本推文对2025年5月出版的数据挖掘领域国际顶级期刊《IEEE Transactions on Knowledge and Data Engineering》进行了分析,对收录的62篇论文的关键词与研究主题进行了汇总,并对其中的研究热点进行了深入分析,希望能为相关领域的研究人员提供有价值的参考。
推文作者为邓镝,审校为韩煦
一、期刊介绍

IEEE Transactions on Knowledge and Data Engineering(简称TKDE)是由IEEE Computer Society出版的一份专注于知识与数据工程领域的学术期刊,每年共出版12期,被归为中科院二区期刊,目前的影响因子为8.9。如图1所示,TKDE的最新年度发文量约为905篇,显著上升,显示了该期刊的活跃度和对高质量研究的持续需求。
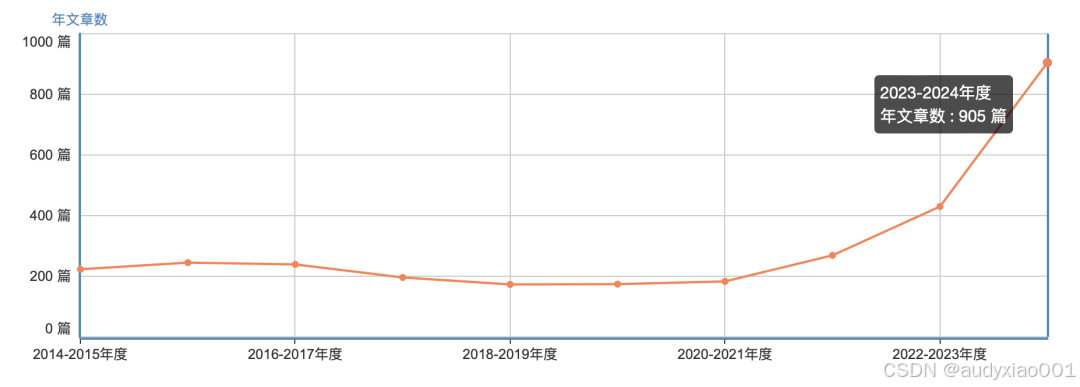
图 1 近年来TKDE 发文量
TKDE的收稿范围包括但不限于基于知识和专家系统的知识与数据工程、与知识和数据管理相关的人工智能技术、知识与数据工程工具和技术、分布式知识库和数据库处理、实时知识库和数据库、基于知识和数据的系统结构、数据管理方法、数据库设计与建模、查询、设计与实现语言、完整性、安全性与容错性、分布式数据库控制、统计数据库、系统的集成与建模、算法及其性能评估、数据通信以及这些系统的应用。
期刊官网:https://ieeexplore.ieee.org/xpl/RecentIssue.jsp?punumber=69
二、 热点分析
本文对该期所收录的62篇论文进行了系统归纳。图2为基于本期论文研究热点生成的词云图,表1则总结了全部论文的标题、关键词以及研究主题,旨在为数据挖掘等相关领域的研究人员提供研究方向上的参考。
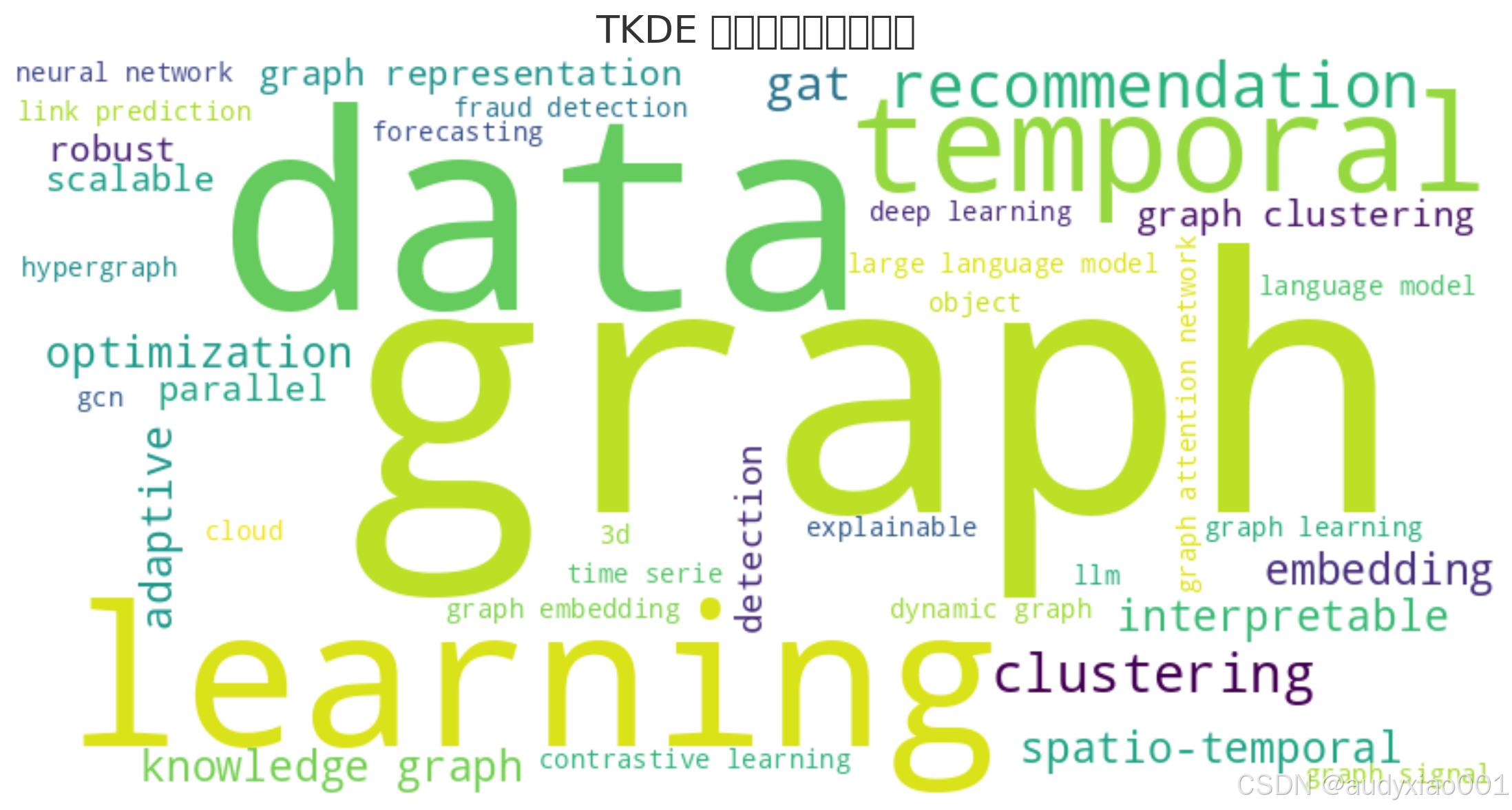
图 2 2025 年5 月TKDE 研究热点词云图
表 1 2025 年5 月TKED 论文合集
|---------------------------------------------------------------------------------------------------------------------|--------------------------------------------------|---------------------------------------------------------------------------|
| 标题 | 关键词 | 研究主题 |
| A Causal-Based Attribute Selection Strategy for Conversational Recommender Systems | 对话推荐系统、因果推理、去混淆、属性选择 | 提出了一种基于因果推断的特征选择策略,用于会话推荐系统以提升推荐效果。 |
| A Novel Expandable Borderline SMOTE Over-Sampling Method for Class Imbalance Problem | 类别不平衡、过采样、合成样本、分类 | 提出了一种新型可扩展边界SMOTE过采样方法,用于解决类别不平衡问题。 |
| A Unified Framework for Bandit Online Multiclass Prediction | 在线学习、多类别分类、带臂学习、梯度下降 | 提出一个统一框架用于在线多类预测,在探索-利用场景下通过Bandit方法进行预测。 |
| A Universal Pre-Training and Prompting Framework for General Urban Spatio-Temporal Prediction | 时空预测、预训练、提示学习、通用模型 | 针对智慧城市中的时空数据预测,提出一个通用的预训练加提示学习框架。 |
| Adaptive Reliable Defense Graph for Multi-Channel Robust GCN | 图神经网络、鲁棒性、防御、对抗攻击 | 提出一种自适应可靠的多通道防御图,用于提高图卷积网络对抗攻击的鲁棒性。 |
