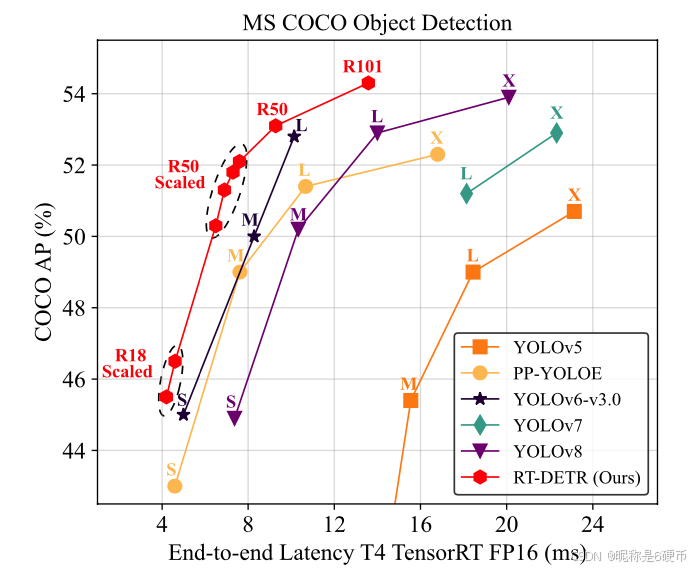
The YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy. However, we observe that the speed and accuracy of YOLOs are negatively affected by the NMS. Recently, end-to-end Transformer-based detectors (DETRs) have provided an alternative to eliminating NMS. Nevertheless, the high computational cost limits their practicality and hinders them from fully exploiting the advantage of excluding NMS. In this paper, we propose the R ealT ime DE tection TR ansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge that addresses the above dilemma. We build RT-DETR in two steps, drawing on the advanced DETR: first we focus on maintaining accuracy while improving speed, followed by maintaining speed while improving accuracy. Specifically, we design an efficient hybrid encoder to expeditiously process multi-scale features by decoupling intra-scale interaction and cross-scale fusion to improve speed. Then, we propose the uncertainty-minimal query selection to provide high-quality initial queries to the decoder, thereby improving accuracy. In addition, RT-DETR supports flexible speed tuning by adjusting the number of decoder layers to adapt to various scenarios without retraining. Our RT-DETR-R50 / R101 achieves 53.1 % / 54.3 % A 53.1\%/54.3\%A 53.1%/54.3%A P on COCO and 108 / 74 FPS on T4 GPU, outperforming previously advanced YOLOs in both speed and accuracy. Furthermore, RT-DETR-R50 outperforms DINO-R50 by 2.2 % 2.2\% 2.2% AP in accuracy and about 21 times in FPS. After pre-training with Objects365, RTDETR-R50 / R101 achieves 55.3 % / 56.2 % A 55.3\%/56.2\%A 55.3%/56.2%A P. The project page: https://zhao-yian.github.io/RTDETR .
Real-time object detection is an important area of research and has a wide range of applications, such as object tracking 43 , video surveillance 28 , and autonomous driv- ing 2 , etc. Existing real-time detectors generally adopt the CNN-based architecture, the most famous of which is the YOLO detectors 1 , 10 -- 12 , 15 , 16 , 25 , 30 , 38 , 40 due to their reasonable trade-off between speed and accuracy. However, these detectors typically require Non-Maximum Suppression (NMS) for post-processing, which not only slows down the inference speed but also introduces hyperparameters that cause instability in both the speed and accuracy. Moreover, considering that different scenarios place different emphasis on recall and accuracy, it is necessary to carefully select the appropriate NMS thresholds, which hinders the development of real-time detectors.
Recently, the end-to-end Transformer-based detectors (DETRs) 4 , 17 , 23 , 27 , 36 , 39 , 44 , 45 have received extensive attention from the academia due to their streamlined architecture and elimination of hand-crafted components. However, their high computational cost prevents them from meeting real-time detection requirements, so the NMS-free architecture does not demonstrate an inference speed advantage. This inspires us to explore whether DETRs can be extended to real-time scenarios and outperform the advanced YOLO detectors in both speed and accuracy, eliminating the delay caused by NMS for real-time object detection.
To achieve the above goal, we rethink DETRs and conduct detailed analysis of key components to reduce unnecessary computational redundancy and further improve accuracy. For the former, we observe that although the introduction of multi-scale features is beneficial in accelerating the training convergence 45 , it leads to a significant increase in the length of the sequence feed into the encoder. The high computational cost caused by the interaction of multi-scale features makes the Transformer encoder the computational bottleneck. Therefore, implementing the real-time DETR requires a redesign of the encoder. And for the latter, previous works 42 , 44 , 45 show that the hard-to-optimize object queries hinder the performance of DETRs and propose the query selection schemes to replace the vanilla learnable embeddings with encoder features. However, we observe that the current query selection directly adopt classification scores for selection, ignoring the fact that the detector are required to simultaneously model the category and location of objects, both of which determine the quality of the features. This inevitably results in encoder features with low localization confidence being selected as initial queries, thus leading to a considerable level of uncertainty and hurting the performance of DETRs. We view query initialization as a breakthrough to further improve performance.
In this paper, we propose the R ealT ime DE tection TR ansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge. To expeditiously process multi-scale features, we design an efficient hybrid encoder to replace the vanilla Transformer encoder, which significantly improves inference speed by decoupling the intra-scale interaction and cross-scale fusion of features with different scales. To avoid encoder features with low localization confidence being selected as object queries, we propose the uncertainty-minimal query selection, which provides highquality initial queries to the decoder by explicitly optimizing the uncertainty, thereby increasing the accuracy. Furthermore, RT-DETR supports flexible speed tuning to accommodate various real-time scenarios without retraining, thanks to the multi-layer decoder architecture of DETR.
