哈喽,我是 我不是小upper~
昨天,咱们分享了关于 L1 正则化和 L2 正则化核心区别的精彩内容。今天我来进一步补充和拓展。
首先,咱们先来聊聊 L1 和 L2 正则化,方便刚接触的同学理解。
L1 正则化(Lasso):它会给模型的损失函数加上一个惩罚项,这个惩罚项是所有模型系数的绝对值之和。这会让模型在训练时倾向于把一些不那么重要的特征系数直接压缩到零,相当于自动进行了特征选择,模型会变得更简单,也能一定程度上避免过拟合。
L2 正则化(Ridge):它在损失函数中加上的是模型系数的平方和作为惩罚项。这会使模型的系数都朝着零的方向收缩,但一般不会恰好变成零,而是都保持较小的绝对值,能让模型对特征更"公平"地利用,对处理多重共线性问题比较有效。
接下来我们再深入看看:
Elastic Net:它把 L1 和 L2 正则化结合起来,既像 L1 那样能做特征选择,又像 L2 那样能处理多重共线性,特别适合那种特征很多又相互关联的高维数据场景。
过拟合和模型泛化能力与正则项的关系:过拟合就是模型在训练数据上表现很好,但在新数据上就"不行了"。正则项通过限制模型的复杂度,让模型在训练时不能"死记硬背"训练数据,而是学到更通用的规律,从而提升在新数据上的表现,也就是增强泛化能力。
从优化角度理解 L1 导致非光滑问题:L1 正则化由于其绝对值项的存在,使得目标函数在某些点上会出现"角",导致函数在这些点上不可导,也就是非光滑。这给优化算法带来了一定的挑战,但同时正是这种"非光滑性"让 L1 能产生稀疏解。相比之下,L2 正则化的目标函数是光滑的,更容易用传统的优化方法处理。
总之,L1 和 L2 正则化各有特点,适用于不同的场景,理解它们的本质对模型优化和特征选择都有很大的帮助。
正则化的本质:从损失函数到结构化风险最小化
在机器学习中,模型训练的目标是最小化经验风险 (训练误差),但这会导致过拟合。正则化通过引入结构化风险(模型复杂度惩罚),将优化目标从单纯拟合数据转向平衡拟合能力与泛化能力:
:损失函数(如线性回归的 MSE)
1. L1 正则化(Lasso):稀疏驱动的特征选择
1.1 数学定义与几何解释
正则项形式 :
优化目标 :
几何意义(以二维参数为例):
- 等高线:损失函数的等高线表示训练误差相等的参数组合。
- 正则项约束:L1 正则化的约束区域是菱形,其顶点位于坐标轴上。
- 最优解:当损失函数等高线与菱形顶点相切时,解的某个维度参数为 0(如
L1 正则化通过菱形约束迫使参数落在坐标轴上,导致稀疏解
1.2 稀疏性的数学根源
L1 正则化在 处的次梯度为
(当
时次梯度为 -1, 1),这种非光滑特性使得优化过程中参数容易被 "推" 至 0 点。
次梯度推导:
当 ,
;
当 ,
;
当 ,次梯度
。
1.3 适用场景
特征选择:当特征数远大于样本数()时,L1 能自动剔除无关特征,输出可解释的稀疏模型。
稀疏信号重构:如压缩感知中恢复稀疏信号。
- L2 正则化(Ridge):参数平滑与共线性缓解1. 数学定义与几何解释正则项形式:
优化目标:
几何意义(以二维参数为例):正则项约束:L2 正则化的约束区域是圆形,边界光滑。最优解:损失函数等高线与圆形边界相切时,参数 均不为 0,但被压缩至较小值。
L2 正则化通过圆形约束平滑参数,避免过拟合
