数据仓库
Kappa架构:将实时和离线代码统一(优化lambda架构),但是不好修正数据,开发周期长,成本浪费,对于历史数据的高吞吐量力不从心
原一代数据仓库:
- 离线:hive+maxcompute
- 实时:clickhouse+driud
- 整合离线和实时:drill+presto
- 保存:mysql+redis
- 最后API
下一代:
- 要实时,很实时
- 离线和实时一体化,减少数据移动
- 通用性,要解耦
- 云原生,标准且生态
| 特点 | 数据库 | 缺点 |
|---|---|---|
| 支持事务+ACID | Mysql+presetSQL | 弹性伸缩难做到PD级别,且不能做复杂查询 |
| 分析加速,分布式 | presto+druid+hive+clickhouse... | 面向分析师 |
| 面向服务产品,高并发,查询简单 | hbase+redis+casandra |
既可以支持分析也可以支持事务:HTAP混合事务分析系统
- 需要事务机制保证ACID + 适合模型简单,简单分析场景,TP解决AP问题
既可以分析也可以服务:HSAP服务/分析一体化:Hologres
- 无事务开销(分布式锁、同步)
- 以数据仓库模型(抽象、服用、标准)解决数据服务问题

Hologres
产品特性:
- 分析服务一体化:point(点查询hbase/redis遇到的) /Ad-hoc(即席分析clickhouse)/OLAP(联机分析) 分析
- 以实时为中心:很快,数据实时写入和更新,与Flink原生集成,写入即可见
- 计算存储分离:存储资源和计算资源分离部署并独立扩展+和Maxcompute无缝打通
- 开放生态:兼容PF生态+对接PG开发工具+对接BI
Flink+hologres组合:实时大屏等

hologres:报表等离线加速

Flink+hologres+maxcompute:数据中台+精准营销+多维分析

Hologres架构原理
计算和存储相分离

计算:
- 接入节点Frontend(FE):SQL认证解析和优化,可以包含多个,兼容postgres11
- worker:执行引擎HQE(hologres query engine,极致查询)/PQE(postgres query engine,兼容postgres)/SQE(对接maxcompute,本地兼容访问maxcompute)+存储引擎(SH,shard,CURD)+缓存+调度(HOS轻量级)
- MetraService(管理元数据信息,同时提供给FE)+Holo Master(拉起Worker)
存储:
- 盘古文件系统
- 数据湖
SQL发送请求-frontend解析分发-worker执行-走不同路径-SE存储获取数据,合并后返回给FE
(点查直接搜Fixed FE)

HSAP挑战和Hologres应对策略

存储计算分离:三种
存储使用盘古

流批统一:底层支持行(PK)、列(OLAP)、行列共存

执行引擎+优化器

名词解释:

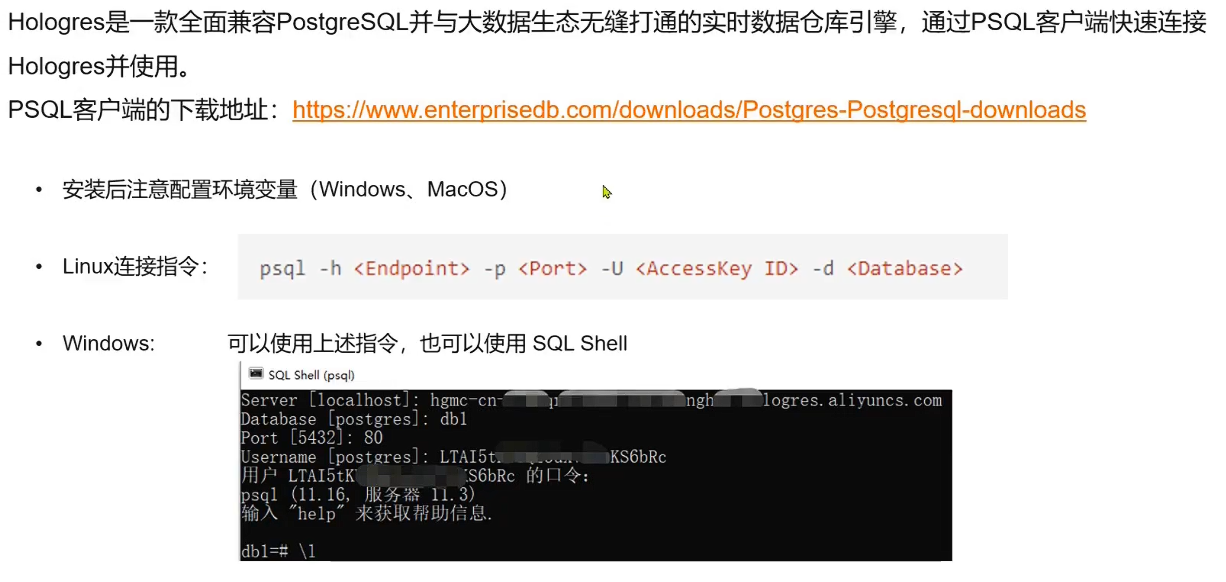
hologres开发工具:

PSQL客户端
JDBC连接hologres

数据同步
支持多种异构数据源的离线、实时写入

实时写入数据到hologres
进入hologres控制台--建库建表(1)-进入实时计算Flink控制台-作业开发-新建作业-创建原表和目标表(2)-执行-上线-运维-进入作业运维可以看到提交的作业-启动作业即可-在holoweb控制台查看是否成功(3)
(1)create table if not exists test1(a int ,b bigint ,c text,d timestamp);
(2_1)create temporary table datagen_source(a int ,b bigint,c string,proctime as proctime()) with ('connector'='datagen')flink随机源
(2_2)create temporary table holo_sink(a int,b bigint,c varchar,d timestamp) with ('connector'='hologres','endpoint'='XXX(hologres实例列表控制台查看)','username'='XX','password'='XX','dbname'='XX','tablename'='test1(上面建的表)')holo目标表
(2_3)insert into holo_sink select * from datagen_source;数据实时写入目标表
(3)select * from test1 order by d limit 2;/select count(1) from test1;

Maxcompute离线加速查询
单表创建/批量外表创建

dataworks控制台
- 数据开发
- 临时查询-新建数据源
- 创建表并插入数据
sh
create table if not exists odps_test(
shop_name string,
customer_id string,
total_price int
)
partitioned by (
sale_date string
)
#插入数据
insert into odps_test partition(sale_date='20221111') values('a','张三',50),('b','李四',55);
# 查看数据
read odps_test;- 创建holoweb外部表(元数据管理可视化创建/sql创建)
sql
create foreign table t_odps(
shop_name text,
customer_id text,
total_price int8,
sale_date text
)
server odps_server
options(project_name 'XXX项目空间名',table_name 'odps_test');
# 验证是否创建,相应会很快,dataworks慢,hologres加速查询!
select * from t_odps;- 外表完成加速查询完成
COPY命令导入导出数据

在psql里面,连接后测试copy命令
sql
#\d查看数据表
#建表
create table copy_test(
id int,
age int,
name text
);
# 从控制台(stdin)输入数据并复制到表
copy copy_test from stdin with delimiter as ',' null as '';
# 验证
select * from copy_test;
#从txt文件导入数据
cmd
psql -U XXX -p 80 -h XX -d X数据库名X -c "copy copy_test from stdin with delimiter ','; " < X文件路径X
#COPY N,代表写入了多少条数据
# 下载数据到本地
psql
\copy (select * from copy_test) to '本地路径/写入OSS';
#下载数据到OSS
psql/HoloWEB SQL编辑器
\copy (select * copy_test limit 2) to program '
hg_dump_to_odd
--AccessKeyId XX
--AccessKeySecret XX
--BucketName XX
--DirName X路径X
--FileName X文件名X
--BatchSize X多少记录X
'
# 最后到OSS查看验证即可Hologres数据开发
数据类型:

Maxcompute与Hologres数据类型映射:

Flink与Hologres数据类型映射:

Hologres扩展函数

DDL(表操作)和DML、DQL(表数据操作)

Hologres建表语法:(和PG一致,但是表属性有差异(CALL set_table_property))

分区表
静态分区
只能向子表插入数据
attach:绑定父表
detach:解绑父表

动态分区
| 配置项 | 含义 |
|---|---|
| auto_partitioning.enable | 开去动态分区(true/false) |
| auto_partitioning.time_unit | 时间单位,小时、天DAY、月、季度、年:每小时第一秒/每天凌晨第一秒进行分区创建或删除 |
| auto_partitioning.time_zone | 时区(Asia/Shanghai) |
| auto_partitioning.num_precreate | 创建分区数值(0-512,0表示不进行预创建,4代表创建4个) |
| auto_partitioning.num_retention | 保留历史分区数量(0不保留,-1不清理,正数保留历史分区个数,不超过512) |
| keep_alive | true/false:不删除过期数据/立即触发删除过期数据 |
自动创建删除分区

外部表

视图操作

插入insert操作:

删除和更新操作

insert on conflict
插入数据的时候,主键有重复值,选择更新还是跳过

truncate清空目标表
countinue identity 加上代表继续排序,序号不清空

HologresSQL高阶语法
SQL-partition-Shard-Segment-Row-Block


存储属性

行存:主键点查询
列存:数据分析OLAP
行列共存:都有但存储开销大,也需要主键
分布键

分段键

聚簇索引

字典编码

位图索引
向量进行高效计算

生命周期

Binlog操作

binglog格式

查询binlog

性能调优

更新统计信息
analyze

hologres数据存在盘古上面,一张表数据存储在固定一组表下,根据键分发在不同shard上面
需要设置合适的Shard Count

分布列

关闭Dictionary Encoding
关闭的时候会消耗CPU和内存资源,业务低峰期进行修改

使用Fixed Plan

PQE算子改写
not in(PQE) =》 not exist(HQE,效率更高)

KV查询场景

Hologres数仓建立
即席查询
指标修正简单

分钟级准实时

增量数据实时统计
