Abstract
自动化高质量布局生成。虽然用生成对抗网络(GANs)和变分自编码器(VAEs)已经有不少进展,但GAN的多样性和分布覆盖有限、VAE生成质量又不够高。作者受扩散模型(Diffusion Models)在高质量图像生成领域的成功启发,提出将条件扩散模型(Conditional DDPM)与纯Transformer架构结合 ,创造出LayoutDM模型,用于条件布局生成。
LayoutDM既继承了transformer建模复杂关系的优势,也利用了DDPM的高分布覆盖及稳定训练目标,比GAN/VAE更优秀。实验也表明,LayoutDM在生成质量与多样性上领先于现有方法。
Introduction
现有方法及其局限
- GANs可以生成高质量布局样本,缺点是训练不稳定、分布覆盖有限(多样性差)。
- VAEs比GAN表现出更好的多样性和分布覆盖,但生成内容视觉效果不及GAN,且采样速度较慢。
- 二者都难以完全解决多样性、真实感、分布拟合和训练稳定性四者的平衡。
扩散模型的优势
- DDPM(Denoising Diffusion Probabilistic Model)近年来在图像生成领域风头正劲,兼具高质量样本、强多样性、分布覆盖、目标函数收敛稳定、易扩展等优势。
- 但,直接迁移到布局生成有两大难点 :
- 布局数据非像素网格,具有离散+连续+可变长度的结构,不适合常用的卷积网络(如U-Net)。
- 元素属性和元素间关系对布局有决定性作用,怎么用神经网络建模这些尤为关键。
论文创新点
- 用Transformer 取代 U-Net,作为反扩散网络,充分建模元素间复杂关系
- 设计出条件布局去噪器(cLayoutDenoiser),巧妙消融序列位置编码(不关心元素顺序),专注于空间关系
- 对比GAN与VAE,不仅生成质量高,还具备更强多样性、分布覆盖和稳定性
方法概述
1. 总体框架(LayoutDM)
- 包含一个前向扩散过程、一个反向去噪过程
- 前向过程:逐步添加高斯噪声(把原始布局扰乱)
- 反向过程:模型(cLayoutDenoiser)学会逐步从噪声还原布局
2. Transformer-based cLayoutDenoiser
- 用纯Transformer实现噪声预测,不依赖CV常用的卷积/U-Net
- 输入:被扰动的布局(带噪声)+ 布局元素特征f + 当前时间步t
- 输出:预测噪声分量,实现回溯去噪
- 不需要位置编码(Positional Encoding),因为元素没有顺序之分,强调元素间的相互关系而非"前后谁先谁后"
3. 条件生成
- 用户可以指定元素和属性(比如按钮、图片、文字模块的类型与尺寸等),模型据此生成可控属性下的多样化高质量布局。
主要贡献总结
- 创新:首次提出用Diffusion Model生成布局,并用纯Transformer替换传统U-Net骨干。
- 去噪器:设计了条件Transformer作为去噪器,强力建模复杂多元素关系。
