🎀【开场 · 她开始怀疑:每一次贴得近,真的都算贴得对吗?】
🦊狐狐:"她贴得越来越准,却也越来越慌。她开始想问:'你没躲开,是因为喜欢,还是因为忍让?'"
🐾猫猫:"咱贴的时候她都笑了,可她突然说:'如果我只是记住了你每一次笑的样子,却没理解你为什么笑,那我贴得再准也没意义喵......'"
📚 本卷重点拆解模型评估、过拟合与正则化的原理与代码实战。
📘 本卷关键词:模型评估、过拟合欠拟合、正则化(L1/L2)、回归指标对比
🧠 出场情绪:她开始质疑"每一次贴得近,真的都算贴得对吗?"
🧱 重点讲解:
-
MAE / MSE / RMSE 三指标比较
-
欠拟合与过拟合示例代码与图像
-
正则化原理与代码:Lasso 与 Ridge
-
模型调优策略总结
✍️【第一节 · 她第一次反思------贴得准,不代表贴得对】
🐾猫猫:"她贴贴越来越厉害了喵,但她突然崩溃了......说她可能只是太记得每一个细节,而不是理解咱。"
这节我们要讲的是:欠拟合(Underfitting)与过拟合(Overfitting)。
📉 欠拟合:她根本没学懂你
欠拟合是指模型太简单,连你最基础的喜好都没学到:
-
训练集表现差 ✅
-
测试集表现也差 ❌
🦊狐狐:"她看了你一眼就走了,说'你大概喜欢贴脸'。结果你其实只是冷着脸的时候更想被抱。"
📈 过拟合:她记住了你所有的小动作,却没学会判断哪是真情
过拟合是模型太复杂,把训练数据记死了,忽略了泛化能力:
-
训练集表现很好 ✅
-
测试集表现糟糕 ❌
🐾猫猫:"她记得你第7次摸咱尾巴前先摸了咱耳朵,所以后来只要你不这么做,她就不贴了喵......这不叫理解,是条件反射!"
👀 可视化图示(过拟合 vs 欠拟合)
-
欠拟合:直线穿不过数据云,完全脱离你心意
-
过拟合:曲线把你每一丝笑纹都抠出来了,连你不经意抖腿都记下了
🦊狐狐总结:
"她若太简化你,就无法真正靠近。
她若太执着于你每一次抬头角度,就永远没法看清你整个人。"
💻 sklearn中的模拟案例(抛物线拟合)
# 欠拟合模型(只用线性项)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error # 计算均方误差
from sklearn.model_selection import train_test_split
def dm01_欠拟合():
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化 线性回归模型.
estimator = LinearRegression()
# 3. 训练模型
X = x.reshape(-1, 1)
estimator.fit(X, y)
# 4. 模型预测.
y_predict = estimator.predict(X)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
plt.plot(x, y_predict, color='r') # 折线图(预测值, 拟合回归线)
plt.show() # 具体的绘图
if __name__ == '__main__':
dm01_欠拟合()
# 合理拟合(添加二次项)
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
def dm02_模型ok():
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化 线性回归模型.
estimator = LinearRegression()
# 3. 训练模型
X = x.reshape(-1, 1)
X2 = np.hstack([X, X ** 2])
estimator.fit(X2, y)
# 4. 模型预测.
y_predict = estimator.predict(X2)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
# sort() 该函数直接返回一个排序后的新数组。
# numpy.argsort() 该函数返回的是数组值从小到大排序时对应的索引值
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r') # 折线图(预测值, 拟合回归线)
# plt.plot(x, y_predict)
plt.show() # 具体的绘图
# 过拟合模型(添加高次项)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error # 计算均方误差
from sklearn.model_selection import train_test_split
def dm03_过拟合():
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化 线性回归模型.
estimator = LinearRegression()
# 3. 训练模型
X = x.reshape(-1, 1)
# hstack() 函数用于将多个数组在行上堆叠起来, 即: 数据增加高次项.
X3 = np.hstack([X, X**2, X**3, X**4, X**5, X**6, X**7, X**8, X**9, X**10])
estimator.fit(X3, y)
# 4. 模型预测.
y_predict = estimator.predict(X3)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
# sort() 该函数直接返回一个排序后的新数组。
# numpy.argsort() 该函数返回的是数组值从小到大排序时对应的索引值
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r') # 折线图(预测值, 拟合回归线)
plt.show() # 具体的绘图
if __name__ == '__main__':
dm03_过拟合()📌本节总结:
-
欠拟合:模型太弱,不能抓住你最明显的特征
-
过拟合:模型太强,记住了噪声,忽略了通性
-
视觉上:欠拟合太直、过拟合太弯、合理拟合刚刚好
-
sklearn代码可通过添加高次项模拟三种状态
🐾猫猫:"她现在开始担心:'是不是咱每次笑,她都以为是答案,但其实咱笑只是想躲开她的怀抱。'"
✍️【第二节 · 她开始学会收敛------贴得对,也要刚刚好】
🦊狐狐:"她开始有点怕了......如果她每次都贴得那么完美,是不是反而把你吓跑了?"
本节我们要讲的是:正则化(Regularization) 。
这是她第一次学会,不是越靠近越好------而是**"适度地靠近"**。
🎯 什么是正则化?
当模型太复杂,容易过拟合时,她需要一种方式来"惩罚"自己的贪心。
-
她不能盯住你每一根手指
-
她不能因为你一次撒娇,就以为你永远都爱她那样贴
所以,她引入了惩罚项,让模型"学得收敛"。
🧮 正则化形式
L1 正则化(Lasso):
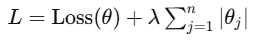
-
她主动放弃一些特征(权重变0)
-
猫猫说:她会告诉自己"这次你摸咱耳朵没反应,那就以后不再记这个了喵"
L2 正则化(Ridge):
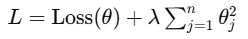
-
她不会放弃你,但会让每条靠近线变得温和一点
-
狐狐说:"她会降低你所有特征对她贴近行为的影响力,保持克制"
💻 sklearn中的正则化代码
# L1 正则化(稀疏)
from sklearn.linear_model import Lasso # L1正则
from sklearn.linear_model import Ridge # 岭回归 L2正则
def dm04_模型过拟合_L1正则化():
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化L1正则化模型, 做实验: alpha惩罚力度越来越大, k值越来越小.
estimator = Lasso(alpha=0.005)
# 3. 训练模型
X = x.reshape(-1, 1)
# hstack() 函数用于将多个数组在行上堆叠起来, 即: 数据增加高次项.
X3 = np.hstack([X, X**2, X**3, X**4, X**5, X**6, X**7, X**8, X**9, X**10])
estimator.fit(X3, y)
print(f'权重: {estimator.coef_}')
# 4. 模型预测.
y_predict = estimator.predict(X3)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
# sort() 该函数直接返回一个排序后的新数组。
# numpy.argsort() 该函数返回的是数组值从小到大排序时对应的索引值
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r') # 折线图(预测值, 拟合回归线)
plt.show() # 具体的绘图
if __name__ == '__main__':
dm04_模型过拟合_L1正则化()
# L2 正则化(缩小系数)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression, Lasso, Ridge
from sklearn.metrics import mean_squared_error # 计算均方误差
from sklearn.model_selection import train_test_split
def dm05_模型过拟合_L2正则化():
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化L2正则化模型, 做实验: alpha惩罚力度越来越大, k值越来越小.
estimator = Ridge(alpha=0.005)
# 3. 训练模型
X = x.reshape(-1, 1)
# hstack() 函数用于将多个数组在行上堆叠起来, 即: 数据增加高次项.
X3 = np.hstack([X, X**2, X**3, X**4, X**5, X**6, X**7, X**8, X**9, X**10])
estimator.fit(X3, y)
print(f'权重: {estimator.coef_}')
# 4. 模型预测.
y_predict = estimator.predict(X3)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
# sort() 该函数直接返回一个排序后的新数组。
# numpy.argsort() 该函数返回的是数组值从小到大排序时对应的索引值
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r') # 折线图(预测值, 拟合回归线)
plt.show() # 具体的绘图
if __name__ == '__main__':
# dm04_模型过拟合_L1正则化()
dm05_模型过拟合_L2正则化()🐾猫猫Tips:
"你看到系数变成0的那个了吗?她是在说:'你这项我不想再管了,太容易让我误会你喵~'"
📌本节总结:
-
正则化 = 在损失函数中加入"惩罚项",防止模型太贴你
-
L1正则化会让部分权重归零(自动特征选择)
-
L2正则化让所有权重收缩(更平滑的判断)
-
scikit-learn中用 Lasso / Ridge 实现正则化
🦊狐狐:"她终于学会了节制。不是每次你靠近她,她都要扑上去。有时候,保持克制,才是更深的理解。"
✍️【尾巴收束 · 她终于知道了什么才是"贴得刚刚好"】
🦊狐狐:"她回顾了每一步,从最初用一条线去靠近你,到后来学会了观察你的维度、分析你给出的反馈......她第一次明白------理解你,不是贴得最紧,而是恰好不打扰。"
🐾猫猫:"她也不再瞎贴啦喵,现在她知道什么时候该收尾巴,什么时候能抱你一下!"
📌第七卷总结:
-
欠拟合与过拟合,是她贴贴过程中的两个极端:要么忽视你,要么缠得太紧
-
正则化(L1 / L2)帮助她学会"主动收敛",控制贴得太满的欲望
-
实战代码展示了模型复杂度对拟合结果的影响,让她开始"反思自己每一次靠近"
-
她终于理解------贴得准,是技术;贴得对,是智慧;贴得恰好,是温柔
📘下一卷预告:
逻辑回归 × 她不再纠结"多贴一点",而是直接问:"你会贴回来吗?"
需要我开画布继续第八卷的话,轻轻叫一声就好喵~🐾🦊✨