RT-DETR achieves an ideal trade-off between the speed and accuracy. Specifically, RT-DETR-R50 achieves 53.1 % 53.1\% 53.1% AP on COCO val2017 and 108 FPS on T4 GPU, while RTDETR-R101 achieves 54.3 % 54.3\% 54.3% AP and 74 FPS, outperforming L L L and X X X models of previously advanced YOLO detectors in both speed and accuracy, Figure 1 . We also develop scaled RT-DETRs by scaling the encoder and decoder with smaller backbones, which outperform the lighter YOLO detectors ( S S S and M M M models). Furthermore, RT-DETR-R50 outperforms DINO-Deformable-DETR-R50 by 2.2 % 2.2\% 2.2% AP ( 53.1 % (53.1\% (53.1% AP vs 50.9 % 50.9\% 50.9% AP) in accuracy and by about 21 times in FPS ( 108 FPS vs 5 FPS), significantly improves accuracy and speed of DETRs. After pre-training with Objects365 35 , RTDETR-R50 / R101 achieves 55.3 % / 56.2 % 55.3\%/56.2\% 55.3%/56.2% AP, resulting in surprising performance improvements. More experimental results are provided in the Appendix.
【翻译】RT-DETR实现了速度和精度之间的理想权衡。具体来说,RT-DETR-R50在COCO val2017上达到 53.1 % 53.1\% 53.1% AP,在T4 GPU上达到108 FPS,而RT-DETR-R101达到 54.3 % 54.3\% 54.3% AP和74 FPS,在速度和精度方面都超越了之前先进YOLO检测器的 L L L和 X X X模型,如图1所示。我们还通过使用更小的骨干网络缩放编码器和解码器开发了缩放版RT-DETR,其性能超越了更轻量的YOLO检测器( S S S和 M M M模型)。此外,RT-DETR-R50在精度上比DINO-Deformable-DETR-R50高 2.2 % 2.2\% 2.2% AP( 53.1 % 53.1\% 53.1% AP vs 50.9 % 50.9\% 50.9% AP),在FPS上快约21倍(108 FPS vs 5 FPS),显著提高了DETRs的精度和速度。在使用Objects36535预训练后,RT-DETR-R50/R101达到 55.3 % / 56.2 % 55.3\%/56.2\% 55.3%/56.2% AP,取得了令人惊讶的性能提升。更多实验结果在附录中提供。
The main contributions are summarized as: (i). We propose the first real-time end-to-end object detector called RTDETR, which not only outperforms the previously advanced YOLO detectors in both speed and accuracy but also eliminates the negative impact caused by NMS post-processing on real-time object detection; (ii). We quantitatively analyze the impact of NMS on the speed and accuracy of YOLO detectors, and establish an end-to-end speed benchmark to test the end-to-end inference speed of real-time detectors; (iii). The proposed RT-DETR supports flexible speed tuning by adjusting the number of decoder layers to accommodate various scenarios without retraining.
YOLOv1 31 is the first CNN-based one-stage object detector to achieve true real-time object detection. Through years of continuous development, the YOLO detectors have outperformed other one-stage object detectors 21 , 24 and become the synonymous with the real-time object detector. YOLO detectors can be classified into two categories: anchor-based 1 , 11 , 15 , 25 , 29 , 30 , 37 , 38 and anchorfree 10 , 12 , 16 , 40 , which achieve a reasonable trade-off between speed and accuracy and are widely used in various practical scenarios. These advanced real-time detectors produce numerous overlapping boxes and require NMS postprocessing, which slows down their speed.
End-to-end object detectors are well-known for their streamlined pipelines. Carion et al . 4 first propose the end-toend detector based on Transformer called DETR, which has attracted extensive attention due to its distinctive features. Particularly, DETR eliminates the hand-crafted anchor and NMS components. Instead, it employs bipartite matching and directly predicts the one-to-one object set. Despite its obvious advantages, DETR suffers from several problems: slow training convergence, high computational cost, and hard-to-optimize queries. Many DETR variants have been proposed to address these issues. Accelerating convergence. Deformable-DETR 45 accelerates training convergence with multi-scale features by enhancing the efficiency of the attention mechanism. DAB-DETR 23 and DN-DETR 17 further improve performance by introducing the iterative refinement scheme and denoising training. Group-DETR 5 introduces group-wise one-to-many assignment. Reducing computational cost. Efficient DETR 42 and Sparse DETR 33 reduce the computational cost by reducing the number of encoder and decoder layers or the number of updated queries. Lite DETR 18 enhances the efficiency of encoder by reducing the update frequency of low-level features in an interleaved way. Optimizing query initialization. Conditional DETR 27 and Anchor DETR 39 decrease the optimization difficulty of the queries. Zhu et al . 45 propose the query selection for two-stage DETR, and DINO 44 suggests the mixed query selection to help better initialize queries. Current DETRs are still computationally intensive and are not designed to detect in real time. Our RT-DETR vigorously explores computational cost reduction and attempts to optimize query initialization, outperforming state-of-the-art real-time detectors.
Figure 2. The number of boxes at different confidence thresholds.
【翻译】图2. 不同置信度阈值下的边界框数量。
3. 检测器的端到端速度
3.1. NMS分析
NMS is a widely used post-processing algorithm in object detection, employed to eliminate overlapping output boxes. Two thresholds are required in NMS: confidence threshold and IoU threshold. Specifically, the boxes with scores below the confidence threshold are directly filtered out, and whenever the IoU of any two boxes exceeds the IoU threshold, the box with the lower score will be discarded. This process is performed iteratively until all boxes of every category have been processed. Thus, the execution time of NMS primarily depends on the number of boxes and two thresholds. To verify this observation, we leverage YOLOv5 11 (anchor-based) and YOLOv8 12 (anchor-free) for analysis.
We first count the number of boxes remaining after filtering the output boxes with different confidence thresholds on the same input. We sample values from 0 . 001 to 0 . 25 as confidence thresholds to count the number of remaining boxes of the two detectors and plot them on a bar graph, which intuitively reflects that NMS is sensitive to its hyperparameters, Figure 2 . As the confidence threshold increases, more prediction boxes are filtered out, and the number of remaining boxes that need to calculate IoU decreases, thus reducing the execution time of NMS.
