摘要:检索增强型语言模型(Retrieval-Augmented Language Models,RALMs)是一种经典范式,模型通过专门模块检索外部知识来增强生成能力。最近在Agent技术方面的进展使得大型语言模型(LLMs)能够自主利用工具进行检索、规划和推理。尽管现有的基于训练的方法显示出潜力,但它们的Agent能力受到训练中使用任务特定数据的固有特性的限制。为了进一步增强Agent的通用搜索能力,我们提出了一个新的预训练框架------MASKSEARCH。在预训练阶段,我们引入了检索增强掩码预测(Retrieval Augmented Mask Prediction,RAMP)任务,模型通过利用搜索工具填补大量预训练数据中的掩码片段,从而为LLMs获得通用的检索和推理能力。之后,模型在下游任务上进行训练以实现进一步提升。我们同时应用了监督微调(Supervised Fine-tuning,SFT)和强化学习(Reinforcement Learning,RL)进行训练。对于SFT,我们结合了基于Agent和基于蒸馏的方法来生成训练数据,从由规划器、改写器、观察者组成的多Agent系统开始,随后是一个自我进化的教师模型。而对于RL,我们采用DAPO作为训练框架,并采用由答案奖励和格式奖励组成的混合奖励系统。此外,我们引入了一种课程学习方法,允许模型根据掩码片段的数量从简单到复杂逐步学习实例。我们在开放域多跳问答场景中评估了我们框架的有效性。通过广泛的实验,我们证明了MASKSEARCH显著提升了基于LLM的搜索Agent在领域内和领域外下游任务上的性能。
本文目录
[3.1 检索增强掩码预测(RAMP)](#3.1 检索增强掩码预测(RAMP))
[3.2 两阶段训练流程](#3.2 两阶段训练流程)
[4.1 性能提升](#4.1 性能提升)
[4.2 模型规模影响](#4.2 模型规模影响)
[4.3 消融对比结果](#4.3 消融对比结果)
