一、Doc2Vec
Doc2Vec 是一种用于生成句子、段落或文档向量表示的模型,由 Google 在 2014 年提出,基于 Word2Vec 的思想扩展而来。它可以捕捉文档的语义信息,将整个文档表示为固定长度的向量,适用于文本分类、主题建模和相似性计算等任务。
与 Word2Vec 专注于生成单词的向量表示不同,Doc2Vec 的目标是生成文档级别的向量表示。它通过在训练过程中引入文档标签作为额外的输入,学习文档和单词之间的关系。(Doc2Vec在训练过程中,除了会生成文档向量,也会生成词向量)
应用场景
-
文档相似度计算
通过文档向量,可以分析出文档A和文档B之间的相似度较低,而文档A和文档C的相似度较高。
-
文档聚类
通过将文档向量作为特征,可以将语义相似的文档聚集在一起。这样,文档可以按主题进行分类,而无需手动标注每个文档的类别。
-
文本分类
例如有一组电子邮件,通过Doc2Vec将每封邮件转换为文档向量。并预测邮件是否为垃圾邮件。
-
信息检索与推荐系统
例如在推荐系统中,用户的历史行为(如点击过的文档)可以被转换为文档向量,之后可以给推荐给用户相似的文档。
二、训练过程
Doc2Vec本身就是Word2Vec的开发者研发的,所以它的训练方法非常类似于 Word2Vec,但是有一些额外的关键因素,使它能够训练出文档级别的向量表示。
和Word2vec一样,Doc2vec也有两种训练方式:一种是DBOW模式,类似于Word2vec中的Skip-gram模型;另一种是DM模式,类似于Word2vec中的CBOW模型。

DBOW 模式类似于 Skip-gram 模型。它不依赖于上下文窗口内的具体单词,而是直接使用文档向量来预测上下文单词。
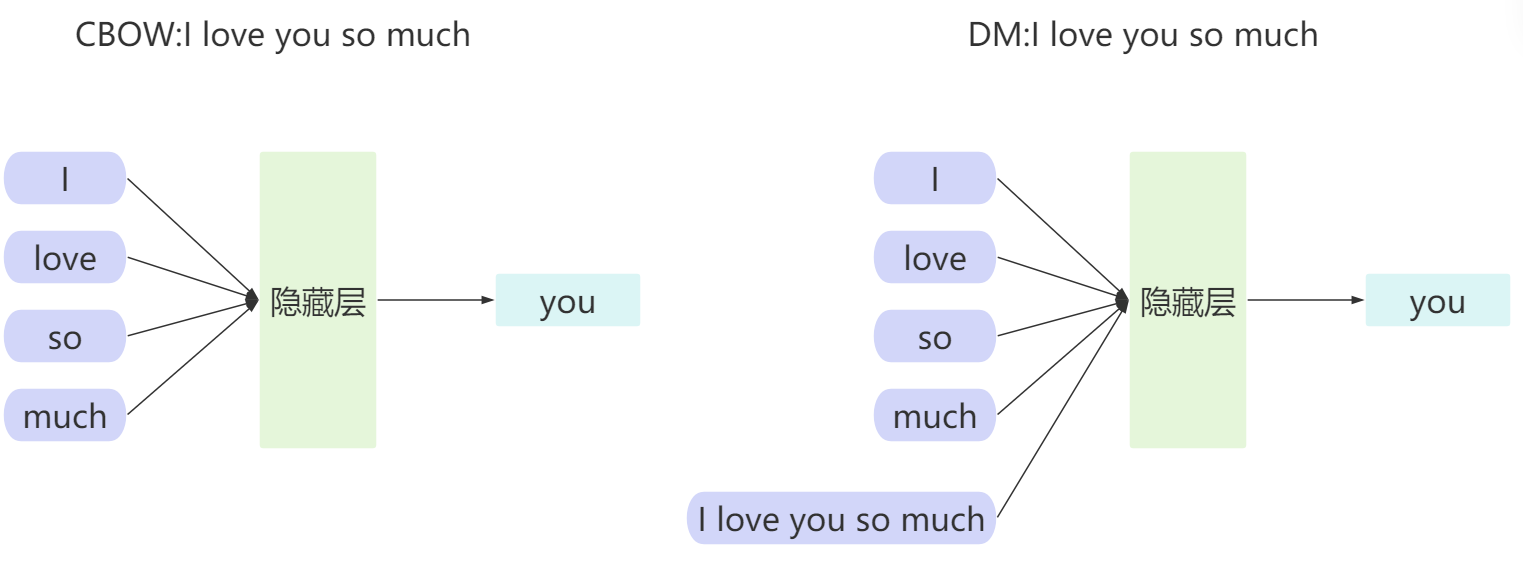
在 Doc2Vec 的 DM 模式 中,预测的是中心词,而不是整个句子。文档向量作为上下文的一部分,与其他上下文单词共同作用,帮助模型在预测目标单词时捕捉文档的全局语义信息。
一般来说,DM模式适用于需要保留上下文关系的任务,而DBOW模式适用于更关注文档的整体信息而非顺序的任务。
三、案例
python
pip install jieba=0.42.1
pip install gensim==4.3.1
python
# 导入所需库
import jieba # 中文分词工具
import re # 正则表达式库
from gensim.models.doc2vec import Doc2Vec, TaggedDocument # Doc2Vec模型及相关数据结构
# 读取文本文件并进行预处理
f = open("sanguo.txt", 'r', encoding='utf-8') # 以UTF-8编码打开文件
lines = [] # 存储处理后的文本行
# 文本预处理流程
for line in f: # 逐行处理文本
# 使用jieba进行精确模式分词
temp = jieba.lcut(line)
# 初始化存储过滤后词语的列表
words = []
# 过滤每个词语中的标点符号和特殊字符
for word in temp:
# 使用正则表达式去除标点符号(匹配中文/英文标点)
cleaned_word = re.sub("[\s+\.\!\/_,$%^*(+\"\'""《》]+|[+------!,。?、~@#¥%......&*():;']+", "", word)
# 只保留非空词语
if len(cleaned_word) > 0:
words.append(cleaned_word)
# 过滤空行
if len(words) > 0:
lines.append(words)
# 打印前5行分词结果(用于检查预处理效果)
print("前5行分词结果预览:")
print(lines[0:5])
# 将分词结果转换为Doc2Vec需要的TaggedDocument格式
# 每个文档包含:词语列表 + 唯一文档标签(这里用行号作为标签)
documents = [TaggedDocument(words=doc, tags=[str(i)]) for i, doc in enumerate(lines)]
print("\n前5个TaggedDocument示例:")
print(documents[0:5])
# 初始化Doc2Vec模型
model = Doc2Vec(
vector_size=20, # 向量维度(通常建议100-300,这里设为20演示)
window=2, # 上下文窗口大小(前后各考虑2个词)
min_count=3, # 词语最低出现频次(低于3次被忽略)
workers=4, # 并行线程数(提高训练速度)
dm=1, # 训练算法:1=PV-DM(分布式记忆模型), 0=PV-DBOW
epochs=40 # 训练迭代次数(通常建议10-50次)
)
# 构建词汇表(统计词频并建立词汇索引)
model.build_vocab(documents) # 必须先构建词汇表才能训练
# 训练模型
model.train(
documents, # 训练数据
total_examples=model.corpus_count, # 总文档数(自动从build_vocab获取)
epochs=model.epochs # 训练轮次
)
# 测试词向量效果
print("\n'荆州'的词向量(20维):")
print(model.wv.get_vector("荆州"))
# 查找与"荆州"最相似的词语
print("\n与'荆州'语义最接近的前20个词语:")
print(model.wv.most_similar("荆州", topn=20))
# 测试文档向量效果
sample_doc_id = 2 # 选择第3个文档(索引从0开始)
print(f"\n文档{sample_doc_id}的原始内容:")
print(documents[sample_doc_id])
print(f"\n文档{sample_doc_id}的向量表示:")
print(model.dv[sample_doc_id]) # 获取文档向量
# 查找相似文档
print(f"\n与文档{sample_doc_id}最相似的前5个文档:")
similar_docs = model.dv.most_similar(str(sample_doc_id), topn=5)
for doc_id, similarity in similar_docs:
print(f"\n相似度 {similarity:.4f} - 文档{doc_id}:")
print(documents[int(doc_id)]) # 打印相似文档内容
python
[['三国演义', '上卷'], ['罗贯中'], ['滚滚', '长江', '东', '逝水', '浪花', '淘尽', '英雄', '是非成败', '转头', '空', '青山', '依旧', '在', '几度', '夕阳红'], ['白发', '渔樵', '江渚上', '惯看', '秋月春风', '一壶', '浊酒', '喜相逢', '古今', '多少', '事', '都', '付笑谈', '中'], ['--', '调寄', '临江仙']]
[TaggedDocument(words=['三国演义', '上卷'], tags=['0']), TaggedDocument(words=['罗贯中'], tags=['1']), TaggedDocument(words=['滚滚', '长江', '东', '逝水', '浪花', '淘尽', '英雄', '是非成败', '转头', '空', '青山', '依旧', '在', '几度', '夕阳红'], tags=['2']), TaggedDocument(words=['白发', '渔樵', '江渚上', '惯看', '秋月春风', '一壶', '浊酒', '喜相逢', '古今', '多少', '事', '都', '付笑谈', '中'], tags=['3']), TaggedDocument(words=['--', '调寄', '临江仙'], tags=['4'])]
荆州的词向量:
[ 0.8629547 -0.05743579 0.9914075 2.024322 -1.6996585 1.4705372
1.7025656 2.4926486 -0.06118374 2.002057 -2.8577862 1.9063181
-0.03972064 1.5808716 0.82415694 -0.11870474 2.2919378 1.361215
1.006521 -2.4119568 ]
和荆州相关性最高的前20个词语:
[('徐州', 0.8830070495605469), ('汝南', 0.8467934727668762), ('江东', 0.833061933517456), ('成都', 0.8281331658363342), ('武陵', 0.821506917476654), ('河北', 0.8197699189186096), ('新野', 0.8161933422088623), ('西川', 0.8026701807975769), ('襄阳', 0.797217607498169), ('雒城', 0.7765358090400696), ('樊城', 0.7602173089981079), ('冀州', 0.7592052817344666), ('淮南', 0.757359504699707), ('许都', 0.7558230757713318), ('田氏', 0.7556059956550598), ('剑阁', 0.755517303943634), ('江夏', 0.7547146677970886), ('袁术', 0.752963662147522), ('收川', 0.7516705989837646), ('益州', 0.7505261898040771)]
TaggedDocument<['滚滚', '长江', '东', '逝水', '浪花', '淘尽', '英雄', '是非成败', '转头', '空', '青山', '依旧', '在', '几度', '夕阳红'], ['2']>
[ 0.05974183 0.05577988 0.17304933 0.36974317 -0.50563765 0.7087325
0.2129826 0.20187075 -0.15073334 0.8833254 0.13402134 0.34105307
0.18518855 0.0779961 0.4554922 0.2845837 0.26942512 -0.4634803
-0.16767043 0.2252312 ]
与原始文档最接近的段落:
文档 300 的相似度: 0.8686124086380005
文档 300 内容:TaggedDocument<['是', '提剑挥', '鼓', '发命', '东夏', '收罗', '英雄', '弃瑕取用', '故遂', '与'], ['300']>
文档 316 的相似度: 0.8642513155937195
文档 316 内容:TaggedDocument<['法', '乱纪', '坐领', '三台', '专制', '朝政', '爵赏', '由心', '弄戮', '在', '口', '所'], ['316']>
文档 328 的相似度: 0.8484731912612915
文档 328 内容:TaggedDocument<['蹊', '坑阱', '塞路', '举手', '挂', '网罗', '动足触', '机陷', '是', '以', '兖', '豫'], ['328']>
文档 321 的相似度: 0.8159988522529602
文档 321 内容:TaggedDocument<['议', '郎赵彦', '忠谏', '直言', '义有', '可纳', '是', '以', '圣朝', '含', '听', '改容'], ['321']>
文档 329 的相似度: 0.8072118759155273
文档 329 内容:TaggedDocument<['有', '无聊', '之民', '帝都', '有吁', '嗟', '之怨', '历观', '载籍', '无道', '之臣', '贪'], ['329']>