Embedding+MLP:TensorFlow实现经典深度学习模型详解
1. 算法逻辑
模型结构和工作流程
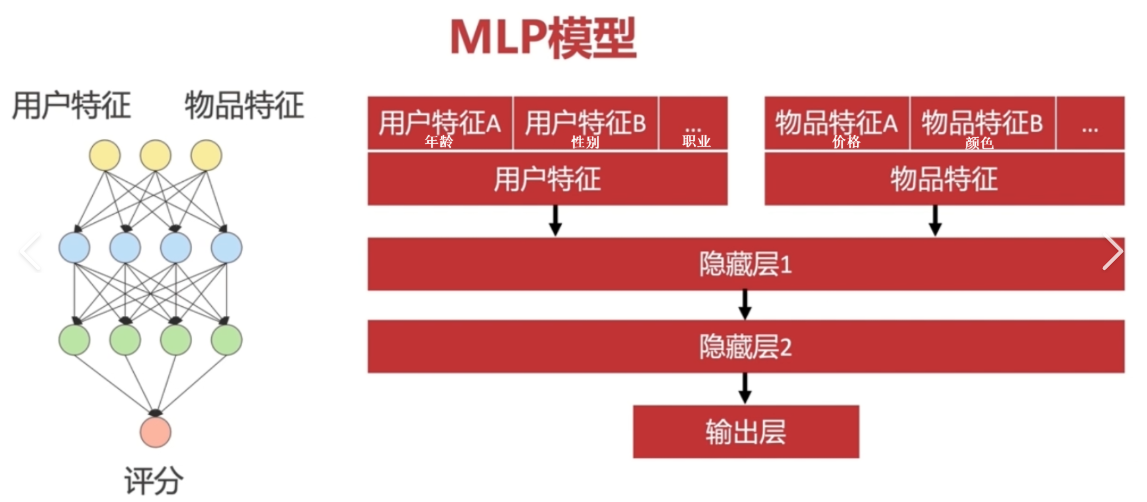
Embedding+MLP模型是处理高维稀疏特征 的经典架构,广泛应用于推荐系统、广告点击率预测(CTR)等场景。其核心思想是将类别型特征 通过Embedding层转换为低维稠密向量,再与连续特征拼接后输入多层感知机(MLP)。
类别特征 连续特征 输入特征 特征类型 Embedding层 归一化处理 特征向量 特征拼接 多层感知机 MLP 输出层 预测结果
关键组件
-
Embedding层:将高维稀疏的类别特征映射为低维稠密向量
- 输入:类别ID(整数索引)
- 输出:固定维度的浮点数向量
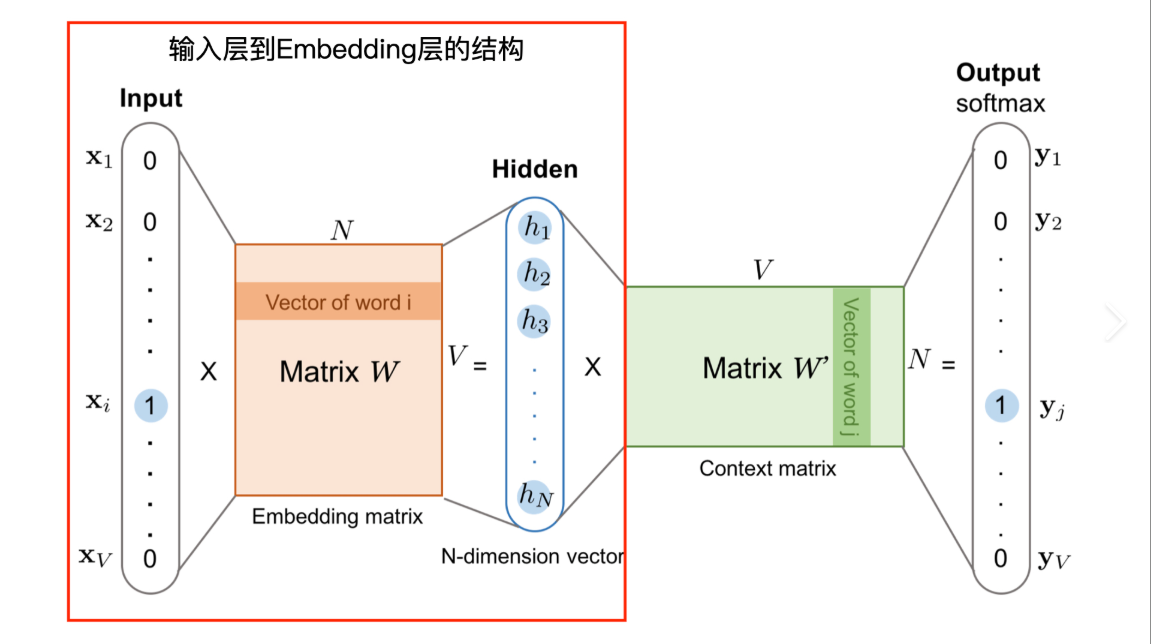
-
特征拼接层:将多个Embedding向量和连续特征拼接为单一特征向量
-
多层感知机(MLP) :由多个全连接层组成,学习特征间的非线性关系
2. 算法原理与数学推导
Embedding层原理
给定类别特征 i i i,其one-hot编码为 x ∈ { 0 , 1 } n \mathbf{x} \in \{0,1\}^n x∈{0,1}n,Embedding层本质是一个查找操作:
e i = W e T x \mathbf{e}_i = \mathbf{W}_e^T \mathbf{x} ei=WeTx
其中 W e ∈ R n × d \mathbf{W}_e \in \mathbb{R}^{n \times d} We∈Rn×d是嵌入矩阵, d d d是嵌入维度。实际实现中,等价于:
e i = W e i \mathbf{e}_i = \mathbf{W}_ei ei=Wei
MLP前向传播
设拼接后的特征向量为 h ( 0 ) \mathbf{h}^{(0)} h(0),MLP的第 l l l层计算为:
z ( l ) = W ( l ) h ( l − 1 ) + b ( l ) \mathbf{z}^{(l)} = \mathbf{W}^{(l)} \mathbf{h}^{(l-1)} + \mathbf{b}^{(l)} z(l)=W(l)h(l−1)+b(l)
h ( l ) = σ ( z ( l ) ) \mathbf{h}^{(l)} = \sigma(\mathbf{z}^{(l)}) h(l)=σ(z(l))
其中 σ \sigma σ是激活函数(如ReLU),最后一层使用sigmoid或softmax激活。
反向传播与优化
使用交叉熵损失函数:
L = − 1 N ∑ i = 1 N y i log ( y \^ i ) + ( 1 − y i ) log ( 1 − y \^ i ) \mathcal{L} = -\frac{1}{N} \sum_{i=1}^{N} y_i \\log(\\hat{y}_i) + (1-y_i)\\log(1-\\hat{y}_i) L=−N1i=1∑Nyilog(y\^i)+(1−yi)log(1−y\^i)
通过链式法则计算梯度:
∂ L ∂ W ( l ) = ∂ L ∂ z ( l ) ∂ z ( l ) ∂ W ( l ) \frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(l)}} = \frac{\partial \mathcal{L}}{\partial \mathbf{z}^{(l)}} \frac{\partial \mathbf{z}^{(l)}}{\partial \mathbf{W}^{(l)}} ∂W(l)∂L=∂z(l)∂L∂W(l)∂z(l)
使用Adam等优化器更新参数:
W ( l ) ← W ( l ) − η ∂ L ∂ W ( l ) \mathbf{W}^{(l)} \leftarrow \mathbf{W}^{(l)} - \eta \frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(l)}} W(l)←W(l)−η∂W(l)∂L
3. 模型评估
常用评估指标
| 指标 | 公式 | 适用场景 |
|---|---|---|
| AUC | $$ \frac{\sum_{i \in P} \sum_{j \in N} I(\hat{y}_i > \hat{y}_j)}{ | P |
| LogLoss | − 1 N ∑ i = 1 N y i log y \^ i + ( 1 − y i ) log ( 1 − y \^ i ) -\frac{1}{N} \sum_{i=1}^N y_i \\log \\hat{y}_i + (1-y_i)\\log(1-\\hat{y}_i) −N1i=1∑Nyilogy\^i+(1−yi)log(1−y\^i) | 概率预测质量 |
| Precision | T P T P + F P \frac{TP}{TP + FP} TP+FPTP | 关注假正例成本 |
| Recall | T P T P + F N \frac{TP}{TP + FN} TP+FNTP | 关注假负例成本 |
评估方法
- 离线评估:时间窗口划分训练/测试集
- 在线评估:A/B测试
- 特征重要性分析:通过消融实验评估特征贡献
4. 应用案例:推荐系统CTR预测
问题描述
预测用户点击广告的概率,特征包括:
- 用户特征:ID、年龄、性别
- 广告特征:ID、类别、价格
- 上下文特征:时间、位置
模型架构
用户ID User Embedding 广告ID Ad Embedding 广告类别 Category Embedding 用户年龄 归一化 广告价格 特征拼接 全连接层 256 全连接层 128 全连接层 64 Sigmoid输出
性能优化
- 特征分桶:连续特征离散化
- 注意力机制:加权重要特征
- 多任务学习:同时优化CTR和CVR
5. 常见面试题
-
为什么需要Embedding层?直接使用one-hot编码输入MLP有什么问题?
- 高维稀疏性导致参数爆炸( n n n类特征需要 n n n维输入)
- 缺乏语义相似性(所有类别相互独立)
- 计算效率低下(矩阵运算低效)
-
如何确定Embedding维度?
- 经验公式: d = 6 × category_size 0.25 d = 6 \times \text{category\_size}^{0.25} d=6×category_size0.25
- 网格搜索:尝试8/16/32/64等常用维度
- 自动学习:通过矩阵分解确定最优维度
-
如何处理未见过的类别(冷启动问题)?
