知识点回顾:
- 彩色和灰度图片测试和训练的规范写法:封装在函数中
- 展平操作:除第一个维度batchsize外全部展平
- dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
作业:仔细学习下测试和训练代码的逻辑,这是基础,这个代码框架后续会一直沿用,后续的重点慢慢就是转向模型定义阶段了。
昨天我们介绍了图像数据的格式以及模型定义的过程,发现和之前结构化数据的略有不同,主要差异体现在2处:
-
模型定义的时候需要展平图像
-
由于数据过大,需要将数据集进行分批次处理,这往往涉及到了dataset和dataloader来规范代码的组织
现在我们把注意力放在训练和测试代码的规范写法上。
单通道图片的规范写法
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 1. 数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 转换为张量并归一化到[0,1]
transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])
# 2. 加载MNIST数据集
train_dataset = datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
test_dataset = datasets.MNIST(
root='./data',
train=False,
transform=transform
)
# 3. 创建数据加载器
batch_size = 64 # 每批处理64个样本
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4. 定义模型、损失函数和优化器
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量
self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元
self.relu = nn.ReLU() # 激活函数
self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)
def forward(self, x):
x = self.flatten(x) # 展平图像
x = self.layer1(x) # 第一层线性变换
x = self.relu(x) # 应用ReLU激活函数
x = self.layer2(x) # 第二层线性变换,输出logits
return x
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):
model.train() # 设置为训练模式
# 新增:记录每个 iteration 的损失
all_iter_losses = [] # 存储所有 batch 的损失
iter_indices = [] # 存储 iteration 序号(从1开始)
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device) # 移至GPU(如果可用)
optimizer.zero_grad() # 梯度清零
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 记录当前 iteration 的损失(注意:这里直接使用单 batch 损失,而非累加平均)
iter_loss = loss.item()
all_iter_losses.append(iter_loss)
iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序号从1开始
# 统计准确率和损失(原逻辑保留,用于 epoch 级统计)
running_loss += iter_loss
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
# 每100个批次打印一次训练信息(可选:同时打印单 batch 损失)
if (batch_idx + 1) % 100 == 0:
print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} '
f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')
# 原 epoch 级逻辑(测试、打印 epoch 结果)不变
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
epoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)
print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')
# 绘制所有 iteration 的损失曲线
plot_iter_losses(all_iter_losses, iter_indices)
# 保留原 epoch 级曲线(可选)
# plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)
return epoch_test_acc # 返回最终测试准确率
# 6. 测试模型
def test(model, test_loader, criterion, device):
model.eval() # 设置为评估模式
test_loss = 0
correct = 0
total = 0
with torch.no_grad(): # 不计算梯度,节省内存和计算资源
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
avg_loss = test_loss / len(test_loader)
accuracy = 100. * correct / total
return avg_loss, accuracy # 返回损失和准确率
# 7.绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):
plt.figure(figsize=(10, 4))
plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')
plt.xlabel('Iteration(Batch序号)')
plt.ylabel('损失值')
plt.title('每个 Iteration 的训练损失')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 8. 执行训练和测试(设置 epochs=2 验证效果)
epochs = 2
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
python
开始训练模型...
