MCP+GraphRAG搭建检索增强智能体
-
-
- (一)MCP+GraphRAG项目环境搭建
-
- [1.1 创建 MCP 客户端项目](#1.1 创建 MCP 客户端项目)
- [1.2 创建MCP客户端虚拟环境](#1.2 创建MCP客户端虚拟环境)
- [1.3 创建GraphRAG并构建索引(Index)](#1.3 创建GraphRAG并构建索引(Index))
- (二)创建GraphRAG服务器Server
- (三)创建GraphRAG服务器client
- (四)MCP+GraphRAG问答测试
-
(一)MCP+GraphRAG项目环境搭建
1.1 创建 MCP 客户端项目
Bash
# 创建项目目录
uv init mcp-graphrag
cd mcp-graphrag
1.2 创建MCP客户端虚拟环境
Bash
# 创建虚拟环境
uv venv
# 激活虚拟环境
source .venv/bin/activate
这里需要注意的是,相比pip,uv会自动识别当前项目主目录并创建虚拟环境。
然后即可通过add方法在虚拟环境中安装相关的库。
Bash
# 安装 MCP SDK
uv add mcp graphrag pathlib pandas
1.3 创建GraphRAG并构建索引(Index)
- 创建项目目录并进行初始化
Bash
mkdir -p ./graphrag/input
graphrag init --root ./graphrag
- 修改配置文件
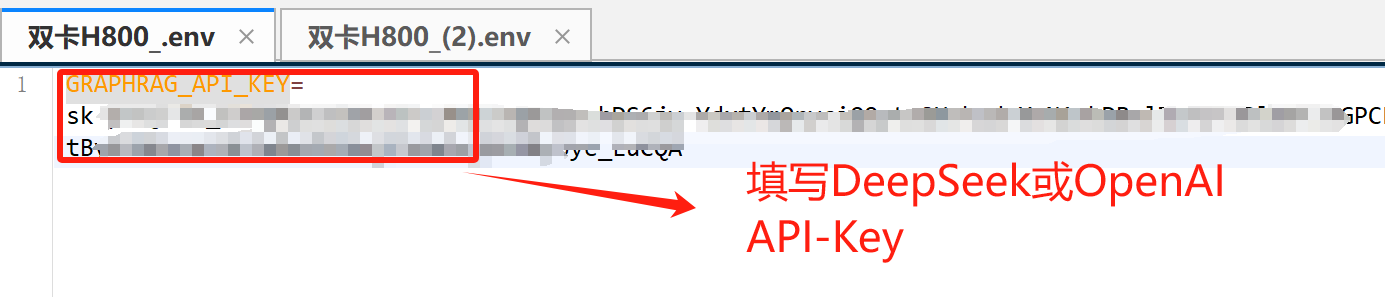
打开.env文件,填写DeepSeek API-KEY或OpenAI API-Key
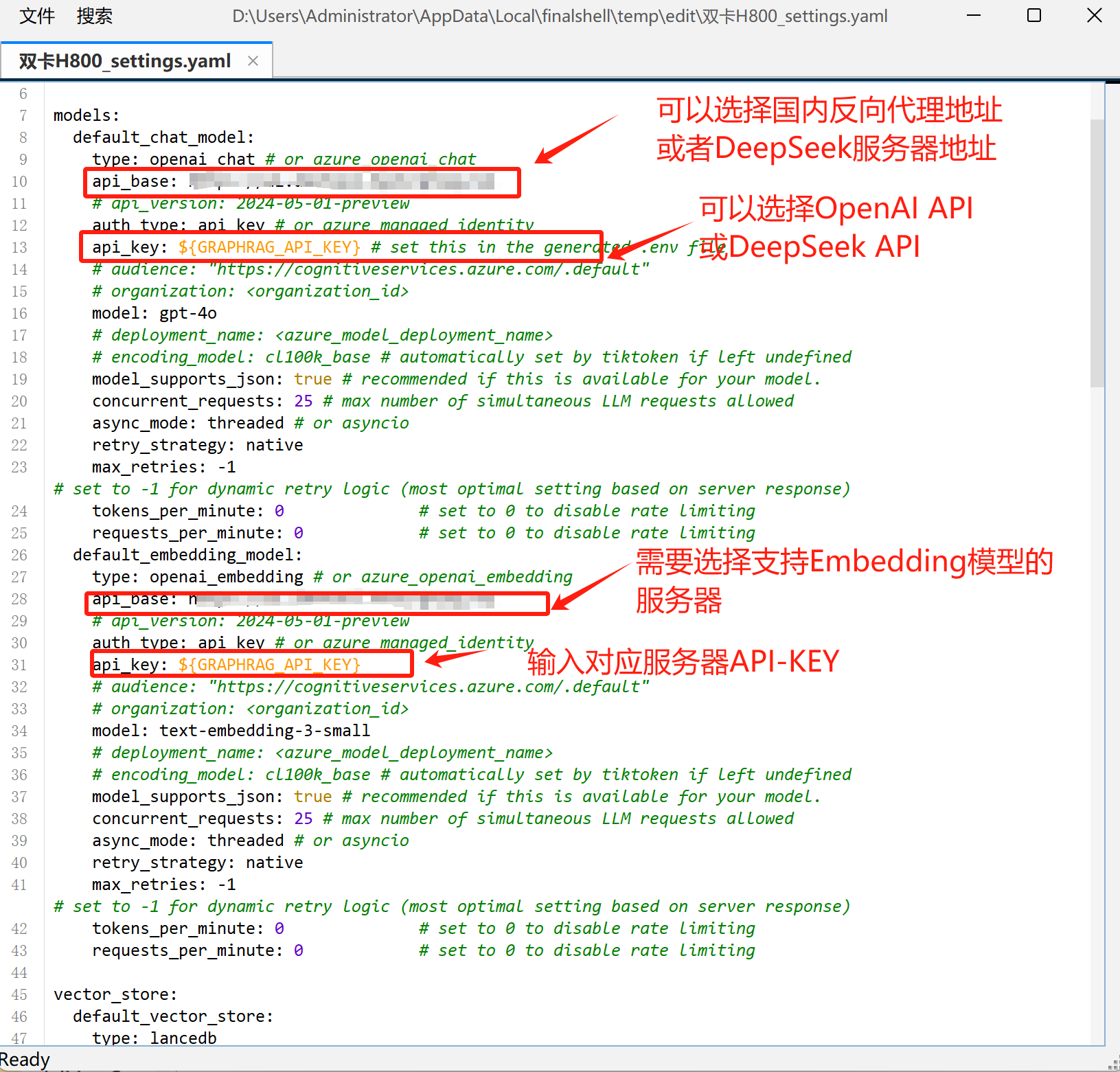
打开setting.yaml文件,填写模型名称和代理地址:
- 上传文本数据
- index过程
Bash
graphrag index --root ./graphrag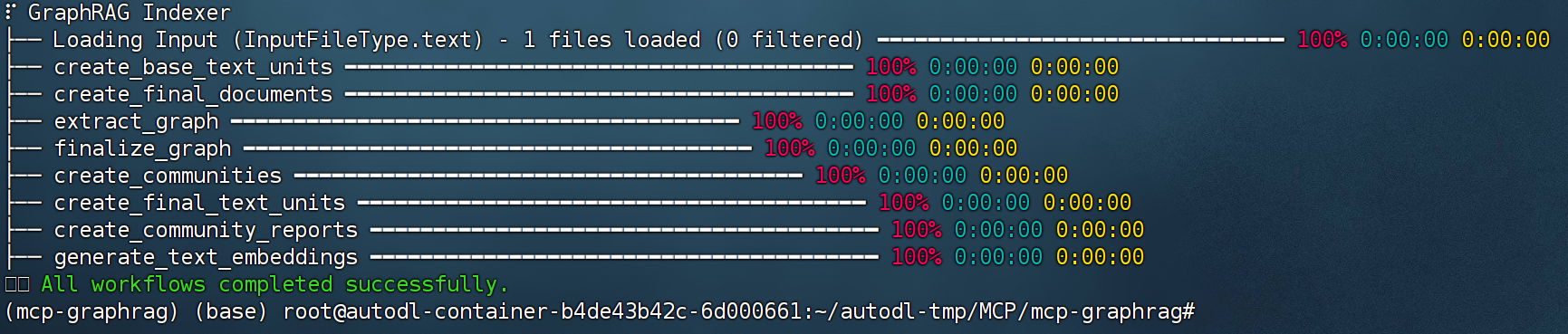
(二)创建GraphRAG服务器Server
这里需要注意,当前创建的GraphRAG Server只负责进行对某一个完成Index的知识库进行Query,更加复杂的如文件管理、实时增加检索、多文件库检索等。
这里我们在当前项目中创建一个名为rag_server.py的server,
并写入如下代码:
Python
from pathlib import Path
from pprint import pprint
import pandas as pd
import graphrag.api as api
from graphrag.config.load_config import load_config
from graphrag.index.typing.pipeline_run_result import PipelineRunResult
from typing import Any
from mcp.server.fastmcp import FastMCP
# 初始化 MCP 服务器
mcp = FastMCP("rag_ML")
USER_AGENT = "rag_ML-app/1.0"
@mcp.tool()
async def rag_ML(query: str) -> str:
"""
用于查询机器学习决策树相关信息。
:param query: 用户提出的具体问题
:return: 最终获得的答案
"""
PROJECT_DIRECTORY = "/root/autodl-tmp/MCP/mcp-graphrag/graphrag"
graphrag_config = load_config(Path(PROJECT_DIRECTORY))
# 加载实体
entities = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/entities.parquet")