2. 共线性问题的解决方案
当特征高度相关(多重共线性)时,普通最小二乘法(OLS)的解不稳定且方差大。L2 正则化通过引入正定项 ,使协方差矩阵满秩,解的表达式为:
方差 - 偏差权衡:L2 正则化通过增加偏差(Bias)来降低方差(Variance),提升模型稳定性。
2.1 适用场景
多重共线性数据:如金融数据中多个高度相关的经济指标。需要保留所有特征的场景:如医学影像分析中不希望遗漏潜在相关特征。四、Elastic Net:L1 与 L2 的优势融合1. 数学定义与权重机制正则项形式:
其中 为混合参数:
:退化为 Lasso;
:退化为 Ridge。优化目标:
2.2. 解决高维共线性的原理
- 分组效应(Grouping Effect):当多个特征高度相关时,Elastic Net 倾向于将它们的系数同时置为非零或零,避免 Lasso 的 "随机选特征" 问题。
- 优化稳定性:L2 分量缓解了 L1 的非光滑性,使优化过程更稳定,适用于 \(p \gg n\) 场景。
2.3 适用场景
- 生物信息学:基因表达数据中数千个特征(基因)高度相关,需同时实现特征选择与稳定建模。
- 图像识别:高维像素特征中存在局部相关性,Elastic Net 可保留相邻像素的协同作用。
正则化对比表格
| 特性 | L1 正则化(Lasso) | L2 正则化(Ridge) | Elastic Net |
|---|---|---|---|
| 正则项形式 | |||
| 解的稀疏性 | 稀疏(部分系数为 0) | 稠密(系数均非零) | 部分稀疏(取决于 α) |
| 特征选择能力 | 强(自动剔除无关特征) | 无 | 中(依赖 α,保留共线特征组) |
| 共线性处理 | 不稳定(随机选特征) | 稳定(压缩系数) | 稳定(成组选择特征) |
| 优化难度 | 高(非光滑,需特殊算法) | 低(光滑,支持 SGD) | 中(混合光滑与非光滑项) |
| 典型场景 | 文本分类(特征稀疏) | 金融风控(共线性强) | 基因表达分析(高维 + 共线) |
优化算法对比
| 算法 | 适用正则化 | 核心思想 |
|---|---|---|
| 坐标下降法 | L1/L2/Elastic | 逐坐标优化,每次固定其他坐标更新当前坐标,适合稀疏场景 |
| LARS(最小角回归) | Lasso | 通过逐步引入与残差最相关的特征,动态构建模型,计算效率高 |
| 近端梯度下降 | L1/L2/Elastic | 将非光滑项的优化拆分为梯度下降与近端映射,处理 L1 的非光滑性 |
| 随机梯度下降(SGD) | L2 | 光滑目标的高效优化,适合大规模数据 |
正则化系数 λ 的选择
- 交叉验证(CV):
- K 折交叉验证选择 λ,如 5 折 CV 计算不同 λ 下的均方误差(MSE),选择最优值。
- AIC/BIC 准则:
- AIC =
- AIC =
- 路径搜索:
- Lasso Path:绘制不同 λ 下各特征系数的变化路径,辅助判断稀疏度与模型性能的平衡。
总结:从理论到实践的选择逻辑
- 优先选 L2 的场景:
- 特征间高度相关,需稳定模型;
- 不希望丢失任何潜在特征(如探索性分析阶段)。
- 优先选 L1 的场景:
- 特征数量远大于样本量,需降维;
