摘要
在大型预训练模型(LPMs)日益成为人工智能基石的当下,其庞大的参数量给传统全参数微调带来了巨大的资源和效率挑战。为应对此,参数高效微调(PEFT)技术应运而生。本文将深入聚焦PEFT中的核心技术------LoRA(Low-Rank Adaptation)。阐述LoRA如何通过引入低秩矩阵,在冻结原始模型权重的前提下,高效地实现模型对特定任务的适应。本文将演示如何利用Hugging Face生态系统进行LoRA微调实践。
关键词: 大模型, LoRA, 低秩微调, PEFT, 参数高效微调, Transformer, QLoRA, 深度学习, 自然语言处理
引言:大模型挑战与PEFT的破局
1.1 大模型崛起与微调的困境
近年来,随着算力突破与海量数据积累,Transformer架构驱动的大规模预训练模型(LPMs)在自然语言处理、计算机视觉及多模态领域取得了革命性进展,展现出惊人的泛化与涌现能力。然而,这些模型动辄数十亿甚至数万亿的参数量,在将其应用于特定下游任务时,传统的**全参数微调(Full Fine-tuning)**方法面临着严峻的挑战。
1.2 参数高效微调(PEFT)的应运而生
为有效解决上述挑战,参数高效微调(Parameter-Efficient Fine-tuning, PEFT) 技术应运而生。PEFT的核心理念是:在微调过程中,仅更新模型中的一小部分参数,或引入少量额外参数,而将大部分预训练模型参数冻结。此举既能使模型适应特定任务,又可大幅降低计算与存储开销,并有效缓解灾难性遗忘问题。
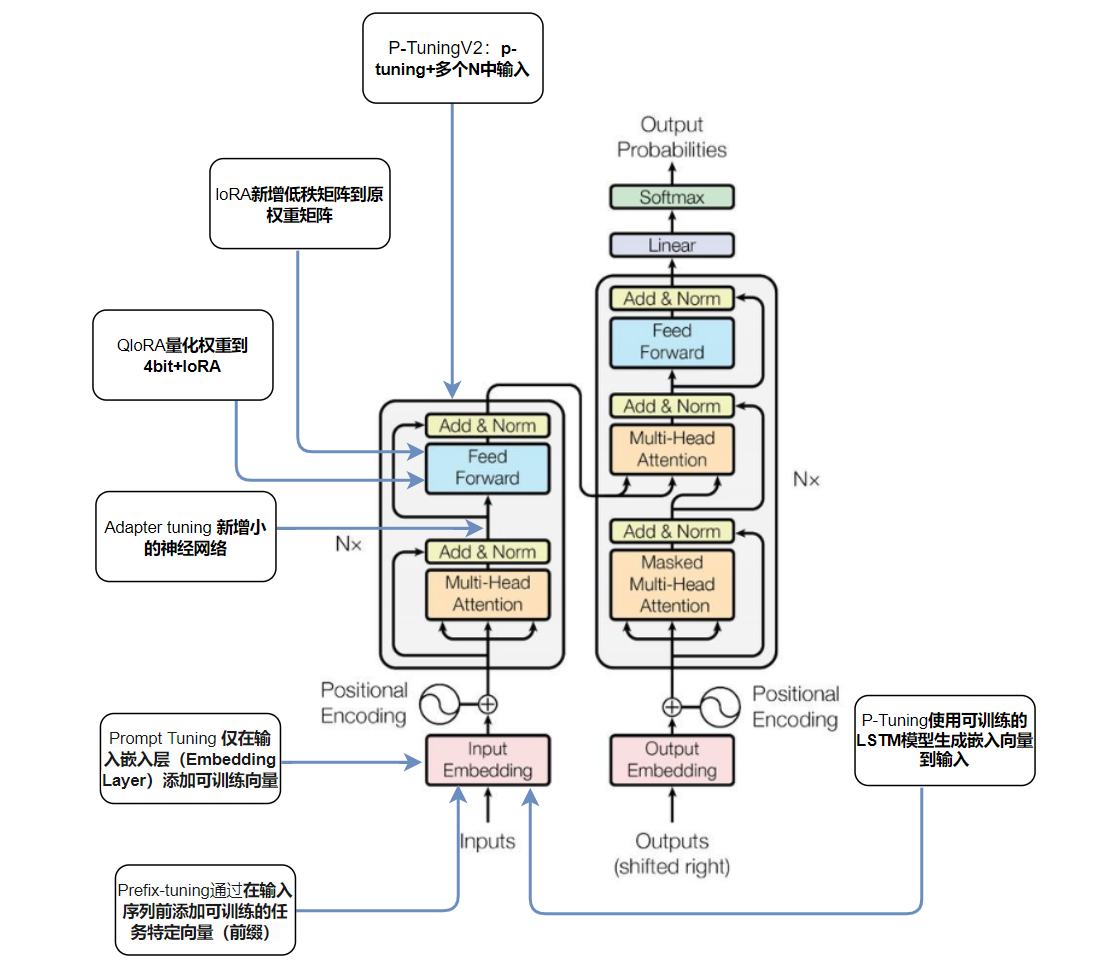
当前主流PEFT方法包括:
-
Adapter Tuning:在预训练模型层间插入小型可训练模块。
-
Prompt Tuning / P-Tuning v2:通过学习连续的"软提示"来引导模型行为。
-
LoRA (Low-Rank Adaptation):本文的重点,通过向预训练模型的特定权重矩阵注入可训练的低秩矩阵来适应新任务。
LoRA凭借其卓越的性能与极致的效率,已迅速成为大模型微调领域的事实标准。
第一部分:核心概念与基础
在探究LoRA的核心原理之前,我们先理解其赖以建立的几个关键概念。
2.1 大模型微调痛点总结
-
内存/显存瓶颈:模型参数、梯度、优化器状态、激活值等占据大量GPU显存,单张GPU难以承载。
-
计算效率低下:每次迭代需处理全部参数,训练速度缓慢。
-
存储与管理挑战:为不同任务维护多个完整模型副本,存储成本与管理复杂性极高。
这些挑战促使我们寻求更优的微调策略,即PEFT,而LoRA正是其中的杰出代表。
2.2 矩阵的低秩分解基础
LoRA的核心思想源于线性代数中的矩阵低秩分解。
