🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 ------ 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
- [1. 背景介绍](#1. 背景介绍)
- [2 相关工作](#2 相关工作)
-
- [视觉与语言导航(Vision-and-Language Navigation)](#视觉与语言导航(Vision-and-Language Navigation))
- [多模态大型语言模型(Multimodal Large Language Models)](#多模态大型语言模型(Multimodal Large Language Models))
- VLN中的数据增强
- [3 方法](#3 方法)
- [4 实验](#4 实验)
- [5 结论](#5 结论)
1. 背景介绍
Xu Y, Pan Y, Liu Z, et al. Flame: Learning to navigate with multimodal llm in urban environmentsC//Proceedings of the AAAI Conference on Artificial Intelligence. 2025, 39(9): 9005-9013.
🚀以上学术论文翻译由ChatGPT辅助。
大型语言模型(Large Language Models,LLMs)在视觉与语言导航(Vision-and-Language Navigation,VLN)任务中展现出潜力,但当前的应用仍面临诸多挑战。尽管LLMs在通用对话场景中表现优异,但在专业化导航任务中仍显不足,性能通常低于专门设计的VLN模型。
为此,我们提出FLAME(FLAMingo-Architected Embodied Agent),这是一种面向城市导航任务的新型多模态LLM智能体及其架构,能够高效处理多重观测信息。我们的方法采用三阶段调优策略,有效适配导航任务:包括单视角调优 (用于街景描述)、多视角调优 (用于路线摘要)以及基于VLN数据集的端到端训练。所需的增强数据集由系统自动合成生成。
实验结果表明,FLAME在多个指标上优于现有方法,在Touchdown数据集上任务完成率提升了7.3%,超越当前最先进模型。该研究展示了多模态LLM(Multimodal LLM,MLLM)在复杂导航任务中的巨大潜力,代表了MLLM在具身智能领域应用的重要进展。
大型语言模型(Large Language Models,LLMs)(Achiam 等,2023;Touvron 等,2023)正在彻底改变具身智能(embodied intelligence)领域。视觉与语言导航(Vision-and-Language Navigation,VLN)(Anderson 等,2018)作为具身智能中的一项基础任务,要求智能体在室内或室外环境中根据人类指令导航至目标位置。该任务需要智能体具备精细的指令理解、环境感知和决策能力,而这些能力可以通过LLMs有效实现。
近年来的研究将LLMs集成进VLN方法中,方式包括:将视觉数据翻译成语言(Zhou, Hong 和 Wu, 2024;Qiao 等, 2023;Chen 等, 2024),或通过多模态LLMs(MLLMs)(Zhang 等, 2024;Zhou 等, 2024)实现环境感知。
