大家好,我是java1234_小锋老师,最近写了一套【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts)视频教程,持续更新中,计划月底更新完,感谢支持。今天讲解架构搭建
视频在线地址:
2026版【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts+爬虫) 视频教程 (火爆连载更新中..)_哔哩哔哩_bilibili
课程简介:
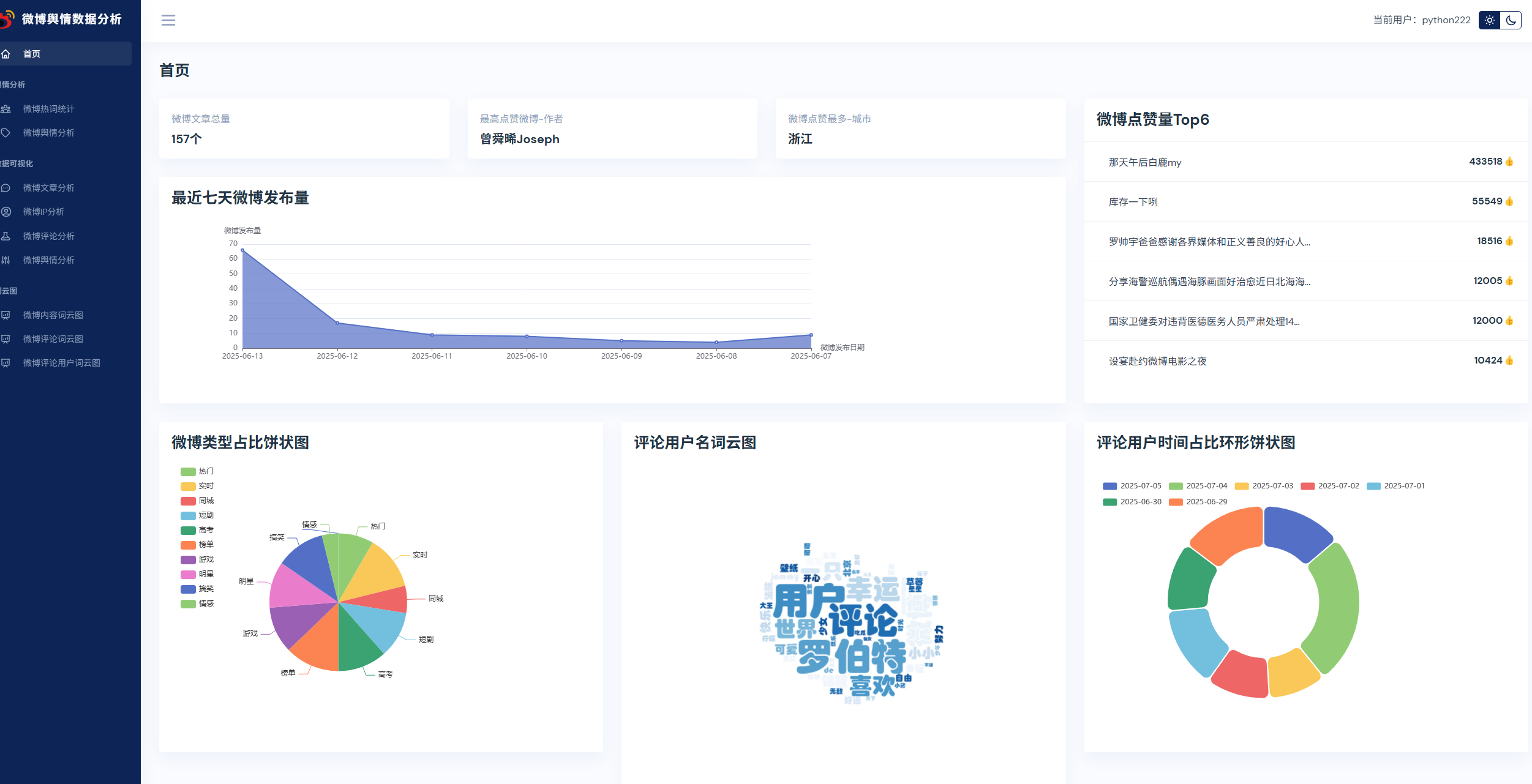
本课程采用主流的Python技术栈实现,Mysql8数据库,Flask后端,Pandas数据分析,前端可视化图表采用echarts,以及requests库,snowNLP进行情感分析,词频统计,包括大量的数据统计及分析技巧。
实现了,用户登录,注册,爬取微博帖子和评论信息,进行了热词统计以及舆情分析,以及基于echarts实现了数据可视化,包括微博文章分析,微博IP分析,微博评论分析,微博舆情分析。最后也基于wordcloud库实现了词云图,包括微博内容词云图,微博评论词云图,微博评论用户词云图等功能。
微博类别信息爬取
再爬取微博之前,我们先把所有微博类别爬取,再遍历每个类别,爬取微博内容。
访问微博首页:Sina Visitor System 打开谷歌开发者工具或者F12直接快捷打开
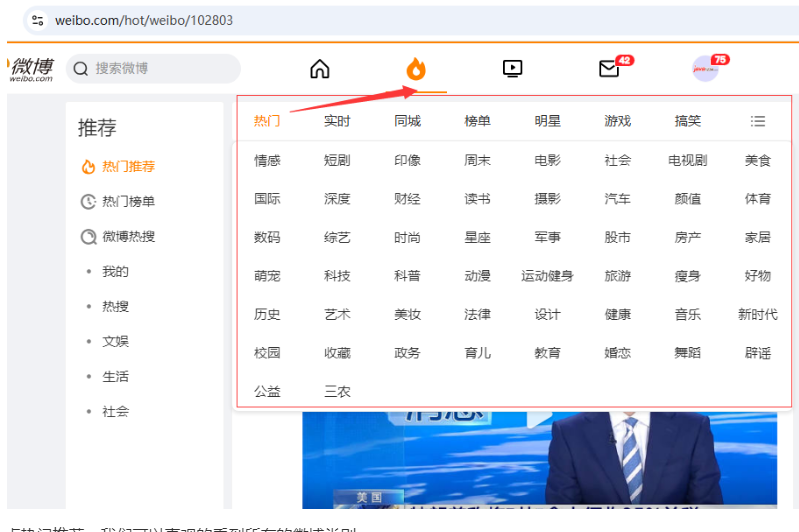
点热门推荐,我们可以直观的看到所有的微博类别。
通过分析,我们找到微博类别的请求接口:https://weibo.com/ajax/feed/allGroups
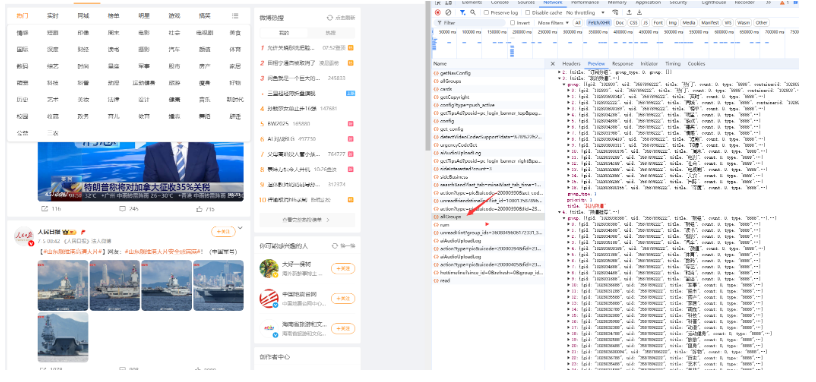
继续分析:接口返回数据的的groups下的第3和第4个下标值正好是所有的微博数据。
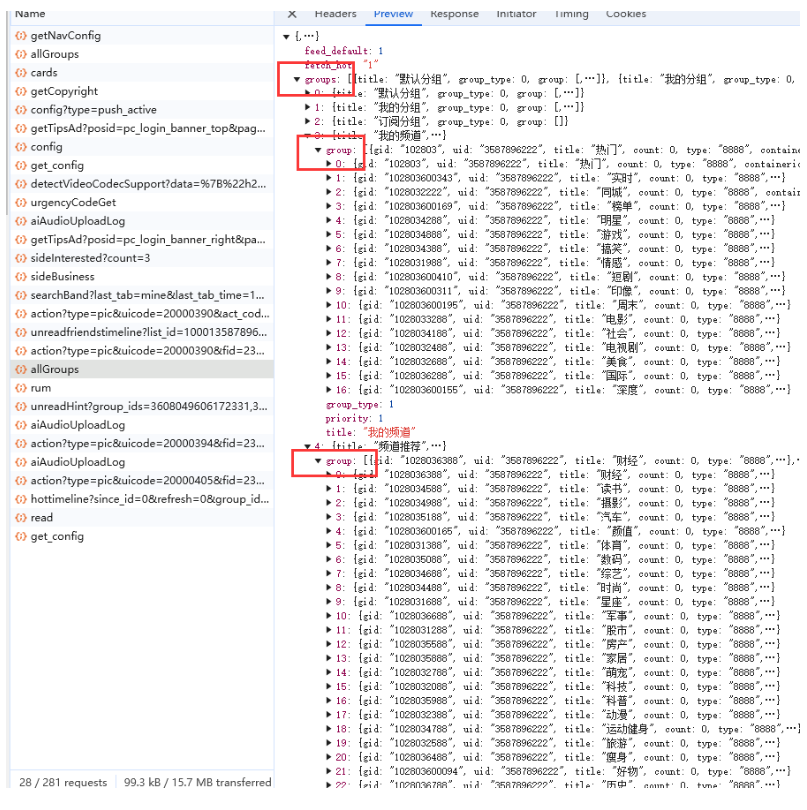
实现代码:
python
"""
https://weibo.com/ajax/feed/allGroups
微博类别 爬虫代码 以及存到csv文件中
"""
import csv
import os.path
import numpy as np
import requests
def init_csv():
"""
初始化操作,判断csv文件是否存在,不能存在就创建一个