2.2.1 矩阵的秩(Rank)
一个矩阵的秩表示其列向量(或行向量)中最大线性无关组的个数,直观反映了矩阵的"信息维度"或"复杂度"。一个 d x k 矩阵 W 的秩 r 满足 r <= min(d, k)。当 r 远小于 min(d, k) 时,我们称该矩阵为低秩矩阵。
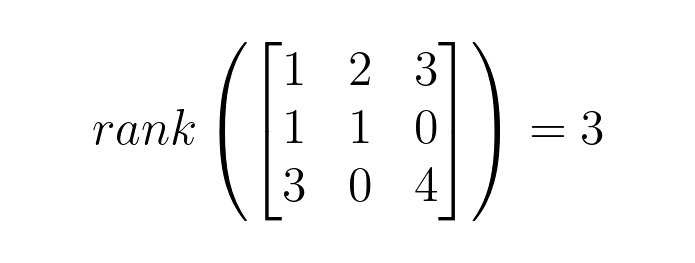
2.2.2 低秩近似与参数压缩
一个秩为 r 的 d x k 矩阵 W 可以被分解为两个更小矩阵的乘积来近似:
W ≈ A B
其中 A 是一个 d x r 的矩阵,B 是一个 r x k 的矩阵。
-
原始矩阵 W 的参数量为 d * k。
-
分解后 A 和 B 的总参数量为 d * r + r * k = r * (d + k)。
当 r << min(d, k) 时,r * (d + k) 将远小于 d * k。例如,d=1024, k=1024, r=4 时,参数量从 1M 骤降至 8K,减少了近130倍。这一参数压缩原理正是LoRA高效性的基石。
第二部分:LoRA 原理深度解析
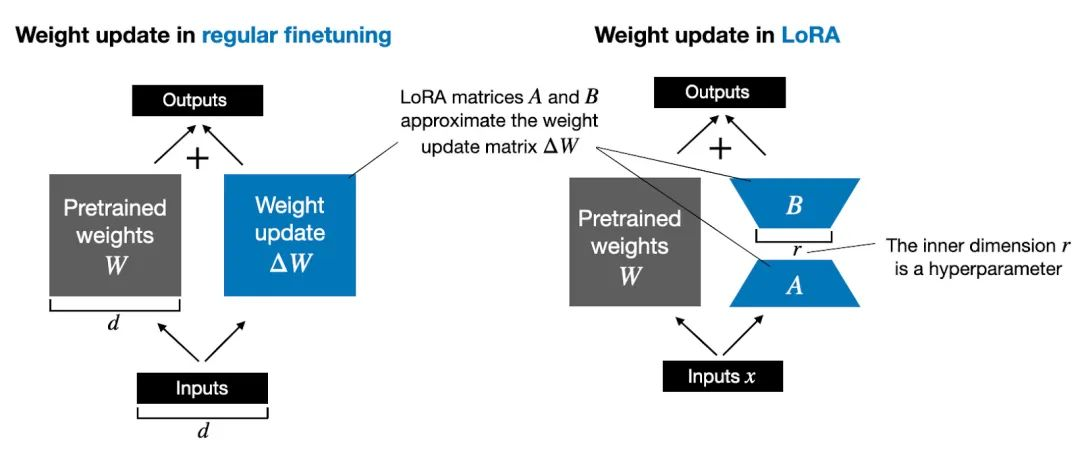
LoRA(Low-Rank Adaptation of Large Language Models)由Microsoft于2021年提出。其核心在于:在微调大模型时,通过向预训练权重矩阵中并行注入一对低秩矩阵来适应新任务,而原始预训练权重保持冻结。
3.1 LoRA 核心机制
设预训练模型中的一个权重矩阵为 W_0,维度为 d x k。LoRA假设微调过程中权重的增量 ΔW 实际上是一个低秩矩阵。
因此,LoRA不直接更新 ΔW,而是将其分解为两个低秩矩阵的乘积:
ΔW = B A
其中,B 是 d x r 矩阵,A 是 r x k 矩阵,r 是我们设定的秩(rank),且 r << min(d, k)。
训练时,我们冻结 W_0,仅优化 A 和 B。前向传播时,更新后的权重 W' 计算如下:
W' = W_0 + ΔW = W_0 + B A
推理时,可将 BA 的结果与 W_0 合并(W' = W_0 + BA),形成一个新的标准权重矩阵,从而不增加推理时的计算开销和延迟。
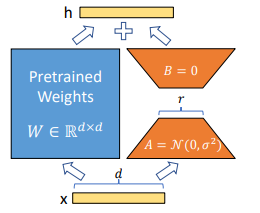
缩放因子(Scaling Factor)alpha
为更好地控制 ΔW 的影响,LoRA引入了缩放因子 α。实际计算中,ΔW 的输出会被 α/r 进行缩放:
h = W_0 x + (B A) x * (α / r)
-
α 是超参数,通常与 r 保持一致或设为固定值(如 16 或 32)。
-