| An Amortized O(1) Lower Bound for Dynamic Time Warping in Motif Discovery | 时间序列、动态时间规整、模体发现、下界 | 研究了时间序列模式发现中动态时间规整算法的复杂性,并提出了摊销O(1)下界分析。 |
| Build a Good Human-Free Prompt Tuning: Jointly Pre-Trained Template and Verbalizer for Few-Shot Classification | 提示学习、Few-shot、模板学习、Verbalizer | 提出联合预训练的模板和Verbalizer方法,实现无人工干预的提示调优用于少样本分类。 |
| CAFE: Improved Federated Data Imputation by Leveraging Missing Data Heterogeneity | 联邦学习、缺失数据插补、数据异质性、个性化模型 | 提出Cafe框架,通过利用缺失数据的异质性来改进联邦学习环境下的数据插补效果。 |
| CGoFed: Constrained Gradient Optimization Strategy for Federated Class Incremental Learning | 联邦学习、增量学习、遗忘、梯度优化 | 提出CGoFed策略,在联邦增量学习中引入受约束的梯度优化,以缓解增量学习中的灾难遗忘。 |
| CMVC+: A Multi-View Clustering Framework for Open Knowledge Base Canonicalization | 多视图聚类、知识库规范化、实体聚类、对比学习 | 提出CMVC+框架,使用多视图聚类和对比学习对开放知识库进行实体规范化。 |
| Collaboratively Semantic Alignment and Metric Learning for Cross-Modal Hashing | 跨模态检索、哈希学习、语义对齐、度量学习 | 提出协同语义对齐与度量学习方法,用于提高跨模态哈希检索的性能。 |
| CoLLM: Integrating Collaborative Embeddings Into Large Language Models for Recommendation | 推荐系统、大语言模型、协同过滤、嵌入 | 提出CoLLM框架,将协同过滤嵌入作为独立模态引入大型语言模型,以增强推荐系统性能。 |
| Cross-Graph Interaction Networks | 图神经网络、跨图交互、消息传递、链接预测 | 提出一种跨图交互网络,用于建模不同图之间的交互关系以提升表示学习能力。 |
| Data Optimization in Deep Learning: A Survey | 深度学习、数据增强、样本加权、数据优化 | 对深度学习中的数据优化技术进行综述,涵盖数据增强、数据选择等方法。 |
| Discovery of Temporal Network Motifs | 时间网络、网络模体、时间序列、模式发现 | 研究时间网络模式发现问题,提出新方法挖掘时序网络中的重复结构。 |
| Diversity-Promoting Recommendation With Dual-Objective Optimization | 推荐系统、多样性、双目标优化、精度-多样性平衡 | 针对推荐系统提出双目标优化模型,同时考虑推荐质量和多样性,以促进推荐结果的多样性。 |
| "Do as I Can, Not as I Get": Topology-Aware Multi-Hop Reasoning on Multi-Modal Knowledge Graphs | 知识图谱、多跳推理、多模态、强化学习 | 提出拓扑感知的多跳推理模型DoAsICan,用于多模态知识图谱的推理任务。 |
| Doing More With Less: A Survey of Data Selection Methods for Mathematical Modeling | 数据选择、主动学习、数据压缩、统计建模 | 综述数学建模中的数据选择方法,总结在降低数据需求同时提升模型性能的策略。 |