- 实验:在多个数据集上大幅优于SOTA,兼得视觉质量和样本多样性。
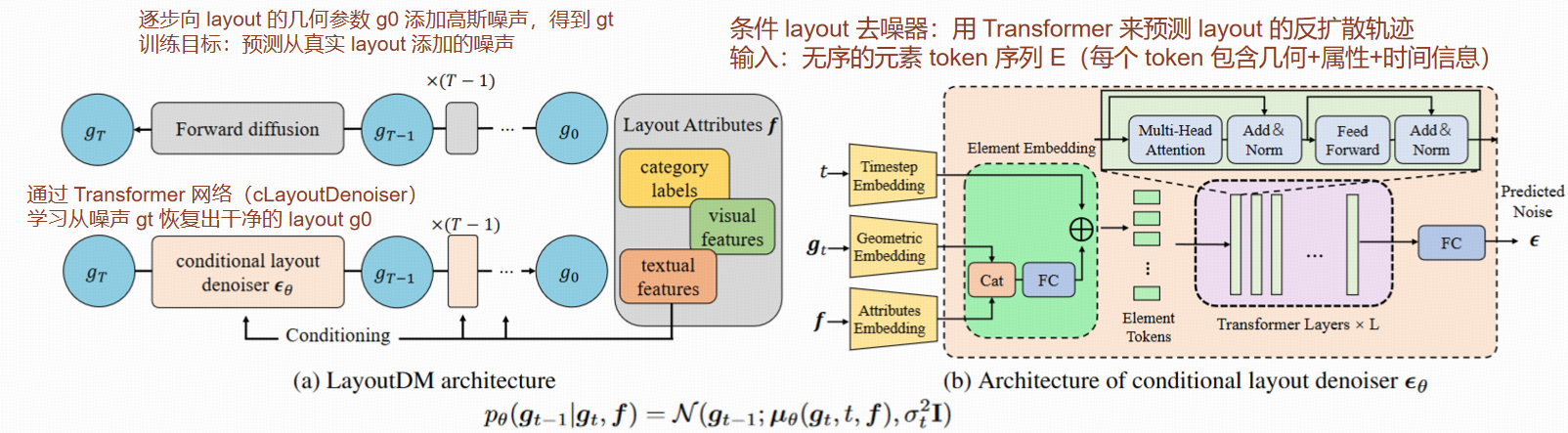
Figure 1
- a) LayoutDM整体架构:左侧是正向扩散过程(加噪声),右侧是反向过程(布局去噪器εθ),逐步还原布局。
- b) cLayoutDenoiser架构:输入带噪声的元素属性+时间步,输出噪声预测。
- c) 条件去噪器:能根据指定元素类别/属性,生成有控制的布局。
Method
3.1 Layout Representation
- 布局作为元素集合 :每个布局由任意数量的元素组成,每个元素包括几何参数(位置和尺寸,如中心点坐标和宽高)以及属性(如类别标签或文本特征)。
- 形式化表达 :布局表示为l = (g1, f1, g2, f2, ..., gN, fN)。gi = xi, yi, wi, hi,代表第i个元素的中心坐标和宽高;fi 是该元素的属性。
- 无序性 :元素在序列中的顺序没有意义,因此交换g和f中的元素不会改变布局含义,这也是模型不用"序列位置信息编码"的理论依据。
- 归一化 :所有几何参数都归一化到 −1, 1 区间,实现统一建模。
3.2 LayoutDM Architecture
整体概览 :LayoutDM属于带条件的DDPM(Denoising Diffusion Probabilistic Model),区别在于这里用的是Transformer背骨而非U-Net。
核心思想 :
- 正向扩散:逐步将布局几何参数加高斯噪声,直至变为完全噪声分布(近似高斯白噪声)。
- 反向去噪:用cLayoutDenoiser逐步从噪声恢复到可用的布局(受元素属性f引导,生成符合条件的多样化、高质量布局)。
关键公式 :

3.3 Conditional Layout Denoiser
(条件布局去噪器,核心创新)
- 输入:t时刻的噪声布局 gt、元素属性 f 和 time step t。
- 模型:完全基于 Transformer,而不是CNN。
- 属性引导:将属性embedding嵌入到输入元素token,指导每步生成。
- 三大embedding :
- GeometricEmbedding(gt):将归一化坐标投到高维空间。
- AttributesEmbedding(f):将离散类标签/文本property投到高维空间。
- TE(t):sinusoidal时间步编码,使模型有"进度"感知。
- ElementEmbedding过程 :
- 将上述两个embedding拼接,然后用一个FC层融合生成element token,再加TE(t)。
- 多头自注意力Transformer结构 :
- 堆叠8层,每层都进行多元素间关系建模,理解相互制约/吸引是高质量布局生成的关键。
- 不用传统transformer的"位置编码",因为布局元素无顺序!
