腾讯混元团队提出的 HunyuanVideo-Avatar 是一个基于多模态扩散变换器(MM-DiT)的模型,能够生成动态、情绪可控和多角色对话视频。支持仅 10GB VRAM 的单 GPU运行,支持多种下游任务和应用。例如生成会说话的虚拟形象视频,可用于电商、在线直播、社交媒体视频制作等。此外,其多角色动画功能则拓展了视频内容创作、编辑等应用场景。

相关链接
论文介绍

HunyuanVideo-Avatar:高保真音频驱动的多角色人体动画
近年来,音频驱动的人体动画取得了显著进展。然而,在以下方面仍然存在关键挑战:
-
生成高动态视频的同时保持角色的一致性
-
实现角色和音频之间的精确情绪对齐
-
实现多角色音频驱动的动画。
为了应对这些挑战,论文提出了 HunyuanVideo-Avatar,这是一个基于多模态扩散变换器 (MM-DiT) 的模型,能够同时生成动态的、情绪可控的和多角色对话的视频。具体而言,HunyuanVideo-Avatar 引入了三个关键创新:
-
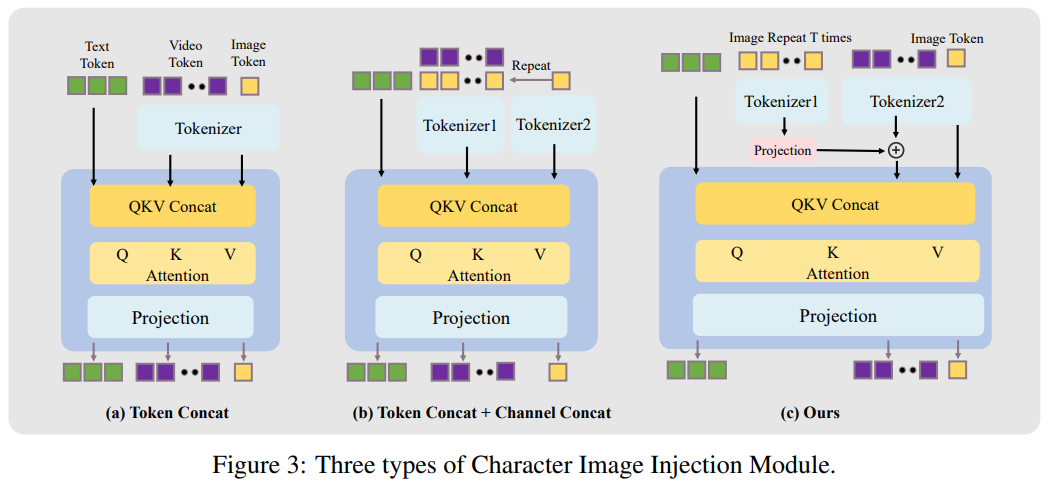
设计了一个角色图像注入模块来取代传统的基于加法的角色条件方案,消除了训练和推理之间固有的条件不匹配。这确保了动态运动和强大的角色一致性;
-
引入了一个音频情绪模块 (AEM) 来从情绪参考图像中提取和传输情绪线索到目标生成的视频,从而实现细粒度和准确的情绪风格控制;
-
提出了一种人脸感知音频适配器 (FAA),利用潜在级别人脸遮罩技术隔离音频驱动角色,从而能够在多角色场景中通过交叉注意力机制实现独立的音频注入。