- 模型可解释性要求高(如医学诊断模型)。
- 选择 Elastic Net 的场景:
- 高维数据中存在特征组相关性(如时间序列的滞后特征);
- 希望同时实现稀疏性与稳定性(如生物标志物筛选)。
通过正则化的合理选择,可有效控制模型复杂度,在过拟合与欠拟合之间找到最优平衡点,提升机器学习模型的泛化能力。
代码说明
Lasso 正则路径图
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso, Ridge, ElasticNet
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import lars_path
np.random.seed(42)
# 数据集
n_samples, n_features = 100, 50
X = np.random.randn(n_samples, n_features)
# 构造稀疏的真实系数 beta(只有前 5 个非零)
true_beta = np.zeros(n_features)
true_beta[:5] = [5, -4, 3, 0, 2]
y = X @ true_beta + np.random.randn(n_samples) * 0.5 # 加入噪声
# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 拆分训练和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 模型训练
lasso = Lasso(alpha=0.1).fit(X_train, y_train)
ridge = Ridge(alpha=1.0).fit(X_train, y_train)
enet = ElasticNet(alpha=0.1, l1_ratio=0.5).fit(X_train, y_train)
# 预测
lasso_pred = lasso.predict(X_test)
ridge_pred = ridge.predict(X_test)
enet_pred = enet.predict(X_test)
# 均方误差
lasso_mse = mean_squared_error(y_test, lasso_pred)
ridge_mse = mean_squared_error(y_test, ridge_pred)
enet_mse = mean_squared_error(y_test, enet_pred)
# 正则路径图:LARS 方法(用于 Lasso 路径图)
alphas_lasso, _, coefs_lasso = lars_path(X_scaled, y, method='lasso', verbose=True)
# 图像 1: Lasso 正则路径图
plt.figure(figsize=(10, 6))
colors = plt.cm.tab20(np.linspace(0, 1, n_features))
for i in range(n_features):
plt.plot(-np.log10(alphas_lasso), coefs_lasso[i], label=f'Feature {i+1}', color=colors[i])