Epoch: 1/2 | Batch: 100/938 | 单Batch损失: 0.3583 | 累计平均损失: 0.6321
Epoch: 1/2 | Batch: 200/938 | 单Batch损失: 0.2035 | 累计平均损失: 0.4776
Epoch: 1/2 | Batch: 300/938 | 单Batch损失: 0.3044 | 累计平均损失: 0.4053
Epoch: 1/2 | Batch: 400/938 | 单Batch损失: 0.1427 | 累计平均损失: 0.3669
Epoch: 1/2 | Batch: 500/938 | 单Batch损失: 0.1742 | 累计平均损失: 0.3321
Epoch: 1/2 | Batch: 600/938 | 单Batch损失: 0.3089 | 累计平均损失: 0.3104
Epoch: 1/2 | Batch: 700/938 | 单Batch损失: 0.0455 | 累计平均损失: 0.2921
Epoch: 1/2 | Batch: 800/938 | 单Batch损失: 0.1018 | 累计平均损失: 0.2762
Epoch: 1/2 | Batch: 900/938 | 单Batch损失: 0.2935 | 累计平均损失: 0.2628
Epoch 1/2 完成 | 训练准确率: 92.42% | 测试准确率: 95.84%
Epoch: 2/2 | Batch: 100/938 | 单Batch损失: 0.1767 | 累计平均损失: 0.1356
Epoch: 2/2 | Batch: 200/938 | 单Batch损失: 0.1742 | 累计平均损失: 0.1289
Epoch: 2/2 | Batch: 300/938 | 单Batch损失: 0.1273 | 累计平均损失: 0.1282
Epoch: 2/2 | Batch: 400/938 | 单Batch损失: 0.2078 | 累计平均损失: 0.1234
Epoch: 2/2 | Batch: 500/938 | 单Batch损失: 0.0236 | 累计平均损失: 0.1209
Epoch: 2/2 | Batch: 600/938 | 单Batch损失: 0.0573 | 累计平均损失: 0.1193
Epoch: 2/2 | Batch: 700/938 | 单Batch损失: 0.0990 | 累计平均损失: 0.1170
Epoch: 2/2 | Batch: 800/938 | 单Batch损失: 0.1580 | 累计平均损失: 0.1152
Epoch: 2/2 | Batch: 900/938 | 单Batch损失: 0.0749 | 累计平均损失: 0.1139
Epoch 2/2 完成 | 训练准确率: 96.63% | 测试准确率: 96.93%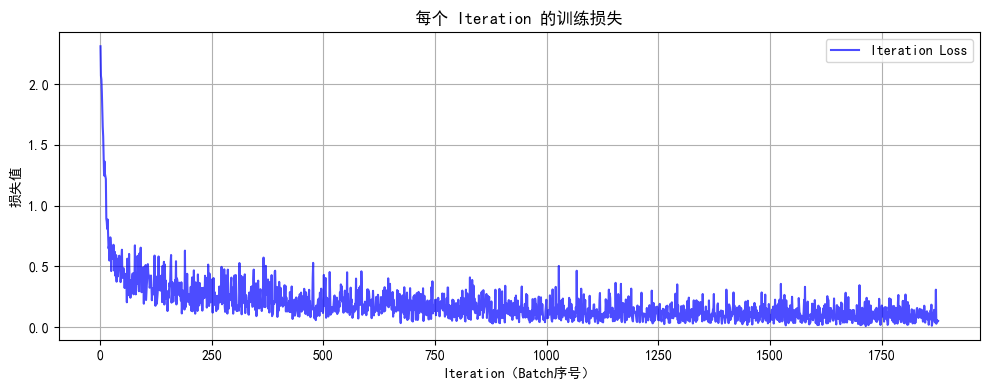
训练完成!最终测试准确率: 96.93%
彩色图片的规范写法
彩色的通道也是在第一步被直接展平,其他代码一致
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 1. 数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 转换为张量
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])
# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=transform
)
test_dataset = datasets.CIFAR10(
root='./data',
train=False,
transform=transform
)
# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量
self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合
self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(0.2)
self.layer3 = nn.Linear(256, 10) # 输出层:10个类别
def forward(self, x):
# 第一步:将输入图像展平为一维向量
x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]
# 第一层全连接 + 激活 + Dropout
x = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]
x = self.relu1(x) # 应用ReLU激活函数
x = self.dropout1(x) # 训练时随机丢弃部分神经元输出
# 第二层全连接 + 激活 + Dropout
x = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]
x = self.relu2(x) # 应用ReLU激活函数
x = self.dropout2(x) # 训练时随机丢弃部分神经元输出
# 第三层(输出层)全连接
x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]
return x # 返回未经过Softmax的logits
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):
model.train() # 设置为训练模式
# 记录每个 iteration 的损失
all_iter_losses = [] # 存储所有 batch 的损失
iter_indices = [] # 存储 iteration 序号
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device) # 移至GPU
optimizer.zero_grad() # 梯度清零
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 记录当前 iteration 的损失
iter_loss = loss.item()
all_iter_losses.append(iter_loss)
iter_indices.append(epoch * len(train_loader) + batch_idx + 1)
# 统计准确率和损失
running_loss += iter_loss
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
# 每100个批次打印一次训练信息
if (batch_idx + 1) % 100 == 0:
print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} '
f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')
# 计算当前epoch的平均训练损失和准确率
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
# 测试阶段
model.eval() # 设置为评估模式
test_loss = 0
correct_test = 0
total_test = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')
# 绘制所有 iteration 的损失曲线
plot_iter_losses(all_iter_losses, iter_indices)
return epoch_test_acc # 返回最终测试准确率
# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):
plt.figure(figsize=(10, 4))
plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')
plt.xlabel('Iteration(Batch序号)')
plt.ylabel('损失值')
plt.title('每个 Iteration 的训练损失')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