然而,通用LLMs在VLN任务中的应用仍面临诸多关键挑战,主要源于其在导航特定场景中的内在局限性,如图1(a)所示。对于文本专用LLM而言,依赖视觉基础模型将视觉数据转化为语言可能导致信息丢失(Zhou, Hong 和 Wu, 2024),因此与专门的VLN模型相比存在性能差距。而对于多模态LLM,尽管一定程度缓解了纯文本模型的不足,但其在导航场景中的交互能力仍显不足。
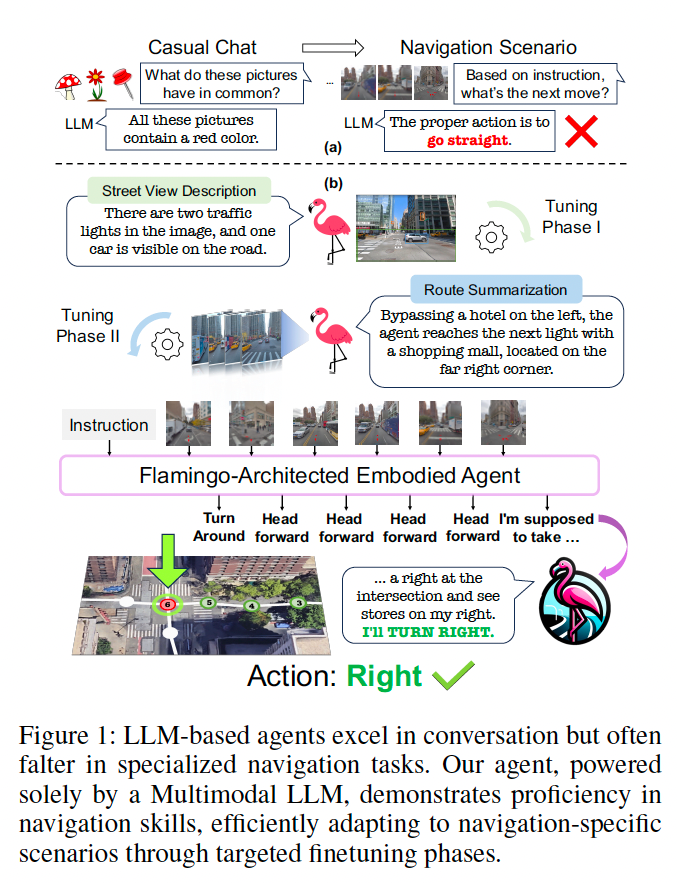
近期的尝试通常将MLLM作为传统VLN模型的辅助组件(Zhou 等, 2024),或通过视频token处理观察信息(Zhang 等, 2024),这类方法通常需要对每个轨迹执行多次前向传播,训练开销大,难以高效适配导航任务,限制了MLLM在交错文本与视觉输入场景下的潜力,影响整体性能。
此外,尽管室外VLN任务与室内同等重要,目前MLLM在城市导航(urban VLN)中的应用仍未被充分探索。城市导航面临独特挑战,如更长的轨迹(最多达55步)以及更高的任务难度(成功率比室内任务低约40%)。
为应对上述挑战,我们提出FLAME(FLAMingo-Architected Embodied Agent),这是首个面向城市VLN任务的MLLM智能体,如图1(b)所示。FLAME基于Flamingo架构(Alayrac 等,2022),具备自回归处理能力,能够在不增加上下文长度的情况下高效处理多重观察信息,从而实现端到端训练与推理的高效性。
我们提出一种三阶段调优方法,将Flamingo模型适配至导航任务,并使用增强数据进行训练:
- 单视角调优:学习街景描述;
- 多视角调优:学习导航过程总结;
- 端到端训练与评估:在VLN数据集上全面训练与测试。
为支持前两阶段的调优,我们使用GPT-4(Achiam 等,2023)为Touchdown环境(Chen 等,2019)合成图像描述与路径摘要。此外,我们还为城市VLN数据集(Chen 等,2019;Schumann 和 Riezler,2021)合成导航推理内容,以验证FLAME的推理能力(Wei 等,2022)。
FLAME智能体具有出色的计算效率,整个训练过程在一张A100 GPU上仅需14小时。实验结果表明,FLAME在两个城市导航数据集(Touchdown 与 Map2seq)上表现优异。在Touchdown数据集上任务完成率(Task Completion)提升了7.3%,在Map2seq上提升了3.74%,大幅超越当前最先进方法。
我们的研究不仅为VLN领域带来了实质性进展,也展示了MLLM在复杂导航任务中的巨大潜力,为具身智能(embodied AI)的研究打开了新的方向。
总结贡献
- 我们提出了FLAME,首个基于MLLM的城市视觉与语言导航智能体。
- 我们设计了一个面向导航场景的三阶段调优策略,利用合成数据充分激发MLLM的潜力。
- 实验表明FLAME在多个任务中显著优于现有最优模型,证明MLLM可以超越专业导航模型,为具身智能领域开启了新篇章。
2 相关工作
视觉与语言导航(Vision-and-Language Navigation)