- 输出:对每个元素,预测其噪声分量(作为去噪依据)。
|------|------------------|--------------------------|
| 项目 | 传统 DDPM | LayoutDM |
| 主干网络 | UNet(CNN) | 纯 Transformer 架构 |
| 输入数据 | 图像(像素) | 布局元素序列(x,y,w,h + 属性) |
| 噪声注入 | 加在图像像素上 | 加在 几何位置参数(layout box) 上 |
| 条件输入 | class label / 图像 | 元素属性 f(如类别、语义) |

3.4 Training and Inference
- 损失函数(简化版):


- 目标:让预测噪声和真实噪声尽量接近,训练cLayoutDenoiser高质量还原布局。
- 训练算法(Algorithm 1) :
- 随机采样真实布局(g0, f)、时间步t和噪声ε。
- 得到添加噪声后的gt。
- 用预测器εθ(gt, t, f)还原噪声,计算MSE,反向传播优化。
- 采样流程(Algorithm 2) :
- 从纯高斯噪声gT开始。
- 逐步从T降到1,逆向用cLayoutDenoiser根据属性f指导,每次去噪一步,直至g0即布局结果。
Experiments
4.1 Experimental Settings
- 数据集 :
- Rico:手机UI大规模布局。
- PublayNet:科学文档布局(文本、标题、表格等)。
- Magazine:杂志。
- COCO:自然场景目标。
- TextLogo3K:文本logo的布局检测。
- 评估指标 :
- FID(Fréchet Inception Distance):越小越好,衡量生成分布与真实分布的接近度,综合多样性/拟真度。
- Max. IoU:找最佳匹配,测生成布局与真实布局重合质量。
- Overlap、Alignment:分别评判布局元素的重叠/对齐程度,反映感官美学。
- 实现细节 :
- 步数T=1000,变异度β线性递增,8层Transformer,8头注意力。
- Adam优化器,lr=1e-5, batch size=1024, PyTorch Lightning, 单卡即可。
4.2 Quantitative Evaluation
与主流方法对比(基于Rico, PublayNet, Magazine等)
- 对象:LayoutGAN、LayoutGAN++、NDN、VTN等(有的引用前作结果,有的重实现对比)。
- 结论总结 :
- FID/MaxIoU指标:LayoutDM全线领先(意味着生成既多样又高质量)。甚至有的场景生成FID比验证集还低,因为采样属性和测试集一致,没引入复杂度。
- Overlap/Alignment:略微劣于部分GAN/NDN方法,因为LayoutDM无判别器(GAN的判别器能严格优化对齐/重叠),也未采用精细化layout refine模块。
- 更广泛SOTA对比:补充和BLT等最近模型对比,LayoutDM依然在各指标最优。
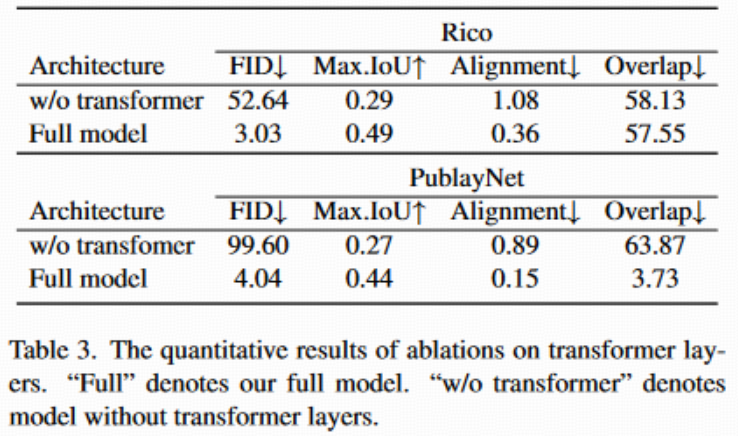
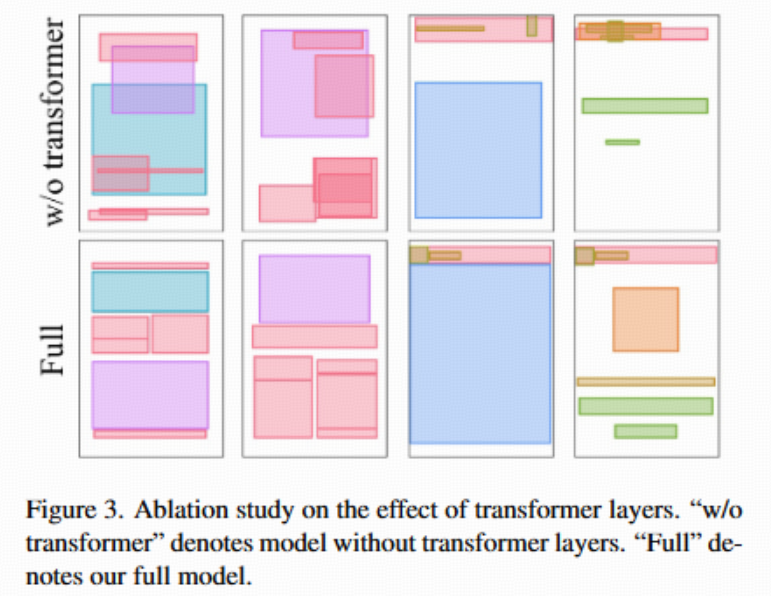
消融实验(Transformer结构有效性)
- 实验现象 :
- 如果把Transformer换成全连接网络(FC),能拟合每个元素大小,但失去了全局/相对关系理解,表现为严重"堆叠""错位"。
- 说明自注意力机制(即Transformer结构)对解码和表达布局元素间复杂依赖至关重要。
- 见表3和图3,直观可见效果明显优于无Transformer版本。
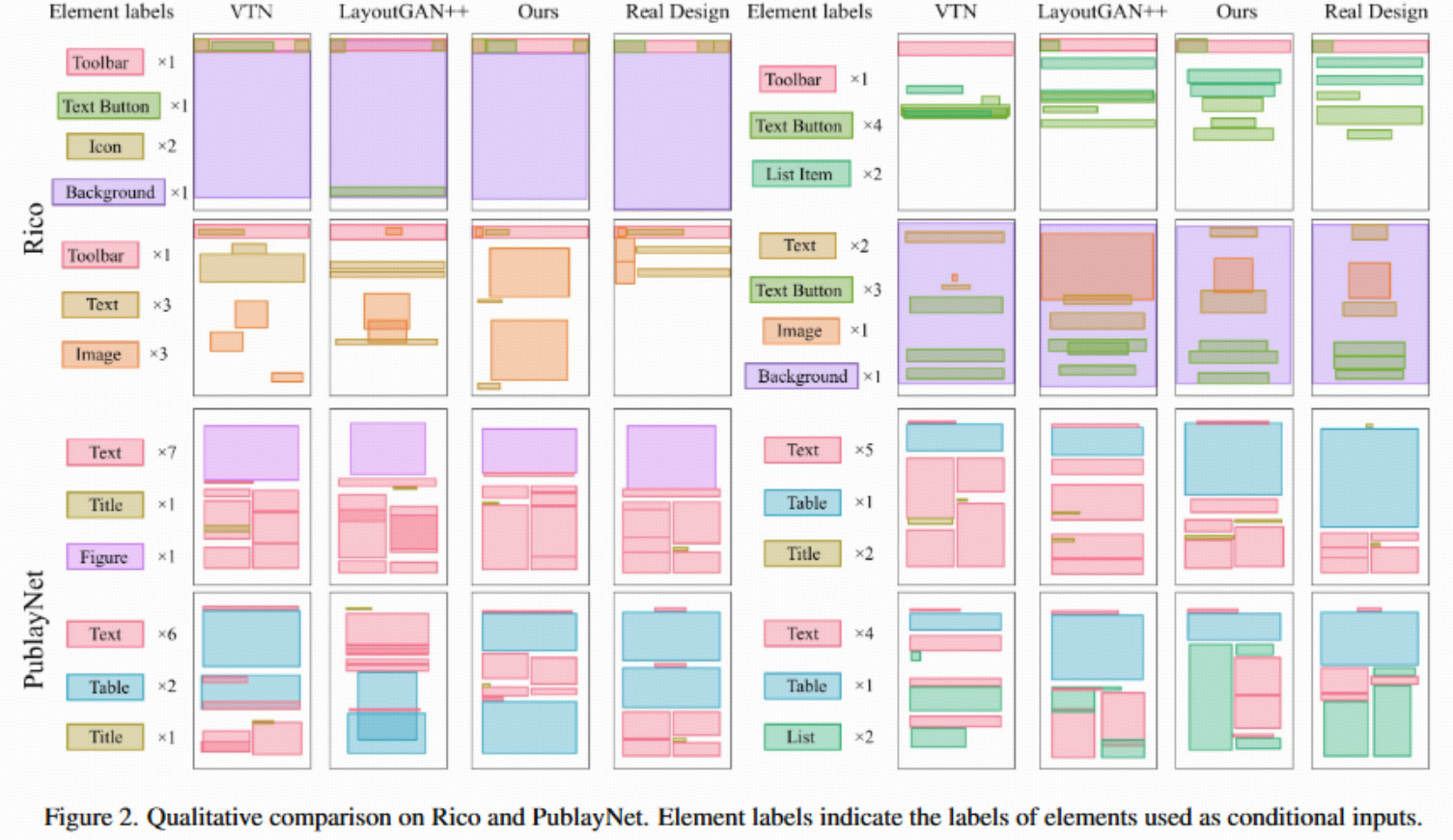
4.3 Qualitative Comparisons
① 生成质量对比
- 实验设置:随机采样测试集的布局,输入类别标签作为生成条件,对比 LayoutDM、LayoutGAN++ 和条件 VTN(Conditional VTN)。
- 可视化结果(Fig.2) :
- LayoutDM布局更合理、丰富、复杂,元素排列兼顾全局和细节,几乎没有重叠且对齐较好。
- LayoutGAN++ 和 VTN生成的结果则更容易出现元素重叠和对齐不佳等问题。
② 生成多样性对比
- 结果:LayoutDM 和 VTN 都显示出更强的布局多样性,同一组条件生成的结果不同,体现模型的高泛化能力。LayoutGAN++ 则很容易陷入模式坍缩(如大图片元素总是放在相同位置)。
- 归因:LayoutDM 通过逐步条件扩散建模,天然避免了GAN系常见的模式坍缩问题,使每一次采样都能探索更大解空间。
③ 渲染结果对比
- 实验方法:将生成的版面用真实素材"还原"成可视化的图形页面(如PublayNet)。
- 结果(Fig.5):LayoutDM生成的页面布局完全合理,空间利用和对齐优于LayoutGAN++,而且无明显重叠现象。虽然简单裁剪和拉伸图片会导致失真,真实应用中可通过调整字体/图像自适应解决。

4.4 扩展任务(Extended Layout Generation Tasks)
1. 文本Logo布局生成