# # 保存模型
# torch.save(model.state_dict(), 'cifar10_mlp_model.pth')
# # print("模型已保存为: cifar10_mlp_model.pth")开始训练模型...
Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.9130 | 累计平均损失: 1.9142
Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 1.7181 | 累计平均损失: 1.8331
Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.6971 | 累计平均损失: 1.7934
Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.4990 | 累计平均损失: 1.7678
Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 1.6183 | 累计平均损失: 1.7442
Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.5543 | 累计平均损失: 1.7267
Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 1.7159 | 累计平均损失: 1.7129
Epoch 1/20 完成 | 训练准确率: 39.84% | 测试准确率: 45.88%
Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 1.4124 | 累计平均损失: 1.4658
Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 1.6699 | 累计平均损失: 1.4697
Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 1.7102 | 累计平均损失: 1.4671
Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 1.4926 | 累计平均损失: 1.4676
Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 1.3666 | 累计平均损失: 1.4650
Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 1.3310 | 累计平均损失: 1.4607
Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 1.4583 | 累计平均损失: 1.4586
Epoch 2/20 完成 | 训练准确率: 48.62% | 测试准确率: 49.68%
Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 1.1293 | 累计平均损失: 1.3566
Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 1.4640 | 累计平均损失: 1.3403
Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 1.2351 | 累计平均损失: 1.3399
Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 1.3131 | 累计平均损失: 1.3401
Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 1.2970 | 累计平均损失: 1.3390
Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 1.3351 | 累计平均损失: 1.3405
Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 1.5919 | 累计平均损失: 1.3426
...
Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.3302 | 累计平均损失: 0.3606
Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.3446 | 累计平均损失: 0.3678
Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.5340 | 累计平均损失: 0.3799
Epoch 20/20 完成 | 训练准确率: 86.23% | 测试准确率: 52.44%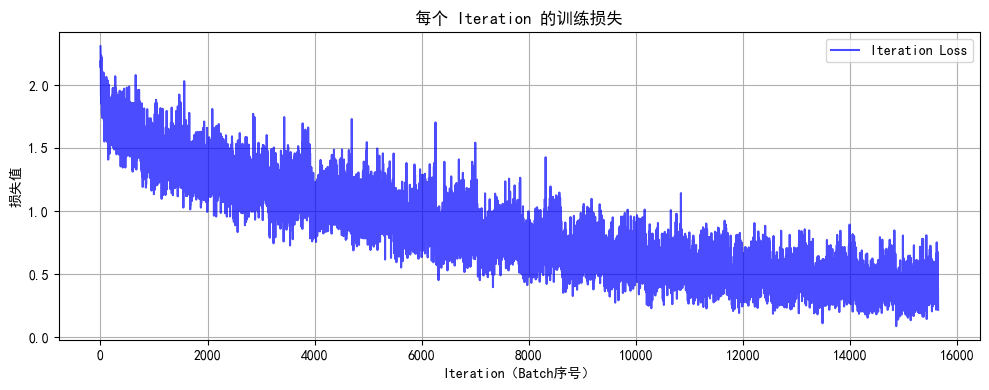
训练完成!最终测试准确率: 52.44%
由于深度mlp的参数过多,为了避免过拟合在这里引入了dropout这个操作,他可以在训练阶段随机丢弃一些神经元,避免过拟合情况。dropout的取值也是超参数。
在测试阶段,由于开启了eval模式,会自动关闭dropout。
可以继续调用这个函数来复用。
python
# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")开始训练模型...
Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.1690 | 累计平均损失: 1.3007
Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 0.9294 | 累计平均损失: 1.2487
Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.2073 | 累计平均损失: 1.2097
Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.0061 | 累计平均损失: 1.1792
Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 1.0305 | 累计平均损失: 1.1537
Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.5181 | 累计平均损失: 1.1305
Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 0.9825 | 累计平均损失: 1.1136
Epoch 1/20 完成 | 训练准确率: 63.69% | 测试准确率: 52.15%
Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 0.3530 | 累计平均损失: 0.4892
Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 0.3962 | 累计平均损失: 0.4302
Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 0.3235 | 累计平均损失: 0.4046
Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 0.3666 | 累计平均损失: 0.3863
Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 0.2378 | 累计平均损失: 0.3766
Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 0.4059 | 累计平均损失: 0.3716
Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 0.2039 | 累计平均损失: 0.3690
Epoch 2/20 完成 | 训练准确率: 87.11% | 测试准确率: 52.81%
Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 0.1667 | 累计平均损失: 0.2780
Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 0.1784 | 累计平均损失: 0.2727
Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 0.1975 | 累计平均损失: 0.2778
Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 0.2125 | 累计平均损失: 0.2834
Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 0.1700 | 累计平均损失: 0.2937
Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 0.4179 | 累计平均损失: 0.3023
Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 0.3614 | 累计平均损失: 0.3117
Epoch 3/20 完成 | 训练准确率: 88.84% | 测试准确率: 51.97%
Epoch: 4/20 | Batch: 100/782 | 单Batch损失: 0.3458 | 累计平均损失: 0.3014
Epoch: 4/20 | Batch: 200/782 | 单Batch损失: 0.3180 | 累计平均损失: 0.2991
Epoch: 4/20 | Batch: 300/782 | 单Batch损失: 0.2757 | 累计平均损失: 0.3060
Epoch: 4/20 | Batch: 400/782 | 单Batch损失: 0.2953 | 累计平均损失: 0.3019
Epoch: 4/20 | Batch: 500/782 | 单Batch损失: 0.4005 | 累计平均损失: 0.3065
Epoch: 4/20 | Batch: 600/782 | 单Batch损失: 0.2583 | 累计平均损失: 0.3105