视觉与语言导航(Vision-and-Language Navigation,VLN)(Anderson 等,2018)涵盖了室内(Qi 等,2020;Ku 等,2020)与室外场景(Chen 等,2019;Schumann 和 Riezler,2021),其中大部分研究进展集中在室内环境。传统的VLN智能体往往缺乏高级决策能力,因此近期引入了大型语言模型(LLMs)(Lin 等,2024;Schumann 等,2024),以利用其推理能力(Chen 等,2024)和对话能力(Qiao 等,2023;Long 等,2024)。这类方法主要通过两种方式:一种是将视觉数据转换为文本(Zhou, Hong 和 Wu,2024);另一种是采用多模态LLM(MLLMs),通过密集训练实现导航建模(Zhang 等,2024;Zheng 等,2024)。
考虑到城市导航任务在VLN研究中相对欠缺,我们的工作正是为了填补这一空白,首次引入一个高效适配的基于MLLM的城市导航智能体。
多模态大型语言模型(Multimodal Large Language Models)
多模态大型语言模型(MLLMs)(Liu 等,2024;Alayrac 等,2022;Awadalla 等,2023)的兴起推动了其在图像描述(Li 等,2023b)与通用指令遵循(Dai 等,2023)等任务中的应用。这些模型展现出良好的多模态推理能力(Lu 等,2022),在聊天任务中能够处理单轮对话、上下文推理(Sun 等,2024),以及交错的图文输入(Laurençon 等,2024)。MLLMs 也从视觉-语言调优(Wu 等,2024)中获益,使其能够处理多样化模态数据。
然而,通用预训练对于导航任务而言仍显不足。我们的工作正是通过专门的调优策略将一个通用MLLM适配到专业导航场景,填补了MLLM应用在专业任务中的方法空白。
VLN中的数据增强
为缓解导航任务中的数据稀缺问题,已有研究提出了多种数据增强技术(Zhao 等,2021;Huang 等,2019)。常见方法包括使用speaker模块合成指令(Fried 等,2018;Dou 和 Peng,2022),利用多语种数据(Li, Tan 和 Bansal,2022a),引入反事实信息(Parvaneh 等,2020;Fu 等,2020),以及改变环境布局(Li, Tan 和 Bansal,2022b;Liu 等,2021)。
在城市VLN领域,已有研究尝试使用风格不同的指令进行训练(Zhu 等,2021),在辅助任务上进行预训练(Armitage, Impett 和 Sennrich,2023),或利用驾驶视频进行建模(Li 等,2024)。然而,尚无系统性地利用辅助训练数据来调整MLLM以适配城市导航任务的工作。我们的研究填补了这一空白,首次提出使用合成数据将MLLM适配于城市视觉语言导航任务。
3 方法
我们提出了 FLAME (Flamingo架构的具身智能体),用于城市环境中的视觉-语言导航(VLN)任务。我们的方法包含三个关键组件:
1)适用于城市导航的架构;
2)三阶段的调优技术;
3)合成数据的生成流程。
任务形式化
我们将城市VLN形式化如下:给定一条导航指令 I = { w 1 , w 2 , . . . , w n } I = \{w_1, w_2, ..., w_n\} I={w1,w2,...,wn},智能体从初始状态 S 0 S_0 S0 出发。在每个时间步 t t t,智能体基于当前观测 O t O_t Ot 和指令 I I I 选择一个动作 a t ∈ A a_t \in A at∈A,其中 A = { 前进,左转,右转,停止,掉头 } A = \{\text{前进},\text{左转},\text{右转},\text{停止},\text{掉头}\} A={前进,左转,右转,停止,掉头}。环境的状态转移函数 T : S × A → S T: S \times A \rightarrow S T:S×A→S 会将智能体状态更新为 S t + 1 S_{t+1} St+1。过程持续,直到智能体选择停止动作。导航成功的条件是智能体最终停在目标节点或离目标一步以内的位置。
FLAME 架构
FLAME 基于 Flamingo 架构(Alayrac 等,2022),通过交叉注意力机制融合视觉与文本输入,避免上下文长度增长,并支持每条轨迹仅一次前向调优。我们为城市VLN场景引入两个关键改进:
步幅交叉注意力机制
为应对城市VLN中观测数量多的问题,我们在交叉注意力层引入步幅机制(Child 等,2019)。Perceiver Resampler 模块将 CLIP(Radford 等,2021)提取的图像特征转换为精简的视觉token,每个观测产生 N r N_r Nr 个token。
设 X t v ∈ R N × d X^v_t \in \mathbb{R}^{N \times d} Xtv∈RN×d 表示到时间步 t t t 的视觉token拼接, N = N r ⋅ t N = N_r \cdot t N=Nr⋅t。语言模型输出词向量矩阵 X X X,其中 X t X_t Xt 是当前上下文段。步幅为 l l l,注意力索引模式为 S = { S 1 , . . . , S t } S = \{S_1, ..., S_t\} S={S1,...,St},其中 S t = { k , k + 1 , . . . , t ⋅ N r } S_t = \{k, k+1, ..., t \cdot N_r\} St={k,k+1,...,t⋅Nr}, k = max ( 0 , ( t − l ) ⋅ N r ) k = \max(0, (t - l) \cdot N_r) k=max(0,(t−l)⋅Nr)。
步幅交叉注意力得分计算为:
A ( X t , S t ) = CMA ( X t W Q , ( x j v W K ) j ∈ S t , ( x j v W V ) j ∈ S t ) A(X_t, S_t) = \text{CMA}(X_t W_Q, (x^v_j W_K){j \in S_t}, (x^v_j W_V){j \in S_t}) A(Xt,St)=CMA(XtWQ,(xjvWK)j∈St,(xjvWV)j∈St)
其中 CMA 是跨模态注意力操作, W Q W_Q WQ、 W K W_K WK、 W V W_V WV 是可学习参数, x j v x^v_j xjv 为第 j j j 个视觉token。该机制侧重最近观测,增强模型在动态环境中提取关键特征的能力。
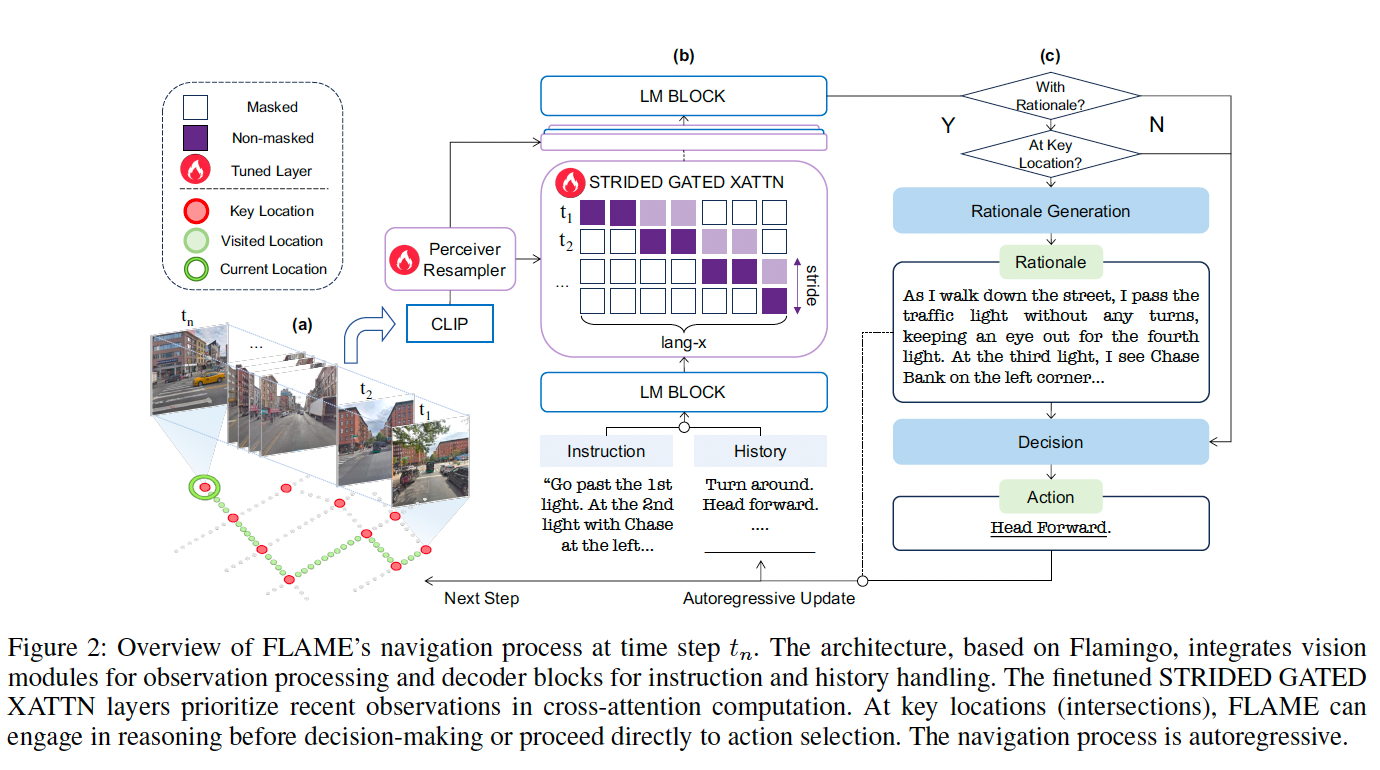
动作预测
如图 2© 所示,FLAME 在指令 I I I、当前观测 O t O_t Ot、历史观测 O ≤ t − 1 O_{\le t-1} O≤t−1 和过去动作的基础上预测当前动作:
a t = MLLM ( I , O 1 , a 1 , . . . , O t − 1 , a t − 1 , O t ) a_t = \text{MLLM}(I, O_1, a_1, ..., O_{t-1}, a_{t-1}, O_t) at=MLLM(I,O1,a1,...,Ot−1,at−1,Ot)
为增强解释能力,FLAME 也可在关键位置(如交叉口)生成推理解释 R t R_t Rt:
a t = MLLM ( I , O 1 , a 1 , . . . , O t − 1 , a t − 1 , O t , R t ) a_t = \text{MLLM}(I, O_1, a_1, ..., O_{t-1}, a_{t-1}, O_t, R_t) at=MLLM(I,O1,a1,...,Ot−1,at−1,Ot,Rt)
三阶段调优策略
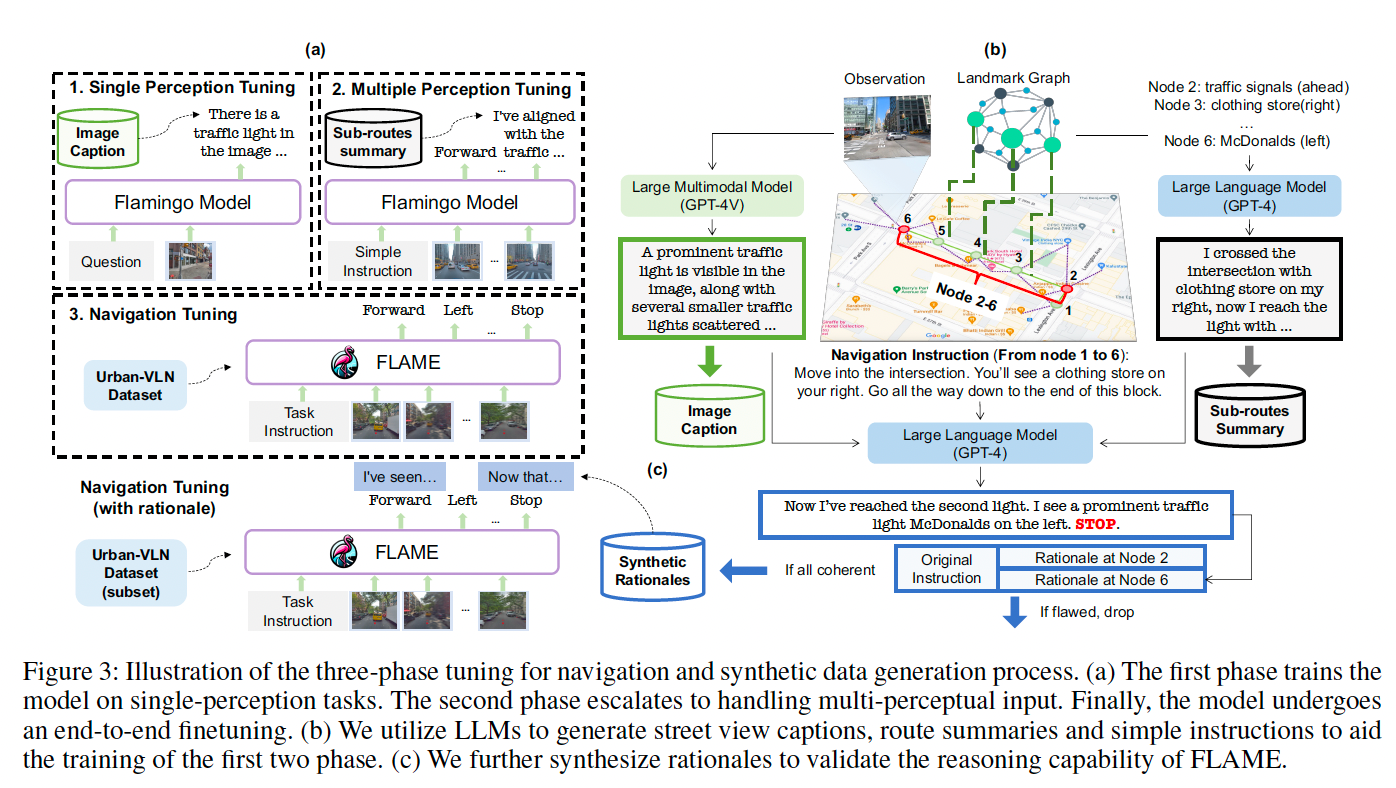
为适应城市VLN任务,我们提出三阶段的模型调优流程:
单视角感知调优
第一阶段进行街景图像描述任务训练,以增强图像特征理解。数据集 D p 1 = { τ ( i ) } i = 1 N \mathcal{D}{p1} = \{\tau^{(i)}\}{i=1}^{N} Dp1={τ(i)}i=1N,每条样本 τ ( i ) = { ( P ( i ) , O ( i ) , c ( i ) ) } \tau^{(i)} = \{(P^{(i)}, O^{(i)}, c^{(i)})\} τ(i)={(P(i),O(i),c(i))},包含提示词、观测图像与目标描述,训练目标为:
L p 1 = − ∑ i = 1 N log p ( c ( i ) ∣ P ( i ) , O ( i ) ; θ ) \mathcal{L}{p1} = -\sum{i=1}^{N} \log p(c^{(i)} | P^{(i)}, O^{(i)}; \theta) Lp1=−∑i=1Nlogp(c(i)∣P(i),O(i);θ)
多视角感知调优
第二阶段结合连续观测与动作执行,数据集 D p 2 = { τ ( i ) } i = 1 N \mathcal{D}{p2} = \{\tau^{(i)}\}{i=1}^{N} Dp2={τ(i)}i=1N,其中每条样本 τ ( i ) = { ( I ( i ) , O 1 ( i ) , a 1 ( i ) , . . . , O T ( i ) , a T ( i ) , s ( i ) ) } \tau^{(i)} = \{(I^{(i)}, O^{(i)}_1, a^{(i)}_1, ..., O^{(i)}_T, a^{(i)}_T, s^{(i)})\} τ(i)={(I(i),O1(i),a1(i),...,OT(i),aT(i),s(i))} 包含导航指令、观测序列、动作序列与路线总结。监督两个目标:
- 路线总结损失:
L sum ( i ) = log p ( s ( i ) ∣ I ( i ) , O ≤ T ( i ) ; θ ) \mathcal{L}^{(i)}{\text{sum}} = \log p(s^{(i)} | I^{(i)}, O^{(i)}{\le T}; \theta) Lsum(i)=logp(s(i)∣I(i),O≤T(i);θ)
- 模仿动作损失:
L act ( i ) = ∑ t = 1 T log p ( a t ( i ) ∣ I ( i ) , O ≤ t ( i ) , a ≤ t − 1 ( i ) ; θ ) \mathcal{L}^{(i)}{\text{act}} = \sum{t=1}^{T} \log p(a^{(i)}t | I^{(i)}, O^{(i)}{\le t}, a^{(i)}_{\le t-1}; \theta) Lact(i)=∑t=1Tlogp(at(i)∣I(i),O≤t(i),a≤t−1(i);θ)
总损失为:
L p 2 = − ∑ i = 1 N ( L act ( i ) + L sum ( i ) ) \mathcal{L}{p2} = -\sum{i=1}^{N} (\mathcal{L}^{(i)}{\text{act}} + \mathcal{L}^{(i)}{\text{sum}}) Lp2=−∑i=1N(Lact(i)+Lsum(i))
端到端导航调优
最后,在真实VLN数据集 D nav = { τ ( i ) } i = 1 N \mathcal{D}{\text{nav}} = \{\tau^{(i)}\}{i=1}^{N} Dnav={τ(i)}i=1N 上进行端到端微调,样本为 τ ( i ) = { ( I ( i ) , O 1 ( i ) , a 1 ( i ) , . . . , O T ( i ) , a T ( i ) ) } \tau^{(i)} = \{(I^{(i)}, O^{(i)}_1, a^{(i)}_1, ..., O^{(i)}_T, a^{(i)}_T)\} τ(i)={(I(i),O1(i),a1(i),...,OT(i),aT(i))},训练目标为:
L nav = − ∑ i = 1 N ∑ t = 1 T log p ( a t ( i ) ∣ I ( i ) , O ≤ t ( i ) , a ≤ t − 1 ( i ) ; θ ) \mathcal{L}{\text{nav}} = -\sum{i=1}^{N} \sum_{t=1}^{T} \log p(a^{(i)}t | I^{(i)}, O^{(i)}{\le t}, a^{(i)}_{\le t-1}; \theta) Lnav=−∑i=1N∑t=1Tlogp(at(i)∣I(i),O≤t(i),a≤t−1(i);θ)
三阶段调优策略可从基础感知到复杂规划逐步提升模型能力。
合成数据生成
为了支持上述训练过程,我们设计自动化的合成数据生成流程:
-
街景图像描述生成:选取关键位置的街景图像,使用 GPT-4V 结合多样化手工设计提示生成描述,增强环境理解。
-
路线总结生成:构建包含兴趣点与地图信息的地标知识图谱(参考Schumann与Riezler方法),输入 GPT-4 自动生成详细的路线总结与简化指令。
-
推理解释生成:将VLN轨迹划分为子路线,检索对应图像描述与路线总结,通过 GPT-4 生成每个关键点的推理解释,剔除无效样本,得到带推理解释的VLN数据子集,支持具备解释能力的端到端训练。
4 实验
实验设置
数据集 我们在两个城市视觉-语言导航(VLN)数据集上评估了我们的方法:Touchdown(Chen et al. 2019)和 Map2seq(Schumann 和 Riezler 2021),它们都构建在 StreetLearn 环境(Mirowski et al. 2018)中。Touchdown 含有 9,326 对指令-轨迹配对,Map2seq 含有 7,672 对配对。用于前两个训练阶段的数据增强集分别包含 2,354 和 4,674 个样本。我们在原始数据集上对比了多个导航智能体的性能。