| Dual-State Personalized Knowledge Tracing With Emotional Incorporation | 知识追踪、情绪建模、个性化学习、迁移学习 | 在个性化知识追踪中引入情感因素,提出双状态模型以更准确地预测学习者的知识掌握。 |
| Dynamic Ensemble Framework for Imbalanced Data Classification | 集成学习、不平衡数据、数据生成、动态集成 | 提出动态集成框架,通过自适应结合多个分类器来解决不平衡数据的分类问题。 |
| Efficient and Accurate Spatial Queries Using Lossy Compressed 3D Geometry Data | 空间查询、3D几何、压缩、GIS、数字孪生 | 提出利用有损压缩的三维几何数据来加速空间查询的方法,提高查询效率与精度。 |
| Efficient PMU Data Compression Using Enhanced Graph Filtering Enabled Principal Component Analysis | PMU数据; 数据压缩; 图滤波; 主成分分析 | 提出基于增强图滤波和主成分分析的高效PMU数据压缩方法,用于电网监测数据处理。 |
| Enhancing Attribute-Driven Fraud Detection With Risk-Aware Graph Representation | 欺诈检测; 图表示学习; 风险意识; 属性分析 | 通过风险感知的图表示学习方法提升了基于属性的欺诈检测性能。 |
| Estimating Multi-Label Expected Accuracy Using Labelset Distributions | 多标签分类; 准确率估计; 标签分布; 性能评估 | 提出利用标签集分布来估计多标签分类任务期望准确率的方法。 |
| Few-Shot Knowledge Graph Completion With Star and Ring Topology Information Aggregation | 知识图谱补全; 少样本学习; 拓扑信息; 表示聚合 | 引入星形和环形拓扑信息聚合策略,提出少样本情况下的知识图谱补全方法。 |
| Finding Rule-Interpretable Non-Negative Data Representation | 非负矩阵分解;规则挖掘;可解释表示;低维表示 | 论文结合规则挖掘与非负矩阵分解方法,构造了一种可解释的数据低维非负表示,使得每个潜在因子都可通过相应的规则描述,从而提高了表示的可解释性。 |
| From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models | 图表理解;基础模型;数据可视化;深度学习 | 回顾了近年来大型基础模型(如大型语言模型)在自动图表理解任务中的研究进展,并讨论了未来的挑战与研究方向。 |
| GAFExplainer: Global View Explanation of Graph Neural Networks Through Attribute Augmentation and Fusion Embedding | 可解释性;图神经网络;节点属性增强;融合嵌入 | 提出通过属性增强和融合嵌入强调节点属性的新型 GNN 解释器 GAFExplainer,在保持计算效率的同时提升了解释的有效性、准确性和可理解性。 |
| Generating k-Hop-Constrained s-t Path Graphs | 图搜索;路径约束;k跳路径;图遍历 | 设计一种高效算法生成满足k跳约束的源-汇路径图。 |
| Graph Clustering With Harmonic-Maxmin Cut Guidance | 图聚类;最小割;图划分;谱方法 | 引入Harmonic-Maxmin cut指标优化图聚类划分质量。 |
| Group-Aware Dynamic Graph Representation Learning for Next POI Recommendation | 下一个兴趣点推荐;群组感知推荐;动态图表示学习 | 提出群组感知动态图表示学习方法 GDGRL,通过构建融合用户交互和伙伴影响的动态图结构学习用户偏好。 |