Epoch: 4/20 | Batch: 700/782 | 单Batch损失: 0.3109 | 累计平均损失: 0.3162
Epoch 4/20 完成 | 训练准确率: 88.52% | 测试准确率: 51.82%
Epoch: 5/20 | Batch: 100/782 | 单Batch损失: 0.3924 | 累计平均损失: 0.2956
Epoch: 5/20 | Batch: 200/782 | 单Batch损失: 0.3494 | 累计平均损失: 0.2924
Epoch: 5/20 | Batch: 300/782 | 单Batch损失: 0.2822 | 累计平均损失: 0.3106
Epoch: 5/20 | Batch: 400/782 | 单Batch损失: 0.1936 | 累计平均损失: 0.3136
Epoch: 5/20 | Batch: 500/782 | 单Batch损失: 0.5070 | 累计平均损失: 0.3189
Epoch: 5/20 | Batch: 600/782 | 单Batch损失: 0.2527 | 累计平均损失: 0.3242
Epoch: 5/20 | Batch: 700/782 | 单Batch损失: 0.3267 | 累计平均损失: 0.3261
Epoch 5/20 完成 | 训练准确率: 88.36% | 测试准确率: 52.00%
Epoch: 6/20 | Batch: 100/782 | 单Batch损失: 0.1880 | 累计平均损失: 0.3100
Epoch: 6/20 | Batch: 200/782 | 单Batch损失: 0.2353 | 累计平均损失: 0.2915
Epoch: 6/20 | Batch: 300/782 | 单Batch损失: 0.2529 | 累计平均损失: 0.2942
Epoch: 6/20 | Batch: 400/782 | 单Batch损失: 0.4678 | 累计平均损失: 0.2997
Epoch: 6/20 | Batch: 500/782 | 单Batch损失: 0.3993 | 累计平均损失: 0.3007
Epoch: 6/20 | Batch: 600/782 | 单Batch损失: 0.4105 | 累计平均损失: 0.3078
Epoch: 6/20 | Batch: 700/782 | 单Batch损失: 0.2575 | 累计平均损失: 0.3126
Epoch 6/20 完成 | 训练准确率: 88.84% | 测试准确率: 52.95%
Epoch: 7/20 | Batch: 100/782 | 单Batch损失: 0.2817 | 累计平均损失: 0.2499
Epoch: 7/20 | Batch: 200/782 | 单Batch损失: 0.1256 | 累计平均损失: 0.2508
Epoch: 7/20 | Batch: 300/782 | 单Batch损失: 0.4671 | 累计平均损失: 0.2559
Epoch: 7/20 | Batch: 400/782 | 单Batch损失: 0.1727 | 累计平均损失: 0.2640
Epoch: 7/20 | Batch: 500/782 | 单Batch损失: 0.2598 | 累计平均损失: 0.2703
Epoch: 7/20 | Batch: 600/782 | 单Batch损失: 0.3861 | 累计平均损失: 0.2827
Epoch: 7/20 | Batch: 700/782 | 单Batch损失: 0.3786 | 累计平均损失: 0.2914
Epoch 7/20 完成 | 训练准确率: 89.71% | 测试准确率: 52.77%
Epoch: 8/20 | Batch: 100/782 | 单Batch损失: 0.3253 | 累计平均损失: 0.2668
Epoch: 8/20 | Batch: 200/782 | 单Batch损失: 0.2284 | 累计平均损失: 0.2659
Epoch: 8/20 | Batch: 300/782 | 单Batch损失: 0.1499 | 累计平均损失: 0.2636
Epoch: 8/20 | Batch: 400/782 | 单Batch损失: 0.2084 | 累计平均损失: 0.2650
Epoch: 8/20 | Batch: 500/782 | 单Batch损失: 0.2098 | 累计平均损失: 0.2700
Epoch: 8/20 | Batch: 600/782 | 单Batch损失: 0.2286 | 累计平均损失: 0.2801
Epoch: 8/20 | Batch: 700/782 | 单Batch损失: 0.4029 | 累计平均损失: 0.2830
Epoch 8/20 完成 | 训练准确率: 89.82% | 测试准确率: 52.35%
Epoch: 9/20 | Batch: 100/782 | 单Batch损失: 0.0950 | 累计平均损失: 0.2447