除以 r 旨在平衡不同 r 值下的优化过程,防止 α 过大导致训练不稳定,使得 ΔW 的相对大小在不同 r 值下保持一致。
3.2 LoRA 在 Transformer 架构中的应用
LoRA通常应用于Transformer模型的注意力权重矩阵,特别是W_q(Query)、W_v(Value)的投影矩阵。这是因为研究表明,这些矩阵在微调中展现出更强的低秩特性,且对其微调能有效提升模型性能。当然,LoRA也可应用于W_k(Key)、W_o(Output)以及前馈网络(FFN)中的线性层。
3.3 LoRA 核心超参数
LoRA主要依赖以下几个关键超参数:
-
秩 (r):LoRA中最重要的超参数,决定了 A 和 B 的维度。r 越大,模型表达能力越强,但参数量也越多。常见取值 4, 8, 16, 32, 64。经验表明,即使 r 较小(如 8 或 16),也能达到接近全参数微调的性能。
-
LoRA Alpha (alpha):缩放因子 α,实际缩放系数为 α/r。常见取值与 r 相同或为 r 的倍数(如 16 或 32)。
-
LoRA Dropout (lora_dropout):应用于 A 矩阵输出的Dropout比率,防止过拟合,提高泛化能力。通常设为 0.05 或 0.1。
-
目标模块 (target_modules):指定注入LoRA层的模型模块名称列表。对于Transformer模型,通常是注意力机制中的 query 和 value 投影层(如 q_proj, v_proj)。也可以包括 k_proj, out_proj 或 FFN 线性层。
第三部分:LoRA 实践与代码实现
本部分将提供一个使用Hugging Face transformers和peft库进行LoRA微调的完整代码示例。
4.1 准备环境与核心代码示例
import torch
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training, PeftModel
import os
# --- 1. 配置参数 ---
model_id = "THUDM/chatglm2-6b" # 替换为你希望微调的模型
dataset_name = "silk-road/alpaca-data-gpt4-chinese" # 替换为你希望使用的数据集
output_dir = "./lora_finetuned_model"
lora_r = 8 # LoRA的秩 (Rank),决定低秩矩阵的大小
lora_alpha = 16 # LoRA的缩放因子
lora_dropout = 0.05 # LoRA层的Dropout比率
