一、简单概述
LSTM(Long Short-Term Memory):长短期记忆网络。
1.1LSTM出现的原因
在LSTM之间也有一个用于循环神经网络的模型---RNN模型。
但是RNN模型存在明显的局限性,它只能处理短序列的文本内容,在处理长序列时容易出现梯度消失或梯度爆炸的问题,因此难以捕捉长期依赖关系。
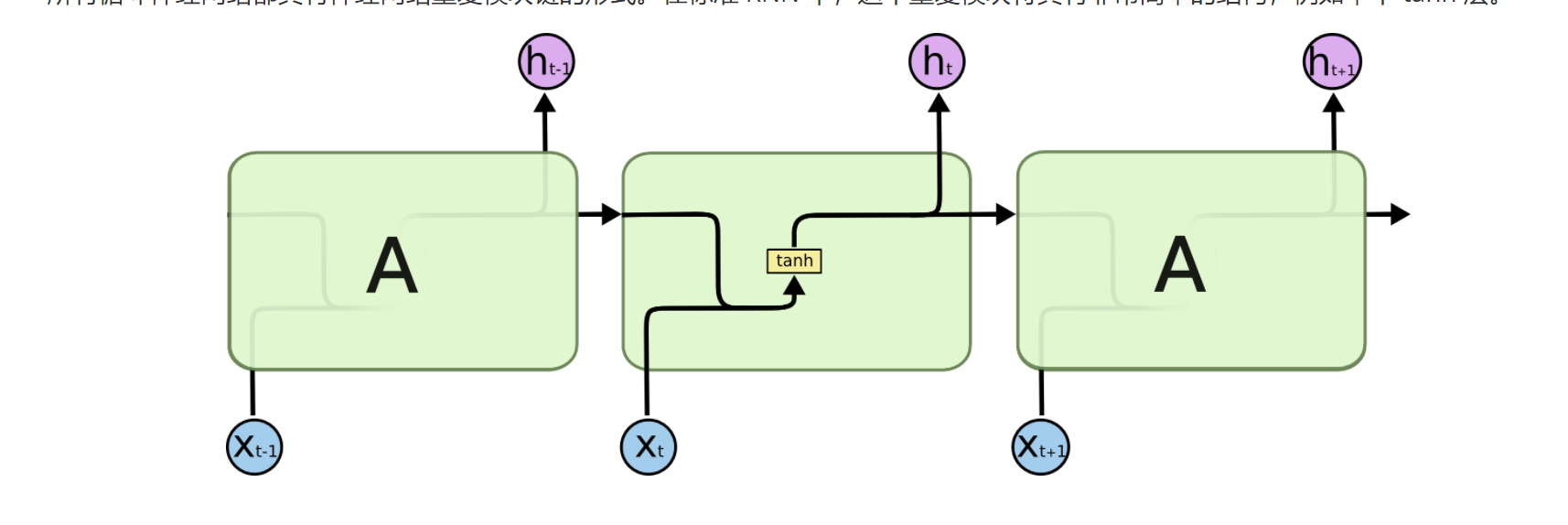
举个栗子:对于一个长序列'他小时候养过一只猫,现在**_____**很喜欢小动物 ',此时RNN模型可能忘记'他'和'猫'的关联。模型无法判断横线上到底是哪个答案。RNN就相当于只是机械的记住短序列,但是它没有上下关联的能力。
1.2LSTM的优胜点
LSTM在RNN的基础上进行优化,此时LSTM就能处理长期依赖问题,因此成为处理序列数据的核心模型之一。
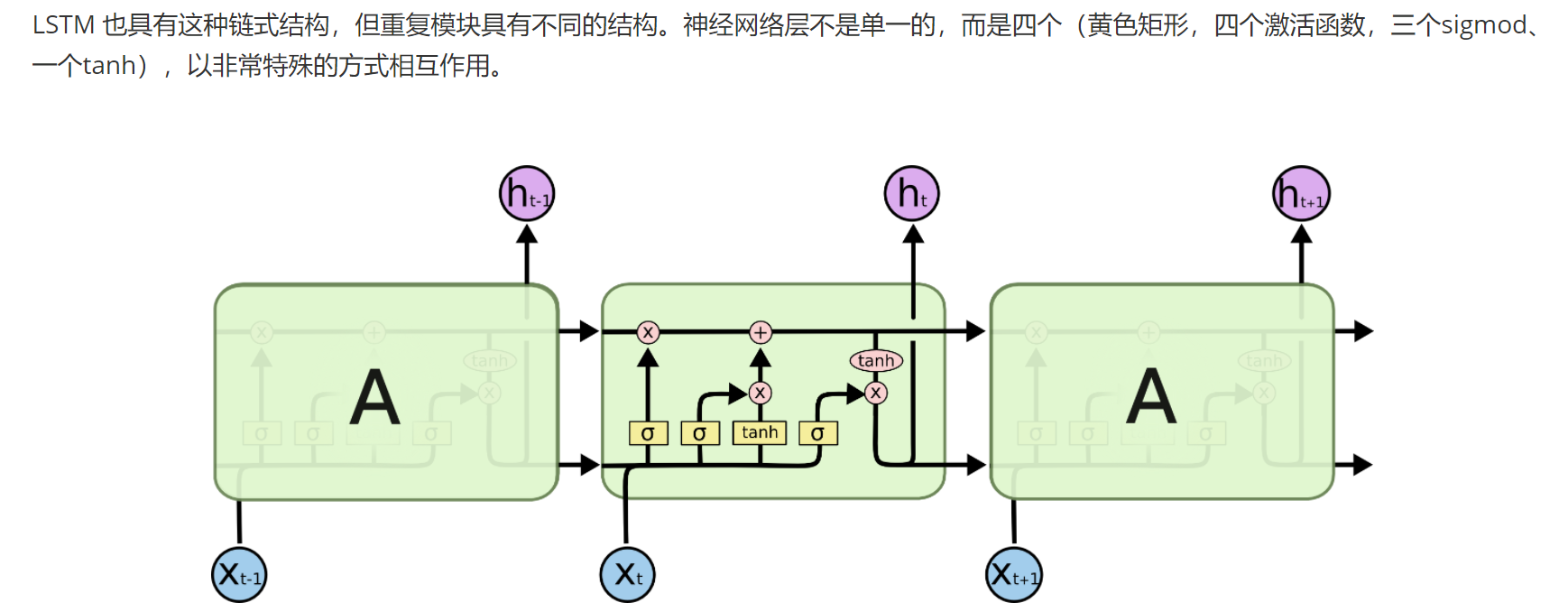
LSTM主要是通过三门一状态来解决长期依赖问题的:三门就是下面要描述的三个门控机制,一状态指的是细胞状态,细胞状态主要负责'长期记忆'的存储:
一条水平线贯穿于图像的上方,这些线上只有少量的线性操作(从而避免了剧烈的梯度变化),信息在上面很容易保持。
二、门控机制
每个门控单元由一个sigmoid激活函数和一个点积操作组成:
-
sigmoid 输出范围为 (0,1),表示 "信息通过的比例"(0 = 完全阻止,1 = 完全通过);
-
点积操作则将 sigmoid 的输出与对应信息相乘,实现对信息的筛选。
2.1遗忘门
遗忘门决定的是保留什么信息以及遗忘什么信息
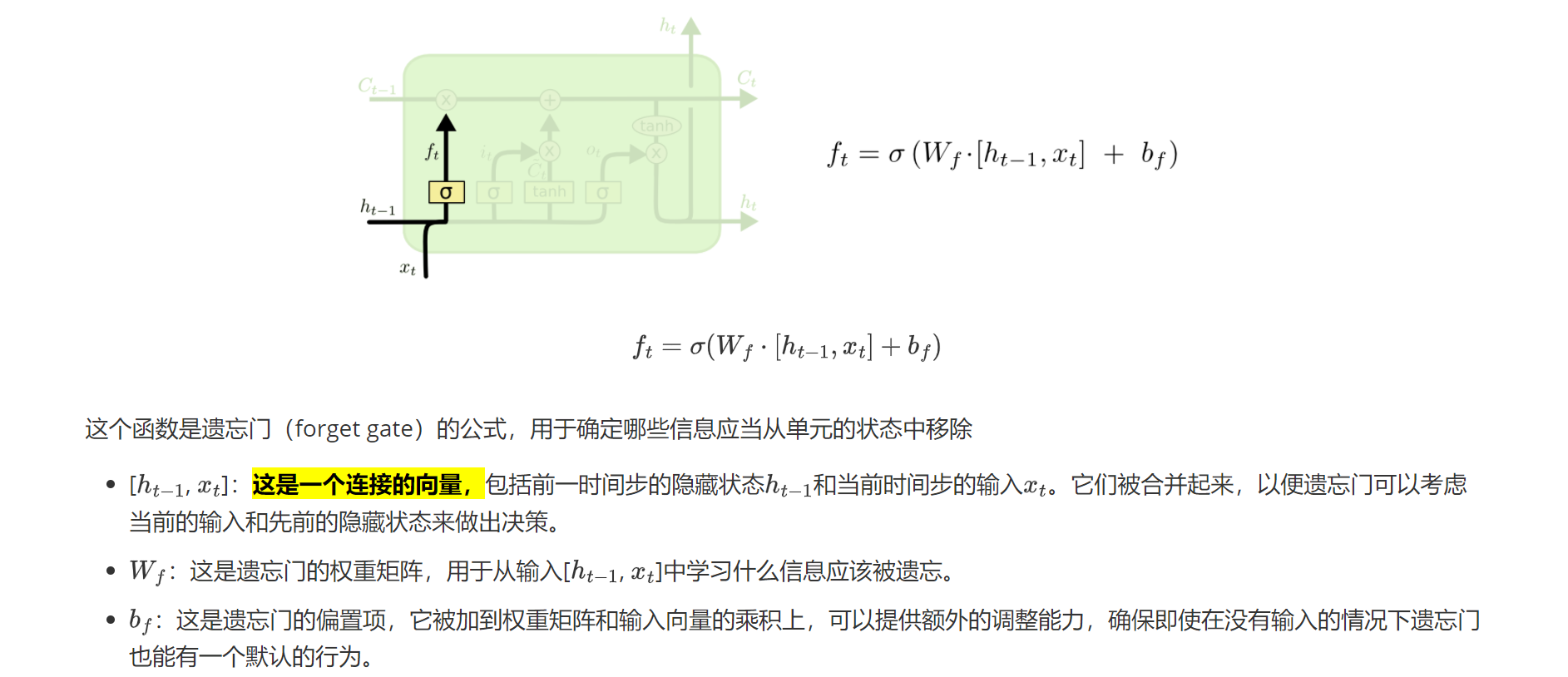
Ft:这是在时间步 ( t ) 的遗忘门的输出,它是一个向量,其中的每个元素都在0和1之间,对应于细胞状态中每个元素应该被保留的比例。若结果为0,则遗忘该信息,若为1,则保留该信息。
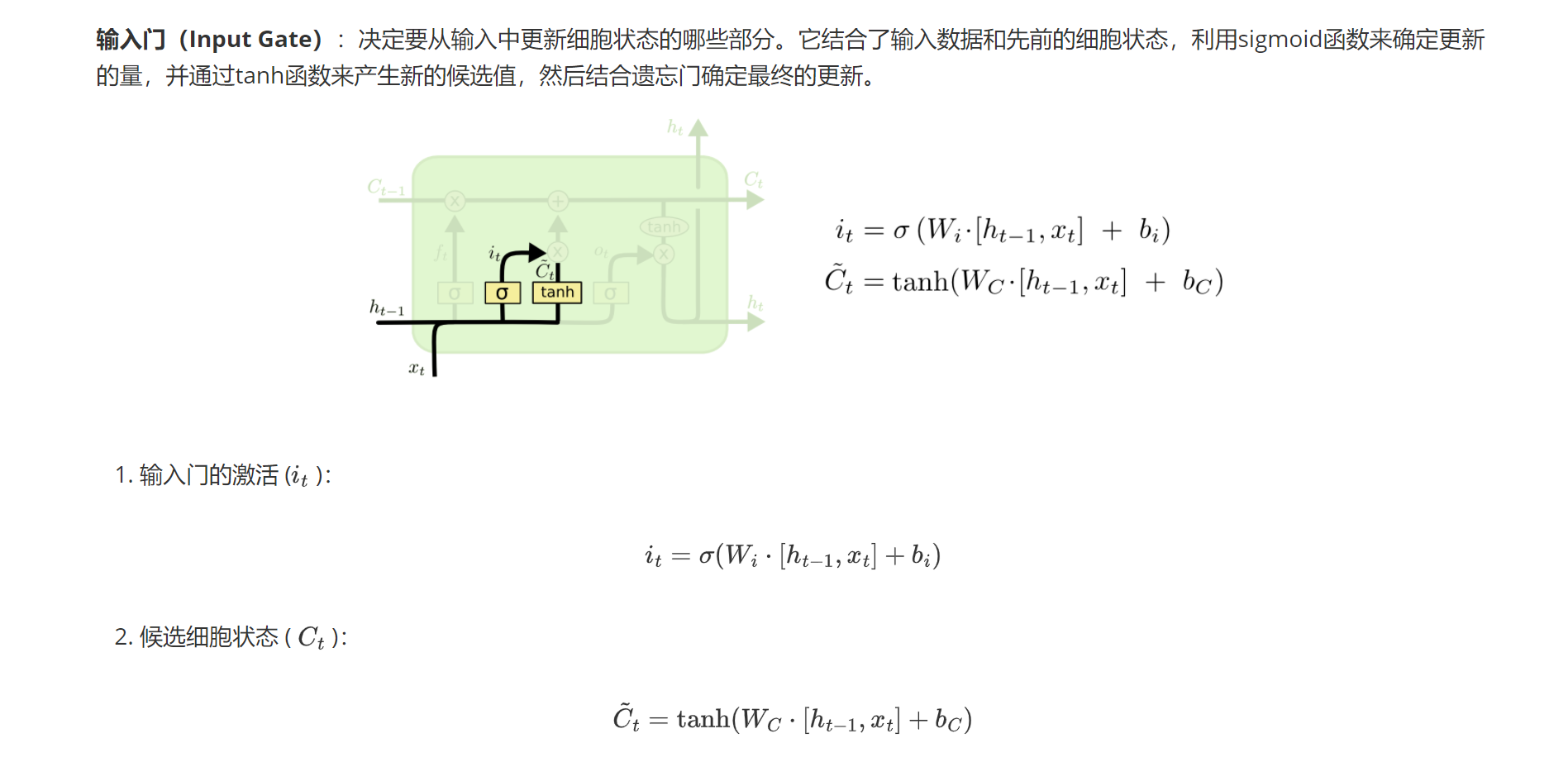
2.2输入门
输入门决定记住什么信息
2.3状态更新
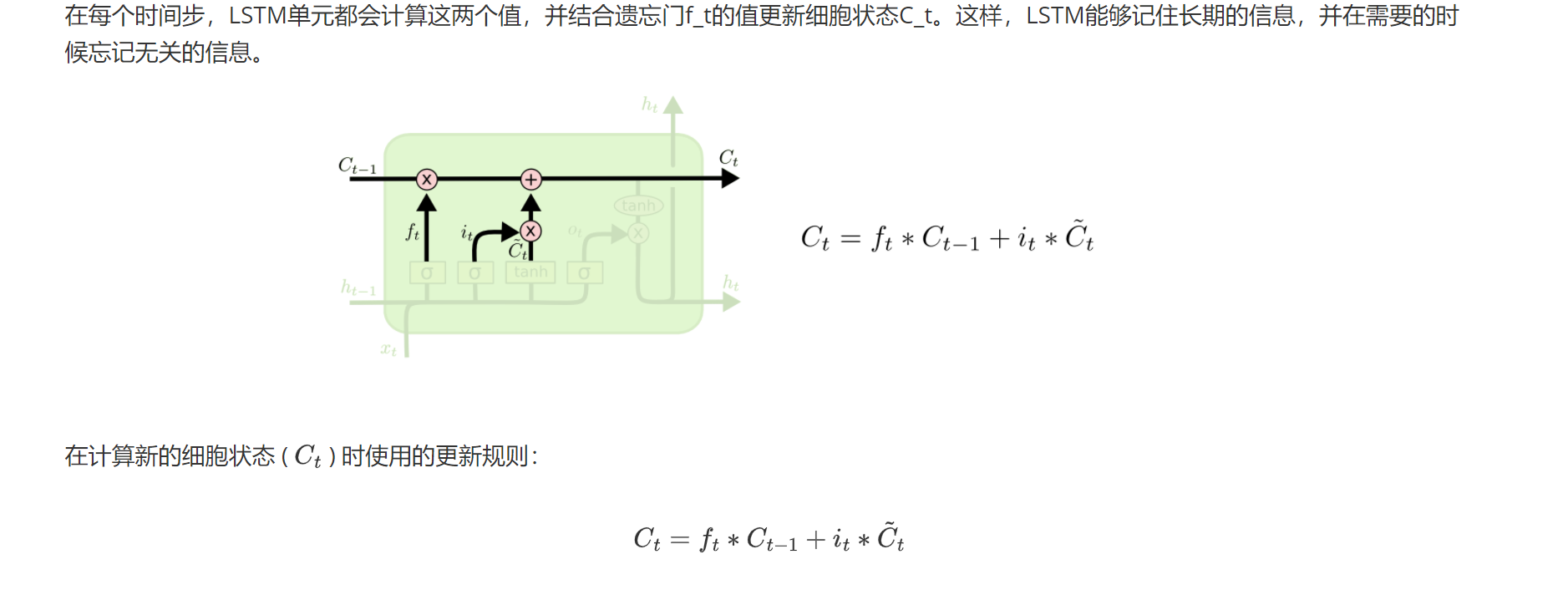
2.4输出门
输出门决定输出什么信息
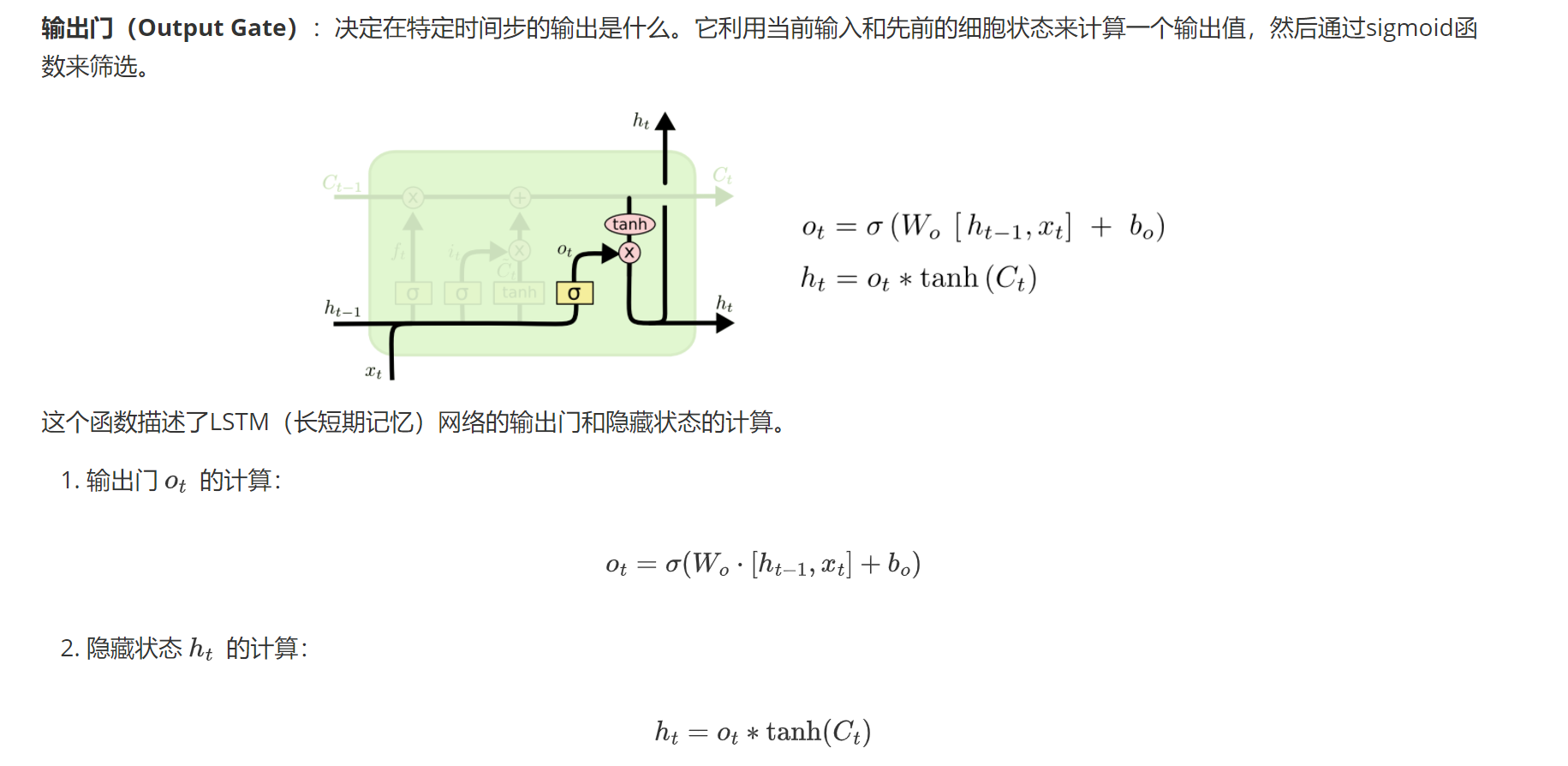
2.5小结
LSTM是一种特殊的循环神经网络,专为解决传统RNN的梯度消失或爆炸问题设计。
它通过引入细胞状态和三个门控机制(输入门、遗忘门、输出门)来有效捕捉序列数据中的长期依赖关系。输入门控制新信息的进入,遗忘门决定保留或丢弃历史信息,输出门则筛选当前需输出的内容。
