目录
[1 问题背景与概述](#1 问题背景与概述)
[1.1 集群健康状态的含义](#1.1 集群健康状态的含义)
[1.2 未分配分片的常见原因](#1.2 未分配分片的常见原因)
[2 问题诊断流程](#2 问题诊断流程)
[3 详细诊断命令与解释](#3 详细诊断命令与解释)
[3.1 检查集群健康状态](#3.1 检查集群健康状态)
[3.2 列出所有RED状态索引](#3.2 列出所有RED状态索引)
[3.3 查看未分配分片详情](#3.3 查看未分配分片详情)
[3.4 获取详细未分配原因解释](#3.4 获取详细未分配原因解释)
[4 总结](#4 总结)
1 问题背景与概述
Elasticsearch集群的健康状态是运维人员需要密切关注的指标之一,它直接反映了集群是否正常运行。当集群状态变为RED时,意味着至少有一个主分片及其副本分片不可用,这将导致数据不完整,严重影响集群的正常使用。
1.1 集群健康状态的含义
Elasticsearch集群健康状态分为三种:
- GREEN:所有主分片和副本分片都已分配,集群100%健康
- YELLOW:所有主分片已分配,但部分副本分片未分配或不可用
- RED:至少有一个主分片(及其副本)未分配或不可用
1.2 未分配分片的常见原因
未分配分片可能由多种原因引起,主要包括:
- 节点离线或宕机
- 磁盘空间不足
- 分片分配设置限制
- 分片损坏
- JVM内存压力过大
- 集群重新平衡过程中断
- 版本兼容性问题
2 问题诊断流程
- 以下是诊断ES集群RED状态及未分配分片问题的标准流程:

步骤说明:
- 发现集群状态为RED:通过监控系统或手动检查发现集群异常
- 检查集群健康状态:获取集群整体健康信息
- 列出所有RED状态索引:定位具体有问题的索引
- 查看未分配分片详情:获取未分配分片的详细信息
- 获取未分配原因解释:深入分析分片未分配的具体原因
- 根据原因采取对应措施:针对不同原因实施解决方案
- 验证问题是否解决:确认集群状态恢复正常
- 问题解决 或深入分析:闭环处理或进一步排查
3 详细诊断命令与解释
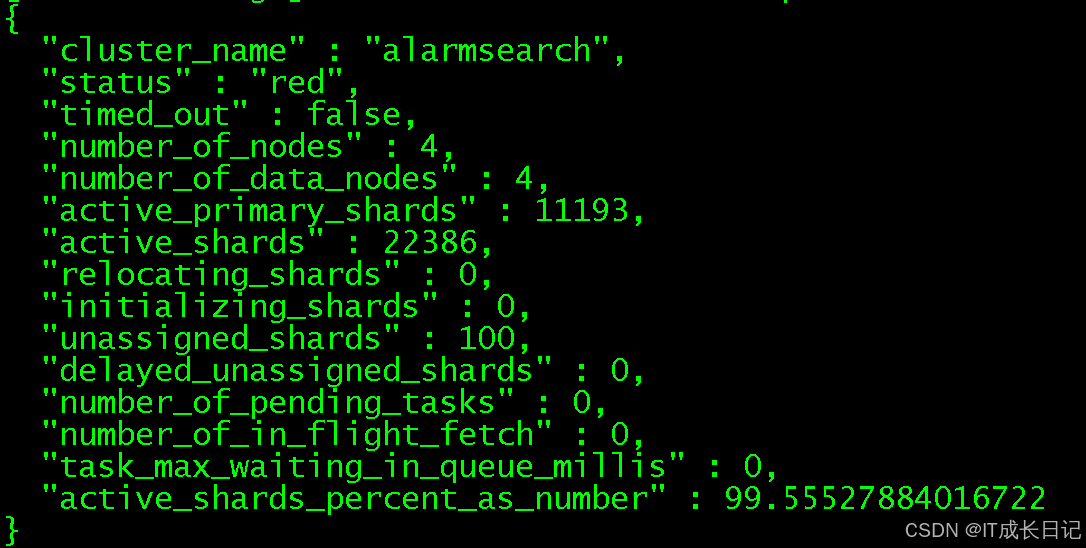
3.1 检查集群健康状态
curl -u 'es_user:es_user_passwd' -XGET "ip:9200/_cluster/health?pretty"此命令返回的JSON包含关键信息:
- status:集群当前状态(GREEN/YELLOW/RED)
- number_of_nodes:集群节点数量
- unassigned_shards:未分配分片数量
- active_shards_percent_as_number:活跃分片百分比
3.2 列出所有RED状态索引
curl -u 'es_user:es_user_passwd' -X GET "ip:9200/_cat/indices?v&health=red&h=index,health,status,pri,rep"命令参数说明:
- health=red:只显示状态为RED的索引
- h=index,health,status,pri,rep:指定显示的列(索引名、健康状态、状态、主分片数、副本数)

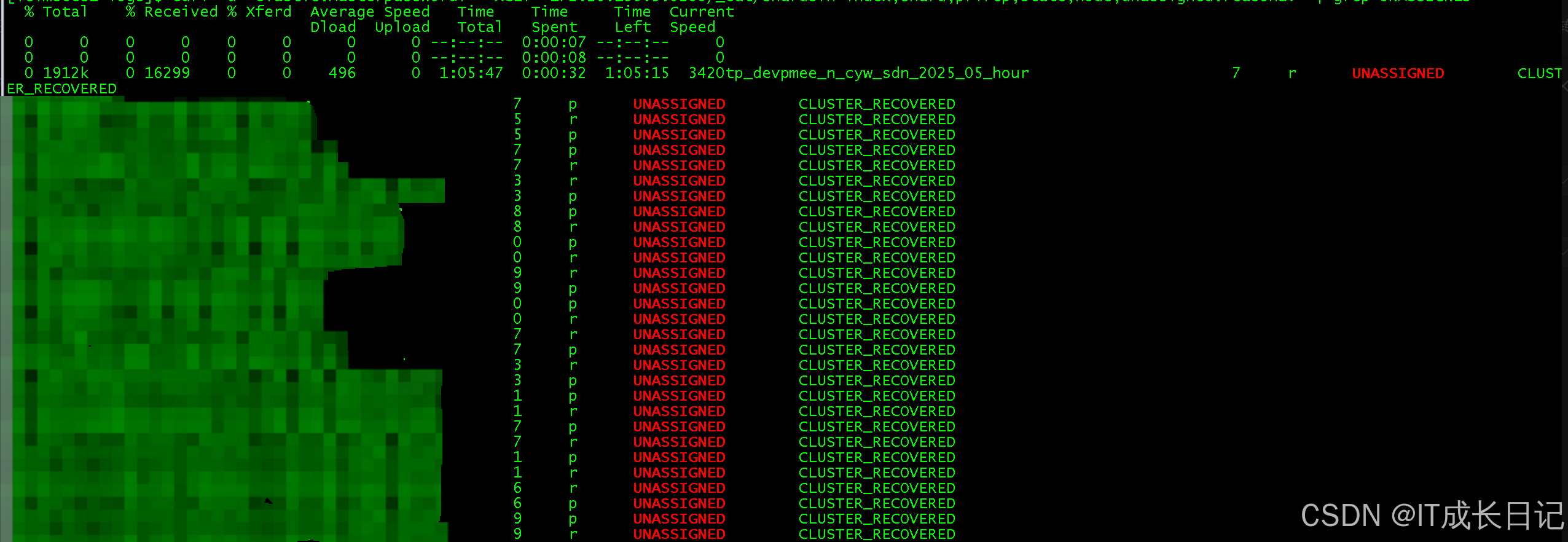
3.3 查看未分配分片详情
curl -u 'es_user:es_user_passwd' -X GET "ip:9200/_cat/shards?h=index,shard,prirep,state,node,unassigned.reason&v" | grep UNASSIGNED命令解析:
- _cat/shards:显示所有分片信息
- h=参数指定显示的字段:
- index:索引名称
- shard:分片号
- prirep:分片类型(p=primary主分片,r=replica副本分片)
- state:分片状态
- node:所在节点
- unassigned.reason:未分配原因
- grep UNASSIGNED:过滤出未分配的分片
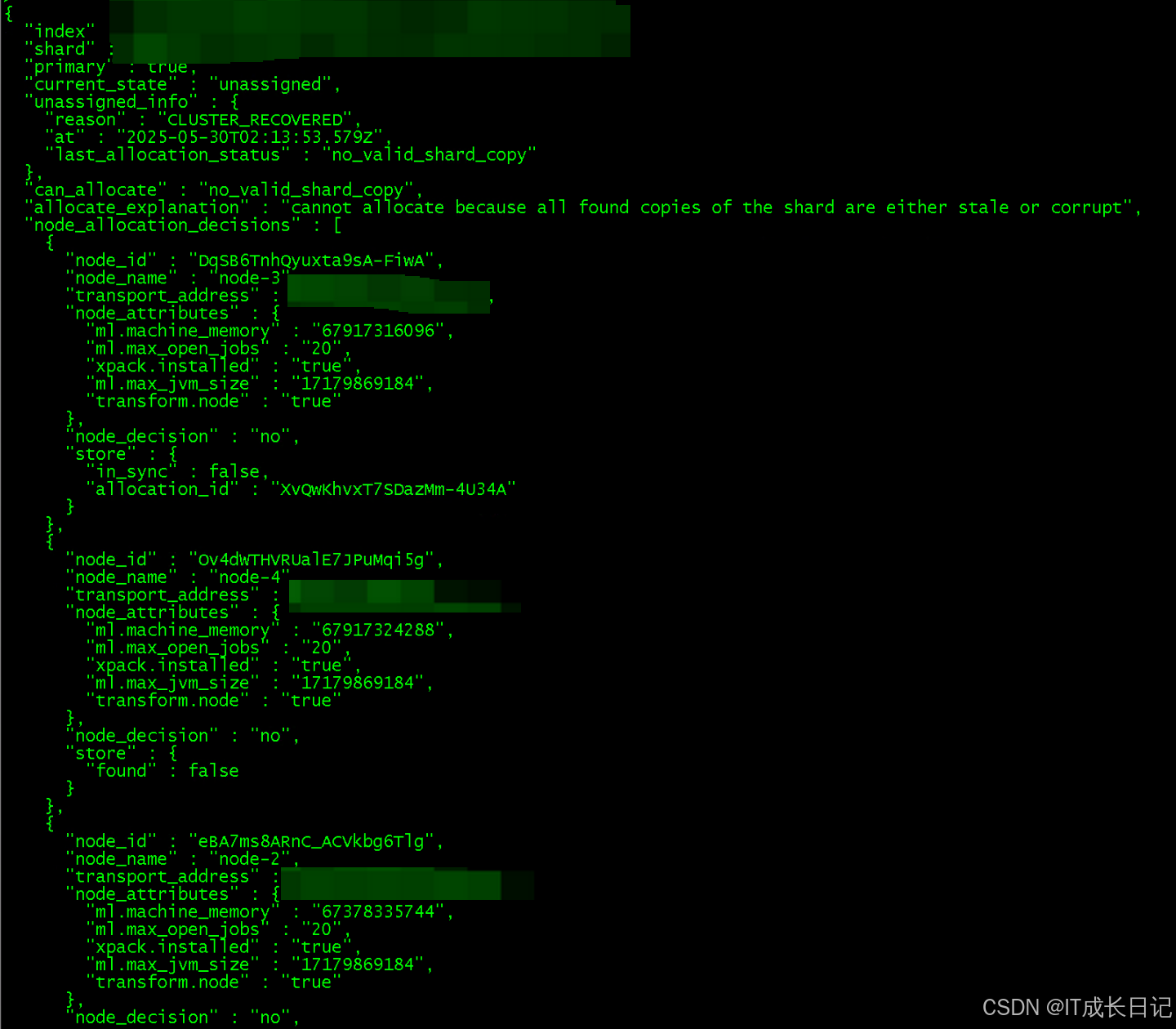
3.4 获取详细未分配原因解释
-
对于特定的未分配分片,可以获取更详细的解释:
curl -u 'es_user:es_user_passwd' -X GET "ip:9200/_cluster/allocation/explain?pretty" -H "Content-Type: application/json" -d'
{
"index": "index_name",
"shard": 3,
"primary": false
}'
此命令返回详细的分配决策解释,包括:
- 分片当前状态
- 分配失败的具体原因
- 尝试分配的节点列表及每个节点的分配决策原因
- 可能的解决方案提示
4 总结
处理Elasticsearch集群RED状态和未分配分片问题需要系统性的排查方法:
- 首先确认集群整体状态和具体有问题的索引
- 定位未分配分片并获取详细的未分配原因
- 根据具体原因采取针对性的解决方案
- 实施修复后验证集群状态
- 建立预防措施避免问题再次发生
通过本文提供的详细诊断流程和解决方案,运维人员可以有效应对ES集群的RED状态问题,保障集群的稳定运行。记住,预防胜于治疗,良好的监控和容量规划可以避免大多数分片分配问题。