在 Elasticsearch 的布尔查询(bool query)中,must 和 filter 是两个核心子句,它们的核心区别在于 是否影响相关性评分,这直接决定了它们在查询性能、使用场景和结果排序上的差异。以下是详细对比:
一、核心区别
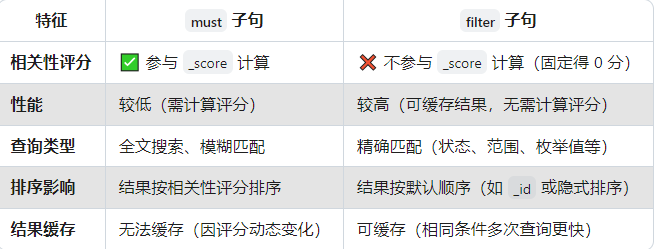
二、底层原理
1. must 子句
-
执行流程:
- 对每个文档执行查询条件
- 计算匹配条件的相关性评分(
_score) - 合并所有
must子句的评分(默认相加) - 按总分排序结果
-
典型应用:
java
{
"query": {
"bool": {
"must": [
{ "match": { "title": "elasticsearch" } }, // 全文搜索
{ "range": { "price": { "gte": 100 } } } // 范围条件(但需要影响排序)
]
}
}
}2. filter 子句
-
执行流程:
- 使用倒排索引快速过滤文档(无需计算评分)
- 结果集返回匹配文档(不排序)
- 若与其他评分查询组合,仅传递过滤后的文档给评分模块
-
典型应用:
java
{
"query": {
"bool": {
"must": [ { "match": { "title": "elasticsearch" } } ],
"filter": [
{ "term": { "status": "published" } }, // 精确匹配
{ "range": { "publish_date": { "gte": "2023-01-01" } } }
]
}
}
}三、使用场景对比
1. 必须使用 must 的场景
- 需求涉及相关性排序: 例如:搜索商品时,关键词匹配度高的结果需要排在前面。
- 需要组合多个相关性条件: 例如:同时匹配标题和内容的关键词,且两者的匹配度共同影响排序。
2. 必须使用 filter 的场景
- 精确筛选数据: 例如:过滤出状态为"已发布"、价格在 100-500 元之间的商品。
- 高频重复查询: 例如:电商平台首页的"促销商品"筛选(同样条件会被多次执行)。
- 不关心排序的过滤: 例如:审计日志的时间范围过滤,结果按时间倒序即可。
四、性能优化技巧
1. 层级优化原则
将过滤条件尽量放在 filter 中,优先缩小数据集:
java
{
"query": {
"bool": {
"must": [ { "match": { "content": "性能优化" } } ],
"filter": [
{ "term": { "category": "技术文档" } },
{ "range": { "view_count": { "gte": 1000 } } }
]
}
}
}2. 强制跳过评分
对 must 中的非相关性条件使用 constant_score:
java
{
"query": {
"bool": {
"must": [
{ "match": { "title": "elasticsearch" } },
{ "constant_score": { // 此条件不贡献评分
"filter": { "term": { "version": "7.x" } },
"boost": 0 // 评分权重设为0
}}
]
}
}
}3. 缓存验证
通过 _search API 的 profile 参数验证是否命中缓存:
java
GET /index/_search?request_cache=true
{
"query": { "bool": { "filter": [ {...} ] } }
}五、错误使用案例
1. 误用 must 导致性能下降
java
// 错误:用 must 处理精确匹配
{
"bool": {
"must": [
{ "term": { "status": "active" } }, // 精确条件应放在 filter
{ "range": { "age": { "gte": 18 } } }
]
}
}2. 误用 filter 导致排序失效
java
// 错误:用 filter 处理需要影响排序的条件
{
"bool": {
"must": [ { "match": { "title": "紧急通知" } } ],
"filter": [ { "range": { "priority": { "gte": 5 } } } ] // priority 应影响排序
}
}六、高级组合用法
1. 混合使用提升性能
java
{
"query": {
"bool": {
"must": [ { "match": { "text": "error" } } ],
"filter": [
{ "term": { "service": "gateway" } },
{ "range": { "@timestamp": { "gte": "now-1h" } } }
]
}
}
}2. 嵌套 bool 查询
java
{
"query": {
"bool": {
"must": [
{ "match": { "title": "系统故障" } },
{ "bool": {
"filter": [ // 嵌套的过滤条件
{ "term": { "environment": "prod" } },
{ "range": { "severity": { "gte": 3 } } }
]
}}
]
}
}
}七、总结
must的本质:贡献相关性评分的条件,适用于需要影响结果排序的场景。filter的本质:高效的二进制过滤器,适用于精确匹配和高频查询。- 黄金法则 : 能用
filter的不要用must------ 除非明确需要该条件影响评分。