LSTM在自然语言处理、时间序列预测等领域应用广泛,能处理变长序列,较好保留上下文信息,是处理序列数据的重要模型之一。
三、API
API:nn.LSTM (input_size, hidden_size, num_layers=1)。
input_size 为输入特征维度
hidden_size 是隐藏层大小
num_layers 指定 LSTM 层数
四、序列池化
序列池化(sequence pooling)是一种将变长序列转换为固定长度表示的方法。
在 LSTM 模型中,最大池化和平均池化通常用于处理序列输出,提取关键信息。
两者都能将变长序列转换为固定长度向量,便于后续处理,选择哪种取决于任务是否需强调极端值或整体趋势。
4.1最大池化
最大池化从序列的多个时间步输出中选取最大值,突出序列中最显著的特征或关键时刻的信息。
API:nn.AdaptiveMaxPool1d(1)
注意:要调整维度信息
调整形状以匹配池化层的输入要求
x = x.permute(0, 2, 1)
从 batch_size, seq_len, feature_size 变为 batch_size, feature_size, seq_len
4.2平均池化
平均池化则计算序列所有时间步输出的平均值,反映序列整体的平均特征,平滑局部波动。
API:nn.AdaptiveAvgPool1d(1)
调整形状以匹配池化层的输入要求
x = x.permute(0, 2, 1)
从 batch_size, seq_len, feature_size 变为 batch_size, feature_size, seq_len
五、梯度消失
5.1梯度消失
在以下这些方面中,LSTM可能仍会出现梯度消失的问题:
(1)长期依赖问题:若果序列很长很长,即使是LSTM仍然有可能会记不得有效信息;
(2)不适当的权重初始化;
(3)激活函数的寻找不同,梯度缩小程度也不同。
5.2梯度爆炸
(1)过长的序列长度;
(2)不适当的学习率;
(3)不适当的权重初始化。
六、中文情绪分析案例
6.1简单介绍
所用的数据集是关于酒店的中文评价,数据量为5265条,其中2822条好评,其余的均为差评。
我们目的就是利用LSTM和全连接实现自定义网络结构对数据集进行训练,然后实现中文评论的情感分析,分析评论是正面的还是负面的。
6.2实现步骤
6.2.1数据预处理
(1)对原本格式为csv的数据集进行处理,获取文字:索引的字典;
注意:这里的字典要除去标点符号,并且里面的关键字不能重复。
