论文信息
论文题目:On the design fundamentals of diffusion models: A survey(扩散模型的设计基础综述)
期刊:Pattern Recognition
摘要:扩散模型是一种学习模式学习系统,它从数据分布中建模和抽样,具有三个功能组件,即正向过程、反向过程和抽样过程。扩散模型的组成部分已经引起了广泛的关注,在通常的实践中考虑了许多设计因素。现有的审查主要集中在高层次的解决方案上,较少涉及组件的设计基础。本研究旨在通过在扩散模型的每个功能组成部分中提供一个全面和连贯的开创性可设计因素的审查来解决这一差距。这为扩散模型提供了一个更细粒度的视角,有利于未来对单个组件的分析、不同目的的设计因素和扩散模型的实现进行研究。
扩散模型设计基础深度解析:从三大组件到未来趋势
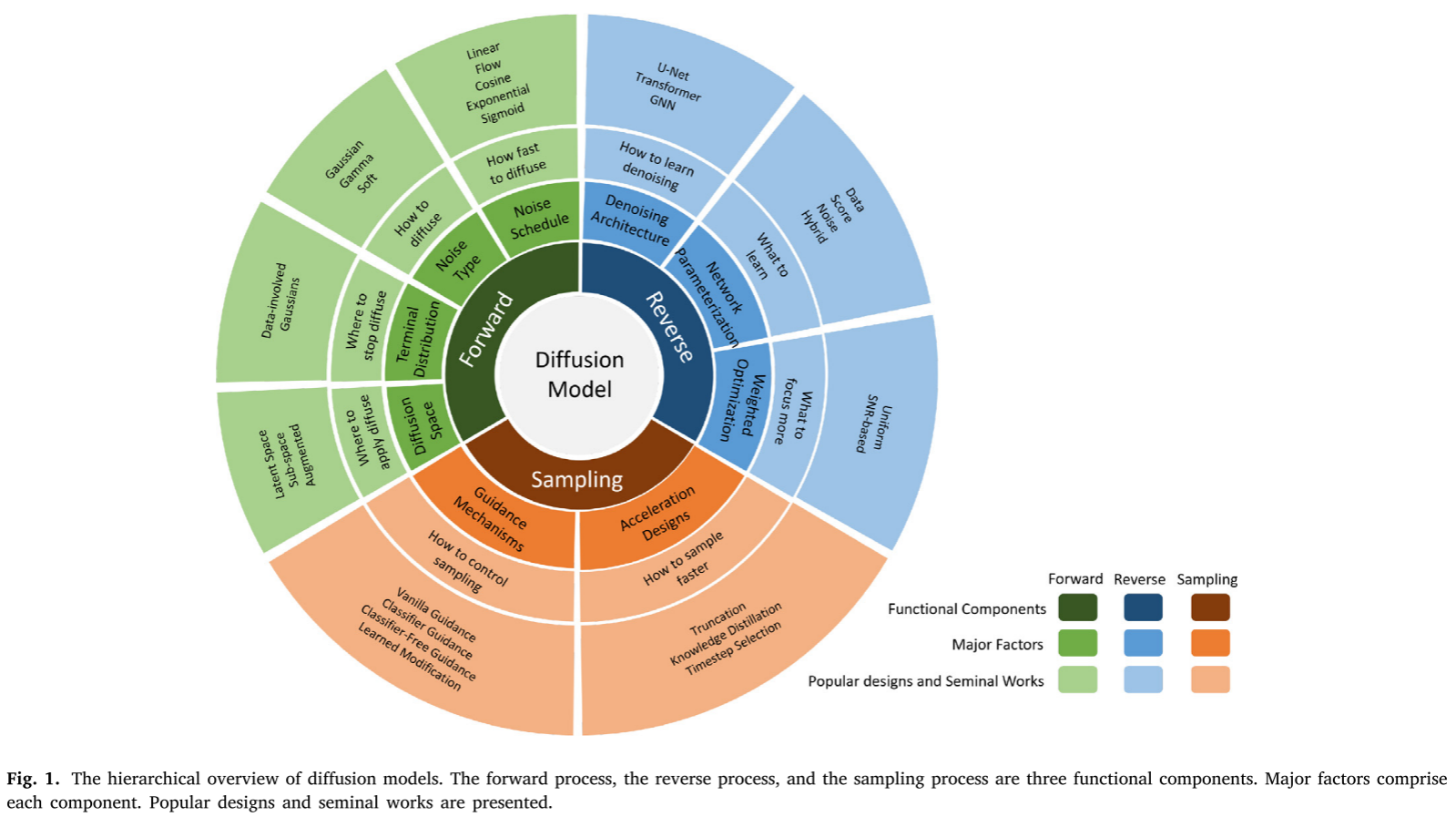
扩散模型作为当前最炙手可热的生成式人工智能技术,已经在图像生成、文本到图像合成、视频创作等领域展现出了惊人的能力。从Stable Diffusion到DALL-E,从Midjourney到Sora,这些令人瞩目的应用背后都离不开扩散模型的核心技术。然而,对于大多数人来说,扩散模型仍然是一个"黑盒子"。最近,来自Durham University和Birmingham University的研究团队发表了一篇重要综述论文《On the design fundamentals of diffusion models: A survey》,为我们系统性地解析了扩散模型的设计基础。
为什么需要这样一篇综述?
