始语音识别
function startListening() {
isListening = true;
// 更新 UI 状态
voiceButton.classList.add('active');
voiceButton.innerHTML = '<i class="fa fa-microphone-slash"></i>';
messageInput.setAttribute('placeholder', '正在聆听...');
// 启动识别
recognition.start();
}
// 停止语音识别
function stopListening() {
isListening = false;
// 更新 UI 状态
voiceButton.classList.remove('active');
voiceButton.innerHTML = '<i class="fa fa-microphone"></i>';
messageInput.setAttribute('placeholder', '输入消息...');
// 停止识别
recognition.abort();
}
// 绑定按钮事件
voiceButton.addEventListener('click', () => {
if (isListening) {
stopListening();
} else {
startListening();
}
});2. 理解关键参数
2.1 recognition.lang
设置识别语言,格式为 BCP 47 语言标签(如 zh-CN、en-US)。完整语言列表可参考 MDN 文档。
2.2 recognition.interimResults
true:识别过程中实时返回临时结果false:只在识别完成后返回最终结果
2.3 recognition.maxAlternatives
设置返回的候选结果数量。例如:
1:只返回最可能的结果3:返回 3 个最可能的结果(需要在结果处理中遍历获取)
3. 处理识别结果
javascript
// 处理识别结果
recognition.onresult = (event) => {
let transcript = '';
// 遍历所有结果块
for (let i = 0; i < event.results.length; i++) {
// 获取当前块的最佳匹配结果
transcript += event.results[i][0].transcript;
// 如果是最终结果,添加标点符号
if (event.results[i].isFinal) {
if (!transcript.endsWith('。') && !transcript.endsWith('?') && !transcript.endsWith('!')) {
transcript += '。';
}
}
}
// 更新输入框内容
messageInput.value = transcript;
};结果结构说明
event.results:包含多个结果块(SpeechRecognitionResultList)- 每个结果块包含多个候选结果(
SpeechRecognitionAlternative) - 每个候选结果有:
transcript:识别文本confidence:置信度(0-1 之间的数值)isFinal:是否为最终结果
4. 错误处理与权限管理
javascript
// 错误处理(关键修改:忽略用户主动中断的错误)
recognition.onerror = (event) => {
if (event.error === 'aborted') {
// 用户主动中断,不显示错误
console.log('语音识别已中断');
} else {
// 其他错误(如网络问题、权限问题)
console.error('语音识别错误:', event.error);
stopListening();
// 根据不同错误类型显示不同提示
let errorMessage = '语音识别失败';
if (event.error === 'not-allowed') {
errorMessage = '请授予麦克风权限后重试!';
} else if (event.error === 'network') {
errorMessage = '网络连接不稳定,请检查网络!';
}
alert(errorMessage);
}
};三、使用 Tailwind CSS 美化界面
1. 设计语音按钮
css
/* 输入框内语音按钮样式 */
.input-wrapper {
position: relative;
flex: 1;
}
.voice-button {
position: absolute;
left: 8px;
top: 50%;
transform: translateY(-50%);
width: 32px;
height: 32px;
display: flex;
align-items: center;
justify-content: center;
cursor: pointer;
color: var(--text-secondary);
background: transparent;
border: none;
z-index: 10;
}2. 输入框与按钮布局
css
<!-- 输入区域 -->
<div class="bg-[var(--bg-primary)] p-4 border-t border-[var(--border-color)]">
<div class="flex space-x-2">
<!-- 输入框包装器 -->
<div class="input-wrapper">
<button id="voiceButton" class="voice-button">
<i class="fa fa-microphone"></i>
</button>
<input
id="messageInput"
type="text"
placeholder="输入消息..."
class="message-input flex-1 w-full p-2 border border-[var(--border-color)] rounded-lg focus:outline-none focus:ring-2 focus:ring-blue-500 bg-[var(--bg-secondary)] text-[var(--text-primary)]"
>
</div>
<button id="sendButton" class="px-4 py-2 bg-blue-600 text-white rounded-lg hover:bg-blue-700 transition-colors">
发送
</button>
</div>
</div>3. 处理语音识别的结果并实时显示在输入框中
javascript
// 处理识别结果(优化显示临时结果)
recognition.onresult = (event) => {
let transcript = '';
for (let i = 0; i < event.results.length; i++) {
transcript += event.results[i][0].transcript;
// 如果是最终结果,添加句号(可选)
if (event.results[i].isFinal) {
transcript += '。';
}
}
messageInput.value = transcript;
};实际运行效果
当用户说话时:
- 输入框会实时显示识别的内容(包括临时结果)
- 说话结束后(短暂停顿),会标记为最终结果并添加句号
- 如果用户继续说话,会继续追加识别内容
总结
通过集成语音识别功能,我们的 AI 对话框页面变得更加智能和易用。用户可以根据需要选择文本输入或语音输入,大大提升了交互体验。结合 Tailwind CSS 的强大样式能力和 Kooboo 平台的便捷开发环境,我们能够高效地实现这些功能,并为未来的扩展留下空间。