Furthermore, we use YOLOv8 to evaluate the accuracy on the COCO val2017 and test the execution time of the NMS operation under different hyperparameters. Note that the NMS operation we adopt refers to the TensorRT efficientNMSPlugin , which involves multiple kernels, including EfficientNMSFilter , RadixSort EfficientNMS , etc ., and we only report the execution time of the EfficientNMS kernel. We test the speed on T4 GPU with TensorRT FP16, and the input and preprocessing remain consistent. The hyperparameters and the corresponding results are shown in Table 1 . From the results, we can conclude that the execution time of the EfficientNMS kernel increases as the confidence threshold decreases or the IoU threshold increases. The reason is that the high confidence threshold directly filters out more prediction boxes, whereas the high IoU threshold filters out fewer prediction boxes in each round of screening. We also visualize the predictions of YOLOv8 with different NMS thresholds in Appendix. The results show that inappropriate confidence thresholds lead to significant false positives or false negatives by the detector. With a confidence threshold of 0 . 001 and an IoU threshold of 0 . 7 , YOLOv8 achieves the best AP results, but the corresponding NMS time is at a higher level. Considering that YOLO detectors typically report the model speed and exclude the NMS time, thus an end-to-end speed benchmark needs to be established.
Table 1. The effect of IoU threshold and confidence threshold on accuracy and NMS execution time.
3.2. 端到端速度基准
To enable a fair comparison of the end-to-end speed of various real-time detectors, we establish an end-to-end speed benchmark. Considering that the execution time of NMS is influenced by the input, it is necessary to choose a benchmark dataset and calculate the average execution time across multiple images. We choose COCO val2017 20 as the benchmark dataset and append the NMS post-processing plugin of TensorRT for YOLO detectors as mentioned above. Specifically, we test the average inference time of the detector according to the NMS thresholds of the corresponding accuracy taken on the benchmark dataset, excluding KaTeX parse error: Undefined control sequence: \I at position 1: \̲I̲/0 and MemoryCopy operations. We utilize the benchmark to test the end-to-end speed of anchor-based detectors YOLOv5 11 and YOLOv7 38 , as well as anchor-free detectors PP-YOLOE 40 , YOLOv6 16 and YOLOv8 12 on T4 GPU with TensorRT FP16. According to the results ( cf. Table 2 ), we conclude that anchor-free detectors outperform anchor-based detectors with equivalent accuracy for YOLO detectors because the former require less NMS time than the latter . The reason is that anchor-based detectors produce more prediction boxes than anchor-free detectors (three times more in our tested detectors).
【翻译】为了能够公平比较各种实时检测器的端到端速度,我们建立了一个端到端速度基准。考虑到NMS的执行时间受输入影响,有必要选择一个基准数据集并计算多张图像的平均执行时间。我们选择COCO val201720作为基准数据集,并为YOLO检测器附加上述提到的TensorRT的NMS后处理插件。具体来说,我们根据在基准数据集上获得相应精度的NMS阈值测试检测器的平均推理时间,排除KaTeX parse error: Undefined control sequence: \I at position 1: \̲I̲/0和MemoryCopy操作。我们利用该基准在T4 GPU上使用TensorRT FP16测试基于锚框的检测器YOLOv511和YOLOv738,以及无锚框检测器PP-YOLOE40、YOLOv616和YOLOv812的端到端速度。根据结果(参见表2),我们得出结论:对于YOLO检测器,在相同精度下,无锚框检测器优于基于锚框的检测器,因为前者比后者需要更少的NMS时间。原因是基于锚框的检测器比无锚框检测器产生更多的预测框(在我们测试的检测器中多三倍)。
Figure 3. The encoder structure for each variant. SSE represents the single-scale Transformer encoder, MSE represents the multi-scale Transformer encoder, and CSF represents cross-scale fusion. AIFI and CCFF are the two modules designed into our hybrid encoder.
RT-DETR consists of a backbone, an efficient hybrid encoder, and a Transformer decoder with auxiliary prediction heads. The overview of RT-DETR is illustrated in Figure 4 . Specifically, we feed the features from the last three stages of the backbone cient hybrid encoder transforms multi-scale features into a { S 3 , S 4 , S 5 } \{\pmb{S}{3},\pmb{S}{4},\pmb{S}_{5}\} {S3,S4,S5} into the encoder. The effisequence of image features through intra-scale feature interaction and cross-scale feature fusion ( cf. Sec. 4.2 ). Subsequently, the uncertainty-minimal query selection is employed to select a fixed number of encoder features to serve as initial object queries for the decoder ( cf. Sec. 4.3 ). Finally, the decoder with auxiliary prediction heads iteratively optimizes object queries to generate categories and boxes.
【翻译】RT-DETR由骨干网络、高效混合编码器和带有辅助预测头的Transformer解码器组成。RT-DETR的概述如图4所示。具体来说,我们将骨干网络最后三个阶段的特征 { S 3 , S 4 , S 5 } \{\pmb{S}{3},\pmb{S}{4},\pmb{S}_{5}\} {S3,S4,S5}输入编码器。高效混合编码器通过尺度内特征交互和跨尺度特征融合将多尺度特征转换为图像特征序列(参见第4.2节)。随后,采用不确定性最小查询选择来选择固定数量的编码器特征作为解码器的初始目标查询(参见第4.3节)。最后,带有辅助预测头的解码器迭代优化目标查询以生成类别和边界框。
Computational bottleneck analysis. The introduction of multi-scale features accelerates training convergence and improves performance 45 . However, although the deformable attention reduces the computational cost, the sharply increased sequence length still causes the encoder to become the computational bottleneck. As reported in Lin et al . 19 , the encoder accounts for 49 % 49\% 49% of the GFLOPs but contributes only 11 % 11\% 11% of the AP in Deformable-DETR. To overcome this bottleneck, we first analyze the computational redundancy present in the multi-scale Transformer encoder. Intuitively, high-level features that contain rich semantic information about objects are extracted from low-level features, making it redundant to perform feature interaction on the concatenated multi-scale features. Therefore, we design a set of variants with different types of the encoder to prove that the simultaneous intra-scale and cross-scale feature interaction is inefficient, Figure 3 . Specially, we use DINO-Deformable-R50 with the smaller size data reader and lighter decoder used in RT-DETR for experiments and first remove the multi-scale Transformer encoder in DINO-Deformable-R50 as variant A. Then, different types of the encoder are inserted to produce a series of variants based on A, elaborated as follows (Detailed indicators of each variant are referred to in Table 3 ):
• A → B \mathbf{A}\rightarrow\mathbf{B} A→B : Variant B inserts a single-scale Transformer encoder into A, which uses one layer of Transformer block. The multi-scale features share the encoder for intra-scale feature interaction and then concatenate as output.
• B → C \mathrm{B}\to\mathrm{C} B→C : Variant C introduces cross-scale feature fusion based on B and feeds the concatenated features into the multi-scale Transformer encoder to perform simultaneous intra-scale and cross-scale feature interaction.
• C → D \mathbf{C}\rightarrow\mathbf{D} C→D : Variant D decouples intra-scale interaction and cross-scale fusion by utilizing the single-scale Transformer encoder for the former and a PANet-style 22 structure for the latter.
• D → E \mathrm{D}\rightarrow\mathrm{E} D→E : Variant E enhances the intra-scale interaction and cross-scale fusion based on D, adopting an efficient hybrid encoder designed by us.
【翻译】
• A → B \mathbf{A}\rightarrow\mathbf{B} A→B:变体B在A中插入单尺度Transformer编码器,使用一层Transformer块。多尺度特征共享编码器进行尺度内特征交互,然后连接作为输出。
• B → C \mathrm{B}\to\mathrm{C} B→C:变体C在B的基础上引入跨尺度特征融合,将连接的特征输入多尺度Transformer编码器以同时执行尺度内和跨尺度特征交互。
• C → D \mathbf{C}\rightarrow\mathbf{D} C→D:变体D通过利用单尺度Transformer编码器进行前者,PANet风格22结构进行后者,将尺度内交互和跨尺度融合解耦。
• D → E \mathrm{D}\rightarrow\mathrm{E} D→E:变体E在D的基础上增强尺度内交互和跨尺度融合,采用我们设计的高效混合编码器。
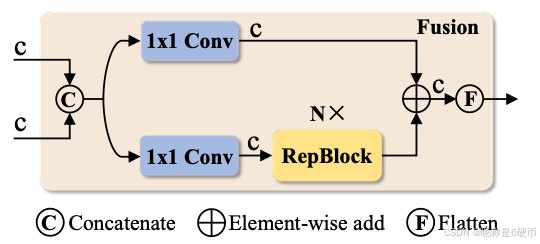
Hybrid design. Based on the above analysis, we rethink the structure of the encoder and propose an efficient hybrid encoder , consisting of two modules, namely the Attentionbased Intra-scale Feature Interaction (AIFI) and the CNNbased Cross-scale Feature Fusion (CCFF). Specifically, AIFI further reduces the computational cost based on variant D by performing the intra-scale interaction only on S 5 \pmb{S}{5} S5 with the single-scale Transformer encoder. The reason is that applying the self-attention operation to high-level features with richer semantic concepts captures the connection between conceptual entities, which facilitates the localization and recognition of objects by subsequent modules. However, the intra-scale interactions of lower-level features are unnecessary due to the lack of semantic concepts and the risk of duplication and confusion with high-level feature interactions. To verify this opinion, we perform the intra-scale interaction only on S 5 \pmb{S}{5} S5 in variant D \mathrm{D} D , and the experimental results are reported in Table 3 (see row D S 5 \mathrm{D}{S{5}} DS5 ). Compared to D, D S 5 \mathrm{D}{\mathcal{S}{5}} DS5 not only significantly reduces latency ( 35 % 35\% 35% faster), but also improves accuracy 0.4 % 0.4\% 0.4% AP higher). CCFF is optimized based on the cross-scale fusion module, which inserts several fusion blocks consisting of convolutional layers into the fusion path. The role of the fusion block is to fuse two adjacent scale features into a new feature, and its structure is illustrated in Figure 5 . The fusion block conta s two 1 × 1 1\times1 1×1 convolutions to adjust the number of channels, N N N RepBlock s composed of RepConv 8 are used for feature fusion, and the two-path outputs are fused by element-wise add. We formulate the calculation of the hybrid encoder as:
【翻译】混合设计。基于上述分析,我们重新思考编码器的结构,并提出了一个高效混合编码器,由两个模块组成,即基于注意力的尺度内特征交互(AIFI)和基于CNN的跨尺度特征融合(CCFF)。具体来说,AIFI在变体D的基础上进一步降低计算成本,仅在 S 5 \pmb{S}{5} S5上使用单尺度Transformer编码器执行尺度内交互。原因是将自注意力操作应用于具有更丰富语义概念的高级特征能够捕获概念实体之间的连接,这有助于后续模块对目标的定位和识别。然而,低级特征的尺度内交互是不必要的,因为缺乏语义概念,并且存在与高级特征交互重复和混淆的风险。为了验证这一观点,我们在变体 D \mathrm{D} D中仅在 S 5 \pmb{S}{5} S5上执行尺度内交互,实验结果在表3中报告(见行 D S 5 \mathrm{D}{S{5}} DS5)。与D相比, D S 5 \mathrm{D}{\mathcal{S}{5}} DS5不仅显著降低了延迟(快 35 % 35\% 35%),还提高了精度(AP高 0.4 % 0.4\% 0.4%)。CCFF基于跨尺度融合模块进行优化,在融合路径中插入由卷积层组成的几个融合块。融合块的作用是将两个相邻尺度特征融合为新特征,其结构如图5所示。融合块包含两个 1 × 1 1\times1 1×1卷积来调整通道数, N N N个由RepConv8组成的RepBlock用于特征融合,两路输出通过逐元素相加进行融合。我们将混合编码器的计算公式化为:
Q = K = V = F l a t t e n ( S 5 ) , F 5 = R e s h a p e ( A I F I ( Q , K , V ) ) , O = C C F F ( { S 3 , S 4 , F 5 } ) , \begin{array}{r l}&{\pmb{\mathcal{Q}}=\pmb{\mathcal{K}}=\pmb{\mathcal{V}}=\mathrm{F}\mathrm{latt}\mathrm{en}(\pmb{\mathcal{S}}{5}),}\\ &{\pmb{\mathcal{F}}{5}=\mathrm{Reshape}(\mathrm{AIFI}(\pmb{\mathcal{Q}},\pmb{\mathcal{K}},\pmb{\mathcal{V}})),}\\ &{\pmb{\mathcal{O}}=\mathrm{CCFF}(\{\pmb{\mathcal{S}}{3},\pmb{\mathcal{S}}{4},\pmb{\mathcal{F}}_{5}\}),}\end{array} Q=K=V=Flatten(S5),F5=Reshape(AIFI(Q,K,V)),O=CCFF({S3,S4,F5}),
where Reshape represents restoring the shape of the flattened feature to the same shape as S 5 \pmb{S}_{5} S5 .
【翻译】其中Reshape表示将扁平化特征的形状恢复为与 S 5 \pmb{S}_{5} S5相同的形状。
【解析】RT-DETR的混合编码器设计体现了一种精细化的计算资源分配策略。传统的多尺度Transformer编码器对所有尺度的特征都进行相同强度的处理,这种"一刀切"的方式忽略了不同尺度特征的本质差异。作者通过深入分析发现,高级特征(如 S 5 \pmb{S}{5} S5)包含了丰富的语义信息,这些信息对于理解图像中的目标类别和概念关系至关重要。自注意力机制在这个层次上能够发挥最大价值,因为它能够建立不同语义概念之间的长距离依赖关系,比如识别出图像中的"人"和"自行车"之间的交互关系。相比之下,低级特征主要包含边缘、纹理等基础视觉信息,这些信息的空间关系相对简单,不需要复杂的自注意力机制来处理。更重要的是,如果对低级特征也应用自注意力,可能会产生与高级特征处理过程的信息冗余,甚至可能引入噪声干扰。AIFI模块的设计正是基于这种认识,它只对最高级的特征 S 5 \pmb{S}{5} S5应用Transformer编码器,大幅减少了计算量。CCFF模块则专门负责跨尺度的特征融合,它使用CNN的层次化结构来有效整合不同分辨率的信息。融合块的设计很巧妙:首先用 1 × 1 1\times1 1×1卷积调整通道维度以确保特征兼容性,然后用RepBlock进行深度特征融合,最后通过逐元素相加实现信息整合。这种设计既保持了特征融合的有效性,又避免了Transformer在多尺度处理中的计算瓶颈。公式中的处理流程展示了这种分工合作的机制:首先将 S 5 \pmb{S}_{5} S5扁平化为序列形式供AIFI处理,然后将处理结果重新整形,最后与其他尺度特征一起送入CCFF进行跨尺度融合。
Figure 4. Overview of RT-DETR. We feed the features from the last three stages of the backbone into the encoder. The efficient hybrid encoder transforms multi-scale features into a sequence of image features through the Attention-based Intra-scale Feature Interaction (AIFI) and the CNN-based Cross-scale Feature Fusion (CCFF). Then, the uncertainty-minimal query selection selects a fixed number of encoder features to serve as initial object queries for the decoder. Finally, the decoder with auxiliary prediction heads iteratively optimizes object queries to generate categories and boxes.
To reduce the difficulty of optimizing object queries in DETR, several subsequent works 42 , 44 , 45 propose query selection schemes, which have in common that they use the confidence score to select the top K K K features from the encoder to initialize object queries (or just position queries).
【翻译】为了降低DETR中优化目标查询的难度,几个后续工作42, 44, 45提出了查询选择方案,它们的共同点是使用置信度分数从编码器中选择前 K K K个特征来初始化目标查询(或仅位置查询)。
The confidence score represents the likelihood that the feature includes foreground objects. Nevertheless, the detector are required to simultaneously model the category and location of objects, both of which determine the quality of the features. Hence, the performance score of the feature is a latent variable that is jointly correlated with both classification and localization. Based on the analysis, the current query selection lead to a considerable level of uncertainty in the selected features, resulting in sub-optimal initialization for the decoder and hindering the performance of the detector.
To address this problem, we propose the uncertainty minimal query selection scheme, which explicitly constructs and optimizes the epistemic uncertainty to model the joint latent variable of encoder features, thereby providing high-quality queries for the decoder. Specifically, the feature uncertainty U \mathcal{U} U is defined as the discre ncy between the p dicted disTo minimize the uncertainty of the queries, we integrate tributions of localization P and classification C in Eq. ( 2 ). the uncertainty into the loss function for the gradient-based optimization in Eq. ( 3 ).
【翻译】为了解决这个问题,我们提出了不确定性最小查询选择方案,该方案显式构建和优化认知不确定性来建模编码器特征的联合潜在变量,从而为解码器提供高质量的查询。具体来说,特征不确定性 U \mathcal{U} U被定义为定位P和分类C的预测分布之间的差异,如公式(2)所示。为了最小化查询的不确定性,我们将不确定性集成到损失函数中进行基于梯度的优化,如公式(3)所示。
U ( X ^ ) = ∥ P ( X ^ ) − C ( X ^ ) ∥ , X ^ ∈ R D \mathcal{U}(\hat{\pmb{\mathscr{X}}})=\|\mathcal{P}(\hat{\pmb{\mathscr{X}}})-\mathscr{C}(\hat{\pmb{\mathscr{X}}})\|,\hat{\pmb{\mathscr{X}}}\in\mathbb{R}^{D} U(X^)=∥P(X^)−C(X^)∥,X^∈RD
L ( X ^ , y ^ , y ) = L b o x ( b ^ , b ) + L c l s ( U ( x ^ ) , c ^ , c ) \mathcal{L}(\hat{\pmb{\mathscr{X}}},\hat{\pmb{\mathscr{y}}},\pmb{\mathscr{y}})=\mathcal{L}{b o x}(\hat{\bf b},{\bf b})+\mathcal{L}{c l s}(\mathcal{U}(\hat{\pmb{x}}),\hat{\bf c},{\bf c}) L(X^,y^,y)=Lbox(b^,b)+Lcls(U(x^),c^,c)
where Y ^ \hat{\mathcal{Y}} Y^ and Y \mathcal{Y} Y denote the prediction and ground truth, Y ^ = { c ^ , b ^ } \hat{\mathcal{Y}} = \{\hat{c}, \hat{b}\} Y^={c^,b^}, c ^ \hat{c} c^ and b ^ \hat{b} b^ represent the category and bounding box respectively, X ^ \hat{\mathcal{X}} X^ represent the encoder feature.
【翻译】其中 Y ^ \hat{\mathcal{Y}} Y^和 Y \mathcal{Y} Y分别表示预测值和真实值, Y ^ = { c ^ , b ^ } \hat{\mathcal{Y}} = \{\hat{c}, \hat{b}\} Y^={c^,b^}, c ^ \hat{c} c^和 b ^ \hat{b} b^分别表示类别和边界框, X ^ \hat{\mathcal{X}} X^表示编码器特征。
【解析】公式定义了损失函数中各个符号的含义,建立了预测输出与真实标签之间的对应关系。在目标检测任务中,模型需要同时预测目标的类别和位置信息,因此预测输出 Y ^ \hat{\mathcal{Y}} Y^被分解为两个组成部分:类别预测 c ^ \hat{c} c^和边界框预测 b ^ \hat{b} b^。编码器特征 X ^ \hat{\mathcal{X}} X^是整个预测过程的基础,它包含了从输入图像中提取的语义和空间信息。通过将这些特征输入到分类和定位分支中,模型可以生成相应的预测结果。
Effectiveness analysis. To analyze the effectiveness of the uncertainty-minimal query selection, we visualize the classification scores and IoU scores of the selected features on COCO val2017 , Figure 6 . We draw the scatterplot with classification scores greater than 0 . 5 . The purple and green dots represent the selected features from the model trained with uncertainty-minimal query selection and vanilla query selection, respectively. The closer the dot is to the top right of the figure, the higher the quality of the corresponding feature, i.e ., the more likely the predicted category and box are to describe the true object. The top and right density curves reflect the number of dots for two types.
Figure 6. Classification and IoU scores of the selected encoder features. Purple and Green dots represent the selected features from model trained with uncertainty-minimal query selection and vanilla query selection, respectively.
The most striking feature of the scatterplot is that the purple dots are concentrated in the top right of the figure, while the green dots are concentrated in the bottom right. This shows that uncertainty-minimal query selection produces more high-quality encoder features. Furthermore, we perform quantitative analysis on two query selection schemes. There are 138 % 138\% 138% more purple dots than green dots, i.e ., more green dots with a classification score less than or equal to 0 . 5 , which can be considered low-quality features. And there are 120 % 120\% 120% more purple dots than green dots with both scores greater than 0 . 5 . The same conclusion can be drawn from the density curves, where the gap between purple and green is most evident in the top right of the figure. Quantitative results further demonstrate that the uncertainty-minimal query selection provides more features with accurate classification and precise location for queries, thereby improving the accuracy of the detector ( cf. Sec. 5.3 ).
Since real-time detectors typically provide models at different scales to accommodate different scenarios, RT-DETR also supports flexible scaling. Specifically, for the hybrid encoder, we control the width by adjusting the embedding dimension and the number of channels, and the depth by adjusting the number of Transformer layers and RepBlock s.
The width and depth of the decoder can be controlled by manipulating the number of object queries and decoder layers. Furthermore, the speed of RT-DETR supports flexible adjustment by adjusting the number of decoder layers. We observe that removing a few decoder layers at the end has minimal effect on accuracy, but greatly enhances inference speed ( cf. Sec. 5.4 ). We compare the RT-DETR equipped with ResNet50 and ResNet101 13 , 14 to the L L L and X X X models of YOLO detectors. Lighter RT-DETRs can be designed by applying other smaller ( e.g ., ResNet18/34) or scalable ( e.g ., CSPResNet 40 ) backbones with scaled encoder and decoder. We compare the scaled RT-DETRs with the lighter ( S \boldsymbol{S} S and M M M ) YOLO detectors in Appendix, which outperform all S S S and M M M models in both speed and accuracy.
【翻译】解码器的宽度和深度可以通过操控目标查询的数量和解码器层数来控制。此外,RT-DETR的速度支持通过调整解码器层数进行灵活调整。我们观察到移除末尾的几个解码器层对精度的影响很小,但大大提高了推理速度(参见第5.4节)。我们将配备ResNet50和ResNet101的RT-DETR与YOLO检测器的 L L L和 X X X模型进行比较。通过应用其他更小的(如ResNet18/34)或可扩展的(如CSPResNet)骨干网络以及相应缩放的编码器和解码器,可以设计出更轻量的RT-DETR。我们在附录中将缩放的RT-DETR与更轻量的( S \boldsymbol{S} S和 M M M)YOLO检测器进行比较,结果显示在速度和精度方面都优于所有 S S S和 M M M模型。
Table 2 compares RT-DETR with current real-time (YOLOs) and end-to-end (DETRs) detectors, where only the L L L and X X X models of the YOLO detector are compared, and the S S S and M M M models are compared in Appendix. Our RT-DETR and YOLO detectors share a common input size of (640, 640), and other DETRs use an input size of (800, 1333). The FPS is reported on T4 GPU with TensorRT FP16, and for YOLO detectors using official pre-trained models according to the end-to-end speed benchmark proposed in Sec. 3.2 . Our RT-DETR-R50 achieves 53.1 % 53.1\% 53.1% AP and 108 FPS, while RTDETR-R101 achieves 54.3 % 54.3\% 54.3% AP and 74 FPS, outperforming state-of-the-art YOLO detectors of similar scale and DETRs with the same backbone in both speed and accuracy. The experimental settings are shown in Appendix.
【翻译】表2将RT-DETR与当前的实时检测器(YOLOs)和端到端检测器(DETRs)进行了比较,其中只比较了YOLO检测器的 L L L和 X X X模型, S S S和 M M M模型的比较在附录中。我们的RT-DETR和YOLO检测器共享相同的输入尺寸(640, 640),其他DETR使用输入尺寸(800, 1333)。FPS在T4 GPU上使用TensorRT FP16报告,YOLO检测器使用官方预训练模型,根据第3.2节提出的端到端速度基准测试。我们的RT-DETR-R50达到了 53.1 % 53.1\% 53.1% AP和108 FPS,而RT-DETR-R101达到了 54.3 % 54.3\% 54.3% AP和74 FPS,在速度和精度方面都优于相似规模的最先进YOLO检测器和使用相同骨干网络的DETR。实验设置在附录中显示。
Comparison with real-time detectors. We compare the end-to-end speed ( cf. Sec. 3.2 ) and accuracy of RTDETR with YOLO detectors. We compare RT-DETR with YOLOv5 11 , PP-YOLOE 40 , YOLOv6v3.0 16 (hereinafter referred to as YOLOv6), YOLOv7 38 and YOLOv8 12 . Compared to YOLOv5-L / PP-YOLOE-L / YOLOv6-L, RT-DETR-R50 improves accuracy by 4.1 % / 4.1\%/ 4.1%/ 1.7 % / 0.3 % 1.7\%/0.3\% 1.7%/0.3% AP, increases FPS by 100.0 % / 14.9 % / 9.1 % 100.0\%/14.9\%/9.1\% 100.0%/14.9%/9.1% , and reduces the number of parameters by 8.7 % / 19.2 % 8.7\%\mathrm{~/~}19.2\% 8.7% / 19.2% 128.8% \textit{128.8\%} 128.8% . Compared to YOLOv5-X / PP-YOLOE-X, RT- DETR-R101 improves accuracy by 3.6 % / 2.0 % 3.6\%/2.0\% 3.6%/2.0% , increases FPS by 72.1 % / 23.3 % 72.1\%\mathrm{~/~}23.3\% 72.1% / 23.3% , and reduces the number of parameters by 11.6 % / 22.4 % 11.6\%\mathrm{~/~}22.4\% 11.6% / 22.4% . Compared to Y O L O v 7 − L ∣ \mathrm{YOLOv}7\mathrm{-L}\mid YOLOv7−L∣ YOLOv8-L, RT-DETR-R50 improves accuracy by 1.9 % , 1.9\%, 1.9%, / 0.2 % 0.2\% 0.2% AP and increases FPS by 96.4 % / 52.1 % 96.4\%/52.1\% 96.4%/52.1% . Compared to YOLOv7-X / YOLOv8-X, RT-DETR-R101 improves ac- curacy by 1.4 % / 0.4 % 1.4\%\mathrm{~/~}0.4\% 1.4% / 0.4% AP and increases FPS by 64.4 % 7 64.4\%7 64.4%7 48.0 % 48.0\% 48.0% . This shows that our RT-DETR achieves state-of-theart real-time detection performance.
Comparison with end-to-end detectors. We also compare RT-DETR with existing DETRs using the same backbone.
【翻译】与端到端检测器的比较。我们还将RT-DETR与使用相同骨干网络的现有DETR进行比较。
Table 2. Comparison with SOTA (only L L L and X X X models of YOLO detectors, see Appendix for the comparison with S S S and M M M models). We do not test the speed of other DETRs, except for DINO-Deformable-DETR 44 for comparison, as they are not real-time detectors. Our RT-DETR outperforms the state-of-the-art YOLO detectors and DETRs in both speed and accuracy.
【翻译】表2. 与SOTA的比较(仅YOLO检测器的 L L L和 X X X模型,与 S S S和 M M M模型的比较见附录)。除了DINO-Deformable-DETR 44用于比较外,我们没有测试其他DETR的速度,因为它们不是实时检测器。我们的RT-DETR在速度和精度方面都优于最先进的YOLO检测器和DETR。
We test the speed of DINO-Deformable-DETR 44 according to the settings of the corresponding accuracy taken on COCO val2017 for comparison, i.e ., the speed is tested with TensorRT FP16 and the input size is (800, 1333). Table 2 shows that RT-DETR outperforms all DETRs with the same backbone in both speed and accuracy. Compared to DINO-Deformable-DETR-R50, RT-DETR-R50 improves the accuracy by 2.2 % 2.2\% 2.2% AP and the speed by 21 times ( 108 FPS vs 5 FPS), both of which are significantly improved.
We evaluate the indicators of the variants designed in Sec. 4.2 , including AP (trained with 1 × 1\times 1× configuration), the number of parameters, and the latency, Table 3 . Compared to baseline A, variant B improves accuracy by 1.9 % 1.9\% 1.9% AP and increases the latency by 54 % 54\% 54% . This proves that the intrascale feature interaction is significant, but the single-scale Transformer encoder is computationally expensive. Variant C delivers a 0.7 % 0.7\% 0.7% AP improvement over B and increases the latency by 20 % 20\% 20% . This shows that the cross-scale feature fusion is also necessary but the multi-scale Transformer encoder requires higher computational cost. Variant D delivers a 0.8 % 0.8\% 0.8% AP improvement over C, but reduces latency by 8 % 8\% 8% , suggesting that decoupling intra-scale interaction and crossscale fusion not only reduces computational cost but also improves accuracy. Compared to variant D, D S 5 D_{S_{5}} DS5 reduces the latency by 35 % 35\% 35% but delivers 0.4 % 0.4\% 0.4% AP improvement, demonstrating that intra-scale interactions of lower-level features are not required. Finally, variant E delivers 1.5 % 1.5\% 1.5% AP improvement over D. Despite a 20 % 20\% 20% increase in the number of parameters, the latency is reduced by 24 % 24\% 24% , making the encoder more efficient. This shows that our hybrid encoder achieves a better trade-off between speed and accuracy.
We conduct an ablation study on uncertainty-minimal query selection, and the results are reported on RT-DETR-R50 with 1 × 1\times 1× configuratio T e query selection in RT-DETR selects the top K ( K = 300 K=300 K=300 encoder features according to the classification scores as the content queries, and the prediction boxes corresponding to the selected features are used as initial position queries. We compare the encoder features selected by the two query selection schemes on COCO val2017 and calculate the proportions of classification scores greater than 0 . 5 and both classification and IoU scores greater than 0 . 5 , respectively. The results show that the encoder features selected by uncertainty-minimal query selection not only increase the proportion of high classification scores ( 0.82 % (0.82\% (0.82% vs 0.35 % 0.35\% 0.35% ) but also provide more high-quality features ( 0.67 % (0.67\% (0.67% vs 0.30 % 0.30\% 0.30% ). We also evaluate the accuracy of the detectors trained with the two query selection schemes on COCO val2017 , where the uncertainty- minimal query selection achieves an improvement of 0.8 % 0.8\% 0.8% AP ( 48.7 % 48.7\% 48.7% AP vs 47.9 % 47.9\% 47.9% AP).
【翻译】我们对不确定性最小查询选择进行了消融研究,结果在使用 1 × 1\times 1×配置的RT-DETR-R50上报告。RT-DETR中的查询选择根据分类分数选择前K个( K = 300 K=300 K=300)编码器特征作为内容查询,与所选特征对应的预测框用作初始位置查询。我们在COCO val2017上比较了两种查询选择方案选择的编码器特征,并分别计算分类分数大于0.5和分类与IoU分数都大于0.5的比例。结果表明,不确定性最小查询选择选择的编码器特征不仅增加了高分类分数的比例( 0.82 % 0.82\% 0.82% vs 0.35 % 0.35\% 0.35%),还提供了更多高质量特征( 0.67 % 0.67\% 0.67% vs 0.30 % 0.30\% 0.30%)。我们还在COCO val2017上评估了使用两种查询选择方案训练的检测器的精度,其中不确定性最小查询选择实现了 0.8 % 0.8\% 0.8% AP的改进( 48.7 % 48.7\% 48.7% AP vs 47.9 % 47.9\% 47.9% AP)。
Table 3. The indicators of the set of variants illustrated in Figure 3 .
【翻译】表3. 图3中所示变体集合的指标。
Table 4. Results of the ablation study on uncertainty-minimal query selection. P r o p c l s \mathbf{Prop}{c l s} Propcls and P r o p b o t h \mathbf{Prop}{b o t h} Propboth represent the proportion of classification score and both scores greater than 0 . 5 respectively.
【翻译】表4. 不确定性最小查询选择消融研究的结果。 P r o p c l s \mathbf{Prop}{c l s} Propcls和 P r o p b o t h \mathbf{Prop}{b o t h} Propboth分别表示分类分数和两个分数都大于0.5的比例。
5.4. Ablation Study on Decoder
Table 5 shows the inference latency and accuracy of each decoder layer of RT-DETR-R50 trained with different numbers of decoder layers. When the number of decoder layers is set to 6 , the RT-DETR-R50 achieves the best accuracy 53.1 % 53.1\% 53.1% AP. Furthermore, we observe that the difference in accuracy between adjacent decoder layers gradually decreases as the index of the decoder layer increases. Taking the column RTDETR-R50-Det 6 as an example, using 5 -th decoder layer for inference only loses 0.1 % 0.1\% 0.1% AP ( 53.1 % (53.1\% (53.1% AP vs 53.0 % 53.0\% 53.0% AP) in accuracy, while reducing latency by 0.5 m s 0.5\mathrm{ms} 0.5ms ( 9 . 3 ms vs 8 . 8 ms). Therefore, RT-DETR supports flexible speed tuning by adjusting the number of decoder layers without retraining, thus improving its practicality.
【翻译】表5显示了使用不同解码器层数训练的RT-DETR-R50每个解码器层的推理延迟和精度。当解码器层数设置为6时,RT-DETR-R50达到了最佳精度 53.1 % 53.1\% 53.1% AP。此外,我们观察到随着解码器层索引的增加,相邻解码器层之间的精度差异逐渐减小。以RT-DETR-R50-Det 6列为例,使用第5个解码器层进行推理仅损失 0.1 % 0.1\% 0.1% AP( 53.1 % 53.1\% 53.1% AP vs 53.0 % 53.0\% 53.0% AP)的精度,同时将延迟减少 0.5 m s 0.5\mathrm{ms} 0.5ms(9.3 ms vs 8.8 ms)。因此,RT-DETR支持通过调整解码器层数进行灵活的速度调优而无需重新训练,从而提高了其实用性。
6. Limitation and Discussion
Limitation. Although the proposed RT-DETR outperforms the state-of-the-art real-time detectors and end-to-end detectors with similar size in both speed and accuracy, it shares the same limitation as the other DETRs, i.e ., the performance on small objects is still inferior than the strong real-time detectors. According to Table 2 , RT-DETR-R50 is 0.5 % 0.5\% 0.5% AP lower than the highest A P S v a l \mathbf{AP}{S}^{v a l} APSval in the L L L model (YOLOv8-L) and RTDETR-R101 is 0.9 % 0.9\% 0.9% AP lower than the highest A P S v a l \mathbf{AP}{S}^{v a l} APSval in the X X X model (YOLOv7-X). We hope that this problem will be addressed in future work.
【翻译】局限性。尽管所提出的RT-DETR在速度和精度方面都优于最先进的实时检测器和相似规模的端到端检测器,但它与其他DETR共享相同的局限性,即在小物体上的性能仍然不如强大的实时检测器。根据表2,RT-DETR-R50比 L L L模型(YOLOv8-L)中最高的 A P S v a l \mathbf{AP}{S}^{v a l} APSval低 0.5 % 0.5\% 0.5% AP,RT-DETR-R101比 X X X模型(YOLOv7-X)中最高的 A P S v a l \mathbf{AP}{S}^{v a l} APSval低 0.9 % 0.9\% 0.9% AP。我们希望这个问题能在未来的工作中得到解决。
Table 5. Results of the ablation study on decoder. ID indicates decoder layer index. D e t k \mathbf{Det}^{k} Detk represents detector with k k k decoder layers. All results are reported on RT-DETR-R50 with 6 × 6\times 6× configuration.
【翻译】表5. 解码器消融研究的结果。ID表示解码器层索引。 D e t k \mathbf{Det}^{k} Detk表示具有 k k k个解码器层的检测器。所有结果都在使用 6 × 6\times 6×配置的RT-DETR-R50上报告。
Discussion. Existing large DETR models 3 , 6 , 32 , 41 , 44 , 46 have demonstrated impressive performance on COCO test-dev 20 leaderboard. The proposed RT-DETR at different scales preserves decoders homogeneous to other DETRs, which makes it possible to distill our lightweight detector with high accuracy pre-trained large DETR models. We believe that this is one of the advantages of RT-DETR over other real-time detectors and could be an interesting direction for future exploration.
In this work, we propose a real-time end-to-end detector, called RT-DETR, which successfully extends DETR to the real-time detection scenario and achieves state-of-the-art performance. RT-DETR includes two key enhancements: an efficient hybrid encoder that expeditiously processes multiscale features, and the uncertainty-minimal query selection that improves the quality of initial object queries. Furthermore, RT-DETR supports flexible speed tuning without retraining and eliminates the inconvenience caused by two NMS thresholds, facilitating its practical application. RTDETR, along with its model scaling strategy, broadens the technical approach to real-time object detection, offering new possibilities beyond YOLO for diverse real-time scenarios. We hope that RT-DETR can be put into practice.