(2)解析当前字典;
(3)获得索引文本,这里的索引是csv里的文字信息的索引;
注意:文字索引与标签索引的分隔符号为英文逗号,所以可以用split拆分。
(4)对索引文本进行拆分处理,最后返回data和label;
(5)读取字典,获取字典大小即键值对的数量--文本的数量。
6.2.2数据加载
(1)获取输入数据inputs和标签labels;
(2)划分数据集,训练和测试的比例为8:2;
(3)将训练数据和训练标签先转换为数组,再转换为张量;
(4)将数据放入数据集中;
(5)创建数据加载器方法,最后返回加载器。
6.2.3模型训练
(1)训练之前先定义网络结构;
(2)LSTM的网络结构:embedding、LSTM、tanh、Linear
注意:前向传播的时候要用0填充初始化隐藏层和细胞层;
LSTM的模型变量承接是两个变量,如:x,_ = self.LSTM(x,(h0,c0))
(3)开始训练;
(4)保存模型。
6.2.5模型预测
(1)加载模型;
(2)加载数据加载器;
(3)梯度清理;
(4)模型预测。
6.3实现代码
数据处理:
python
import os
#原数据位置
csv_path = os.path.relpath(os.path.join(os.path.dirname(__file__), './dataset', 'hotel_discuss2.csv'))
#处理之后的字典索引位置
word_index_path = os.path.relpath(os.path.join(os.path.dirname(__file__), './dataset', 'word_index.txt'))
#处理之后的索引位置
index_path = os.path.relpath(os.path.join(os.path.dirname(__file__), './dataset', 'index.txt'))
#文本数据中不要的标点符号,这里的符号要用中文符号
punk = ',。!?'
def test01():
index = 1
#关键字:索引 ------字典
word_index = {}
with open(csv_path, 'r', encoding='utf-8-sig') as f:
with open(word_index_path, 'w', encoding='utf-8-sig') as f1:
lines = f.readlines()
for line in lines:
line = line.replace('\n', '')