Epoch: 9/20 | Batch: 200/782 | 单Batch损失: 0.1702 | 累计平均损失: 0.2450
Epoch: 9/20 | Batch: 300/782 | 单Batch损失: 0.1907 | 累计平均损失: 0.2457
Epoch: 9/20 | Batch: 400/782 | 单Batch损失: 0.1766 | 累计平均损失: 0.2520
Epoch: 9/20 | Batch: 500/782 | 单Batch损失: 0.3625 | 累计平均损失: 0.2576
Epoch: 9/20 | Batch: 600/782 | 单Batch损失: 0.2169 | 累计平均损失: 0.2570
Epoch: 9/20 | Batch: 700/782 | 单Batch损失: 0.1956 | 累计平均损失: 0.2635
Epoch 9/20 完成 | 训练准确率: 90.41% | 测试准确率: 51.64%
Epoch: 10/20 | Batch: 100/782 | 单Batch损失: 0.2936 | 累计平均损失: 0.2489
Epoch: 10/20 | Batch: 200/782 | 单Batch损失: 0.2909 | 累计平均损失: 0.2324
Epoch: 10/20 | Batch: 300/782 | 单Batch损失: 0.1375 | 累计平均损失: 0.2305
Epoch: 10/20 | Batch: 400/782 | 单Batch损失: 0.0812 | 累计平均损失: 0.2352
Epoch: 10/20 | Batch: 500/782 | 单Batch损失: 0.3469 | 累计平均损失: 0.2392
Epoch: 10/20 | Batch: 600/782 | 单Batch损失: 0.1433 | 累计平均损失: 0.2467
Epoch: 10/20 | Batch: 700/782 | 单Batch损失: 0.4560 | 累计平均损失: 0.2535
Epoch 10/20 完成 | 训练准确率: 90.85% | 测试准确率: 51.52%
Epoch: 11/20 | Batch: 100/782 | 单Batch损失: 0.1649 | 累计平均损失: 0.2532
Epoch: 11/20 | Batch: 200/782 | 单Batch损失: 0.2458 | 累计平均损失: 0.2379
Epoch: 11/20 | Batch: 300/782 | 单Batch损失: 0.1691 | 累计平均损失: 0.2427
Epoch: 11/20 | Batch: 400/782 | 单Batch损失: 0.1717 | 累计平均损失: 0.2456
Epoch: 11/20 | Batch: 500/782 | 单Batch损失: 0.3952 | 累计平均损失: 0.2559
Epoch: 11/20 | Batch: 600/782 | 单Batch损失: 0.3514 | 累计平均损失: 0.2661
Epoch: 11/20 | Batch: 700/782 | 单Batch损失: 0.3663 | 累计平均损失: 0.2691
Epoch 11/20 完成 | 训练准确率: 90.59% | 测试准确率: 52.22%
Epoch: 12/20 | Batch: 100/782 | 单Batch损失: 0.1177 | 累计平均损失: 0.2207
Epoch: 12/20 | Batch: 200/782 | 单Batch损失: 0.1346 | 累计平均损失: 0.2176
Epoch: 12/20 | Batch: 300/782 | 单Batch损失: 0.2742 | 累计平均损失: 0.2289
Epoch: 12/20 | Batch: 400/782 | 单Batch损失: 0.2813 | 累计平均损失: 0.2345
Epoch: 12/20 | Batch: 500/782 | 单Batch损失: 0.2469 | 累计平均损失: 0.2344
Epoch: 12/20 | Batch: 600/782 | 单Batch损失: 0.2058 | 累计平均损失: 0.2381
Epoch: 12/20 | Batch: 700/782 | 单Batch损失: 0.5586 | 累计平均损失: 0.2473
Epoch 12/20 完成 | 训练准确率: 91.18% | 测试准确率: 52.62%
Epoch: 13/20 | Batch: 100/782 | 单Batch损失: 0.1948 | 累计平均损失: 0.2062
Epoch: 13/20 | Batch: 200/782 | 单Batch损失: 0.1775 | 累计平均损失: 0.2080
Epoch: 13/20 | Batch: 300/782 | 单Batch损失: 0.0834 | 累计平均损失: 0.2194