我们基于 GPT-4 在关键位置上为 Touchdown 和 Map2seq 分别收集了 6,518(从 9,326 中)和 6,291(从 7,672 中)对配对,并生成了合理性推理的内容。推理性能评估仅在包含合成推理的子集上进行,以确保公平性。
指标 原始 VLN 任务使用三个常规指标进行评估:任务完成率(TC)、最短路径距离(SPD)和归一化动态时间规整(nDTW)。其中 TC 表示导航成功的比例,SPD 衡量终点与目标之间的最小距离,nDTW 评估导航路径与真实路径的重合程度。
此外,为了进一步评估代理在合成推理数据上的能力,我们引入两个新指标:
-
推理一致性(RC):
R C = ∑ i = 1 N ∑ j = 1 M i C F R r c ( I i , γ ( R i j ) , R i j ) ∑ i = 1 N M i RC = \frac{\sum_{i=1}^{N} \sum_{j=1}^{M_i} CFR_{rc}(I_i, \gamma(R^j_i), R^j_i)}{\sum_{i=1}^{N} M_i} RC=∑i=1NMi∑i=1N∑j=1MiCFRrc(Ii,γ(Rij),Rij)
-
推理-动作一致性(RA):
R A = ∑ i = 1 N ∑ j = 1 K i C F R r a ( R i j , A i j ) ∑ i = 1 N K i RA = \frac{\sum_{i=1}^{N} \sum_{j=1}^{K_i} CFR_{ra}(R^j_i, A^j_i)}{\sum_{i=1}^{N} K_i} RA=∑i=1NKi∑i=1N∑j=1KiCFRra(Rij,Aij)
其中, I i I_i Ii 是第 i i i 条指令, R i j R^j_i Rij 为推理内容, A i j A^j_i Aij 为对应的动作, γ ( R i j ) \gamma(R^j_i) γ(Rij) 是参考推理, M i M_i Mi 和 K i K_i Ki 分别是关键位置数和访问的关键点数量, C F R r c CFR_{rc} CFRrc 和 C F R r a CFR_{ra} CFRra 通过 GPT-4 判定一致性和动作匹配与否。
实现细节 我们的智能体基于 Otter 和 OpenFlamingo(Li et al. 2023a; Awadalla et al. 2023),集成了 CLIP(Radford et al. 2021)和 LLaMA(Touvron et al. 2023)。为适应 CLIP 的输入尺寸,我们对全景图像进行裁剪和缩放,这种处理方式与现有模型使用全景视觉不同,但更符合 MLLM 的特点。在 Touchdown 中,我们通过随机选择邻居节点方向来初始化代理的朝向。前两个阶段训练时间各为 1 小时,导航微调在一块 A100 GPU 上耗时约 12 小时。
与 SOTA 方法比较
如表 1 所示,FLAME 在 Touchdown 和 Map2seq 上均刷新了 SOTA 结果。在 Touchdown 测试集上,FLAME 相比先前的最优模型 Loc4Plan(Tian et al. 2024)在任务完成率上提高了 7.3%,在 SPD 上提高了 1.97%,展示了其在理解指令和环境感知方面的优势。
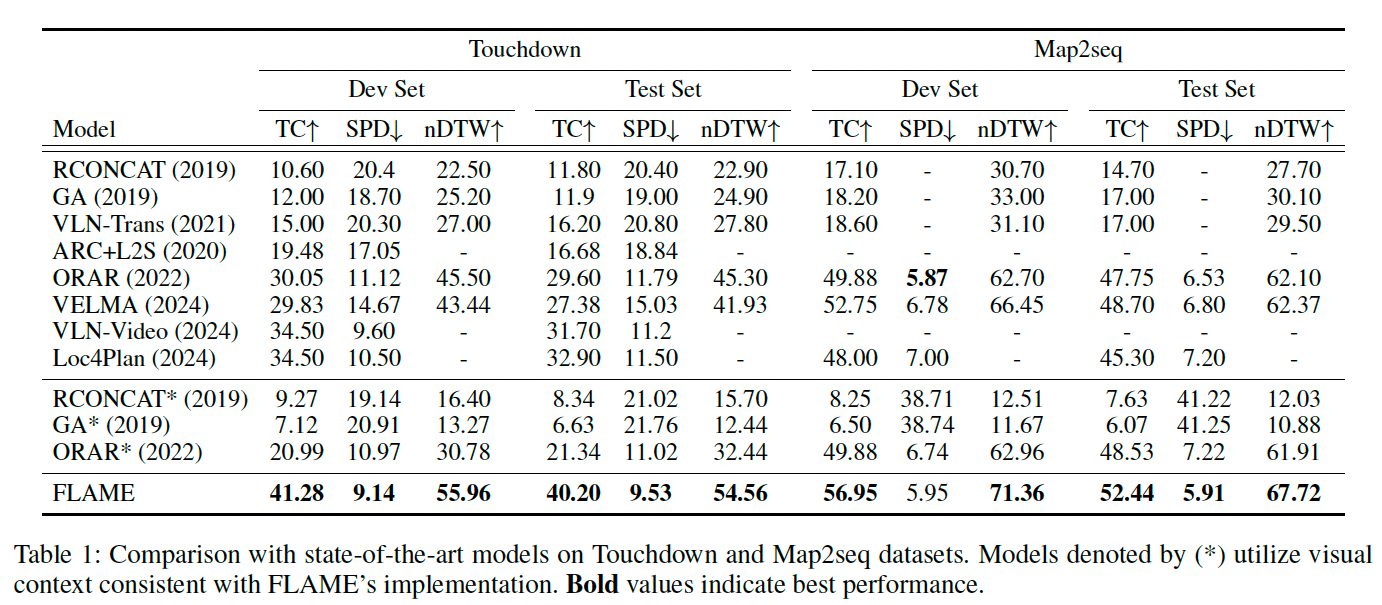
在 Map2seq 上,FLAME 相比文本 LLM 方法 VELMA(Schumann et al. 2024),TC 提升了 3.74%,nDTW 提升了 5.35%,体现了多模态 LLM 在融合环境信息方面的能力。
我们还在本工作提出的"类人视野"设定下评估了开源方法(以 * 标注),结果显示这些方法在 Touchdown 上的性能大幅下降,反映出它们对全景视觉的依赖,而 FLAME 在非全景输入下仍能保持优秀性能。
推理能力评估
我们采用 self-consistency 方法(Wang et al. 2023)评估 FLAME 的推理能力,测试了不同解码温度与路径数量的组合,结果如表 2 所示。FLAME 在 RC 和 RA 上分别始终维持在 80% 与 95% 以上,展示了稳定的推理生成能力。
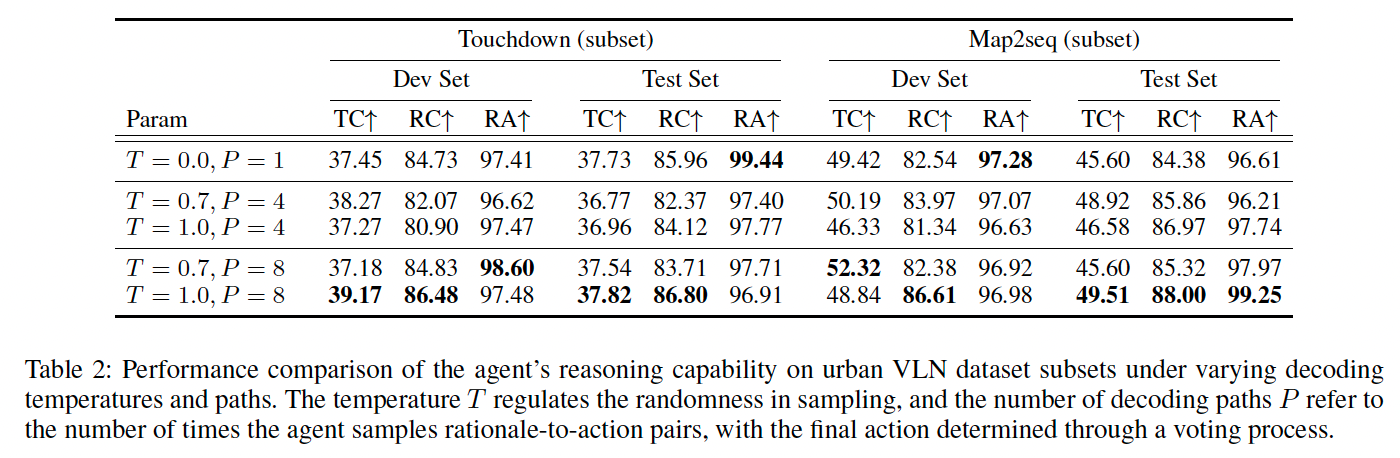
温度越高、路径越多,推理性能提升越显著。在 Touchdown 上,温度设为 1.0 且解码路径为 8 时,TC 提高 1.72%、RC 提高 1.75%;Map2seq 上 TC 提升 3.91%、RC 提升 3.62%。结果表明,多样化采样与推理集成增强了决策效果,进一步验证了三阶段推理微调的有效性。
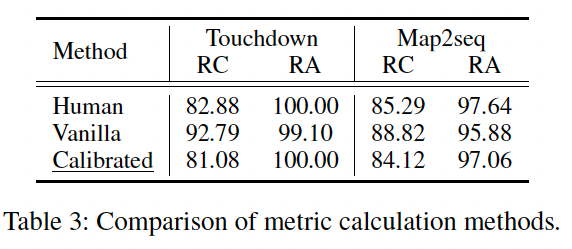
指标计算验证
为验证自动计算指标的可靠性,我们对 Touchdown 与 Map2seq 各抽取 50 个样本进行人工评估。表 3 显示初始指标存在偏差,经校准后明显减少误差,因此我们默认采用校准方法。
具体规则为:
- 若关键动作错误且 CFRrc=1,强制设 CFRrc=0;
- 若关键动作正确但 CFRra=0,强制设 CFRra=1。
模块与策略分析
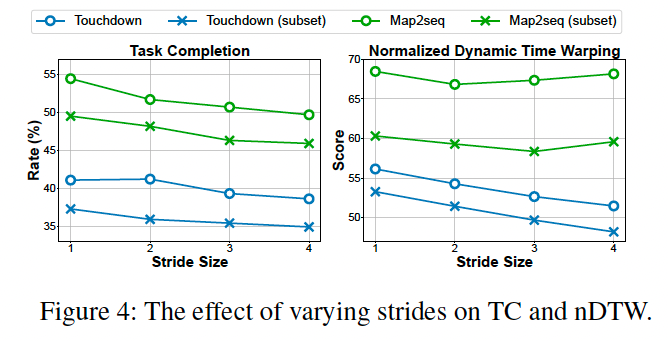
Strided Cross-Attention 效果分析 如图 4 所示,不同步长设置下,TC 总体呈下降趋势,说明聚焦最近观测比长历史更有效。nDTW 在 Map2seq 上波动较大,表明其对视觉信息依赖较弱。我们默认将步长设置为 1。
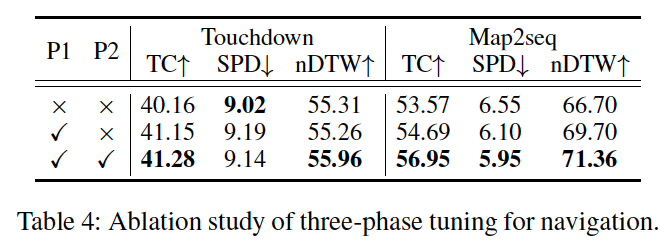
三阶段微调效果分析 表 4 展示了各阶段的贡献。基础模型(无 P1/P2 微调)性能最低;引入第一阶段后 TC 分别提升 0.99%、1.12%;第二阶段进一步提升性能。该结果强调三阶段策略能有效提升环境感知与决策能力。
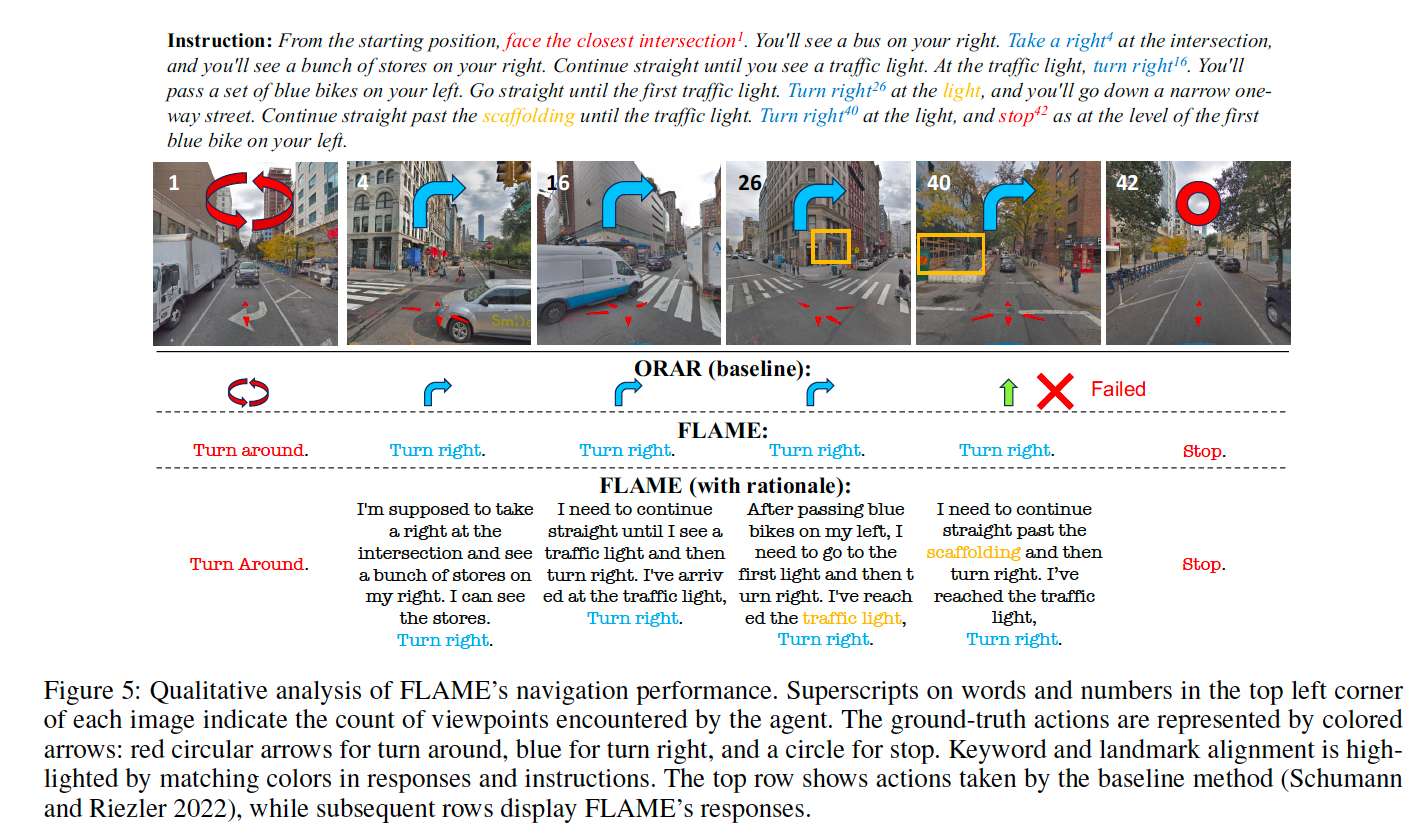
导航可视化分析 图 5 对比了 FLAME 与 ORAR 方法的实际导航表现。ORAR 在第 4 个路口失败,而 FLAME 成功完成任务,并准确识别关键地标如"红绿灯"和"脚手架",显示其优秀的指令理解和视觉感知能力。
5 结论
本文提出了一种用于城市视觉-语言导航任务的多模态大模型智能体 FLAME。通过三阶段微调与合成数据生成,我们显著提升了模型在 Touchdown 与 Map2seq 上的表现,超越现有方法。实验结果表明,FLAME 能有效融合语言与视觉信息,实现复杂场景中的推理与导航,展现出多模态 LLM 在具身智能领域中的巨大潜力。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 "Stay Hungry, Stay Foolish" ------ 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!