# 加载社区
communities = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/communities.parquet")
# 加载社区报告
community_reports = pd.read_parquet(
f"{PROJECT_DIRECTORY}/output/community_reports.parquet"
)
# 进行全局搜索
response, context = await api.global_search(
config=graphrag_config,
entities=entities,
communities=communities,
community_reports=community_reports,
community_level=2,
dynamic_community_selection=False,
response_type="Multiple Paragraphs",
query=query,
)
return response
if __name__ == "__main__":
# 以标准 I/O 方式运行 MCP 服务器
mcp.run(transport='stdio')代码解释如下:
-
导入必要的模块和库:
Path和pprint:用于路径操作和美化打印输出。pandas:用于数据处理,特别是读取 Parquet 格式的数据文件。graphrag.api和相关配置模块:用于加载配置和调用 GraphRAG 的 API。FastMCP:MCP 协议的快速实现,用于创建 MCP 服务器。
-
初始化 MCP 服务器:
mcp = FastMCP("rag_ML"):创建一个名为rag_ML的 MCP 服务器实例。USER_AGENT = "rag_ML-app/1.0":定义用户代理字符串,可能用于标识客户端应用程序的版本信息。
-
定义工具函数 rag_ML**:**
-
使用装饰器
@mcp.tool()将函数注册为 MCP 工具,使其可被客户端调用。 -
函数为异步函数,接受一个字符串类型的
query参数,表示用户的查询。 -
函数内部执行以下操作:
-
加载 GraphRAG 配置:
PROJECT_DIRECTORY:定义项目目录路径。graphrag_config = load_config(Path(PROJECT_DIRECTORY)):加载 GraphRAG 的配置文件。
-
加载数据文件:
- 使用
pandas的read_parquet方法分别加载实体、社区和社区报告的 Parquet 文件。
- 使用
-
调用
Plaintextapi.global_search-
方法进行全局搜索:
- 传入配置、实体、社区和社区报告等参数。
- 设置
community_level=2和dynamic_community_selection=False,用于控制社区层级和是否动态选择社区。 - 设置
response_type="Multiple Paragraphs",指定响应类型为多段落文本。
-
返回搜索结果
response。
-
-
-
运行 MCP 服务器:
- 在主程序中,调用
mcp.run(transport='stdio')以标准输入输出(stdio)的方式运行 MCP 服务器,使其能够接收和响应客户端的请求。
- 在主程序中,调用
(三)创建GraphRAG服务器client
接下来继续创建客户端,在项目主目录下创建一个名为client.py的客户端,
并写入如下代码:
Python
import asyncio
import os
import json
from typing import Optional
from contextlib import AsyncExitStack
from openai import OpenAI