Epoch: 13/20 | Batch: 400/782 | 单Batch损失: 0.1640 | 累计平均损失: 0.2163
Epoch: 13/20 | Batch: 500/782 | 单Batch损失: 0.2912 | 累计平均损失: 0.2265
Epoch: 13/20 | Batch: 600/782 | 单Batch损失: 0.4307 | 累计平均损失: 0.2348
Epoch: 13/20 | Batch: 700/782 | 单Batch损失: 0.5615 | 累计平均损失: 0.2456
Epoch 13/20 完成 | 训练准确率: 91.39% | 测试准确率: 52.30%
Epoch: 14/20 | Batch: 100/782 | 单Batch损失: 0.1902 | 累计平均损失: 0.2704
Epoch: 14/20 | Batch: 200/782 | 单Batch损失: 0.1832 | 累计平均损失: 0.2474
Epoch: 14/20 | Batch: 300/782 | 单Batch损失: 0.1021 | 累计平均损失: 0.2310
Epoch: 14/20 | Batch: 400/782 | 单Batch损失: 0.3127 | 累计平均损失: 0.2318
Epoch: 14/20 | Batch: 500/782 | 单Batch损失: 0.1489 | 累计平均损失: 0.2332
Epoch: 14/20 | Batch: 600/782 | 单Batch损失: 0.2432 | 累计平均损失: 0.2343
Epoch: 14/20 | Batch: 700/782 | 单Batch损失: 0.2338 | 累计平均损失: 0.2398
Epoch 14/20 完成 | 训练准确率: 91.78% | 测试准确率: 51.89%
Epoch: 15/20 | Batch: 100/782 | 单Batch损失: 0.1551 | 累计平均损失: 0.1924
Epoch: 15/20 | Batch: 200/782 | 单Batch损失: 0.0794 | 累计平均损失: 0.2037
Epoch: 15/20 | Batch: 300/782 | 单Batch损失: 0.1742 | 累计平均损失: 0.2068
Epoch: 15/20 | Batch: 400/782 | 单Batch损失: 0.2041 | 累计平均损失: 0.2106
Epoch: 15/20 | Batch: 500/782 | 单Batch损失: 0.2483 | 累计平均损失: 0.2176
Epoch: 15/20 | Batch: 600/782 | 单Batch损失: 0.3731 | 累计平均损失: 0.2215
Epoch: 15/20 | Batch: 700/782 | 单Batch损失: 0.1749 | 累计平均损失: 0.2280
Epoch 15/20 完成 | 训练准确率: 92.07% | 测试准确率: 51.83%
Epoch: 16/20 | Batch: 100/782 | 单Batch损失: 0.2730 | 累计平均损失: 0.1971
Epoch: 16/20 | Batch: 200/782 | 单Batch损失: 0.0863 | 累计平均损失: 0.1945
Epoch: 16/20 | Batch: 300/782 | 单Batch损失: 0.1693 | 累计平均损失: 0.2008
Epoch: 16/20 | Batch: 400/782 | 单Batch损失: 0.2598 | 累计平均损失: 0.2119
Epoch: 16/20 | Batch: 500/782 | 单Batch损失: 0.3095 | 累计平均损失: 0.2262
Epoch: 16/20 | Batch: 600/782 | 单Batch损失: 0.1129 | 累计平均损失: 0.2349
Epoch: 16/20 | Batch: 700/782 | 单Batch损失: 0.2049 | 累计平均损失: 0.2365
Epoch 16/20 完成 | 训练准确率: 91.83% | 测试准确率: 52.04%
Epoch: 17/20 | Batch: 100/782 | 单Batch损失: 0.1754 | 累计平均损失: 0.1977
Epoch: 17/20 | Batch: 200/782 | 单Batch损失: 0.1466 | 累计平均损失: 0.1984
Epoch: 17/20 | Batch: 300/782 | 单Batch损失: 0.0957 | 累计平均损失: 0.1946
Epoch: 17/20 | Batch: 400/782 | 单Batch损失: 0.0544 | 累计平均损失: 0.1984
Epoch: 17/20 | Batch: 500/782 | 单Batch损失: 0.2236 | 累计平均损失: 0.2093