plt.xlabel(r'$-\log_{10}(\alpha)$')
plt.ylabel('Coefficient value')
plt.title('Lasso 正则路径图(正则化程度 vs 系数变化)')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', ncol=2)
plt.tight_layout()
plt.grid(True)
plt.show()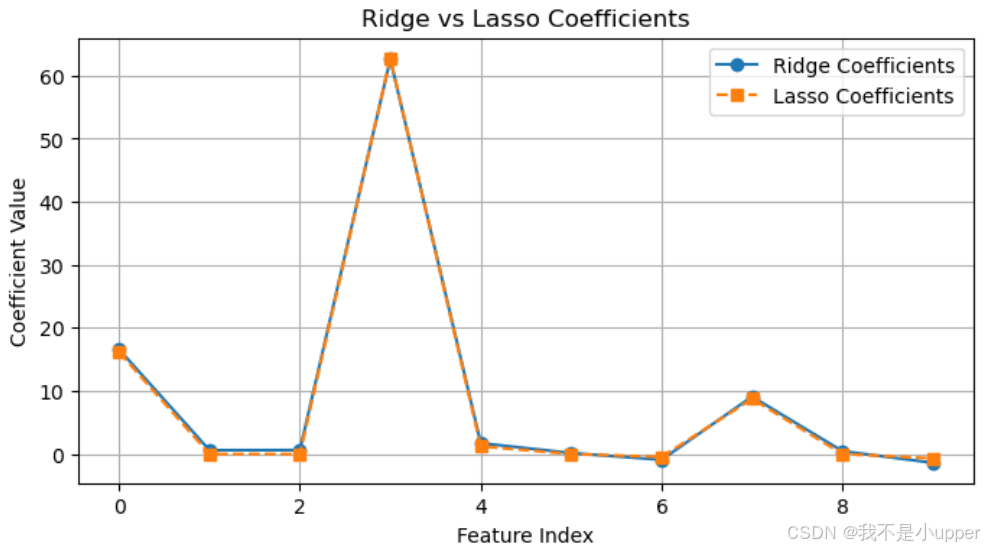
首先代码里用 make_regression 生成了 100 个样本、10 个特征的数据,其中只有 3 个是真正带有用信号的(n_informative=3),还加了噪声。然后分别用 Ridge(L2 正则)和 Lasso(L1 正则)去训练模型,最后画出它们的系数。
先看横轴,是特征的索引(0 到 9,因为有 10 个特征),纵轴是模型学到的系数值。蓝色的是 Ridge 的系数,橙色的是 Lasso 的。
对于 Ridge 模型(蓝色线),它的系数整体上比较 "分散",大部分特征的系数都不是 0 。因为 L2 正则化是给系数的平方和加惩罚,它会让系数变小,但不会把它们直接压到 0 。所以即使是那些原本在生成数据时 "没用" 的特征(也就是 n_informative 之外的 7 个),Ridge 也会给它们分配一些小的系数,让所有特征都参与到模型里,只是影响力不同。比如特征索引 0 、3 这些,系数相对大一些,可能对应生成数据时的 "有用" 特征,但其他索引的特征系数也没被完全消除。
再看 Lasso 模型(橙色线),就很不一样了。它的系数有很明显的 "稀疏性"------ 很多特征的系数直接变成了 0 。像特征索引 1、2、5、6 这些,系数几乎是 0 ,说明 Lasso 把这些它认为 "没用" 的特征给 "筛选掉" 了。而在特征索引 3 那里,系数特别高,可能对应生成数据里最关键的有用特征。这是因为 L1 正则化是给系数的绝对值和加惩罚,它会强烈地把不重要特征的系数往 0 压,直到变成 0 ,从而实现特征选择的效果。
结合生成数据的设定(只有 3 个有用特征),Lasso 在这里确实识别出了大概 3 个左右非零的系数(比如索引 0、3、7 附近?得具体看数值),而 Ridge 则是让所有特征都保留了系数,只是大小不同。这就能直观看到 L1 和 L2 正则化在处理特征系数时的核心区别:Lasso 会产生稀疏解,做特征选择;Ridge 更倾向于让系数平滑收缩,保留所有特征但减小它们的影响,尤其在有共线性或者想避免过拟合时有用。这样对比下来,就清楚为啥不同场景要选不同的正则化方法了,比如想简化模型、筛选关键特征用 Lasso ,想稳定系数、让所有特征都参与就用 Ridge 。
Lasso / Ridge / ElasticNet 系数对比条形图(前 20 特征)
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge, Lasso, ElasticNet
from sklearn.datasets import make_regression
