https://zhuanlan.zhihu.com/p/1918449364008964557
主要是两个模块:Ego-Local-Agents Interactor和Focal-Local-Agents Loss。
主要流程是:状态提取 --> 图嵌入--> 交互得分 --> k-邻居选择 --> Focal-Local-Agents Loss
其中图嵌入 ,分为节点和边。节点就是障碍物自己的状态进行MLP,边的话是和主车状态的差值来做MLP


交互得分 主要用到了MHCA (Multi-Head Cross Attention) 将主车和其他障碍物的信息进行交互

再用MLP联合输出一个增强的特征表示 h_inc及其交互得分s_i ,表示该agent对自车决策的贡献。不太明白的点是为什么MLP能够生成两个结果???

k-邻居选择 如果交互得分比较高,那么Q_motion就会加上agent的信息。Q_motion是个什么东西???Q_plan也会考虑这些agent的信息 Q_plan又是个什么东西???


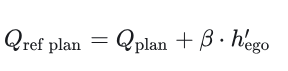
Focal-Local-Agents Loss: 对于重要障碍物的轨迹loss再算一遍


整体看下来主要就是对最重要的障碍物进行了筛选,那么如何选择最终要的障碍物就成了关键问题