目前关于扩散模型的综述文章大多聚焦于特定应用领域,比如自然语言处理、计算机视觉、医学分析等,或者关注特定的技术问题。这些综述虽然很有价值,但往往缺乏对扩散模型设计基础的系统性阐述。
这篇论文采用了一种独特的视角:将扩散模型视为一个学习系统,并从系统化的角度分析其核心组件。这种approach有几个显著优势:
- 层次化理解:提供了从整体到细节的完整视角
- 实用导向:为研究者和工程师提供了直接可用的设计指导
- 基础扎实:专注于可迁移的核心设计原则,而非特定应用
扩散模型的三大功能组件
1. 前向过程(Forward Process):数据到噪声的艺术
前向过程是扩散模型的起点,其核心思想是逐步向原始数据添加噪声,直到数据变成纯噪声。这个看似简单的过程实际上包含了四个关键设计要素:
噪声调度(Noise Schedule) 噪声调度决定了在每个时间步添加多少噪声。这就像烹饪中的火候控制------太快会"煮过头",太慢则效率低下。论文总结了几种主要的调度策略:
- 线性调度:最直观,噪声线性增加
- 余弦调度:更平滑的过渡,在实践中表现更好
- 指数调度:用于更快的扰动
- sigmoid调度:提供了更好的控制性
噪声类型(Noise Type) 不是所有噪声都是相同的。论文深入分析了几种噪声类型:
- 各向同性高斯噪声:最常用,数学性质良好
- 伽马分布噪声:提供更多自由度
- 软损坏:包括高斯模糊、遮罩等操作
选择合适的噪声类型对模型性能至关重要。各向同性高斯噪声虽然通用,但可能忽略数据结构的先验知识;而软损坏则能更好地利用已知的扰动模式。
终端分布(Terminal Distribution) 前向过程的终点是什么?理想情况下,我们希望达到零信噪比(SNR),即完全的噪声。但实际中,这个假设可能不成立,导致训练和推理的不匹配。
表示空间(Representation Space) 数据在什么空间中被处理?这个选择影响计算效率和模型表现:
- 潜在空间:如Latent Diffusion Models,在压缩后的低维空间中操作
- 子空间方法:将不同部分分别处理
- 增强空间:引入中间变量扩展原始空间
2. 反向过程(Reverse Process):从噪声重建数据的智慧
如果说前向过程是"破坏"的艺术,那么反向过程就是"重建"的科学。这个过程训练一个神经网络来逐步去除噪声,是整个扩散模型的核心。
网络架构的演进 论文详细分析了三种主流架构:
- U-Net架构:扩散模型的经典选择,其编码器-解码器结构和跳跃连接非常适合去噪任务
- Transformer架构:近年来的新宠,具有更好的可扩展性和全局依赖建模能力
- 图神经网络(GNN):当数据具有图结构时的自然选择
每种架构都有其优势:U-Net在图像任务上表现稳定;Transformer在可扩展性和多模态融合方面更强;GNN则能更好地处理具有几何对称性的数据。
参数化策略:预测什么? 这是一个看似技术性但实际上非常重要的问题。神经网络应该预测什么?论文分析了四种主要策略:
- 直接预测原始数据:直观但在采样后期可能不准确
- 预测噪声:DDPM的经典选择,具有一致的数量级
- 预测分数(score):避免归一化常数问题
- 混合预测:结合多种策略的优势
每种策略都有其适用场景,选择合适的参数化方式对模型性能有显著影响。