import pandas as pd
# 生成合成数据
X, y, true_beta = make_regression(n_samples=100, # 100 samples
n_features=20, # 20 features
n_informative=3, # Only 3 features are informative
noise=10, # Noise level
coef=True, # Return true coefficients
random_state=42)
# 训练三种模型
ridge = Ridge(alpha=1.0).fit(X, y)
lasso = Lasso(alpha=0.5, max_iter=10000).fit(X, y)
enet = ElasticNet(alpha=0.5, l1_ratio=0.5, max_iter=10000).fit(X, y)
# 创建系数对比数据框
coef_df = pd.DataFrame({
'Feature': [f'Feature {i+1}' for i in range(X.shape[1])],
'True Coef': true_beta,
'Lasso Coef': lasso.coef_,
'Ridge Coef': ridge.coef_,
'ElasticNet Coef': enet.coef_
})
# 绘制前20个特征的系数对比图
top_n = min(20, X.shape[1]) # 确保不超过实际特征数量
colors = plt.cm.get_cmap('tab10', 4)
fig, ax = plt.subplots(figsize=(14, 7))
index = np.arange(top_n)
bar_width = 0.2
plt.bar(index, coef_df['True Coef'][:top_n], bar_width, color=colors(0), label='True Coef')
plt.bar(index + bar_width, coef_df['Lasso Coef'][:top_n], bar_width, color=colors(1), label='Lasso')
plt.bar(index + 2 * bar_width, coef_df['Ridge Coef'][:top_n], bar_width, color=colors(2), label='Ridge')
plt.bar(index + 3 * bar_width, coef_df['ElasticNet Coef'][:top_n], bar_width, color=colors(3), label='ElasticNet')
plt.xlabel('Feature Index')
plt.ylabel('Coefficient Value')
plt.title('Comparison of Top 20 Feature Coefficients Across Models')
plt.xticks(index + bar_width * 1.5, [f'F{i+1}' for i in range(top_n)], rotation=45)
