文章目录
分布假设学习笔记
自然语言处理中的分布假设
分布假设(Distributional Hypothesis)是指:词语在相似上下文中出现,其意义也相似。换句话说,如果两个词在文本中经常出现在相似的环境中,那么它们的语义也很可能相近。
应用场景
- 词向量学习:如Word2Vec、GloVe等模型,利用分布假设通过上下文信息学习词的向量表示。
- 词义消歧:通过分析上下文,判断多义词的具体含义。
- 文本聚类与分类:基于词的分布特征对文本进行聚类或分类。
- 信息检索与推荐:根据词或短语的分布相似性改进检索和推荐效果。
适用范围
分布假设广泛适用于大多数自然语言处理任务,尤其是在无监督或弱监督学习中。它对低资源语言、专业领域文本等也有一定适用性,但对于需要深层语义理解或常识推理的任务,分布假设的能力有限,需结合其他方法提升效果。
Word2vec、BERT和GPT
Word2vec
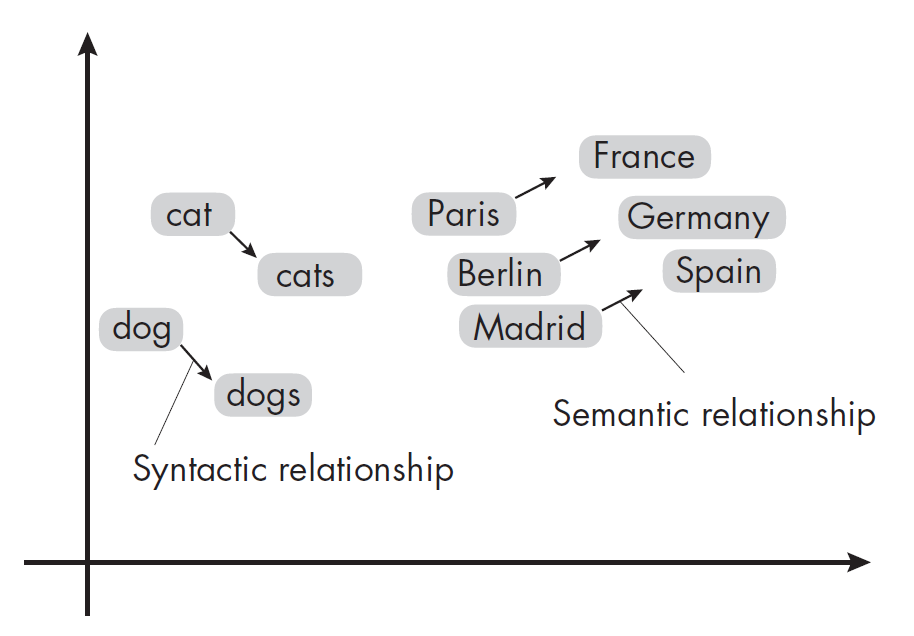
Word2vec 通过一个简单的两层神经网络,将词语编码为嵌入向量,确保相似词语的嵌入向量在语义和句法上也相近。训练Word2vec模型有两种方式:
-
CBOW(continuous bag-of-words,连续词袋)模型:Word2vec依据上下文中的词预测当前词。
-
跳字(skip-gram)模型:与CBOW相反,在跳字模型中,Word2vec根据选定的词来预测上下文词语。尽管跳字模型对于不常见的词更为有效,但CBOW模型通常训练速度更快。
BERT