一、背景动机
**论文题目:**MASKSEARCH: A Universal Pre-Training Framework to Enhance Agentic Search Capability
论文地址: https://arxiv.org/pdf/2505.20285
- **大模型的知识缺陷:**LLMs在处理领域特定或实时任务时容易产生幻觉,依赖内部静态知识,无法动态获取外部信息。
- 检索增强语言模型(RALMs)的不足:传统RALMs通过独立检索模块获取知识,但检索与生成过程分离,难以应对多步推理任务,缺乏主动利用工具的能力。
- **智能体技术存在问题:**基于LLM的智能体可自主规划、调用工具(如搜索引擎),但现有训练方法依赖任务特定数据,泛化能力受限,尤其在跨领域任务中表现不足。
故如何让模型在预训练阶段学会通用的检索与推理能力,使其能灵活适应不同下游任务(如开放域多跳问答),而非依赖特定任务的数据是当前研究的缺失,本文提出了一个新的预训练框架------MASKSEARCH。在预训练阶段,我们引入了检索增强掩码预测(Retrieval Augmented Mask Prediction,RAMP)任务,模型通过利用搜索工具填补大量预训练数据中的掩码片段,从而为LLMs获得通用的检索和推理能力。
二、核心贡献
1. 提出MASKSEARCH框架
- 检索增强掩码预测任务(RAMP) :通过掩码文本中的关键跨度(如实体、数值),强制模型通过多步搜索和推理填充掩码,学习任务分解、工具调用和观察推理能力。
- 两阶段训练策略 :
- 阶段1:预训练(SFT/RL):利用RAMP任务注入通用检索推理能力。
- 阶段2:下游任务微调 :结合具体任务(如问答)进一步优化。
2. 混合数据构建
- 结合多智能体系统(规划器、重写器、观察者)和自进化蒸馏,生成高质量推理轨迹(CoT),解决数据规模与质量的平衡问题。
3. 动态奖励与课程学习
- 混合奖励系统 :结合格式奖励(响应结构)和答案奖励(正确性),避免奖励欺骗。
- 课程学习 :按掩码数量递增难度,逐步提升模型处理复杂任务的能力。
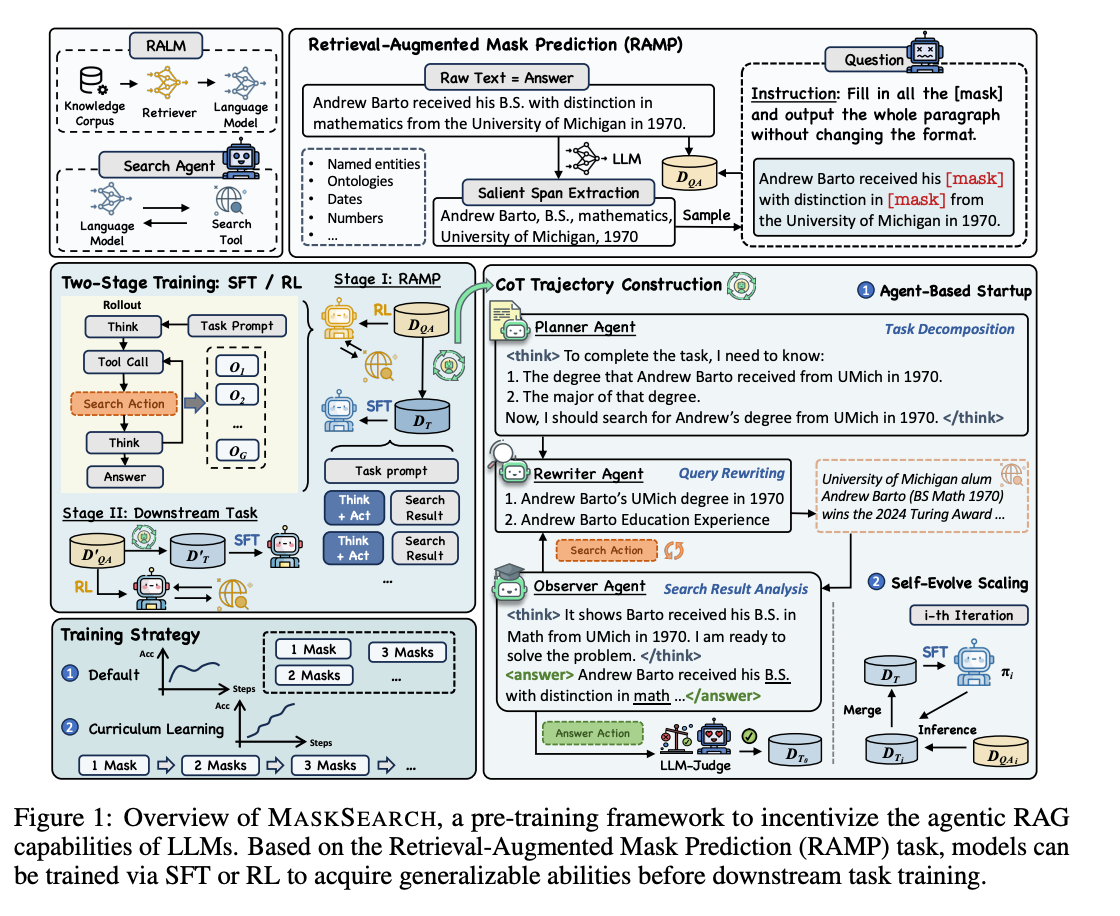
三、实现方法
3.1 检索增强掩码预测(RAMP)
-
数据构建 :
-
从维基百科提取文本,使用Qwen-Turbo识别 显著跨度 (实体、日期、数值等),随机掩码1-4个跨度生成训练样本。
原始文本:Andrew Barto received his B.S. in mathematics from the University of Michigan in 1970.
掩码文本:Andrew Barto received his [mask] with distinction in [mask] from the University of Michigan in 1970.
-
-
目标 :模型需通过多步搜索(如查询"Andrew Barto UMich degree 1970")和推理填充掩码,输出完整正确的文本。
3.2 两阶段训练流程
阶段1:预训练(SFT和RL)
监督微调(SFT) :
- 多智能体数据生成 :
- 规划器(Planner)分解任务为子问题,生成初始搜索查询。
- 观察者(Observer)分析搜索结果,决定是否继续搜索或生成答案。
- 重写器(Rewriter)优化查询以提升检索效果。
- 自进化蒸馏 :用训练好的教师模型迭代生成更复杂的推理轨迹,扩大数据集(如从58K到10M样本)。
强化学习(RL) :
- 采用DAPO算法,结合动态采样和令牌级策略梯度,优化模型的搜索策略。
- 奖励函数 :
- 格式奖励(R_f) :响应是否符合指定格式(如包含搜索标记、推理步骤)。
- 答案奖励(R_a) :基于令牌级召回率(TR)或模型评分(如Qwen2.5-72B-Instruct作为裁判),避免长度欺骗。
阶段2:下游任务微调
- 针对具体任务(如多跳问答),使用RAMP预训练模型作为初始化,进一步微调以适应任务特性。
四、实验结论
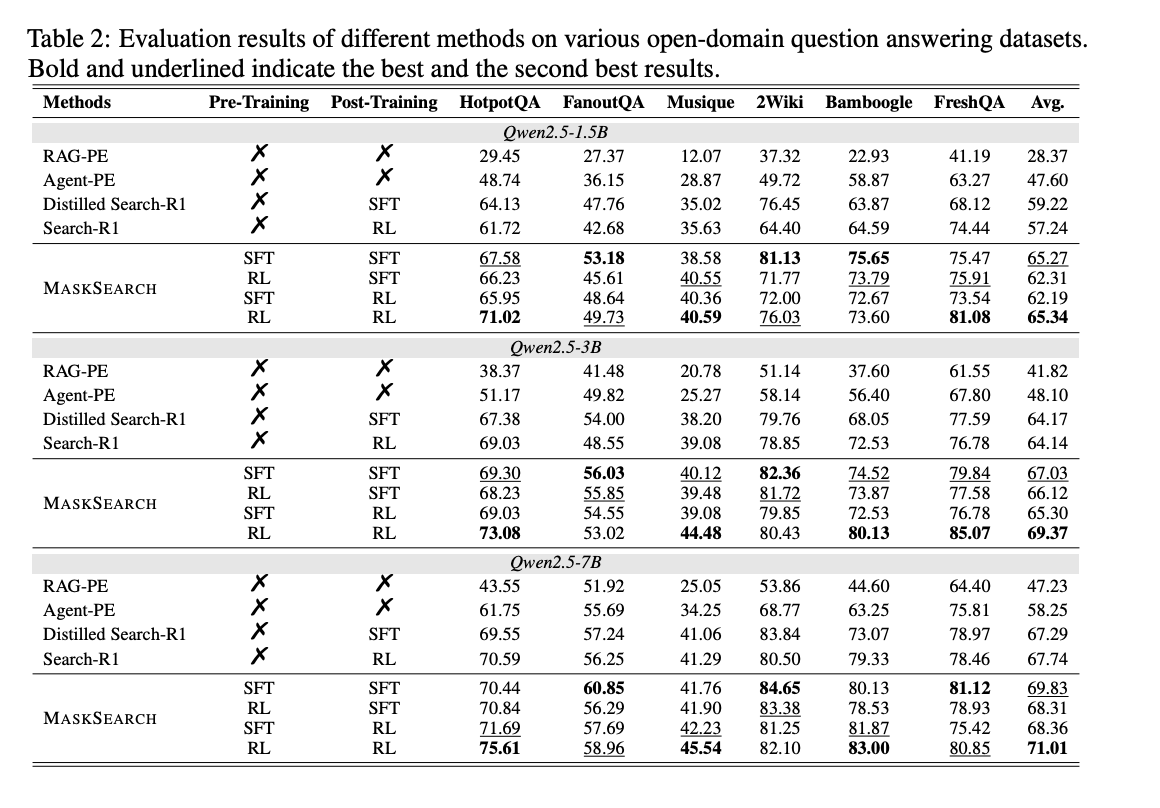
4.1 性能提升
- 在HotpotQA(内域任务)上,MASKSEARCH(SFT+RL)较基线模型(如Search-R1)提升3-5%召回率。
- 在跨领域任务(如Bamboogle、FreshQA)中,提升幅度更大(平均+10%以上),证明其泛化能力。
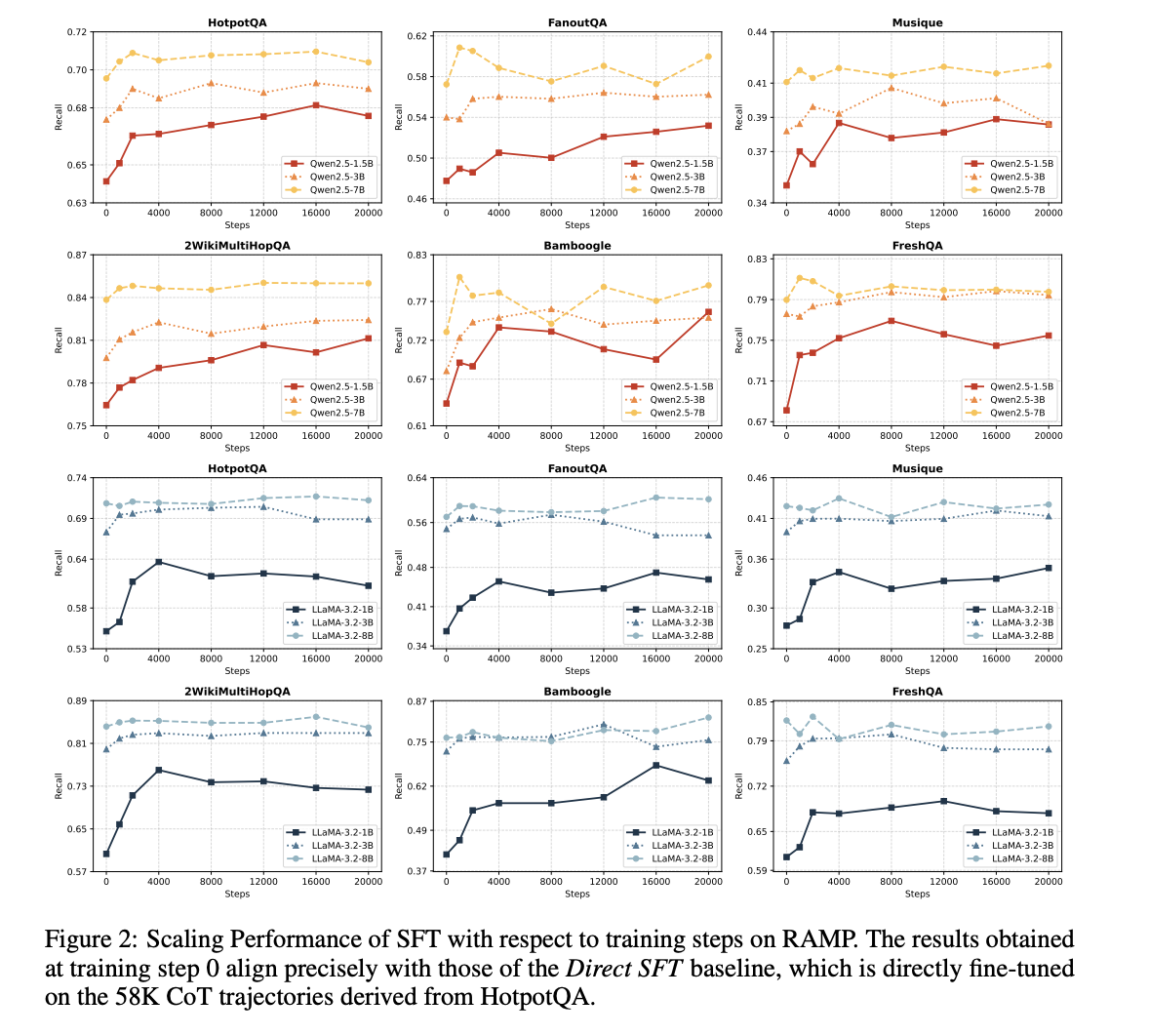
4.2 模型规模影响
- 小模型(如Qwen2.5-1.5B)通过RAMP预训练,性能接近甚至超越未预训练的大模型(如LLaMA-3.2-8B)。
- 大模型(如Qwen2.5-7B)在自进化蒸馏后,性能进一步提升,表明数据质量与规模的重要性。
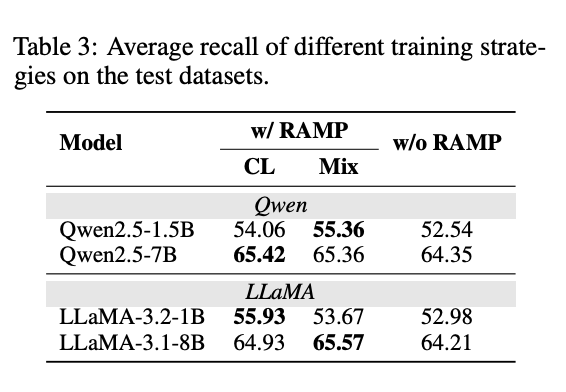
4.3 消融对比结果
- RAMP的必要性 :
- 无RAMP预训练时,模型在跨领域任务中性能显著下降(平均-5%),验证预训练阶段获取通用能力的关键作用。
- 奖励函数效果 :
- 基于模型评分的奖励(Model-based Reward)优于单纯召回奖励,有效抑制响应长度欺骗,提升答案准确性。

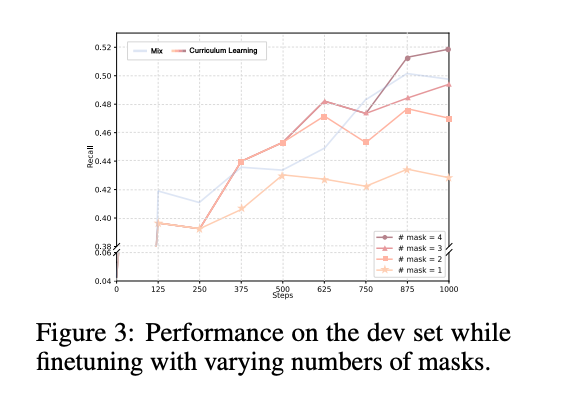
- 课程学习的有效性
- 按掩码数量递增训练的模型,在验证集上的表现优于随机混合训练,尤其在高掩码数量(k=4)时优势明显,证明逐步挑战策略的合理性。
五、总结
该文章将智能体的检索推理能力融入预训练框架,通过RAMP任务实现通用工具调用与多步推理的统一建模。结合多智能体数据生成、自进化蒸馏和动态奖励机制,解决传统方法依赖任务特定数据的局限。