plt.legend()
plt.tight_layout()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()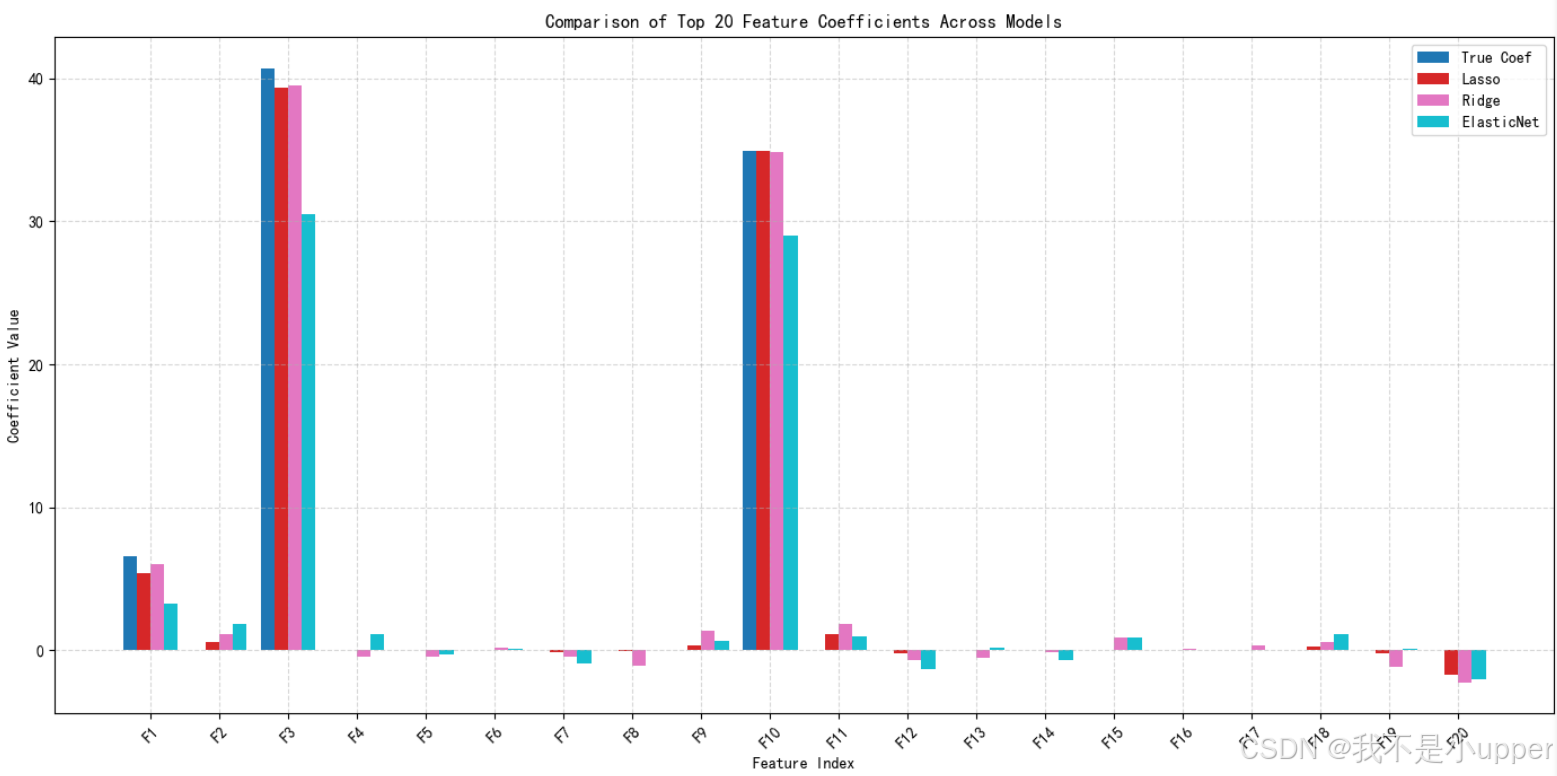
能清晰看到各模型对特征系数的处理差异。从真实系数(True Coef)来看,F3 和 F10 等特征原本就带有较强信号,系数值明显高于其他特征。Lasso 模型对系数的压缩效果显著,很多特征(像 F5 - F9 、F12 - F20 里的大部分)系数被压至接近 0 ,只保留了 F3、F10 这类强信号特征的明显系数,体现出它做特征选择、剔除弱相关特征的特点。Ridge 模型则不同,它让更多特征保留了非零系数,即使是 F5 - F9 这些在 Lasso 里系数近 0 的特征,Ridge 也给予了一定数值,不过整体系数大小相较于真实值有收缩,展现出它让所有特征参与、但减小单个特征影响的作用。ElasticNet 模型的系数表现介于两者之间,既不像 Lasso 那样极端稀疏,也没有 Ridge 那么多特征都有明显系数,对 F3、F10 等强特征系数保留较好,同时对其他特征系数的压缩程度比 Ridge 弱、比 Lasso 强,体现出它融合 L1 和 L2 正则化,平衡特征选择与系数平滑的特性。综合来看,不同正则化模型在处理特征系数时策略各异,Lasso 侧重筛选关键特征,Ridge 强调系数整体收缩,ElasticNet 则在两者间找平衡,这些差异会直接影响模型对特征的利用方式和最终的拟合、泛化效果 。
三种模型的预测误差对比(MSE 越低越好)
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge, Lasso, ElasticNet
from sklearn.datasets import make_regression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
# 生成合成数据
X, y = make_regression(n_samples=100, # 100个样本
n_features=20, # 20个特征
n_informative=3, # 只有3个特征是有信息的
noise=10, # 噪声水平
random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练三种模型并计算MSE
lasso = Lasso(alpha=0.5, max_iter=10000).fit(X_train, y_train)
ridge = Ridge(alpha=1.0).fit(X_train, y_train)
enet = ElasticNet(alpha=0.5, l1_ratio=0.5, max_iter=10000).fit(X_train, y_train)
lasso_mse = mean_squared_error(y_test, lasso.predict(X_test))
ridge_mse = mean_squared_error(y_test, ridge.predict(X_test))