for word in line:
if word not in punk:
if word not in word_index:
word_index[word] = index
index += 1
else:
continue
f1.write(str(word_index))
def test02():
word_index = test03()
with open(csv_path, 'r', encoding='utf-8-sig') as f:
with open(index_path, 'w', encoding='utf-8-sig') as f1:
lines = f.readlines()
for line in lines:
line = line.replace('\n', '')
line_indexs = []
ls = line.split(",")
for word in ls[1]:
if word not in punk:
line_indexs.append(word_index[word])
f1.write(str(line_indexs) + '\t')
f1.write(str(ls[0]) + '\n')
def test03():
with open(word_index_path, 'r', encoding='utf-8-sig') as f:
#eval()将读取的字符串作为 Python 代码执行,通常用于解析字典格式的字符串(如{'apple': 1, 'banana': 2})
word_index = eval(f.read())
return word_index
def test04():
#对索引文本进行拆分处理,最后返回data和label;
with open(index_path, 'r', encoding='utf-8-sig') as f:
line_length_Threshold =200 #句子长度阈值
lines = f.readlines()
labels = []
inputs = []
for line in lines:
ls = line.split("\t")
input = []
#这里的ls[0]是文字列表,ls[1]是标签
if len(eval(ls[0])) > line_length_Threshold:
#如果句子长度大于阈值,截断句子
input = eval(ls[0])[:line_length_Threshold]