# 对于ChatGLM2,target_modules通常是query_key_value和dense
# 对于LLaMA/Mistral/Baichuan,通常是['q_proj', 'v_proj', 'k_proj', 'o_proj']
# 你可以通过 print(model) 观察模型结构来确定
target_modules = ["query_key_value", "dense"]
per_device_train_batch_size = 2 # 根据GPU显存调整
gradient_accumulation_steps = 8 # 梯度累积步数,模拟更大batch size
learning_rate = 3e-4 # 学习率
num_train_epochs = 3 # 训练的epoch数
max_seq_length = 512 # 最大序列长度
# --- 2. 加载数据集与预处理 ---
print(f"正在加载数据集: {dataset_name}...")
dataset = load_dataset(dataset_name)
def preprocess_function(examples):
# 构建指令微调格式文本
texts = []
for instruction, input_text, output_text in zip(examples["instruction"], examples["input"], examples["output"]):
if input_text:
text = f"### 指令:\n{instruction}\n### 输入:\n{input_text}\n### 回复:\n{output_text}"
else:
text = f"### 指令:\n{instruction}\n### 回复:\n{output_text}"
texts.append(text)
return {"text": texts}
processed_dataset = dataset.map(preprocess_function, batched=True, remove_columns=["instruction", "input", "output"])
# 为了演示,只取一小部分数据进行训练
processed_dataset['train'] = processed_dataset['train'].select(range(min(1000, len(processed_dataset['train']))))
print(f"数据集处理完成,训练集大小: {len(processed_dataset['train'])}")
# --- 3. 加载分词器和模型 (QLoRA) ---
print(f"正在加载模型与分词器: {model_id}...")