| Hierarchical Causal Discovery From Large-Scale Observed Variables | 因果发现;大规模观测变量;因果割集;条件独立检验;因果簇;簇内结构;簇间结构;模型无关;分层学习 | 提出分层因果发现框架 HCD,通过划分因果簇并行处理并合并结构。 |
| Hypergraph Collaborative Filtering With Adaptive Augmentation of Graph Data for Recommendation | 自监督学习;双图联合学习;全局协作关系;多任务优化 | 提出基于超图的自适应增强协同过滤框架 HCFAA,通过超图联合学习捕获用户 - 项目图的全局与局部协作关系并过滤无效边。 |
| Improving Sequential Recommendations via Bidirectional Temporal Data Augmentation With Pre-Training | 序列推荐;数据增强;模型预训练 | 提出 BARec 方法,通过双向时序增强和知识增强微调生成保留用户偏好的伪历史项。 |
| Intent Propagation Contrastive Collaborative Filtering | 意图传播;对比学习;协同过滤;推荐系统 | 提出IPCCF算法,引入意图传播机制与对比学习以提升推荐表现。 |
| k-Graph: A Graph Embedding for Interpretable Time Series Clustering | 时间序列;聚类;可解释性 | 通过构建多尺度图结构提升时间序列聚类的解释性与精度。 |
| Large-Scale Hierarchical Causal Discovery via Weak Prior Knowledge | 因果发现;层次模型;先验知识;大规模数据 | 提出了一种层次化的因果发现方法,利用弱先验知识进行搜索约束,有效降低了高维假设空间的复杂度。 |
| Learning Location-Guided Time-Series Shapelets | 时间序列分类;连续优化;可解释性;形状子序列 | 提出了一种连续优化方法,在多类别问题中提升分类准确性和结果的可解释性。 |
| Model-Agnostic Dual-Side Online Fairness Learning for Dynamic Recommendation | 在线推荐;公平性;双侧学习;用户公平;物品公平 | 在推荐系统中引入双侧公平优化机制,兼顾用户与物品的公平性。 |
| MTD-DS: An SLA-Aware Decision Support Benchmark for Multi-Tenant Parallel DBMSs | 基准测试;云计算;DBaaS;多租户;服务等级协议 | 提出MTD-DS基准工具,衡量并行数据库在多租户场景下的SLA性能。 |
| Multi-View Riemannian Manifolds Fusion Enhancement for Knowledge Graph Completion | 知识图谱;知识补全;对比学习;双曲空间;黎曼流形 | 提出MRME-KGC模型,融合多视图黎曼空间提升知识补全性能。 |
| One-Step Adaptive Graph Learning for Incomplete Multiview Subspace Clustering | 不完全多视图聚类;自适应图学习;谱嵌入;张量核范数 | 提出 OAGL 方法,通过稀疏初始化、谱嵌入融合及低秩张量学习实现高效聚类。 |
| Partitioned Dynamic Hub Labeling for Large Road Networks | 动态最短路径;索引维护;中心标号 | 基于图划分的TDHL扩展方法,提升动态路网查询与索引更新效率。 |
| Pattern Hiding and Authorized Searchable Encryption for Data Sharing in Cloud Storage | 云存储;数据共享;结果模式隐藏;私集合交集;可搜索加密 | 提出AXT方案,实现加密检索中对模式隐藏与访问控制的支持。 |
