1st authors:
paper: [2005.12872 End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) ECCV 2020
code: facebookresearch/detr: End-to-End Object Detection with Transformers
1. 背景
目标检测,作为计算机视觉的核心任务之一,其传统流程往往像一盘精心编排但略显繁琐的棋局。无论是基于候选区域的两阶段方法(如 Faster R-CNN),还是基于预设锚框或网格的一阶段方法(如 YOLO, SSD),都离不开诸多手工设计的组件:例如锚框的尺寸与比例、候选框的生成与筛选、非极大值抑制(NMS)等后处理步骤。这些组件虽然在特定数据集上能取得优异性能,但也带来了额外的调参负担,并且使得整个检测流程显得不够"端到端"。
Facebook AI Research (FAIR) 的 DETR (DEtection TRansformer) 横空出世,试图用一种更为简洁、直接的方式,将这场棋局化繁为简。它借鉴了自然语言处理领域大放异彩的 Transformer 架构,并将其成功应用于目标检测任务,实现了首个真正意义上实现完全端到端。
1.1. 核心思想:目标检测即集合预测
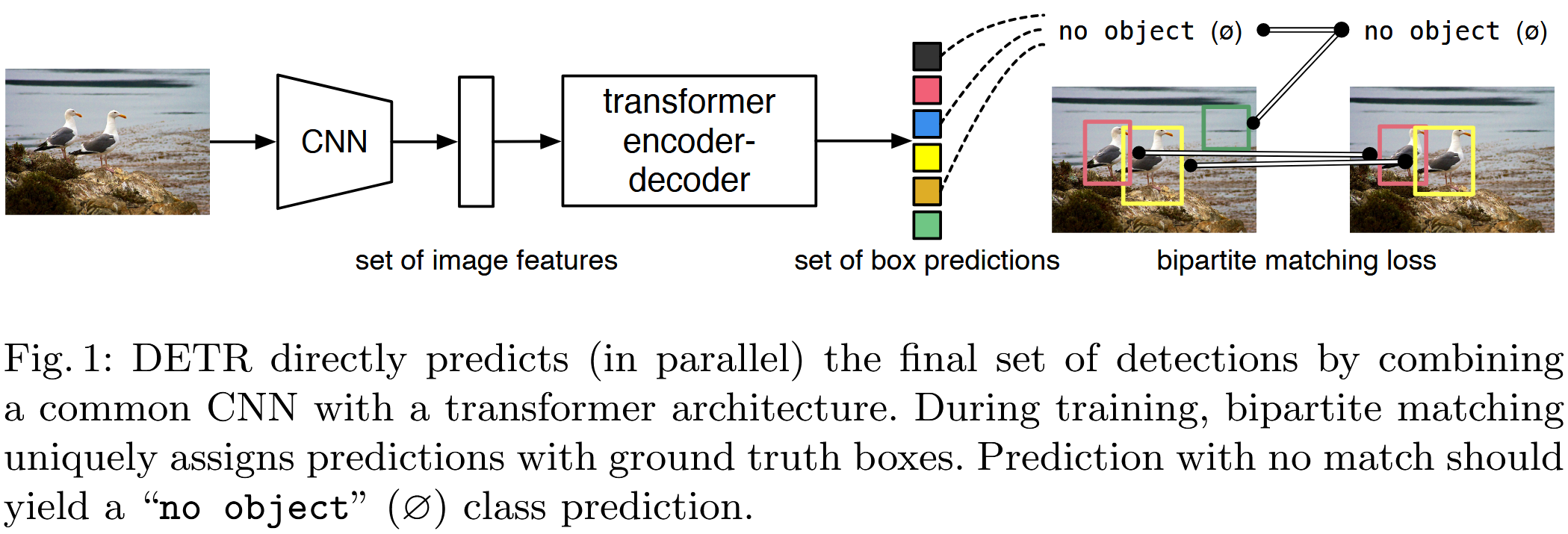
DETR 的核心思想是将目标检测视为一个直接的集合预测 (direct set prediction) 问题。这与传统方法有着本质区别:
- 传统方法:通常预测一大堆候选框(远超真实物体数量),然后通过分类得分和 NMS 等手段筛选出最终结果。输出数量是可变的,且依赖后处理。
- DETR :给定一张图片,DETR 直接输出一个固定大小的预测集合,集合中每个元素包含一个物体的类别标签和边界框坐标。这个固定大小通常设为一个远大于图像中常见物体数量的数 N N N(例如,论文中 N = 100 N=100 N=100)。
数学解释:
假设一张图片中有 M M M 个真实物体,其真实标签集合为 Y = { y 1 , y 2 , . . . , y M } Y = \{y_1, y_2, ..., y_M\} Y={y1,y2,...,yM},其中每个 y i = ( c i , b i ) y_i = (c_i, b_i) yi=(ci,bi) 代表第 i i i 个物体的类别标签 c i c_i ci 和边界框 b i b_i bi(通常是归一化的中心点坐标 ( x , y ) (x,y) (x,y) 及其宽高 ( w , h ) (w,h) (w,h))。
DETR 模型会输出一个固定大小为 N N N 的预测集合 Y ^ = { y ^ 1 , y ^ 2 , . . . , y ^ N } \hat{Y} = \{\hat{y}_1, \hat{y}_2, ..., \hat{y}_N\} Y^={y^1,y^2,...,y^N},其中每个 y ^ j = ( c ^ j , b ^ j ) \hat{y}_j = (\hat{c}_j, \hat{b}_j) y^j=(c^j,b^j)。
- 如果 M < N M < N M<N,那么多余的 N − M N-M N−M 个预测槽位,模型会预测一个特殊的"无对象 " (∅,
no object) 类别。 - 如果 M > N M > N M>N(理论上,如果 N N N 设置得足够大,这种情况很少发生),模型将无法检测出所有物体,这反映了模型容量的限制。
这种"直接集合预测"的范式,是 DETR 能够摆脱 NMS 等复杂后处理的关键。因为它不再产生大量冗余、重叠的预测,而是力求每个预测槽位都对应一个(或没有)真实物体。
1.2. 集合预测的挑战
将目标检测视为集合预测问题,虽然概念上简洁,但也带来了新的挑战:
- 预测与真值的匹配 :由于预测集合 Y ^ \hat{Y} Y^ 中的元素顺序是任意的,而真实标签集合 Y Y Y 的顺序也是任意的(或者说,我们不关心其内部顺序),如何建立 Y ^ \hat{Y} Y^ 和 Y Y Y 之间的一一对应关系以计算损失?