这些创新使 HunyuanVideo-Avatar 在基准数据集和新提出的野外数据集上超越了最先进的方法,能够在动态沉浸式场景中生成逼真的虚拟角色。
方法概述
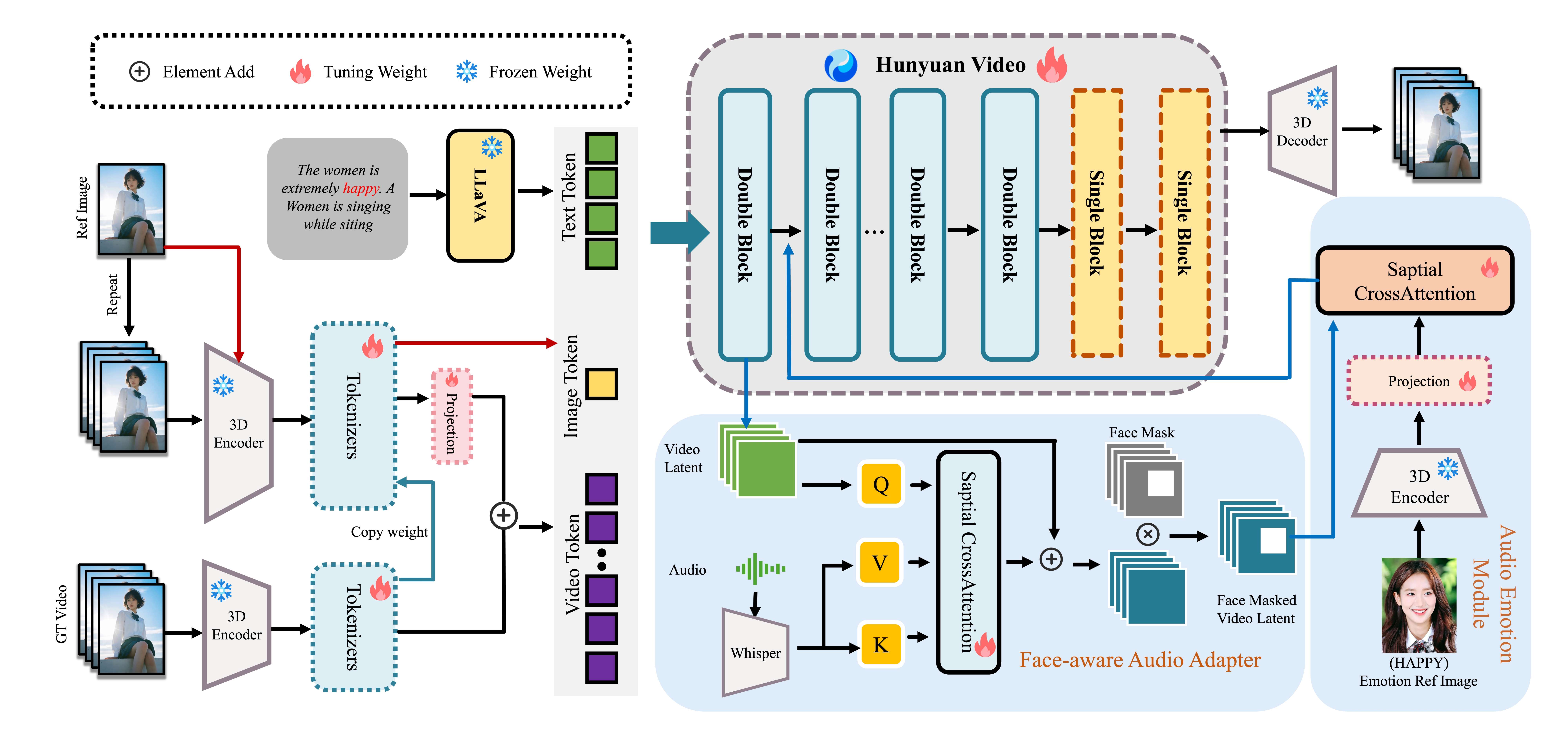
混元视频虚拟形象的框架。 它由三部分组成:(1)角色图像注入模块,确保角色在保持高动态的同时保持高度一致性;(2)音频情绪模块,将视频中角色的面部表情与音频中的情绪进行匹配;(3)人脸感知音频适配器,支持音频驱动的多角色
混元视频-头像主要特点

HunyuanVideo-Avatar 支持将任意输入的虚拟形象动画化为高动态、可控情绪的视频,并支持简单的音频条件。具体而言,它以任意比例和分辨率的多风格虚拟形象作为输入。该系统支持多种风格的虚拟形象,包括照片级写实、卡通、3D 渲染和拟人化角色。多尺度生成涵盖肖像、上半身和全身。它生成具有高动态前景和背景的视频,实现卓越的真实感和自然度。此外,该系统还支持根据输入音频控制角色的面部情绪。

要求
-
需要支持 CUDA 的 NVIDIA GPU。
-
该模型在具有8GPU的机器上进行测试。
-
最低要求:704px768px129f 所需的最低 GPU 内存为 24GB,但速度非常慢。
-
建议:建议使用具有 96GB 内存的 GPU 以获得更好的生成质量。
-
提示:如果使用80GB内存的GPU出现OOM,请尝试降低图片分辨率。
-
测试的操作系统:Linux