| PipeFilter: Parallelizable and Space-Efficient Filter for Approximate Membership Query | 近似成员查询;过滤器;流水线并行;数据库;数据索引 | 提出 PipeFilter 过滤器,通过流水线并行和子过滤器设计提升多平台处理性能。 |
| PipeOptim: Ensuring Effective 1F1B Schedule With Optimizer-Dependent Weight Prediction | 流水线并行;深度神经网络;权重预测;异步训练 | 提出PipeOptim机制解决1F1B训练中的权重不一致与时延问题。 |
| Practical Equi-Join Over Encrypted Database With Reduced Leakage | 加密数据库;等值连接;信息泄露;可验证计算 | 设计新协议减少等值连接中信息泄漏,同时保持高效连接性能。 |
| PRADA: Pre-Train Ranking Models With Diverse Relevance Signals Mined From Search Logs | 排序模型;数据增强;多样性 | 提出 PRADA 模型,通过局部 / 全局数据增强和生成正样本挖掘多样化关联信号,提升排序模型对稀疏及长尾意图的处理能力。 |
| Probabilistic Learning of Multivariate Time Series With Temporal Irregularity | 概率预测;多变量时间序列;不规则采样;RNN;归一化流;神经ODEs | 提出处理时间不规则性的概率模型,提升多变量序列预测性能。 |
| REP: An Interpretable Robustness Enhanced Plugin for Differentiable Neural Architecture Search | 神经架构搜索;对抗攻击;对抗鲁棒性;搜索空间;鲁棒搜索基元 | 提出 REP 方法,通过采样鲁棒搜索基元与概率增强,提升神经架构搜索模型的对抗鲁棒性和准确率法。 |
| Rethinking Variational Bayes in Community Detection From Graph Signal Perspective | 变分贝叶斯;社区发现;图信号处理 | 提出VBPG方法,从图频域角度改进社区检测中的变分推理策略。 |
| Scalable Min-Max Multi-View Spectral Clustering | 多视图聚类;极小极大框架;锚点图;梯度下降法 | 提出 SMMSC 模型,采用锚点图和梯度下降法,提升聚类性能与大规模数据适用性。 |
| Scalable Multi-View Graph Clustering With Cross-View Corresponding Anchor Alignment | 多视图学习;图聚类;锚点对齐;可扩展性 | 提出可扩展聚类方法,通过锚点对齐增强多视图图聚类精度。 |
| SCHENO: Measuring Schema vs. Noise in Graphs | 图结构分析;模式识别;图数据质量 | 提出SCHENO指标用于衡量图中结构与噪声的比例,评估图的有序性。 |
| SemSI-GAT: Semantic Similarity-Based Interaction Graph Attention Network for Knowledge Graph Completion | 知识图谱补全;交互信息;语义相似性采样;图注意力网络 | 提出 SemSI-GAT,结合 BERT 与语义相似性采样,提升补全性能。 |
| Snoopy: Effective and Efficient Semantic Join Discovery via Proxy Columns | 语义连接发现;相似性搜索;代理列;表示学习 | 针对语义连接发现中单元格级方法低效、列级方法效果不足的问题,提出 Snoopy 框架,利用代理列嵌入平衡效率与效果。 |
| Spatio-Temporal Multivariate Probabilistic Modeling for Traffic Prediction | 时空建模;多变量建模;概率预测;交通预测 | 构建时空概率模型实现多变量交通流量的准确预测。 |
| Style Feature Extraction Using Contrastive Conditioned Variational Autoencoders With Mutual Information Constraints | 风格提取;特征提取;变分自编码器;对比学习;无监督学习 | 利用对比条件VAE与互信息约束提取无监督数据中的风格特征。 |
| TagRec: Temporal-Aware Graph Contrastive Learning With Theoretical Augmentation for Sequential Recommendation | 连续时间序列推荐;图对比学习;图神经网络;数据增强 | 提出TagRec模型,融合时序感知与图对比学习提升推荐准确率。 |
| TaylorS: A Multi-Order Expansion Structure for Urban Spatio-Temporal Forecasting | 时空预测;泰勒展开;多阶导数;城市交通 | 提出了一种称为 TaylorS 的模型,将泰勒级数展开引入城市时空序列预测,提高了时空序列预测的准确性。 |
| Towards Stable and Explainable Attention Mechanisms | 注意力机制;可解释性;模型稳定性;干预分析 | 提出一种可解释且鲁棒的注意力机制,有助于模型推理透明性。 |
| Transfer-and-Fusion: Integrated Link Prediction Across Knowledge Graphs | 知识图谱;知识迁移;融合;链接预测;注意力机制 | 提出了 Transfer-and-Fusion 框架,实现了不同知识图谱信息的联合学习,以提升链接预测效果。 |
为进一步展示本期研究热点,本文还对出现频率前10名的关键词进行了整理,如表2所示。
表 2 2025 年5 月TKED 论文标题高频词整理
|-----------------|--------|
| 关键词 | 频次 |
| graph | 20 |
| data | 11 |
| learning | 10 |
| temporal | 7 |
| recommendation | 7 |
| knowledge | 6 |
| clustering | 5 |
| prediction | 4 |
| gat | 4 |
| spatio-temporal | 3 |
基于词云图和关键词出现频次进行分析,当前研究热点聚焦于图神经网络(GNN)的架构与应用拓展,核心体现在以下方向:
图技术(graph: 20次) 是研究中的主导,尤其在时序动态建模(temporal:7次,spatio-temporal:3次) 中,支撑着推荐系统(recommendation: 7次) 、预测任务(prediction:4次) 等关键场景。关键词中数据(data:11次) 和**学习(learning:10次)**高频出现,这表明以数据驱动的深度学习方法正与图技术深度融合。
结合62篇论文题目和高频关键词分析,当前研究最热门的方向集中在如何利用"图"这种结构来分析复杂关系数据,特别是在随时间或地点变化的场景(比如推荐下一个要去的地方、预测交通流量)。研究人员非常关注如何让这些基于图的技术更实用:一方面是让它们更快、更省资源(比如研究如何压缩数据、并行计算),另一方面是让它们更可靠、更容易理解(比如解释模型为什么这样推荐、如何抵御恶意干扰)。
同时,一个显著趋势是融合不同的新方法:
- 结合大语言模型:探索用大语言模型理解文本信息,来辅助图分析,尤其是在推荐系统上,希望结合用户历史行为和语言理解做出更精准的推荐。
- 引入因果关系:让模型不仅能发现关联,还能理解"原因和结果",这样推荐或预测的结果会更合理、更可解释。
- 处理多种类型数据:研究如何让模型同时理解和关联不同类型的数据(比如图片和描述它的文字),以及如何在数据分散、不完整甚至隐私受限的情况下(通过联邦学习等技术)共同训练模型。
三、总结
总的来说,目前研究致力于让基于图的数据分析技术(尤其是处理动态时空数据的)变得更强大、更高效、更可信。核心的方法是融合大语言模型、因果推断等新方法,并解决多模态数据融合与数据隐私/缺失等实际挑战,最终目标是让这些技术在推荐、预测、知识发现等应用上效果取得更好的效果。未来重点也许会放在如何让这些融合技术更稳定、更透明(可解释)、更节省资源。