- 损失函数的排列不变性 :损失函数的设计必须保证,即使打乱预测集合 Y ^ \hat{Y} Y^ 中元素的顺序,最终的损失值也应该保持不变。
- 唯一性惩罚:模型需要被鼓励为每个真实物体只产生一个最佳预测,避免多个预测槽位都去拟合同一个真实物体。
为了解决这些问题,DETR 巧妙地引入了两个核心组件:
- 二分图匹配 (Bipartite Matching) :使用匈牙利算法 (Hungarian Algorithm) 来寻找预测集合 Y ^ \hat{Y} Y^ 与真实标签集合 Y Y Y ( 用 ∅ 填充至大小为 N N N) 之间的最优匹配。这个匹配过程会基于类别预测的置信度和边界框的相似度来计算一个"匹配代价"。
- Transformer 架构:利用 Transformer 的自注意力机制 (self-attention) 和交叉注意力机制 (cross-attention),使得模型能够全局地理解图像内容,并感知不同预测物体之间的关系,从而自然地抑制重复预测。
简单来说,DETR 首先通过一个卷积神经网络 (CNN) 提取图像特征,然后将这些特征以及一组可学习的"对象查询 " (object queries,数量为 N N N) 输入到一个 Transformer 编码器 - 解码器结构中。解码器的输出即为 N N N 个预测结果,然后通过二分图匹配与真实标签进行匹配,并计算损失进行端到端训练。
2. 方法
2.1. 结构: DETR 的"三驾马车"
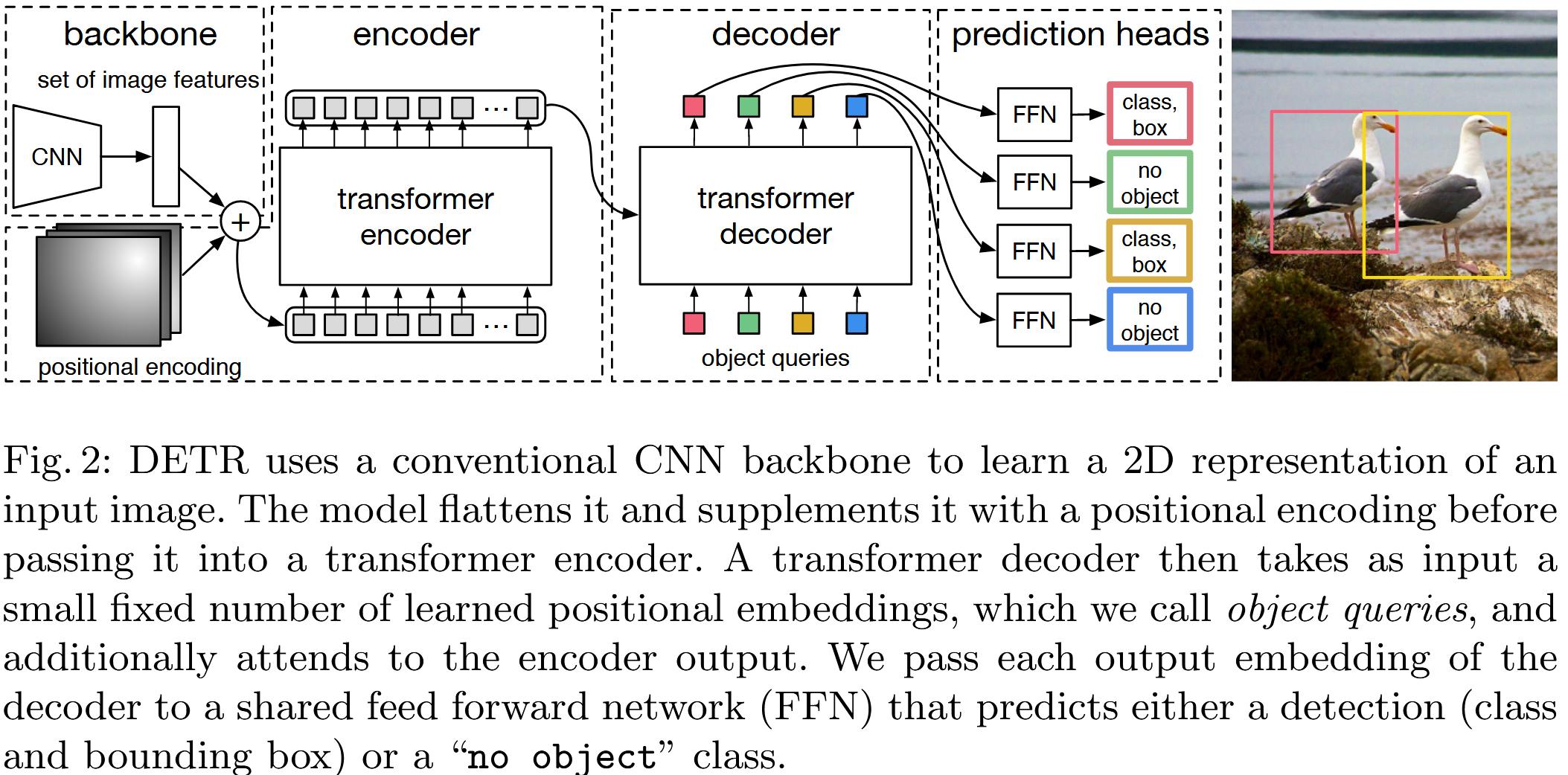
DETR 的整体架构可以概括为三个主要部分(如论文 FIgure 2 所示):一个用于提取图像特征的 CNN 骨干网络,一个用于进行关系推理和上下文建模的 Transformer 编码器 - 解码器,以及一个用于从 Transformer 解码器输出中预测类别和边界框的前馈网络 (FFN)。
-
CNN 骨干网络 (Backbone):
- 作用:从输入图像 x i m g ∈ R 3 × H 0 × W 0 x_{img} \in \mathbb{R}^{3 \times H_0 \times W_0} ximg∈R3×H0×W0 中提取低分辨率但语义丰富的特征图 f ∈ R C × H × W f \in \mathbb{R}^{C \times H \times W} f∈RC×H×W。
- 实现:通常使用标准的预训练 CNN,如 ResNet-50 或 ResNet-101。论文中,对于 ResNet,典型的 H = H 0 / 32 , W = W 0 / 32 H = H_0/32, W = W_0/32 H=H0/32,W=W0/32,通道数 C = 2048 C=2048 C=2048。
- 关键操作:在将特征图输入 Transformer 之前,会通过一个 1 × 1 1 \times 1 1×1 卷积将其通道数从 C C C 降至一个较小的维度 d d d ( 例如 d = 256 d=256 d=256),得到 z 0 ∈ R d × H × W z_0 \in \mathbb{R}^{d \times H \times W} z0∈Rd×H×W。然后,将 z 0 z_0 z0 的空间维度展平,得到一个 d × ( H ⋅ W ) d \times (H \cdot W) d×(H⋅W) 的序列作为 Transformer 编码器的输入。
-
Transformer 编码器 (Encoder):
-
作用:对 CNN 提取的图像特征进行全局上下文建模,捕捉特征图中不同空间位置之间的依赖关系。
-
输入:展平后的图像特征序列 z 0 z_0 z0 ( 尺寸为 H W × d HW \times d HW×d),并为其添加空间位置编码 (spatial positional encodings)。位置编码是必需的,因为标准的 Transformer 本身不具备处理序列顺序的能力。