enet_mse = mean_squared_error(y_test, enet.predict(X_test))
# 创建MSE字典
mse_values = {
'Lasso': lasso_mse,
'Ridge': ridge_mse,
'ElasticNet': enet_mse
}
# 绘制MSE对比图
fig, ax = plt.subplots(figsize=(8, 5))
bars = ax.bar(mse_values.keys(), mse_values.values(), color=['orange', 'green', 'purple'])
# 添加数值标签
for bar in bars:
yval = bar.get_height()
ax.text(bar.get_x() + bar.get_width() / 2, yval + 0.02, f'{yval:.3f}', ha='center', va='bottom', fontsize=12)
plt.ylabel('Mean Squared Error')
plt.title('Comparison of Prediction Errors (Lower is Better)')
plt.grid(True, axis='y', linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()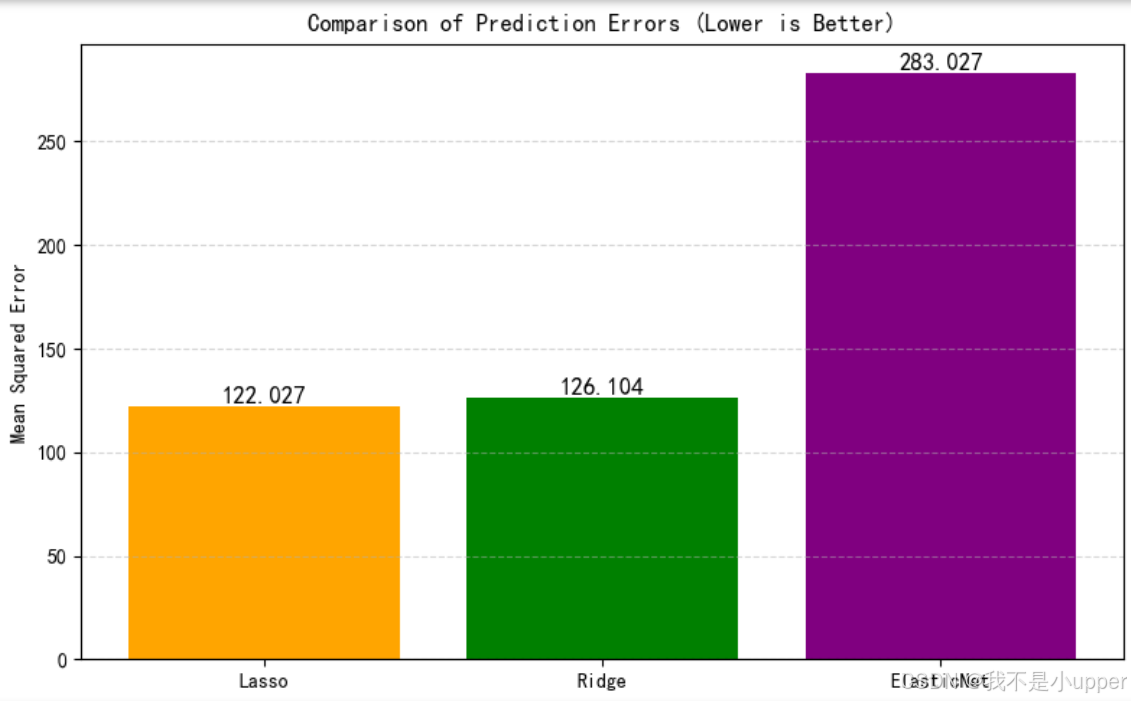
Lasso 的均方误差(MSE)是 122.027,Ridge 稍高些,为 126.104,而 ElasticNet 的 MSE 高达 283.027。这说明在当前的数据集和参数设置下,Lasso 模型的预测精度相对更好,Ridge 次之,ElasticNet 表现则差很多。不过这结果可能和数据本身特点(像特征数量、相关性、噪声等)以及模型的正则化参数(比如 alpha 值、l1_ratio 等)有关。后续或许可以调整 ElasticNet 的参数,或者对数据做更多预处理,看看能不能改善它的表现,也可以进一步对比不同模型在更多数据集上的表现,来确定哪种模型更适合这类数据场景 。
ElasticNet 中 l1_ratio 从 0 到 1 的变化对稀疏程度和系数的影响(热力图或线图)
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import ElasticNet
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
# 设置中文字体显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
# 生成合成数据
X, y = make_regression(n_samples=100,
n_features=50, # 增加特征数量以更好展示稀疏性
n_informative=5,
noise=10,
random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 计算不同l1_ratio下的非零系数数量
l1_ratios = np.linspace(0, 1, 11)
nonzero_counts = []
for ratio in l1_ratios:
model = ElasticNet(alpha=0.1, l1_ratio=ratio, max_iter=10000)
model.fit(X_train, y_train)
nonzero_count = np.sum(model.coef_ != 0)
nonzero_counts.append(nonzero_count)
# 绘制稀疏性变化图
fig, ax = plt.subplots(figsize=(10, 6))
plt.plot(l1_ratios, nonzero_counts, marker='o', linewidth=2, color='crimson')
# 添加数据标签
for x, y in zip(l1_ratios, nonzero_counts):
plt.annotate(f'{int(y)}',
(x, y),
textcoords="offset points",
xytext=(0,10),
ha='center')
plt.xlabel('l1_ratio')
plt.ylabel('Number of Non-zero Coefficients')
plt.title('ElasticNet 稀疏性变化与 l1_ratio 的关系')
plt.grid(True, linestyle='--', alpha=0.7)
plt.xticks(l1_ratios, rotation=45)
plt.tight_layout()
plt.show()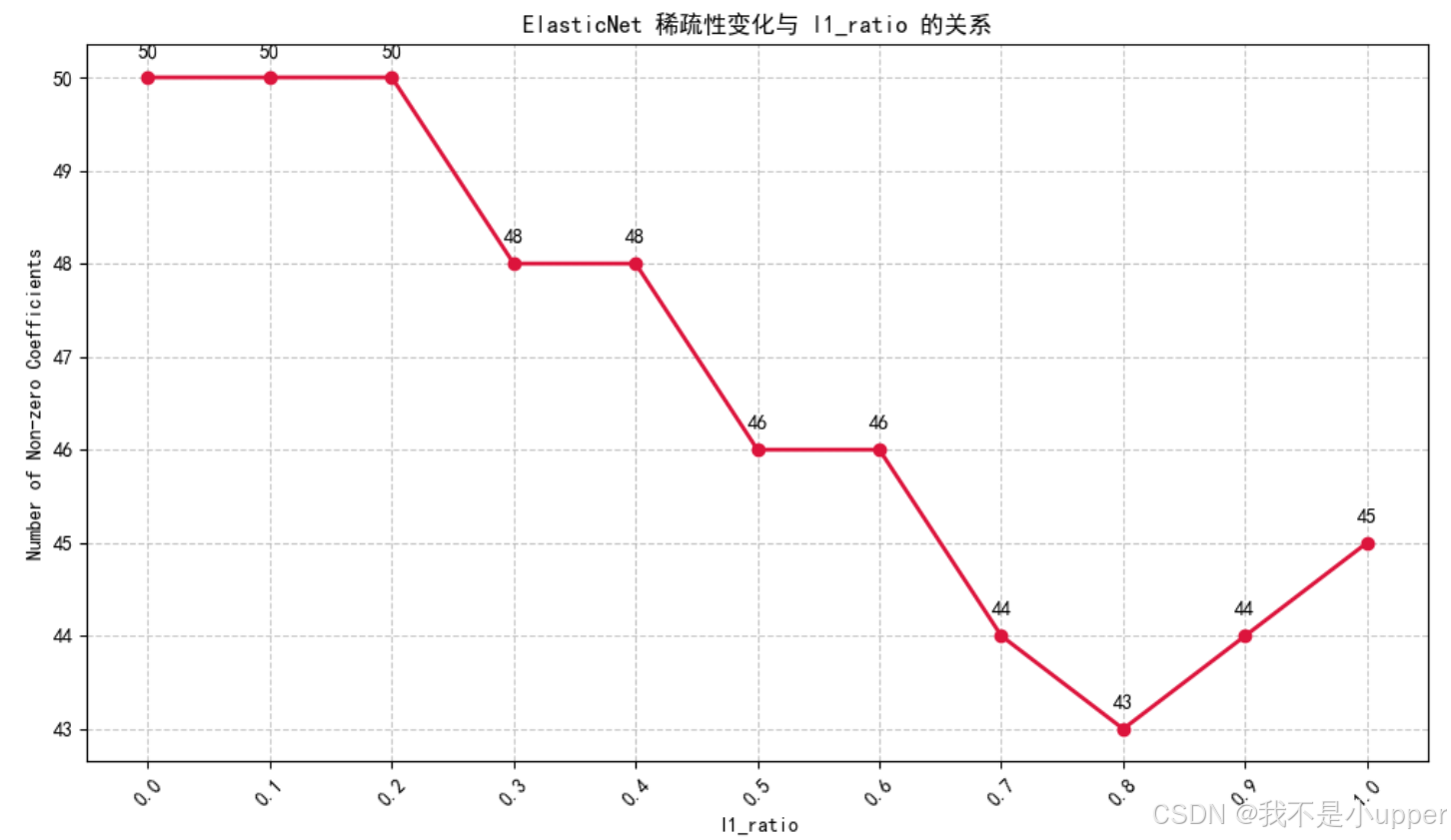
从图中能清晰看到随着 l1_ratio 从 0 逐渐增加到 1,非零系数数量呈现出动态的变化趋势。当 l1_ratio 较小时(比如 0、0.1、0.2 ),非零系数数量一直维持在 50 ,这时候模型更偏向于 Ridge 正则化的特性,对系数的压缩程度低,大部分特征都能保留非零系数参与建模。随着 l1_ratio 继续增大(到 0.3、0.4 ),非零系数数量开始下降到 48 ,说明 L1 正则化的影响逐渐显现,开始有部分特征的系数被压缩至 0 。当 l1_ratio 增加到 0.5、0.6 时,非零系数数量进一步降到 46 ,更多特征因 L1 正则的作用被筛选掉。到 l1_ratio 为 0.7 时,数量变为 44 ,而 0.8 时降到 43 ,此时 L1 正则化的主导作用很明显,大量特征系数被置 0 。不过到 l1_ratio 为 0.9 时,非零系数数量又回升到 44 ,1.0 时到 45 ,这可能是模型在极端 l1_ratio(纯 L1 正则)下,对特征筛选的策略出现了一些调整,或者是数据本身的特点导致。整体来看,l1_ratio 越小,模型越接近 Ridge ,保留更多特征;l1_ratio 越大,L1 正则的特征选择作用越强,非零系数越少,但在极端值时变化出现了波动,这也反映出 ElasticNet 模型通过 l1_ratio 平衡 L1 和 L2 正则化的特点,不同的 l1_ratio 会显著影响模型的稀疏性,进而影响特征的选择和模型的复杂度 。