- 使用哈希技巧: h ( id ) m o d B h(\text{id}) \mod B h(id)modB
- 分配默认Embedding向量
- 建立外部KV存储动态更新Embedding
-
如何加速Embedding层训练?
python# TensorFlow优化示例 embedding_layer = tf.keras.layers.Embedding( input_dim=10000, output_dim=64, embeddings_initializer='uniform', embeddings_regularizer=tf.keras.regularizers.l2(1e-6) )
6. 优缺点分析
优点
- 高效处理稀疏特征:Embedding层大幅降低维度
- 特征自动学习:端到端学习特征表示
- 灵活可扩展:易于添加新特征
- 捕获非线性关系:MLP拟合复杂模式
缺点
- 特征交互有限:难以学习显式特征交叉
- 顺序不敏感:拼接操作丢失特征顺序信息
- 冷启动问题:新类别预测效果差
- 解释性差:Embedding向量难以解释
改进方向
| 问题 | 解决方案 | 代表模型 |
|---|---|---|
| 特征交互浅 | 显式特征交叉 | DeepFM, xDeepFM |
| 顺序不敏感 | 序列建模 | DIN, DIEN |
| 冷启动 | 元学习, 图网络 | MAML, GNN |
7. TensorFlow实现详解
完整实现代码
python
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, Dense, Concatenate
from tensorflow.keras.models import Model
from tensorflow.keras.regularizers import l2
def build_embedding_mlp(categorical_feature_info, continuous_feature_names, embedding_dim=16, hidden_units=[256, 128, 64]):
# 输入层定义
inputs = {}
# 类别特征输入
for name, vocab_size in categorical_feature_info.items():
inputs[name] = Input(shape=(1,), name=name, dtype=tf.int32)
# 连续特征输入
for name in continuous_feature_names:
inputs[name] = Input(shape=(1,), name=name, dtype=tf.float32)
# Embedding层
embeddings = []
for name, vocab_size in categorical_feature_info.items():
embedding = Embedding(
input_dim=vocab_size + 1, # +1 for unknown
output_dim=embedding_dim,
embeddings_regularizer=l2(1e-6),
name=f'embed_{name}'
)(inputs[name])
embeddings.append(tf.squeeze(embedding, axis=1))
# 连续特征处理
normalized_conts = [tf.keras.layers.BatchNormalization()(inputs[name])
for name in continuous_feature_names]
# 特征拼接
concat = Concatenate(axis=1)(embeddings + normalized_conts)
# MLP部分
x = concat
for i, units in enumerate(hidden_units):
x = Dense(units, activation='relu',
kernel_regularizer=l2(1e-5),
name=f'fc_{i}')(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Dropout(0.3)(x)
# 输出层
output = Dense(1, activation='sigmoid', name='output')(x)
# 构建模型
model = Model(inputs=list(inputs.values()), outputs=output)
# 编译模型
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['accuracy', tf.keras.metrics.AUC(name='auc')]
)
return model
# 使用示例
categorical_features = {'user_id': 10000, 'item_id': 5000, 'category': 100}
continuous_features = ['age', 'price']
model = build_embedding_mlp(categorical_features, continuous_features)
model.summary()关键实现细节
-
动态输入处理:
python# 灵活处理不同特征 inputs = {name: Input(shape=(1,), name=name, dtype=dtype) for name in feature_names} -
Embedding优化:
python# 使用正则化防止过拟合 Embedding(..., embeddings_regularizer=l2(1e-6)) -
特征归一化:
python# BatchNorm加速收敛 tf.keras.layers.BatchNormalization()(continuous_input) -
防止过拟合:
python# Dropout层 x = tf.keras.layers.Dropout(0.3)(x) # L2正则化 Dense(..., kernel_regularizer=l2(1e-5))
训练优化技巧
-
样本不平衡处理:
pythonmodel.fit(..., class_weight={0: 1, 1: 10}) # 增加正样本权重 -
动态学习率:
pythonlr_schedule = tf.keras.callbacks.ReduceLROnPlateau( monitor='val_loss', factor=0.5, patience=3) -
早停机制:
pythonearly_stop = tf.keras.callbacks.EarlyStopping( monitor='val_auc', patience=5, mode='max') -
大数据集训练:
python# 使用TF Dataset优化 dataset = tf.data.Dataset.from_tensor_slices((features, labels)) dataset = dataset.shuffle(100000).batch(512).prefetch(2)
总结
Embedding+MLP模型通过特征嵌入 和多层感知机的组合,有效解决了高维稀疏特征的处理问题,成为推荐系统、广告点击率预测等领域的基准模型。TensorFlow提供了灵活高效的实现方式:
- 特征处理:Embedding层高效处理类别特征
- 模型架构:灵活拼接+深度MLP捕获复杂模式
- 优化技术:正则化、归一化、动态学习率提升性能
- 评估体系:AUC、LogLoss等指标全面评估
尽管后续发展出更复杂的模型,Embedding+MLP因其简单高效 、易于实现的特点,仍是工业界广泛使用的解决方案。掌握其核心原理和TensorFlow实现,是深入理解现代深度学习推荐系统的重要基础。