if len(eval(ls[0])) <= line_length_Threshold:
#如果句子长度小于等于阈值,差的补0
input = eval(ls[0])+[0]*(line_length_Threshold-len(eval(ls[0])))
inputs.append(input)
labels.append(int(ls[1].replace('\n', '')))
return inputs, labels
def test05():
#读取并解析指定文件中的word_index字典,然后返回该字典中包含的键值对数量(即词汇表的大小)。
with open(word_index_path, 'r', encoding='utf-8-sig') as f:
word_index = eval(f.read())
print(len(word_index))
return len(word_index)
if __name__ == '__main__':
# test01()
# test02()
# test04()
test05()数据加载器:
python
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split
from DataProcess import test04
import numpy as np
import torch
#获取数据集
inputs,labels = test04()
#划分数据集
train_data,test_data,train_labels,test_labels = train_test_split(inputs,labels,
test_size=0.2)
#将数据集转化为tensor
train_data = np.array(train_data,dtype = np.int64)
train_labels = np.array(train_labels,dtype = np.int64)
train_data = torch.from_numpy(train_data)
train_labels = torch.from_numpy(train_labels)
# test_data = np.array(test_data,dtype = np.int64)
# test_labels = np.array(test_labels,dtype = np.int64)
# test_data = torch.from_numpy(test_data)
# test_labels = torch.from_numpy(test_labels)
#定义数据集