加权优化:关注重点的艺术 扩散模型的训练过程中,不同时间步的重要性是不同的。早期时间步更关注全局结构,后期时间步更关注局部细节。通过巧妙的加权策略,可以让模型更好地平衡这种学习优先级。
3. 采样过程(Sampling Process):生成的最后一公里
有了训练好的去噪网络,如何高效地生成高质量样本?这就是采样过程要解决的问题。论文从两个维度分析了采样过程的设计:
引导机制:精确控制生成内容 现代扩散模型的一个重要特点是可控性。用户希望能够通过文本描述、图像条件等方式控制生成内容。论文分析了四种主要的引导机制:
- 原始引导:最简单的条件融合
- 分类器引导:使用额外的分类器提供梯度信息
- 无分类器引导:通过训练条件和无条件模型的混合来实现控制
- 学习型修改:通过适配器等方式学习特定的控制模式
加速设计:速度与质量的平衡 扩散模型的一个主要缺点是采样速度慢。论文总结了三种主要的加速策略:
- 截断方法:从中间时间步开始采样
- 知识蒸馏:训练更少时间步的学生模型
- 时间步选择:智能地选择关键时间步
技术洞察与实践指导
设计选择的权衡
论文的一个重要贡献是揭示了不同设计选择之间的权衡关系:
探索与利用的平衡:噪声调度需要在探索(足够的噪声以提高泛化能力)和利用(有效拟合训练数据)之间找到平衡。
准确性与效率的权衡:参数化策略的选择影响模型在不同采样阶段的表现,需要根据应用场景进行权衡。
可控性与生成质量的权衡:更强的控制能力往往伴随着更复杂的架构和可能的质量损失。
实践建议
基于论文的分析,可以总结出几个实践指导原则:
- 选择合适的噪声调度:对于大多数任务,余弦调度是一个不错的起点
- 架构选择要考虑数据特性:图像数据可以考虑U-Net,需要可扩展性时选择Transformer
- 参数化策略要匹配应用需求:需要稳定训练时选择噪声预测,需要避免归一化问题时选择分数预测
- 引导机制的选择要平衡性能和复杂度:无分类器引导通常是一个好的compromise
未来发展趋势
论文最后部分对扩散模型的未来发展进行了深入思考,提出了四个重要方向:
1. 泛化能力的理论理解
目前我们对扩散模型为什么具有良好泛化能力的理解还很有限。未来的研究需要从理论角度解释这一现象,这将有助于设计更好的模型。
2. 去噪导向的架构设计
现有的网络架构大多借鉴自其他领域,未来可能会出现专门为扩散模型设计的架构,这些架构会更好地利用去噪任务的特性。
3. 负责任的AI应用
随着扩散模型在创意产业的广泛应用,如何确保生成内容的原创性、避免版权侵犯、处理偏见问题等,都是需要认真考虑的问题。
4. 社会影响的考量
扩散模型的普及可能会对就业市场、教育系统产生深远影响,需要跨学科的合作来应对这些挑战。
结语
这篇综述论文为我们提供了理解扩散模型的一个全新视角。通过将复杂的扩散模型分解为三个功能组件,并系统分析每个组件的设计要素,论文不仅帮助我们更好地理解现有技术,也为未来的研究和应用指明了方向。
对于研究者而言,这篇论文提供了扎实的理论基础和丰富的设计选择;对于工程师而言,它提供了实用的指导原则和最佳实践;对于决策者而言,它揭示了技术发展的趋势和潜在的社会影响。
扩散模型作为生成式AI的核心技术,其发展还远未结束。随着我们对其设计基础理解的加深,相信会有更多创新的应用和突破性的进展出现。正如论文所言,理解一个系统的最好方式就是了解其组成部分------而这篇综述正是为我们打开了这扇理解之门。