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 配置4位量化 (QLoRA)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map="auto", # 自动选择设备(GPU)
trust_remote_code=True
)
# 准备模型进行kbit训练 (兼容PEFT)
model = prepare_model_for_kbit_training(model)
model.train() # 设置为训练模式
# --- 4. 配置并应用 LoRA ---
lora_config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
bias="none", # 通常不微调bias
task_type="CAUSAL_LM", # 任务类型为因果语言建模
target_modules=target_modules,
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 打印可训练参数量
# --- 5. 数据tokenization与Data Collator ---
def tokenize_function(examples):
# 对文本进行tokenize,并截断至最大长度
return tokenizer(examples["text"], truncation=True, max_length=max_seq_length)
tokenized_dataset = processed_dataset.map(
tokenize_function,
batched=True,
remove_columns=["text"],
)
# 过滤掉空的tokenized条目
tokenized_dataset = tokenized_dataset.filter(lambda x: len(x["input_ids"]) > 0)
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# --- 6. 定义训练参数 ---
training_args = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=learning_rate,
num_train_epochs=num_train_epochs,
logging_steps=10,
save_steps=100,
fp16=True, # 启用混合精度训练
warmup_ratio=0.03,
lr_scheduler_type="cosine",
optim="paged_adamw_8bit", # QLoRA推荐的8位优化器
remove_unused_columns=False,
report_to="tensorboard",
)
# --- 7. 创建 Trainer 并开始训练 ---
print("开始训练 LoRA 模型...")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
tokenizer=tokenizer,
data_collator=data_collator,
)
trainer.train()
print("LoRA 模型训练完成。")
# --- 8. 保存 LoRA 适配器 ---
lora_adapter_path = os.path.join(output_dir, "lora_adapter")
trainer.model.save_pretrained(lora_adapter_path)
tokenizer.save_pretrained(lora_adapter_path)
print(f"LoRA 适配器已保存到: {lora_adapter_path}")
# --- 9. 模型评估与推理 ---
print("\n--- LoRA 模型推理测试 ---")
# 首先加载原始预训练模型(不带量化,因为推理通常需要更好的精度)
# 如果你训练时用了量化,这里也可以用量化加载
original_model_for_inference = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16 if model.config.torch_dtype == torch.bfloat16 else torch.float16,
device_map="auto",
trust_remote_code=True
)
# 加载LoRA适配器到原始模型
model_for_inference = PeftModel.from_pretrained(original_model_for_inference, lora_adapter_path)
model_for_inference.eval() # 设置为评估模式
def generate_response(prompt, model, tokenizer, max_new_tokens=256):
inputs = tokenizer(prompt, return_tensors="pt", return_attention_mask=False)
inputs = {key: value.to(model.device) for key, value in inputs.items()}
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=True,