Epoch: 17/20 | Batch: 600/782 | 单Batch损失: 0.2258 | 累计平均损失: 0.2079
Epoch: 17/20 | Batch: 700/782 | 单Batch损失: 0.3008 | 累计平均损失: 0.2127
Epoch 17/20 完成 | 训练准确率: 92.65% | 测试准确率: 52.30%
Epoch: 18/20 | Batch: 100/782 | 单Batch损失: 0.1159 | 累计平均损失: 0.2092
Epoch: 18/20 | Batch: 200/782 | 单Batch损失: 0.2773 | 累计平均损失: 0.2215
Epoch: 18/20 | Batch: 300/782 | 单Batch损失: 0.2862 | 累计平均损失: 0.2173
Epoch: 18/20 | Batch: 400/782 | 单Batch损失: 0.1915 | 累计平均损失: 0.2194
Epoch: 18/20 | Batch: 500/782 | 单Batch损失: 0.4617 | 累计平均损失: 0.2189
Epoch: 18/20 | Batch: 600/782 | 单Batch损失: 0.4545 | 累计平均损失: 0.2212
Epoch: 18/20 | Batch: 700/782 | 单Batch损失: 0.2722 | 累计平均损失: 0.2231
Epoch 18/20 完成 | 训练准确率: 92.38% | 测试准确率: 52.37%
Epoch: 19/20 | Batch: 100/782 | 单Batch损失: 0.0859 | 累计平均损失: 0.1813
Epoch: 19/20 | Batch: 200/782 | 单Batch损失: 0.3460 | 累计平均损失: 0.1917
Epoch: 19/20 | Batch: 300/782 | 单Batch损失: 0.1972 | 累计平均损失: 0.1989
Epoch: 19/20 | Batch: 400/782 | 单Batch损失: 0.4092 | 累计平均损失: 0.1989
Epoch: 19/20 | Batch: 500/782 | 单Batch损失: 0.2398 | 累计平均损失: 0.2045
Epoch: 19/20 | Batch: 600/782 | 单Batch损失: 0.3333 | 累计平均损失: 0.2080
Epoch: 19/20 | Batch: 700/782 | 单Batch损失: 0.0849 | 累计平均损失: 0.2097
Epoch 19/20 完成 | 训练准确率: 92.86% | 测试准确率: 52.97%
Epoch: 20/20 | Batch: 100/782 | 单Batch损失: 0.0850 | 累计平均损失: 0.1737
Epoch: 20/20 | Batch: 200/782 | 单Batch损失: 0.2993 | 累计平均损失: 0.1756
Epoch: 20/20 | Batch: 300/782 | 单Batch损失: 0.2127 | 累计平均损失: 0.1772
Epoch: 20/20 | Batch: 400/782 | 单Batch损失: 0.0924 | 累计平均损失: 0.1753
Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.1720 | 累计平均损失: 0.1829
Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.1470 | 累计平均损失: 0.1943
Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.3909 | 累计平均损失: 0.2011
Epoch 20/20 完成 | 训练准确率: 93.22% | 测试准确率: 52.42%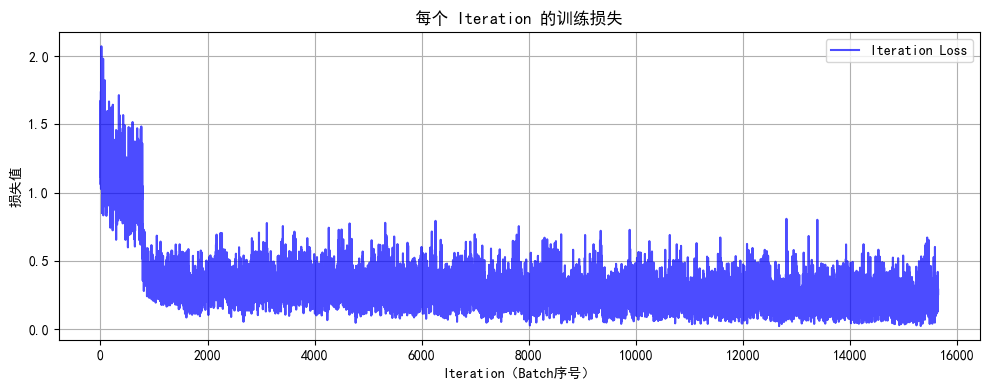
训练完成!最终测试准确率: 52.42%
此时你会发现MLP(多层感知机)在图像任务上表现较差(即使增加深度和轮次也只能达到 50-55% 准确率),主要原因与图像数据的空间特性和MLP 的结构缺陷密切相关。
-
MLP 的每一层都是全连接层,输入图像会被展平为一维向量(如 CIFAR-10 的 32x32x3 图像展平为 3072 维向量)。图像中相邻像素通常具有强相关性(如边缘、纹理),但 MLP 将所有像素视为独立特征,无法利用局部空间结构。例如,识别 "汽车轮胎" 需要邻近像素的组合信息,而 MLP 需通过大量参数单独学习每个像素的关联,效率极低。
-
深层 MLP 的参数规模呈指数级增长,容易过拟合。
所以我们接下来将会学习CNN架构,CNN架构的参数规模相对较小,且训练速度更快,而且CNN架构可以解决图像识别问题,而MLP不能。