train_dataset = TensorDataset(train_data,train_labels)
def get_loader():
dataloader = DataLoader(dataset = train_dataset, batch_size = 32, shuffle = True)
return dataloader
if __name__ == '__main__':
dataloader = get_loader()
for i,(data,label) in enumerate(dataloader):
print(data.shape) #(32, 100):32个样本,每个样本200个字符
print(label.shape) #(32,):32个标签模型训练和预测:
python
import os
import torch
import torch.nn as nn
import torch.optim as optim
from dataloader import get_loader
from DataProcess import test05
#定义一个网络结构
class SimpleLSTM(nn.Module):
def __init__(self,word_size,input_size=128,hidden_size=128,
output_size=2,num_layers=1,batch_first=True,device='cpu'):
super(SimpleLSTM,self).__init__()
self.word_size = word_size
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.batch_first = batch_first
self.device = device
self.embed = nn.Embedding(word_size,input_size)
self.lstm = nn.LSTM(input_size=input_size,hidden_size=hidden_size,
num_layers=num_layers,batch_first=batch_first)
self.tanh = nn.Tanh()
self.fc = nn.Linear(hidden_size,output_size)
def forward(self,x):
x = self.embed(x)
#初始化
h0 = (torch.zeros(self.num_layers,x.shape[0],self.hidden_size))
c0 = (torch.zeros(self.num_layers,x.shape[0],self.hidden_size))
h0 = h0.to(self.device)
c0 = c0.to(self.device)
x,_ = self.lstm(x,(h0,c0))
x = self.tanh(x)
x = x[:,-1,:]
out = self.fc(x)
return out
def train():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 获取词汇表大小并验证
word_size = test05()
print(f"词汇表大小: {word_size}")
# 初始化模型
model = SimpleLSTM(word_size=word_size)
model.to(device)
# 获取数据加载器
loader = get_loader()
# 验证数据索引范围
for x, y in loader:
max_idx = x.max().item()
if max_idx >= word_size:
print(f"警告: 发现超出范围的索引 {max_idx} (词汇表大小 {word_size})")
# 可选:裁剪索引到有效范围
x = torch.clamp(x, max=word_size - 1)
# 训练设置
optimizer = optim.Adam(model.parameters(), lr=0.001) # 降低学习率
criterion = nn.CrossEntropyLoss()
epochs = 10 # 增加训练轮数
for epoch in range(epochs):
model.train()
total_loss = 0
correct = 0
total = 0
for i, (x, y) in enumerate(loader):
x, y = x.to(device), y.to(device)
# 确保索引在有效范围内
x = torch.clamp(x, max=word_size - 1)
out = model(x)
loss = criterion(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
_, predicted = torch.max(out, 1)