temperature=0.7,
top_p=0.9,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
)
input_length = inputs["input_ids"].shape[1]
response = tokenizer.decode(outputs[0][input_length:], skip_special_tokens=True)
return response
# 测试一个指令
test_prompt_1 = "### 指令:\n写一个关于人工智能的短故事\n### 回复:\n"
print(f"Prompt 1:\n{test_prompt_1}")
response_1 = generate_response(test_prompt_1, model_for_inference, tokenizer)
print(f"Generated Response 1:\n{response_1}")
test_prompt_2 = "### 指令:\n如何学习Python编程?\n### 回复:\n"
print(f"\nPrompt 2:\n{test_prompt_2}")
response_2 = generate_response(test_prompt_2, model_for_inference, tokenizer)
print(f"Generated Response 2:\n{response_2}")
# 可选:将 LoRA 权重合并到原始模型中,以便于部署为标准模型
# merged_model = model_for_inference.merge_and_unload()
# merged_model_path = os.path.join(output_dir, "merged_full_model")
# merged_model.save_pretrained(merged_model_path)
# tokenizer.save_pretrained(merged_model_path)
# print(f"合并后的模型已保存到: {merged_model_path}")4.2 高级应用与技巧
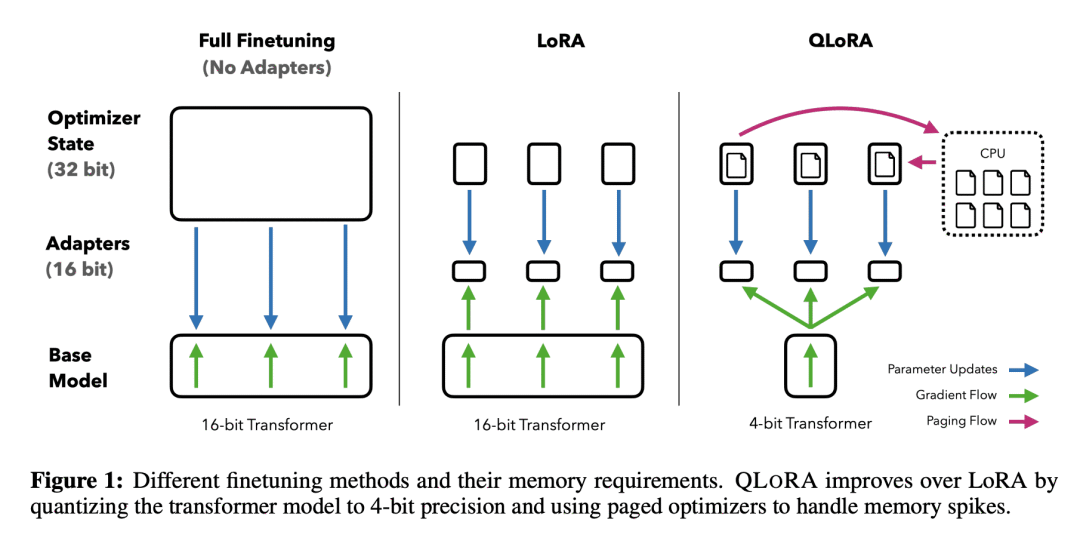
4.2.1 QLoRA:量化与LoRA的深度结合
QLoRA (Quantized LoRA) 是LoRA的关键改进,通过将4位量化(4-bit Quantization)引入微调过程,显著降低显存占用,使在单张消费级GPU上微调数十亿参数模型成为现实。
QLoRA 核心创新点:
-
4-bit NormalFloat (NF4) 量化:为正态分布权重优化的4位数据类型,相较传统量化,性能更优。
-
双量化 (Double Quantization):对量化常数进行再量化,进一步压缩存储。
-
分页优化器 (Paged Optimizers):利用Unified Memory技术,将优化器状态分页至CPU RAM,按需加载到GPU显存,解决优化器状态占用大量显存的问题。
上述代码示例中已通过BitsAndBytesConfig和optim="paged_adamw_8bit"实现了QLoRA配置。
4.2.2 DoRA (Weight-Decomposed LoRA)
DoRA (Weight-Decomposed LoRA) 是LoRA的另一重要变体,它将权重更新 ΔW 分解为大小(Magnitude)和方向(Direction)两部分。LoRA仅更新方向部分,而DoRA则同时更新这两部分,从而实现更全面的更新,有望带来更好的性能。
4.2.3 超参数调优经验法则
-
秩 r:从 8 或 16 开始实验,根据任务复杂度逐步调整。
-
alpha:通常设置为 r 或 r 的倍数,如 16 或 32。
-
lora_dropout:0.05 到 0.1 是常见且安全的范围。
-
learning_rate:LoRA的典型学习率通常高于全参数微调,建议在 1e-4 到 5e-4 之间选择。
-
target_modules:起始点通常为注意力层的 q_proj, v_proj。若性能不佳,可尝试加入 k_proj, o_proj,甚至FFN中的线性层。
-
梯度累积:在显存受限时,增大 gradient_accumulation_steps 可有效模拟更大批次训练,降低单次迭代显存需求。
总结
LoRA技术作为参数高效微调的里程碑式创新,极大地降低了大模型微调的门槛,使得更广泛的研究者和开发者能够参与到大模型的应用与创新中。它通过冻结原始模型,并巧妙地引入少量低秩矩阵进行增量学习,实现了计算和存储资源的大幅节约,提升了训练效率,并有效缓解了灾难性遗忘。
附录:常问问题(LoRA/PEFT专题)
本部分旨在帮助读者巩固LoRA知识,并从面试角度提供更深入的解答。
-
Q: 请解释什么是PEFT(参数高效微调)?它为何在大模型时代变得如此重要?
-
A: PEFT 是一种微调策略,它在大模型微调时,仅更新模型中一小部分参数,或引入少量额外参数,而冻结大部分预训练模型参数。
-
重要性:
-
资源限制: 大模型全参数微调需要天文数字般的计算和存储资源,PEFT显著降低了这些门槛,使得在消费级GPU上进行微调成为可能。
-
效率提升: 更少的训练参数意味着更快的训练速度和迭代周期。
-
存储成本: 每个微调任务只需保存小型适配器而非完整模型副本,极大节省存储空间和管理成本。
-
灾难性遗忘缓解: 冻结大部分预训练权重有助于保留模型的通用知识,防止在特定任务上过拟合和遗忘。
-
-
-
Q: LoRA的核心思想是什么?为什么它能显著减少可训练参数量?