-
结构:由多个相同的编码器层堆叠而成。每个编码器层包含一个多头自注意力模块 (multi-head self-attention module) 和一个简单的前馈网络 (FFN)。
-
自注意力机制:使得序列中的每个元素(对应图像中的一个空间位置)都能"关注"到序列中的所有其他元素,从而学习到全局的上下文信息。
- 对于输入序列 X ∈ R L × d X \in \mathbb{R}^{L \times d} X∈RL×d ( 这里 L = H W L=HW L=HW),自注意力计算可以简化为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk QKT)V
其中 Q = X W Q , K = X W K , V = X W V Q=XW_Q, K=XW_K, V=XW_V Q=XWQ,K=XWK,V=XWV 是通过可学习的权重矩阵 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV 得到的查询、键和值。
- 对于输入序列 X ∈ R L × d X \in \mathbb{R}^{L \times d} X∈RL×d ( 这里 L = H W L=HW L=HW),自注意力计算可以简化为:
-
输出:编码后的特征序列 m e m o r y ∈ R H W × d memory \in \mathbb{R}^{HW \times d} memory∈RHW×d。
-
-
Transformer 解码器 (Decoder):
- 作用:基于编码器的输出 ( m e m o r y memory memory) 和一组可学习的"对象查询 (object queries) ",并行地解码出 N N N 个物体的表示。
- 输入:
- 编码器输出 m e m o r y memory memory。
- N N N 个对象查询 (object queries) ,每个查询是一个 d d d 维的向量。这些查询是可学习的参数,在训练过程中会被优化,可以理解为 N N N 个"槽位 (slots)",每个槽位负责预测一个潜在的物体。论文中将这些对象查询也称为"输出位置编码 (output positional encodings)",因为它们和编码器中的位置编码类似,用于区分不同的预测槽位。
- 结构:由多个相同的解码器层堆叠而成。每个解码器层包含一个多头自注意力模块 、一个多头交叉注意力模块 (multi-head cross-attention module) 和一个 FFN。
- 自注意力模块 :作用于 N N N 个对象查询之间,使得不同的查询可以相互感知,避免产生重复的预测。
- 交叉注意力模块 :将对象查询作为 Query,将编码器的输出 m e m o r y memory memory 作为 Key 和 Value。这使得每个对象查询能够从整个图像的上下文中提取与自身相关的信息,用于定位和识别物体。
- 并行解码:与传统 Transformer 解码器(如机器翻译中)的自回归 (autoregressive) 方式不同,DETR 的解码器是并行 的。 N N N 个对象查询在每一层都被同时处理,并输出 N N N 个更新后的表示。
- 输出: N N N 个 d d d 维的输出嵌入 (output embeddings),每个嵌入对应一个预测的物体(或"无对象")。
-
预测头 (Prediction Heads / FFNs):
- 作用:将 Transformer 解码器输出的 N N N 个 d d d 维嵌入,独立地转换为每个物体的类别标签和边界框坐标。
- 结构:共享参数的小型前馈网络 (FFN)。
- 类别预测头:一个线性层接一个 Softmax 函数,输出每个槽位的类别概率分布(包括"无对象"类别)。
- 边界框预测头 :一个 3 层感知机 (MLP) 并使用 ReLU 激活函数,最后接一个线性层,预测归一化的中心坐标、高度和宽度 ( x , y , h , w ) ∈ 0 , 1 4 (x, y, h, w) \in 0,1^4 (x,y,h,w)∈0,14。
- 共享参数:所有 N N N 个槽位共享同一个类别预测头和同一个边界框预测头。
2.2. 对象查询与注意力机制

-
对象查询 (Object Queries) :
这 N N N 个 d d d 维的可学习向量是 DETR 的精髓之一。它们可以被视为一种"可学习的检测提案生成器"。在训练开始时,它们可能是随机初始化的。通过端到端的训练,每个查询会逐渐学会专注于图像中特定类型或特定位置的物体。
- 多样性:解码器内部的自注意力机制鼓励这些查询变得不同,因为如果多个查询变得相似,它们在自注意力计算中会相互抑制。
- 全局性:通过交叉注意力,每个查询可以访问编码器输出的整个图像上下文,而不仅仅是局部区域。这使得 DETR 在检测大物体方面表现优异。
-
注意力机制的角色:
- 编码器自注意力:建立了图像特征之间的全局依赖关系,例如,如果一个区域像"草地",另一个区域像"天空",编码器可以利用这种全局信息来更好地理解场景。
- 解码器自注意力 :在 N N N 个对象查询之间进行信息交互。这非常重要,因为它允许模型在内部执行一种"隐式 NMS"------如果两个查询试图预测同一个物体,它们可以通过自注意力机制相互"沟通"并决定哪个查询更适合,或者调整自己的预测以避免重叠。
- 解码器交叉注意力:这是对象查询从图像中"读取"信息的关键步骤。每个查询学习关注图像中与其最相关的区域,以提取用于分类和定位的证据。可视化交叉注意力图(如论文 Figure 6 所示)通常显示查询会关注物体的显著部分,如头部、腿部或物体的轮廓。
2.3. 优化与损失
DETR 的损失函数设计是其成功的关键,它确保了模型能够进行端到端的训练,并强制实现预测与真实物体之间的一一对应。
-
二分图匹配 (Bipartite Matching)
在计算损失之前,需要为每个真实物体找到一个唯一的最佳匹配预测。假设有 M M M 个真实物体 Y = { y i } i = 1 M Y=\{y_i\}{i=1}^M Y={yi}i=1M 和 N N N 个预测结果 Y ^ = { y ^ j } j = 1 N \hat{Y}=\{\hat{y}j\}{j=1}^N Y^={y^j}j=1N(其中 M ≤ N M \le N M≤N)。我们将 Y Y Y 用 ∅ \emptyset ∅ ( 无对象 ) 填充到大小为 N N N。目标是找到一个代价最小的排列 σ ^ ∈ S N \hat{\sigma} \in \mathfrak{S}N σ^∈SN( S N \mathfrak{S}N SN 是 N N N 个元素的所有排列的集合),使得总匹配代价最小:
σ ^ = arg min σ ∈ S N ∑ i = 1 N C m a t c h ( y i , y ^ σ ( i ) ) \hat{\sigma} = \arg\min{\sigma \in \mathfrak{S}N} \sum{i=1}^N \mathcal{C}{match}(y_i, \hat{y}{\sigma(i)}) σ^=argσ∈SNmini=1∑NCmatch(yi,y^σ(i))其中, C m a t c h ( y i , y ^ σ ( i ) ) \mathcal{C}{match}(y_i, \hat{y}{\sigma(i)}) Cmatch(yi,y^σ(i)) 是真实物体 y i y_i yi 与第 σ ( i ) \sigma(i) σ(i) 个预测 y ^ σ ( i ) \hat{y}_{\sigma(i)} y^σ(i) 之间的配对代价 (pair-wise matching cost) 。这个代价函数需要同时考虑类别预测 的准确性和边界框 的相似性。
对于一个真实物体 y i = ( c i , b i ) y_i=(c_i, b_i) yi=(ci,bi) 和一个预测 y ^ j = ( p ^ j ( c i ) , b ^ j ) \hat{y}_j=(\hat{p}_j(c_i), \hat{b}j) y^j=(p^j(ci),b^j)(其中 p ^ j ( c i ) \hat{p}j(c_i) p^j(ci) 是预测 j j j 属于类别 c i c_i ci 的概率),配对代价定义为:
C m a t c h ( y i , y ^ j ) = − 1 { c i ≠ ∅ } p ^ j ( c i ) + 1 { c i ≠ ∅ } L b o x ( b i , b ^ j ) \mathcal{C}{match}(y_i, \hat{y}j) = - \mathbb{1}{\{c_i \neq \emptyset\}} \hat{p}j(c_i) + \mathbb{1}{\{c_i \neq \emptyset\}} \mathcal{L}{box}(b_i, \hat{b}_j) Cmatch(yi,y^j)=−1{ci=∅}p^j(ci)+1{ci=∅}Lbox(bi,b^j)- 1 { c i ≠ ∅ } \mathbb{1}_{\{c_i \neq \emptyset\}} 1{ci=∅} 是指示函数,当 c i c_i ci 不是"无对象"类别时为 1,否则为 0。
- − p ^ j ( c i ) -\hat{p}_j(c_i) −p^j(ci):类别匹配项。我们希望最大化正确类别的概率,因此用负概率作为代价。
- L b o x ( b i , b ^ j ) \mathcal{L}_{box}(b_i, \hat{b}_j) Lbox(bi,b^j):边界框匹配项。通常是 L 1 L_1 L1 损失和广义交并比损失 (GIoU loss) 的线性组合。
这个最优分配问题可以通过匈牙利算法 (Hungarian algorithm) 高效求解。
二分图匹配算法例如匈牙利算法 HungarianMatch ( C ) → σ ^ \text{HungarianMatch}(\mathcal{C}) \to \hat{\sigma} HungarianMatch(C)→σ^ 是一个离散的、不可微的 函数。它的输出 σ ^ \hat{\sigma} σ^ 是一个排列,它确定了每个预测 y ^ i \hat{y}i y^i 应该与哪个真实目标 y σ ^ ( i ) y{\hat{\sigma}(i)} yσ^(i) 对应(或与"无物体"对应)。
匈牙利匹配算法不参与梯度计算,它仅作为训练过程中一个动态的"标签生成器"或"目标分配器"。模型通过优化其在这些动态生成的、可微目标上的损失,间接地学习到如何生成与真实物体一致的预测。
-
损失函数: 匈牙利损失 (Hungarian Loss)
一旦通过二分图匹配找到了最优的排列 σ ^ \hat{\sigma} σ^,就可以计算最终的损失。匈牙利损失是所有匹配对的损失之和:
L H u n g a r i a n ( Y , Y ^ ) = ∑ i = 1 N − log p \^ σ \^ ( i ) ( c i ) + 1 { c i ≠ ∅ } L b o x ( b i , b \^ σ \^ ( i ) ) \mathcal{L}{Hungarian}(Y, \hat{Y}) = \sum{i=1}^N \left -\\log \\hat{p}_{\\hat{\\sigma}(i)}(c_i) + \\mathbb{1}_{\\{c_i \\neq \\emptyset\\}} \\mathcal{L}_{box}(b_i, \\hat{b}_{\\hat{\\sigma}(i)}) \\right LHungarian(Y,Y^)=i=1∑N−logp\^σ\^(i)(ci)+1{ci=∅}Lbox(bi,b\^σ\^(i))注意这里的区别:
- 类别损失使用的是负对数似然损失 (negative log-likelihood loss) ,而不是匹配代价中的 − p ^ j ( c i ) -\hat{p}_j(c_i) −p^j(ci)。
- p ^ σ ^ ( i ) ( c i ) \hat{p}_{\hat{\sigma}(i)}(c_i) p^σ^(i)(ci) 是第 σ ^ ( i ) \hat{\sigma}(i) σ^(i) 个预测对于真实类别 c i c_i ci 的预测概率。
- 当 c i = ∅ c_i = \emptyset ci=∅ 时(即真实物体是填充的"无对象"),损失中只有类别损失项。为了平衡类别,论文中对 c i = ∅ c_i = \emptyset ci=∅ 的类别损失项乘以了一个较小的权重(例如 0.1)。
边界框损失 L b o x ( b , b ^ ) \mathcal{L}_{box}(b, \hat{b}) Lbox(b,b^) :边界框损失是 L 1 L_1 L1 损失和 GIoU 损失的加权和:
L b o x ( b , b ^ ) = λ i o u L i o u ( b , b ^ ) + λ L 1 ∥ b − b ^ ∥ 1 \mathcal{L}{box}(b, \hat{b}) = \lambda{iou} \mathcal{L}{iou}(b, \hat{b}) + \lambda{L1} \|b - \hat{b}\|_1 Lbox(b,b^)=λiouLiou(b,b^)+λL1∥b−b^∥1- L i o u ( b , b ^ ) \mathcal{L}_{iou}(b, \hat{b}) Liou(b,b^) 通常是 1 − G I o U ( b , b ^ ) 1 - GIoU(b, \hat{b}) 1−GIoU(b,b^)。GIoU 相比传统的 IoU,即使在两个框不相交时也能提供梯度,并且考虑了框的形状和方向。
- ∥ b − b ^ ∥ 1 \|b - \hat{b}\|_1 ∥b−b^∥1 是 L 1 L_1 L1 范数,直接惩罚预测框和真实框的坐标差异。
- λ i o u \lambda_{iou} λiou 和 λ L 1 \lambda_{L1} λL1 是超参数权重。
辅助损失 (Auxiliary Decoding Losses) :
为了帮助模型更快地收敛并输出正确数量的对象,DETR在Transformer解码器的每一层之后都添加了预测头和匈牙利损失。这些中间层的损失称为辅助损失。所有预测头共享参数。
- 类别损失使用的是负对数似然损失 (negative log-likelihood loss) ,而不是匹配代价中的 − p ^ j ( c i ) -\hat{p}_j(c_i) −p^j(ci)。
通过这种精心设计的架构和损失函数,DETR 成功地将目标检测问题转化为一个纯粹的基于 Transformer 的序列到序列预测任务,无需任何手工设计的锚框或 NMS 后处理。
3. 实验
3.1. 对比实验
DETR 在 COCO 目标检测数据集上进行了评估,并与当时最先进的、经过高度优化的 Faster R-CNN 基线进行了比较。
-
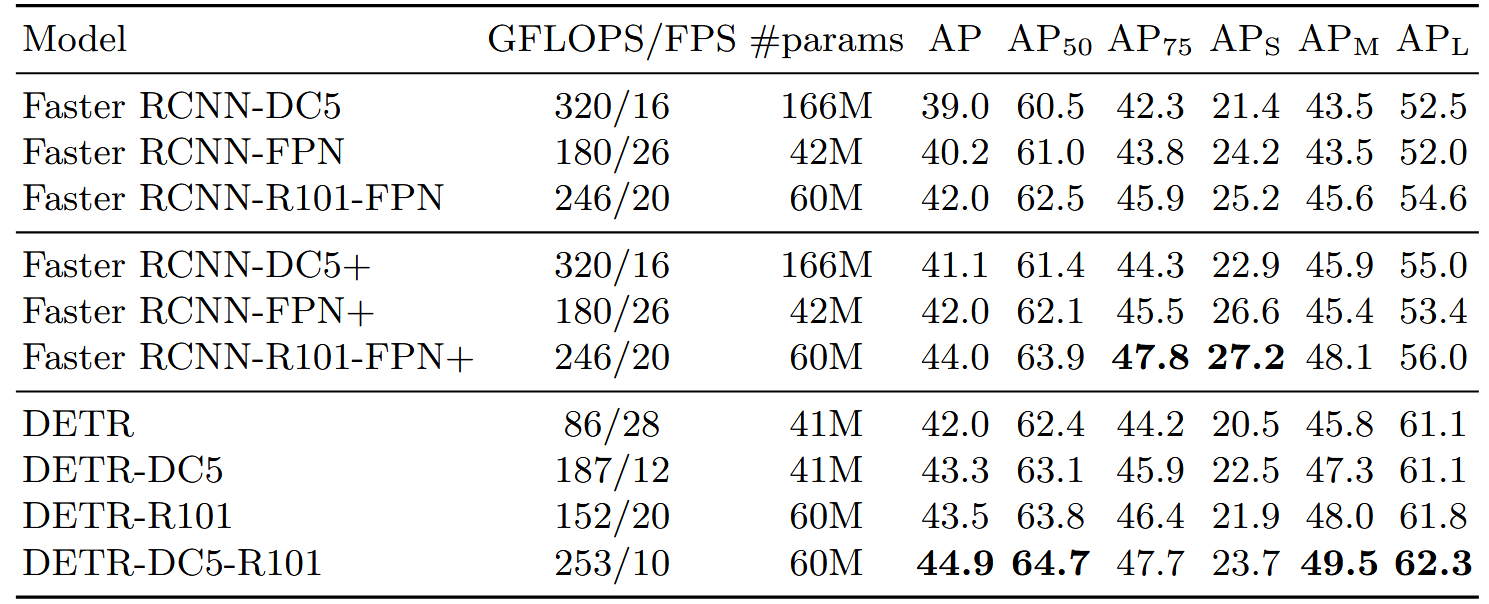
主要结果 ( 如论文 Table 1 所示 ):
- DETR 使用 ResNet-50 作为骨干网络,其参数量与 Faster R-CNN (FPN) 相当(约 41M)。
- 在相同的参数量下,DETR 在 COCO val 集上达到了与 Faster R-CNN 基线相当的 AP (Average Precision)。例如,DETR 可以达到 42.0 AP,而一个强化的 Faster R-CNN+ ( 加入了 GIoU 损失、随机裁剪增强和更长训练周期 ) 可以达到 42.0 AP。
- 对大物体的显著优势 :DETR 在检测大物体 ( A P L AP_L APL) 方面的性能远超 Faster R-CNN。例如,DETR (ResNet-50) 的 A P L AP_L APL 为 61.1,而 Faster R-CNN-FPN+ 的 A P L AP_L APL 为 53.4。这主要归功于 Transformer 的全局注意力机制,使得模型能够整合全局上下文信息。
- 对小物体的挑战 :与此相对,DETR 在检测小物体 ( A P S AP_S APS) 方面表现较差。例如,DETR (ResNet-50) 的 A P S AP_S APS 为 20.5,而 Faster R-CNN-FPN+ 的 A P S AP_S APS 为 26.6。这可能是因为 CNN 骨干网络产生的特征图分辨率较低 ( 例如,对于 ResNet 是输入图像的 1/32),对于小物体信息损失较多,而 Transformer 的全局注意力可能难以精确聚焦于这些微小的目标。论文中也提到,通过使用类似 FPN 的多尺度特征或更高分辨率的特征图(如 DETR-DC5,dilated C5 stage),可以缓解小物体检测性能的问题,但会增加计算成本。
- 训练时间:DETR 需要非常长的训练周期才能达到最佳性能(例如,300 到 500 个 epochs),远超 Faster R-CNN 通常的训练时长。这与 Transformer 在 NLP 任务中的训练特性类似。
- 推理速度:DETR 的推理速度与 Faster R-CNN 相当。
-
参数量与计算量 (FLOPs):
- DETR (ResNet-50, 6 encoder layers, 6 decoder layers, d=256) 的参数量约为 41.3M,FLOPs 约为 86 GFLOPs。
- DETR-DC5 (ResNet-50) 参数量不变,但由于 Encoder 部分处理的特征图分辨率更高,FLOPs 增加到 187 GFLOPs。
3.2. 消融实验
-
Transformer 编码器层数:
- 增加编码器层数可以显著提升性能,尤其是在 AP 和 A P L AP_L APL 上。从 0 层编码器 ( 直接将 CNN 特征送入解码器 ) 到 12 层编码器,AP 从 36.7 提升到 41.6。这表明编码器的全局自注意力对于解耦实例和理解场景至关重要。
- 论文 Figure 3 可视化了编码器最后一层自注意力的结果,显示编码器已经能够区分开图像中的不同实例。
-
Transformer 解码器层数 ( 如论文 Figure 4):
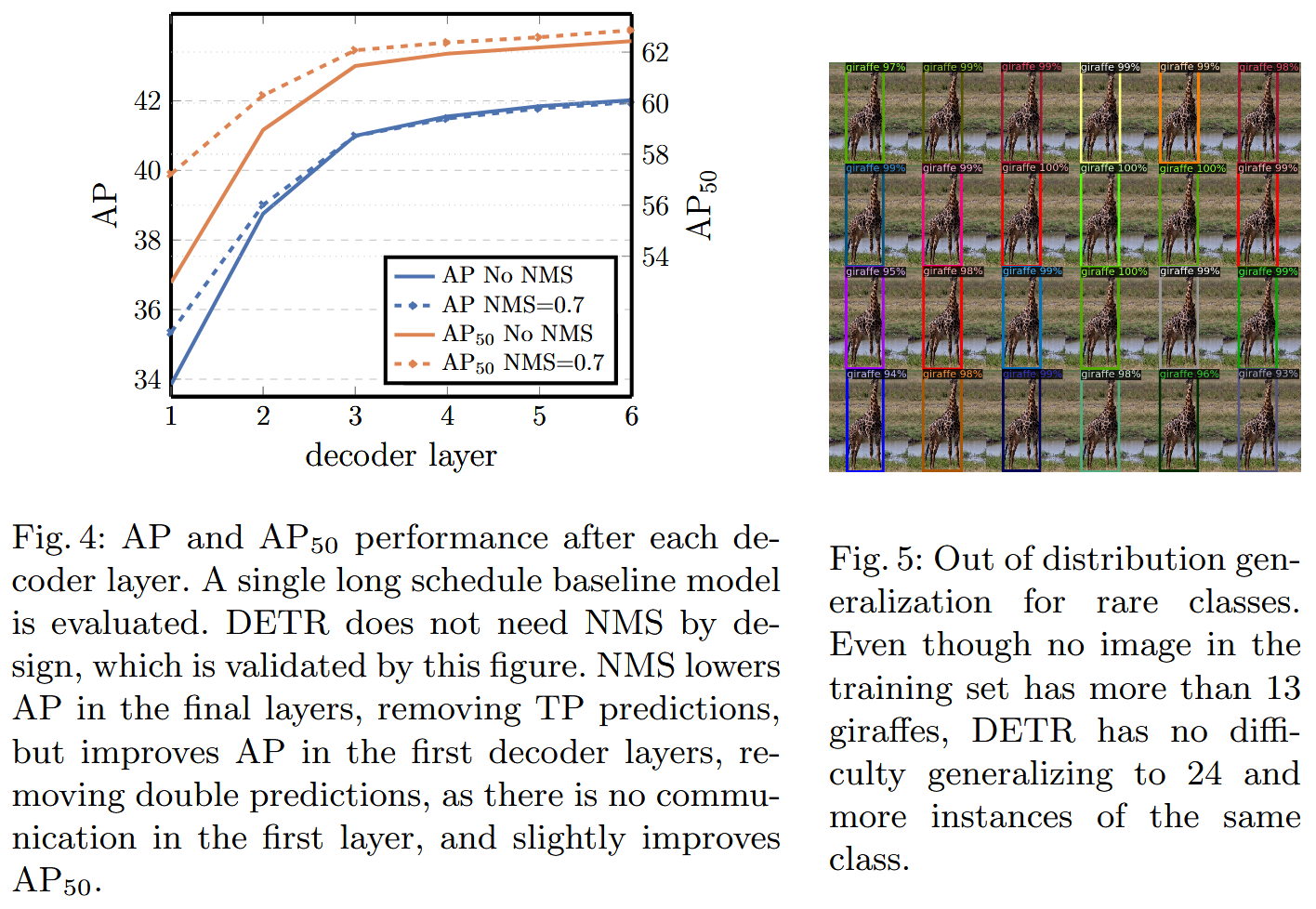
- 解码器的性能随着层数的增加而提升。由于使用了辅助损失,每一层解码器的输出都可以进行评估。第一层解码器的性能较差,但随着层数加深,AP 和 A P 50 AP_{50} AP50 持续提高。
- 一个有趣的发现是,在解码器的浅层,使用 NMS 可以提升性能,因为单层解码器可能难以完全避免重复预测。但随着层数加深,解码器自身的自注意力机制逐渐能够抑制重复,NMS 带来的提升减小,甚至在最后几层会导致性能略微下降(因为 NMS 可能错误地移除了真阳性预测)。这从侧面证明了 DETR 设计上不需要 NMS 的合理性。
-
FFN 在 Transformer 中的重要性:
- Transformer 中的 FFN 层 ( 通常是两层 MLP) 对于性能至关重要。移除 FFN ( 只保留注意力层 ) 会导致 AP 下降约 2.3 点。这说明 FFN 提供的非线性变换和特征转换是必要的。