correct += (predicted == y).sum().item()
total += y.size(0)
if i % 10 == 0:
print(f'Epoch [{epoch + 1}/{epochs}], Step [{i}/{len(loader)}], Loss: {loss.item():.4f}')
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {total_loss / len(loader):.4f}, Accuracy: {correct / total:.4f}')
# 保存整个模型
model_path = os.path.join(os.path.dirname(__file__), 'model', 'full_model.pth')
torch.save(model, model_path)
print('模型保存成功!')
def test():
# 设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据加载器
loader = get_loader()
# 语料库的长度
word_size = test05()
# 模型
model = SimpleLSTM(word_size=word_size, device=device)
model.to(device)
# 训练轮数
epochs = 10
# 损失函数
loss_fn = nn.CrossEntropyLoss(reduction='sum')
# 测试
acc_total = 0
loss_total = 0
model.eval()
with torch.no_grad():
for i, (x, y) in enumerate(loader):
x, y = x.to(device), y.to(device)
# pre(32,2)
pre = model(x)
acc_total += torch.sum(torch.argmax(pre, dim=1) == y)
loss = loss_fn(pre, y)
loss_total += loss.item()
print(f'loss:{loss_total / len(loader.dataset)}----->acc:{acc_total / len(loader.dataset)}')
if __name__ == '__main__':
# train()
test()