-
A: LoRA的核心思想是:在微调过程中,预训练权重矩阵 W_0 的更新增量 ΔW 实际上是一个低秩矩阵。因此,LoRA不直接优化 ΔW,而是将其分解为两个更小的低秩矩阵 B (d x r) 和 A (r x k) 的乘积,即 ΔW = BA。
-
参数减少原理: 一个 d x k 的矩阵 W 有 d*k 个参数。如果将其增量 ΔW 分解为 BA,则 B 有 d*r 个参数,A 有 r*k 个参数。总训练参数量为 d*r + r*k = r*(d+k)。当 r 远小于 min(d,k) 时(例如 r=8 而 d,k=1024),r*(d+k) 会远小于 d*k,从而实现参数量的显著压缩。例如,对于1024x1024的权重矩阵,原始参数量1M,而LoRA只引入 8 * (1024 + 1024) = 16K 参数,参数量减少了约60倍。
-
-
Q: LoRA通常作用于Transformer模型中的哪些模块?为什么选择这些模块?
-
A : LoRA通常作用于Transformer模型中的注意力机制(Self-Attention)内的线性投影层,尤其是查询(Query)矩阵 W_q 和值(Value)矩阵 W_v。有时也会包括键(Key)矩阵 W_k 和输出(Output)矩阵 W_o,甚至前馈网络(FFN)中的线性层。
-
原因:
-
低秩特性: 研究表明,注意力机制中的 W_q 和 W_v 在微调时表现出更显著的低秩更新特性,即它们的权重增量 ΔW 可以很好地被低秩矩阵近似。这可能是因为注意力层更多地学习不同任务之间"通用转化"或"语义对齐"的模式。
-
性能敏感度: 改变这些层的权重对模型性能影响显著。
-
效率与效果平衡: 对这些关键层应用LoRA,可以在保证性能的同时,最大化参数效率。
-
-
-
Q: LoRA中的 r (秩) 和 alpha (缩放因子) 超参数分别代表什么?它们如何影响模型性能和训练?
-
A:
-
r (秩):决定LoRA适配器 A 和 B 矩阵的维度。r 越大,LoRA层能够学习到的信息越丰富,模型表达能力越强,可能更接近全参数微调的效果,但引入的可训练参数量也越多,对资源需求越大。r 过小可能导致欠拟合。
-
alpha (缩放因子):用于缩放LoRA层输出的权重 ΔW。实际的缩放系数是 α/r。alpha 的作用类似于学习率,它控制着LoRA适应器对原始模型权重 W_0 的影响程度。alpha 越大,LoRA层对原始模型的影响越大。将 alpha 除以 r 是为了在不同 r 值下进行更好的优化,防止 alpha 过大导致训练不稳定,使得 ΔW 的"大小"相对稳定,无论 r 如何变化。
-
-
影响: 选择合适的 r 和 alpha 需要在性能和资源消耗之间进行权衡。通常建议从较小的 r 值(如 8 或 16)开始,并保持 alpha >= r,然后根据验证集性能进行调优。
-
-
Q: QLoRA和LoRA有什么区别?QLoRA是如何进一步降低显存需求的?
-
A : QLoRA(Quantized LoRA)是LoRA的改进版本,它在LoRA的基础上引入了4位量化(4-bit Quantization)。
-
核心区别和显存降低机制:
-
LoRA: 冻结原始模型权重,只训练低秩适配器(通常为FP32或FP16)。原始模型权重仍以其原始精度(如FP16)存储。
-
QLoRA : 将整个预训练模型 权重进行4位量化存储(通常使用NF4数据类型),仅在计算时将其解量化到指定计算精度(如BFloat16),而LoRA适配器则以更高的精度(如FP16/BFloat16)存储和训练。
-
显存降低机制:
-
4位模型权重: 大部分模型参数以4位存储,显著减少模型本身的显存占用。
-
双量化: 对量化常数进行二次量化,进一步压缩内存。
-
分页优化器(Paged Optimizers): 将优化器状态(如AdamW的动量和方差)分页到CPU RAM,按需加载到GPU显存,解决了优化器状态占据大量GPU显存的问题。
-
-
-
总结: QLoRA在LoRA的基础上,通过4位量化和分页优化器,进一步大幅降低了大模型的显存占用,使得在单块消费级GPU上微调超大模型成为可能,而性能损失却很小。
-
-
Q: LoRA微调后,模型部署时需要注意什么?推理性能会受影响吗?