from dotenv import load_dotenv
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
# 加载 .env 文件,确保 API Key 受到保护
load_dotenv()
class MCPClient:
def __init__(self):
"""初始化 MCP 客户端"""
self.exit_stack = AsyncExitStack()
self.openai_api_key = os.getenv("OPENAI_API_KEY") # 读取 OpenAI API Key
self.base_url = os.getenv("BASE_URL") # 读取 BASE YRL
self.model = os.getenv("MODEL") # 读取 model
if not self.openai_api_key:
raise ValueError("❌ 未找到 OpenAI API Key,请在 .env 文件中设置 OPENAI_API_KEY")
self.client = OpenAI(api_key=self.openai_api_key, base_url=self.base_url) # 创建OpenAI client
self.session: Optional[ClientSession] = None
async def transform_json(self, json2_data):
"""
将Claude Function calling参数格式转换为OpenAI Function calling参数格式,多余字段会被直接删除。
:param json2_data: 一个可被解释为列表的 Python 对象(或已解析的 JSON 数据)
:return: 转换后的新列表
"""
result = []
for item in json2_data:
# 确保有 "type" 和 "function" 两个关键字段
if not isinstance(item, dict) or "type" not in item or "function" not in item:
continue
old_func = item["function"]
# 确保 function 下有我们需要的关键子字段
if not isinstance(old_func, dict) or "name" not in old_func or "description" not in old_func:
continue
# 处理新 function 字段
new_func = {
"name": old_func["name"],
"description": old_func["description"],
"parameters": {}
}
# 读取 input_schema 并转成 parameters
if "input_schema" in old_func and isinstance(old_func["input_schema"], dict):
old_schema = old_func["input_schema"]
# 新的 parameters 保留 type, properties, required 这三个字段
new_func["parameters"]["type"] = old_schema.get("type", "object")
new_func["parameters"]["properties"] = old_schema.get("properties", {})
new_func["parameters"]["required"] = old_schema.get("required", [])
new_item = {
"type": item["type"],
"function": new_func
}