:return:
"""
if not os.path.exists('arcType_data.csv'): # 不存在就创建一个
with open('arcType_data.csv', 'w', encoding='utf8',
newline='') as file: # newline=''参数,参数用于控制换行符的行为 这表示禁用自动换行符转换,即写入文件时使用原始的换行符(例如\r\n或\n)。这对于处理CSV文件时避免不必要的空行特别有用。
writer = csv.writer(file)
writer.writerow([
'类别标题(title)',
'分组id(gid)',
'分类id(containerid)'
])
def getJsonHtml(url, params):
"""
请求获取Html内容 json数据
:param url:
:param params:
:return:
"""
headers = {
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
'cookie': "UOR=www.baidu.com,s.weibo.com,www.baidu.com; SINAGLOBAL=147269028916.96313.1738405722917; SCF=Aq_smbP0Qulm3aIQiWHRj0MVjLlLvMzPjh08C1UOgzZGKmgtkj3RlIKkPpPunA-Yp4Vs3PxaE2Mnw4EfY-zo22k.; ULV=1746148684228:3:1:1:750370364305.8235.1746148684180:1743395262982; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WWdhwhTipHbo3gGv6wzaRcu5JpX5KMhUgL.Foef1hMR1KqEeoz2dJLoI08ZqP9yi--NiKLsi-2fi--Ri-8siKnci--fiKnRiKnci--Xi-iWi-8Fi--Ni-i2iK.p; XSRF-TOKEN=jkBbdfx8ioL49wGmuLw8ZTv2; ALF=1754794282; SUB=_2A25FdAx5DeRhGeVL41UZ-SjOyT6IHXVmCAGxrDV8PUJbkNAbLWfskW1NTBTNHVQQjZ8TTBpAQ68hUItVd4KUD_CC; WBPSESS=_IA_wwSTTkx7cB4s0X9svEMSaQHgjmYl9nytbvfrAcd7Iosa-3IBWF4ACq_6aV-rM8H92uAEfJAtiOQKdY2Gha_-gW_mgEBLLJLDTNTrl4COyaKsVhMD_fKgQcz8yS4cNe68un-DHcy9a6K983O71w=="
}
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
return response.json()
else:
return None
def writeToCsv(row):
"""
写入csv操作 a操作 尾部追加 写入操作
:param row:
:return:
"""
with open('arcType_data.csv', 'a', encoding='utf8',
newline='') as file:
writer = csv.writer(file)
writer.writerow(row)
def parseJson(json):
"""
解析Json数据
:param json:
:return:
"""
arcTypeList = np.append(json['groups'][3]['group'], json['groups'][4]['group'])
print(arcTypeList)
for arcType in arcTypeList:
arcType_title = arcType['title']
gid = arcType['gid']
containerid = arcType['containerid']
writeToCsv([arcType_title, gid, containerid])
def start():
init_csv()
url = 'https://weibo.com/ajax/feed/allGroups'
jsonHtml = getJsonHtml(url, {})
print(jsonHtml)
parseJson(jsonHtml)
if __name__ == '__main__':
start()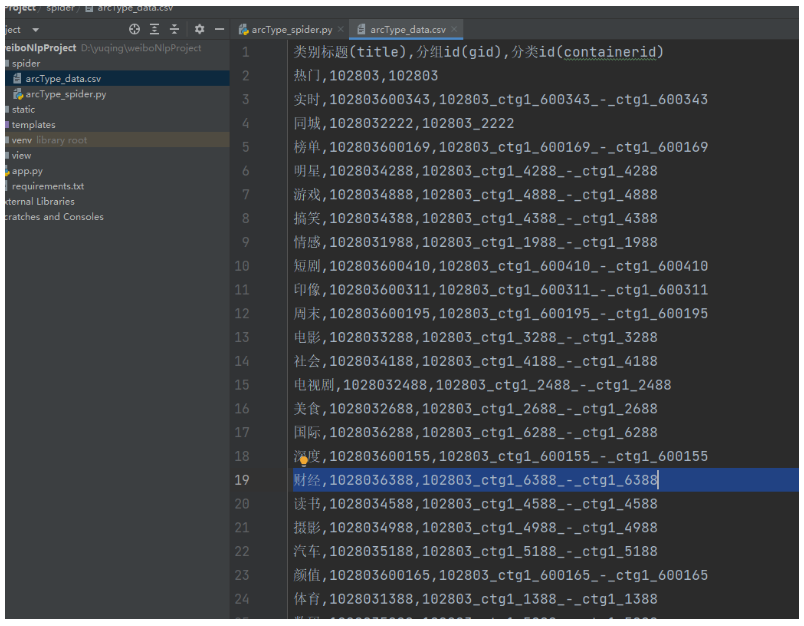
运行后,生成srcType_data.csv文件,里面数据也无误。