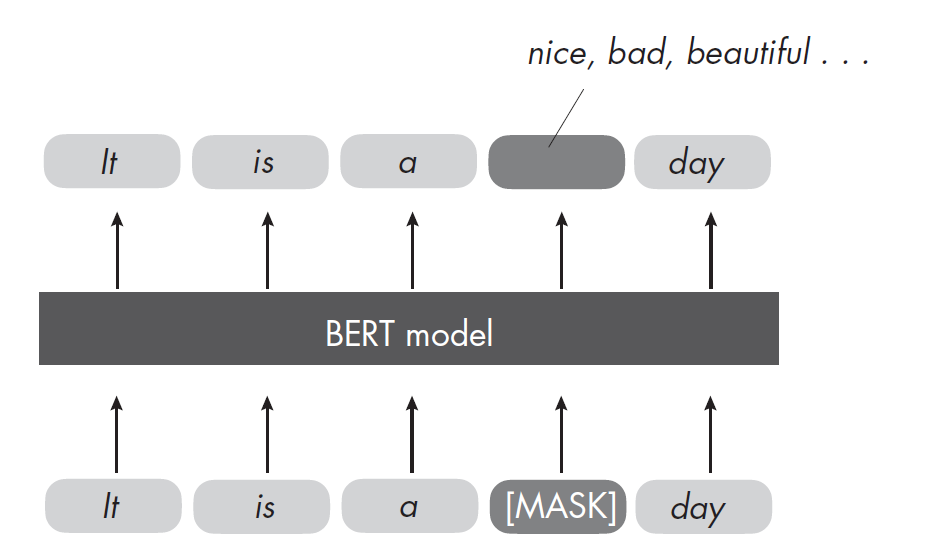
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer结构的预训练语言模型。它通过双向编码器同时关注上下文的左右信息,能够更好地理解词语在句子中的含义。BERT在大规模语料上进行预训练,然后通过微调应用于各种下游任务,如文本分类、问答和命名实体识别等,显著提升了自然语言处理的效果。
GPT
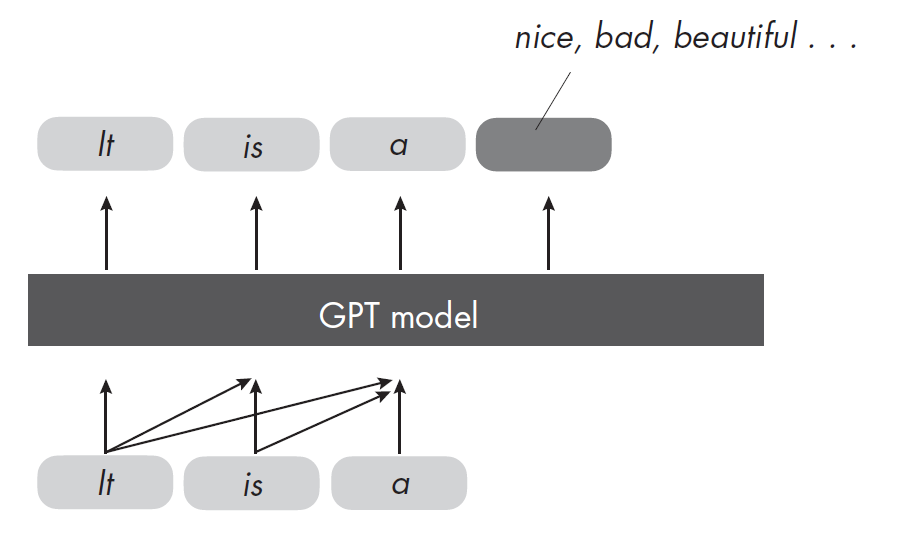
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的生成式预训练语言模型。GPT通过在大规模文本数据上进行自回归训练,学习根据已有文本生成下一个词,从而掌握语言的结构和语义。与BERT不同,GPT主要采用单向(从左到右)建模方式,擅长文本生成、对话系统、自动摘要等任务。经过预训练后,GPT可以通过微调适应各种自然语言处理应用。
假设成立吗
分布假设在大多数自然语言处理场景下是成立的,尤其是在大规模语料和统计学习方法中表现良好。它为词向量、文本聚类等任务提供了理论基础。然而,分布假设也有局限性:它主要关注词的表面共现关系,难以捕捉深层语义、常识推理或上下文依赖极强的语言现象。因此,现代NLP模型(如BERT、GPT)在分布假设基础上,结合了更复杂的结构和预训练目标,以提升对语言的理解和生成能力。
尽管存在一些分布假设不适用的反例,但它仍然是一个非常有用的概念,构成了今天语言类Transformer模型的基石。