result.append(new_item)
return result
async def connect_to_server(self, server_script_path: str):
"""连接到 MCP 服务器并列出可用工具"""
is_python = server_script_path.endswith('.py')
is_js = server_script_path.endswith('.js')
if not (is_python or is_js):
raise ValueError("服务器脚本必须是 .py 或 .js 文件")
command = "python" if is_python else "node"
server_params = StdioServerParameters(
command=command,
args=[server_script_path],
env=None
)
# 启动 MCP 服务器并建立通信
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
# 列出 MCP 服务器上的工具
response = await self.session.list_tools()
tools = response.tools
print("\n已连接到服务器,支持以下工具:", [tool.name for tool in tools])
async def process_query(self, query: str) -> str:
"""
使用大模型处理查询并调用可用的 MCP 工具 (Function Calling)
"""
messages = [{"role": "user", "content": query}]
response = await self.session.list_tools()
available_tools = [{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
}
} for tool in response.tools]
# print(available_tools)
# 进行参数格式转化
available_tools = await self.transform_json(available_tools)
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
tools=available_tools
)
# 处理返回的内容
content = response.choices[0]
if content.finish_reason == "tool_calls":
# 如何是需要使用工具,就解析工具
tool_call = content.message.tool_calls[0]
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
# 执行工具
result = await self.session.call_tool(tool_name, tool_args)
print(f"\n\n[Calling tool {tool_name} with args {tool_args}]\n\n")
# 将模型返回的调用哪个工具数据和工具执行完成后的数据都存入messages中
messages.append(content.message.model_dump())
messages.append({
"role": "tool",
"content": result.content[0].text,
"tool_call_id": tool_call.id,
})
# 将上面的结果再返回给大模型用于生产最终的结果
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
)