-
位置编码 ( 如论文 Table 3):
- 空间位置编码 (Spatial Positional Encodings):对于编码器和解码器的交叉注意力都是重要的。完全移除空间位置编码会导致 AP 大幅下降 7.8 点。
- 输出位置编码 (Object Queries/Output Positional Encodings):是必需的,它们为解码器提供了区分不同预测槽位的基础。
- 编码器中不使用空间位置编码仅导致 AP 轻微下降 1.3 点,这比较令人惊讶,可能意味着 CNN 特征本身已经蕴含了足够的位置信息,或者解码器通过交叉注意力也能间接学习到位置关系。
-
损失函数组成 ( 如论文 Table 4):
- GIoU 损失 :对性能提升至关重要。如果只使用 L 1 L_1 L1 损失,AP 会大幅下降。GIoU 损失和 L 1 L_1 L1 损失的组合效果最好。
- 类别损失:是基础,无法移除。
-
对象查询 (Object Queries) 的泛化能力 ( 如Figure 5, Figure 7):
- 对未见实例数量的泛化:实验显示,即使训练集中某个类别的最大实例数为 13(例如长颈鹿),DETR 也能在测试时成功检测出包含 24 个同类实例的图像。这表明对象查询并没有过拟合到训练集中的特定实例数量分布。
- 查询槽位的特化:可视化解码器不同查询槽位预测的边界框中心点分布 ( Figure 7),发现每个查询槽位会学习专注于图像中的特定区域和特定大小的物体。例如,一些槽位倾向于预测大的、覆盖整个图像的物体,而另一些则专注于较小的、特定位置的物体。
4. 总结/局限/展望
优势:
- 真正的端到端:DETR 彻底移除了许多手工设计的组件,如锚框生成和 NMS,使得检测流程极为简洁。
- 概念简单,实现直接:模型结构清晰,核心思想易于理解。代码实现也相对简单(论文中提到 PyTorch 推理代码少于 50 行)。
- 全局上下文建模:Transformer 的引入使得模型能够利用全局信息,尤其擅长检测大物体和理解复杂场景中物体间的关系。
- 无需 NMS:通过二分图匹配和解码器自注意力,自然地避免了重复预测。
- 可扩展性:DETR 的框架很容易扩展到其他视觉任务,如全景分割 (Panoptic Segmentation)。论文中展示了在 DETR 基础上简单添加一个掩码头 (mask head) 就能取得有竞争力的全景分割结果。
局限性:
- 训练时间长,收敛慢:DETR 需要比传统检测器更长的训练周期和更多的数据增强。
- 小物体检测性能较差:标准 DETR 在小物体上的表现不如 Faster R-CNN。这与 Transformer 处理低分辨率特征图的能力有关。
- 对 Transformer 的理解和调优有门槛:虽然概念简单,但 Transformer 自身的复杂性(如注意力机制、位置编码、多头设计)以及其训练的稳定性问题,对初学者可能有一定挑战。
- 固定数量的查询 : N N N 个对象查询的数量是固定的。虽然通常设置得足够大,但在极端情况下(物体数量远超 N N N),模型将无法检测所有物体。
- 计算复杂度 :Transformer 编码器的自注意力计算复杂度是输入序列长度(即 H W HW HW)的平方,当输入特征图分辨率较高时,计算量会急剧增加。
未来展望:
- 进一步提升性能与效率:持续优化 Transformer 结构、注意力机制、损失函数,以提高 DETR 类模型的检测精度(尤其是小物体)、加快收敛速度、降低计算成本。
- 更少的监督信号:探索在弱监督、半监督甚至自监督设置下训练 DETR 类模型。
- 动态查询数量:研究如何让模型根据输入图像的复杂性动态调整查询的数量。
- 更深层次的视觉理解:利用 DETR 的全局推理能力,探索更复杂的视觉任务,如关系检测、场景图生成等。