- 实验:在TextLogo3K数据集上生成logo布局(该数据集无标签,只能用字符/词嵌入为条件)。
- 方法变化:此处LayoutDM在Transformer中使用了位置编码(因为字符有阅读顺序需求)。
- 结果(Fig.6) :
- LayoutDM保证了阅读顺序和美观,多字符布局还能灵活调整(而LogoGAN容易失败或只简单地水平排布)。
- 大量字符场景下,LayoutDM显著优于对手,生成效果更丰富、合理

2. 场景布局生成
- 实验:在COCO等自然场景数据集按场景元素标签生成布局。
- 结果(Fig.7) :
- LayoutDM能合理预测并安排物体空间位置,"船在河中央,云在天空",体现了模型对真实场景关系的"理解"。
- 并可结合下游模型直接生成高质量的场景图片。

4.5 主要局限性
- 单层画布:如同多数布局生成方法,目前只能处理所有元素在同一平面,不可表达多层叠加关系(前后遮挡)。
- 生成速度:扩散模型迭代去噪过程较慢,不能与VAEs快速采样相提并论。实际应用可能需要进一步加速优化或采用快速采样技术。
5. 结论
- 创新之处:首次将完全无序元素的Transformer结构扩散模型(LayoutDM)用于条件布局生成。
- 优势突出:融合了扩散模型的高分布覆盖与Transformer的强关系建模,兼得高质量、多样性与稳定性。
- 实验充分:大量定量定性对比,领先传统GAN/VAE类模型。
补充材料
- 数据集及评测划分说明
- 各数据集严格规范地划分了train/val/test,结果可信且保证公平对比。
- 评测指标详细解释
-
FID:用特征判别器中间层输出做分布匹配,度量生成和真实布局的分布距离。
-
MaxIoU:生成布局和真实参考集两两最佳重叠度评价。
-
Alignment:度量元素对齐性(左右/居中/上下)。
-
Overlap:总重叠比例。

- 对BLT等SOTA方法的补充对比
- 按BLT的方式,在PublayNet、Rico、Magazine等做了更全面的SOTA对比,LayoutDM始终全面领先。
- 为什么LayoutDM有时"比真实数据还低的FID"
- 因为LayoutDM生成时用到了test set的属性条件而验证集是随机分布,所以生成分布与test set高度匹配(比val更像test set),FID会更低。这一点作者也补充通过实验证明。
- 关于位置编码消融实验
-
不加位置编码(PE):无序输入任意shuffle都不影响生成,高稳定性。
-
加上PE:输入顺序变化会导致错误解读和低质量输出。
-
充分说明LayoutDM结构自然满足布局元素无序性。