return response.choices[0].message.content
return content.message.content
async def chat_loop(self):
"""运行交互式聊天循环"""
print("\n🤖 MCP 客户端已启动!输入 'quit' 退出")
while True:
try:
query = input("\n你: ").strip()
if query.lower() == 'quit':
break
response = await self.process_query(query) # 发送用户输入到 OpenAI API
print(f"\n🤖 OpenAI: {response}")
except Exception as e:
print(f"\n⚠️ 发生错误: {str(e)}")
async def cleanup(self):
"""清理资源"""
await self.exit_stack.aclose()
async def main():
if len(sys.argv) < 2:
print("Usage: python client.py <path_to_server_script>")
sys.exit(1)
client = MCPClient()
try:
await client.connect_to_server(sys.argv[1])
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
import sys
asyncio.run(main())这段代码实现了一个 MCP 客户端,用于连接 MCP 服务器,并利用 OpenAI 的 API 进行 Function Calling(函数调用)。该客户端能够与 MCP 服务器交互,列出可用工具,并根据用户输入选择适当的工具调用。
(1)初始化
AsyncExitStack()处理多个异步上下文(如 MCP 连接)。- 读取 .env配置:
OPENAI_API_KEYBASE_URL(可选,用于自定义 API 代理)MODEL(指定 OpenAI 使用的模型)
self.client = OpenAI(...)创建 OpenAI API 客户端。
(2)转换 API 格式 (transform_json)
- OpenAI 和 Claude API 的 Function Calling 格式不同。
- 该函数将 Claude 的
input_schema转换为 OpenAI 兼容格式。
(3)连接 MCP 服务器
- 连接 MCP 服务器,支持 Python 或 JavaScript 服务器脚本。
stdio_client(server_params)通过stdio进行通信。await self.session.list_tools()列出 MCP 服务器上可用的工具。
(4)处理用户查询 (process_query)
- 获取 MCP 服务器上可用的工具 (
list_tools)。 - 让 OpenAI 选择是否需要调用 MCP 服务器上的工具 (
tool_calls)。 - 若需要工具调用:
- 解析
tool_calls call_tool(tool_name, tool_args)调用 MCP 服务器上的工具- 再次向 OpenAI 提交新信息,获取最终答案
- 解析
(5)交互式聊天 (chat_loop)
- 允许用户输入查询,自动选择 MCP 工具或直接回答。
- 输入
quit退出聊天。
然后创建配置文件.env:
并手动输入
Bash
BASE_URL=
MODEL=
OPENAI_API_KEY=
(四)MCP+GraphRAG问答测试
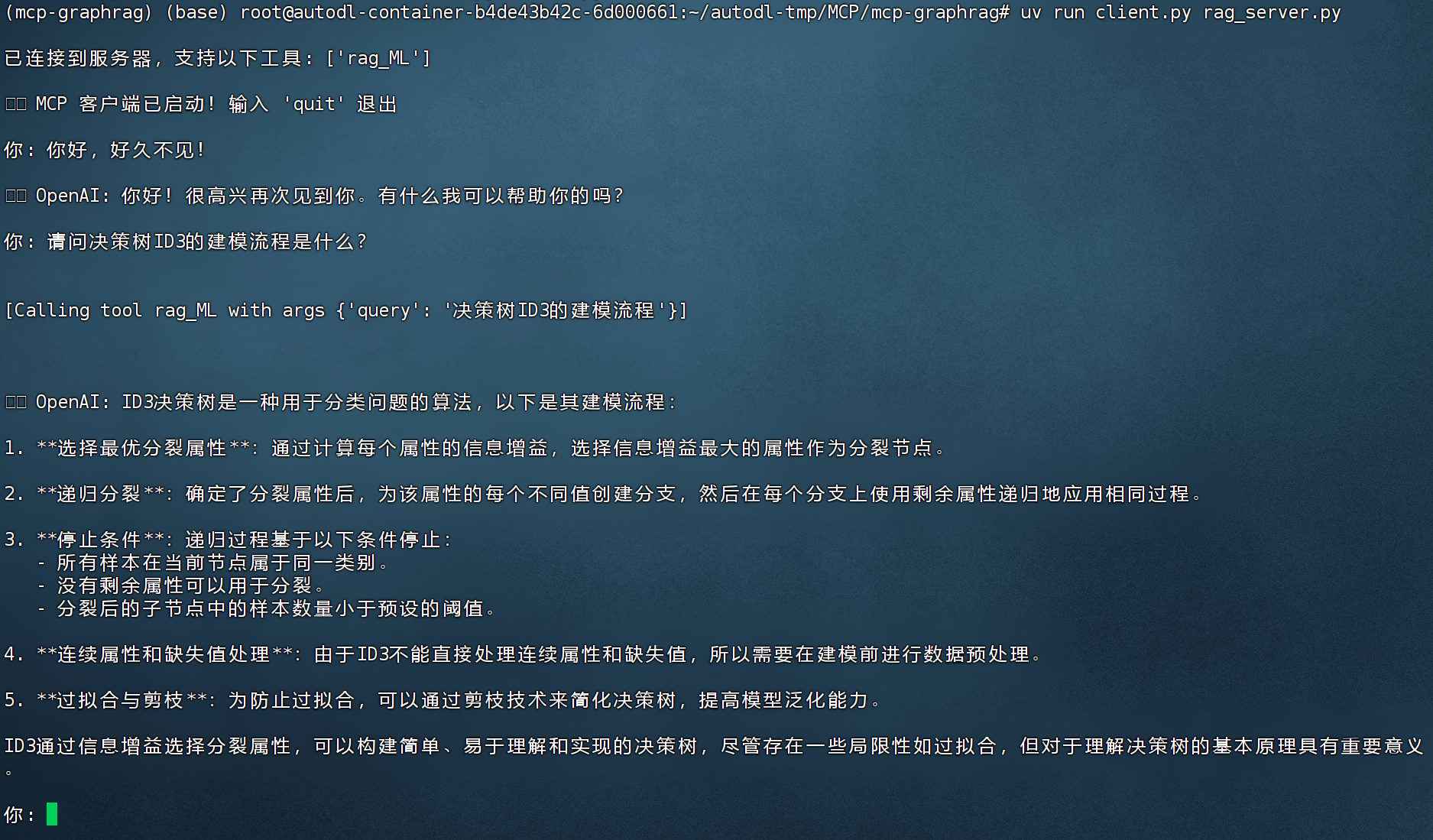
最后即可开始进行问答测试,在命令行中输入如下命令即可启动问答:
Python
uv run client.py rag_server.py问答效果如图所示: