点一下关注吧!!!非常感谢!!持续更新!!!
🚀 大模型与Java双线更新中!
目前《大语言模型实战》已连载至第22篇,探索 MCP 自动操作 Figma+Cursor 实现智能原型设计,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
MyBatis 已完结,Spring 正在火热更新中,深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
Audiblez
官方地址
https://github.com/santinic/audiblez
项目介绍
下面是项目组对项目的介绍:
● Audiblez 是一个工具,它可以将普通的 .epub 电子书转换成 .m4b 格式的有声书,使用的是名为 -Kokoro 的高质量语音合成技术。
● Kokoro-82M 是最近发布的一个文本转语音(Text-to-Speech, TTS)模型,参数量仅有 8200 万(82M),但生成的语音听起来非常自然。这个模型是以 Apache 许可证 开源发布的,并且它的训练数据量少于 100 小时的音频。目前支持的语言包括:英语(美式 🇺🇸、英式 🇬🇧)、西班牙语 🇪🇸、法语 🇫🇷、印地语 🇮🇳、意大利语 🇮🇹、日语 🇯🇵、葡萄牙语(巴西)🇧🇷、中文 🇨🇳。
● 在 Google Colab 上,使用 T4 GPU + CUDA,转换乔治·奥威尔的《动物农庄》(约 16 万字符)为有声书大约需要 5 分钟,速度大约是每秒 600 字符。
● 而在我自己的 M2 MacBook Pro(CPU 上运行) 上,则需要 1 小时,转换速度约为每秒 60 字符。
核心功能
- 多语言支持:支持英语(美式和英式)、西班牙语、法语、印地语、意大利语、日语、葡萄牙语(巴西)和中文(普通话)等多种语言。
- 语音选择:用户可通过 -v 参数选择不同的语音,例如 af_sky 表示美式英语女性声音。
- 语速调节:通过 -s 参数调整语速,范围从 0.5 到 2.0。
- GPU 加速:支持 CUDA,可在支持的 GPU 上加速音频生成。
- 章节选择:使用 --pick 参数可交互式选择要转换的章节。
- 图形界面:提供基于 wxWidgets 的跨平台 GUI,适用于 macOS、Windows 和 Linux。
性能表现
- GPU 加速:在 Google Colab 的 T4 GPU 上,转换《动物农庄》(约 16 万字符)仅需约 5 分钟,速度约为 600 字符/秒。
- CPU 模式:在 M2 MacBook Pro 上,转换同一本书约需 1 小时,速度约为 60 字符/秒。
环境配置
MacOS
我这里是在MacOS上,所以我们需要安装一些依赖
shell
brew install ffmpeg espeak-ng
pip install audiblezbrew 安装依赖:
pip 安装依赖:
Ubuntu
shell
sudo apt install ffmpeg espeak-ng
pip install audiblez这里略过,就不在 Ubuntu 上跑了。
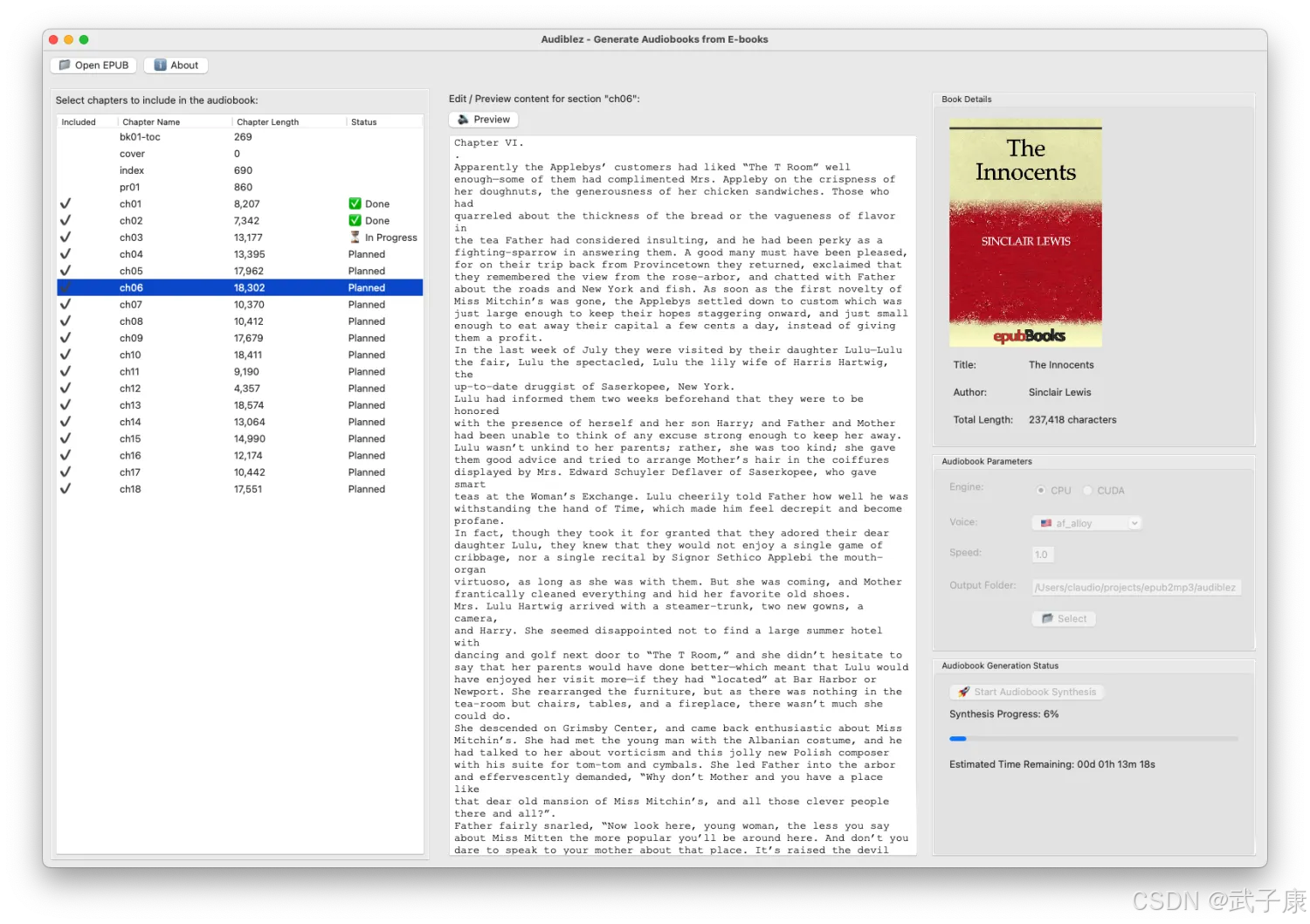
测试使用
我们准备一个文件:rpc.epub
指令模式
shell
audiblez rpc.epub -v zf_xiaoyi转换开始,要耐心等待一会儿:
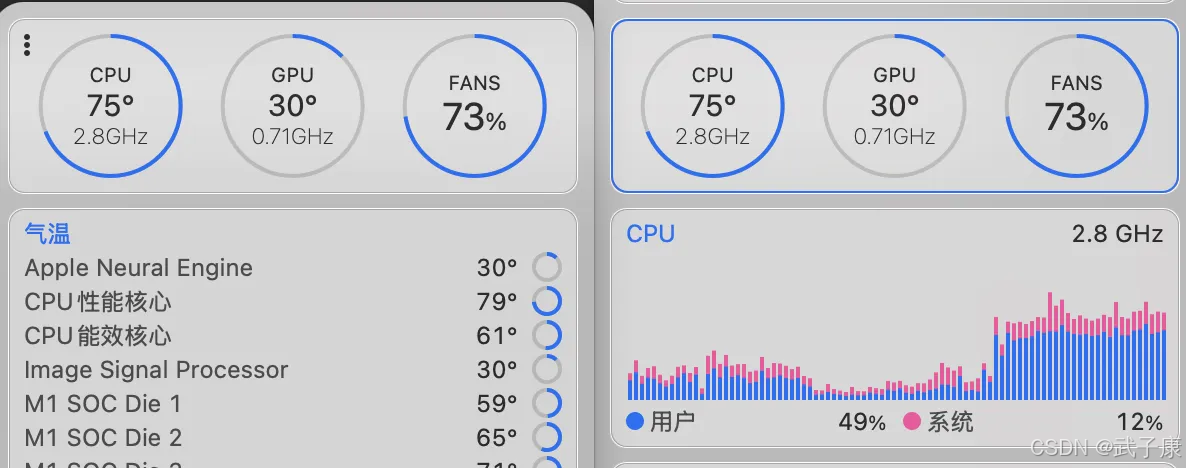
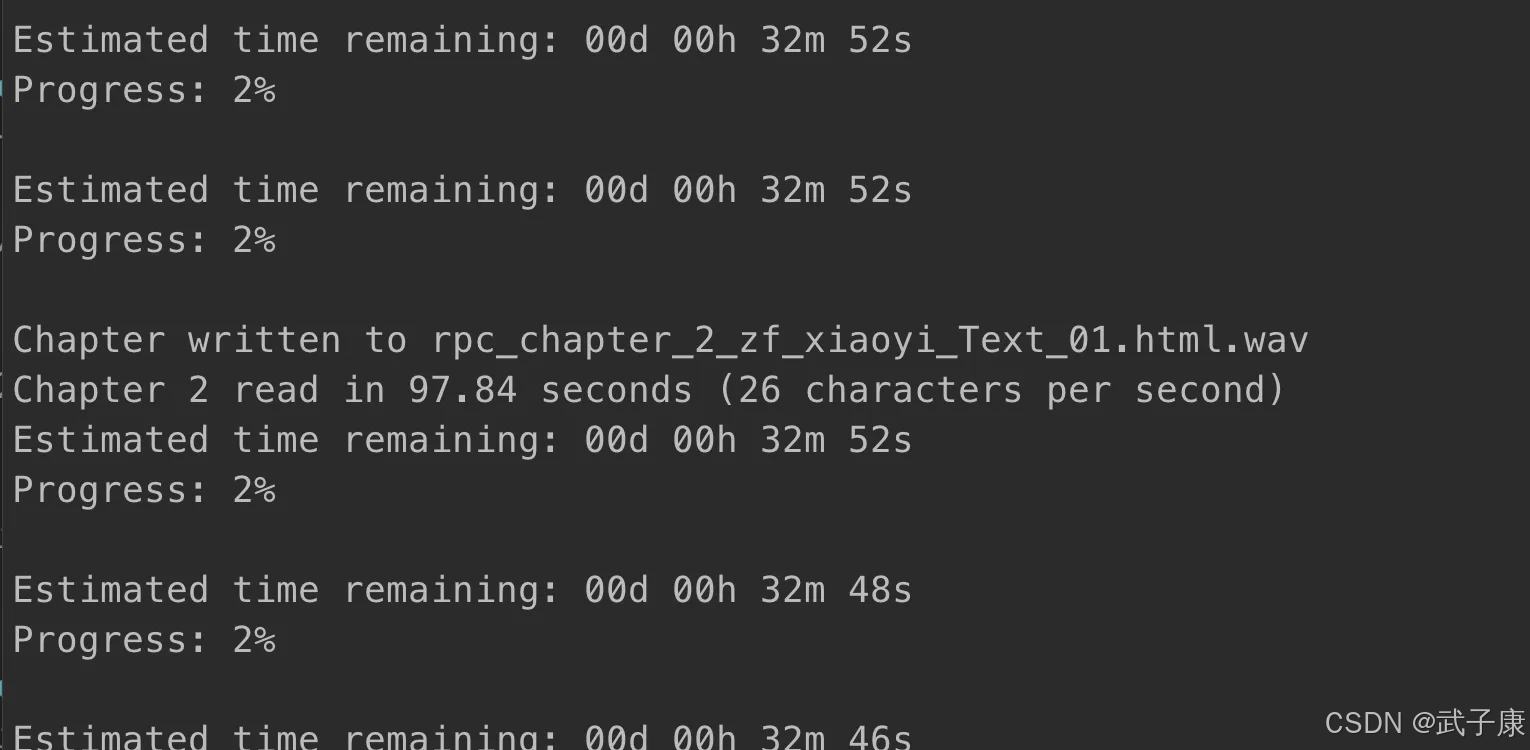
我在 MacBook Pro M1 上跑的,需要等待很久···
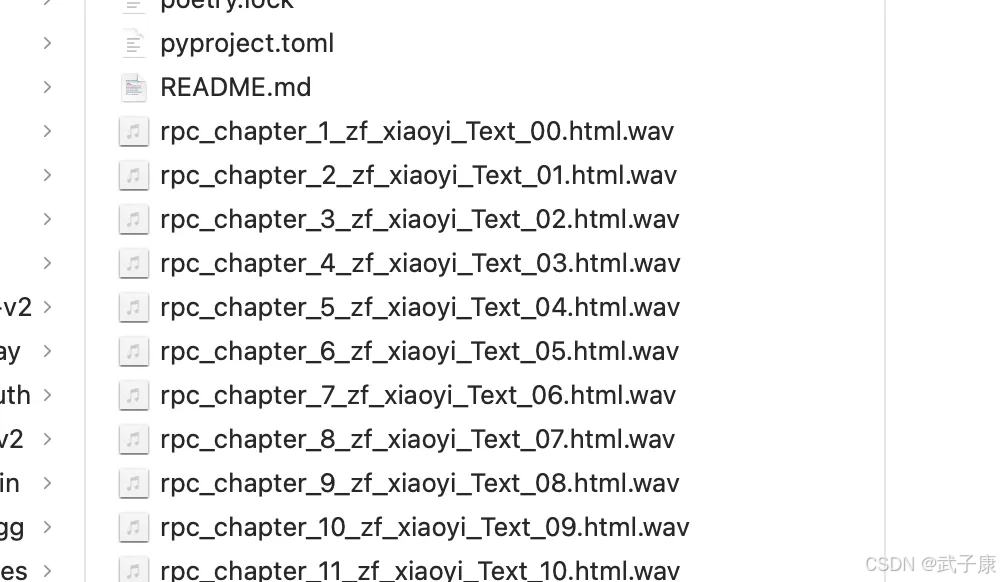
最终成品如下所示:
UI模式
shell
sudo apt install ffmpeg espeak-ng
# just for Ubuntu/Debian 🐧, Windows/Mac don't need this
sudo apt install libgtk-3-dev安装下面的依赖:
shell
pip install audiblez pillow wxpython执行指令:
shell
audiblez-ui语言支持
支持的如下所示

支持的语音示例
Audiblez 提供多种语音选项,涵盖多种语言和性别。例如:
- 美式英语:af_sky(女性)、am_michael(男性)
- 英式英语:bf_emma(女性)、bm_george(男性)
- 西班牙语:ef_dora(女性)、em_alex(男性)
- 法语:ff_siwis(女性)
- 中文(普通话):zf_xiaoxiao(女性)、zm_yunxi(男性)
常见问题与解决方案
- 章节识别问题:部分用户反馈某些 .epub 文件的章节未被正确识别。开发者已在 v0.1.7 版本中修复了该问题。
- 中文段落截断:在处理中文文本时,超过 200 个字符的段落可能会被截断为 120-130 个字符。开发者正在积极解决此问题。
- Windows 安装问题:建议在 Windows 上使用 Python 虚拟环境,并确保安装了必要的依赖项,如 ffmpeg 和 espeak-ng。