-
A: LoRA微调后,你得到的是一个很小的LoRA适配器文件(只包含 A 和 B 矩阵)。
-
部署注意事项:
-
动态加载: 在推理时,你需要先加载原始的预训练模型,然后使用 peft 库将LoRA适配器加载并附加到原始模型上。这意味着需要同时维护原始模型文件和LoRA适配器文件。
-
合并权重: 为了简化部署并确保推理性能不受影响(特别是如果 peft 库不是部署环境的默认依赖),通常建议将LoRA适配器权重与原始模型权重进行合并,生成一个新的"全参数"模型。合并后,该模型与通过全参数微调得到的模型在结构和大小上几乎一致。
-
多适配器管理: 如果一个原始模型有多个LoRA适配器对应不同任务,peft 库支持加载并激活(切换)不同的适配器,而无需重新加载整个基础模型。这在多任务场景下非常高效。
-
-
推理性能:
- 不会增加延迟 : LoRA的设计允许将 ΔW = BA 合并到 W_0 中,形成 W' = W_0 + BA。这意味着在推理阶段,模型的前向传播计算与标准的矩阵乘法 W'x 完全相同,不会引入额外的计算开销或延迟。这是LoRA相比于Adapter Tuning等其他PEFT方法的显著优势之一,后者可能在推理时引入额外的层,从而增加延迟。
-
-
Q: LoRA的超参数 target_modules 的选择有什么讲究?如何确定适合我的模型的 target_modules?
-
A: target_modules 指定了将LoRA层注入到预训练模型中的哪些模块(通常是线性层)。选择合适的 target_modules 对LoRA的性能至关重要。
-
选择依据:
-
经验法则: 对于Transformer模型,通常默认选择注意力机制中的 query (q_proj) 和 value (v_proj) 线性层,因为这些层在微调过程中表现出最强的低秩特性,且对模型性能影响大。
-
模型架构: 不同的模型架构(如LLaMA, ChatGLM, Mixtral, Qwen等)内部的模块命名可能不同。例如,ChatGLM家族的线性层可能命名为 query_key_value。
-
性能优化: 如果只选择 q_proj 和 v_proj 效果不佳,可以尝试扩展到包括 k_proj (键), o_proj (输出投影), 甚至前馈网络中的线性层 (gate_proj, up_proj, down_proj 等)。但通常,增加 target_modules 会增加可训练参数量和计算开销,所以需要在性能和效率之间权衡。
-
-
如何确定:
-
查阅模型文档: Hugging Face模型卡片或官方文档通常会说明推荐的LoRA target_modules。
-
打印模型结构: 最直接的方法是加载模型后,print(model) 或 model.named_modules(),观察模型内部的层级结构和线性层的命名。例如:
# ...加载模型... for name, module in model.named_modules(): if isinstance(module, torch.nn.Linear): print(name) -
社区实践: 参考开源社区中针对特定模型的LoRA微调实践经验。
-
-
参考文献
-
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., ... & Chen, Y. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685.
-
Dettmers, T., Pagnoni, A., Holtzman, F., & Zettlemoyer, L. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv preprint arXiv:2305.14314.
-
Hugging Face PEFT Library: https://github.com/huggingface/peft
-
Hugging Face Transformers Library: https://github.com/huggingface/transformers
-
Wang, L., Huang, S., Dong, B., Zhang, P., Ma, X., & Liu, Q. (2024). DoRA: Weight-Decomposed Low-Rank Adaptation. arXiv preprint arXiv:2402.09353.