目录
[1.1、 核心要素与符号定义](#1.1、 核心要素与符号定义)
[1.2、 核心问题:稀疏奖励困境](#1.2、 核心问题:稀疏奖励困境)
[1.3、 学习目标](#1.3、 学习目标)
[2、HER(Hindsight Experience Replay)算法](#2、HER(Hindsight Experience Replay)算法)
[2.1、 HER 的核心逻辑](#2.1、 HER 的核心逻辑)
[2.2、 算法步骤(结合 DDPG 举例)](#2.2、 算法步骤(结合 DDPG 举例))
[2.2.1、步骤 1:收集原始经验](#2.2.1、步骤 1:收集原始经验)
[2.2.2、步骤 2:重构经验(核心!)](#2.2.2、步骤 2:重构经验(核心!))
[2.2.3、步骤 3:替代目标生成策略](#2.2.3、步骤 3:替代目标生成策略)
[2.2.4、步骤 4:策略更新](#2.2.4、步骤 4:策略更新)
[2.3、 为什么 HER 有效?](#2.3、 为什么 HER 有效?)
1、目标导向的强化学习:问题定义
目标导向的强化学习(Goal-Conditioned Reinforcement Learning)是一类让智能体通过学习策略,从初始状态达到特定目标的任务。与传统强化学习不同,这类任务的核心是 "目标"------ 智能体的行为需围绕 "达成目标" 展开,而目标本身可能随任务变化(如 "机械臂抓取 A 物体""机械臂抓取 B 物体" 是两个不同目标)。
1.1、 核心要素与符号定义
- 状态(State) :环境的观测信息,记为
(
- 目标(Goal) :智能体需要达成的状态,记为
- 动作(Action) :智能体的行为,记为
- 转移函数 :状态 - 动作对到下一状态的映射,记为
- 奖励函数 :衡量 "当前状态与目标的差距",记为
1.2、 核心问题:稀疏奖励困境
目标导向任务的奖励函数通常是稀疏的 :仅当状态 s 与目标 g 几乎一致时,才给予正奖励;否则奖励为 0 或负值。 奖励函数示例(机械臂抓取任务):

- 智能体在绝大多数尝试中(如 99% 的交互)都得不到正奖励,无法判断 "哪些动作有助于接近目标";
- 策略更新缺乏有效信号(梯度难以计算),学习效率极低,甚至无法收敛。
1.3、 学习目标
目标导向强化学习的目标是学习一个目标条件策略 ,使得在策略引导下,智能体从任意初始状态 \(s_0\) 出发,通过执行动作序列
,最终达到目标 g 的概率最大化。
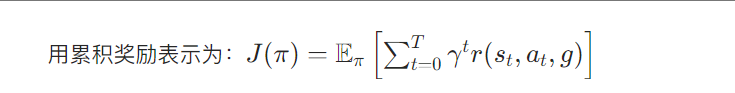
2、HER(Hindsight Experience Replay)算法
HER 算法是解决目标导向任务中稀疏奖励问题的经典方法,核心思想是:从 "失败经验" 中 "事后重构" 有效奖励信号------ 即使智能体没达成原定目标,也能通过修改目标,将 "失败轨迹" 转化为 "成功轨迹",从而提取学习信号。
2.1、 HER 的核心逻辑
假设智能体在一次交互中,原定目标是 g,但实际轨迹为,最终状态
(失败)。 HER 的关键操作是:从轨迹
中选一个状态
作为 "替代目标"
,此时轨迹
对于新目标 \
是 "成功的"(因为
可能接近
),从而可计算有效奖励。
2.2、 算法步骤(结合 DDPG 举例)
HER 通常与离线强化学习算法(如 DDPG)结合使用,流程如下:
2.2.1、步骤 1:收集原始经验
智能体与环境交互,收集轨迹并存储到经验回放池 。每条经验是一个五元组:
其中
是基于原定目标 g 的奖励(可能为 0)。
2.2.2、步骤 2:重构经验(核心!)
对回放池中的每条原始经验 e,HER 通过替代目标生成策略 选一个新目标 ,重构出一条 "虚拟成功经验"
:
其中
是基于新目标
的奖励(此时可能为正,因为
来自轨迹,
可能接近
)。
2.2.3、步骤 3:替代目标生成策略
HER 定义了 4 种常用的替代目标生成策略(以轨迹 为例):
- Final :
- Future :
- Random :
- Episode :
2.2.4、步骤 4:策略更新
将原始经验 e 和重构经验 一起放入回放池,用离线算法(如 DDPG)更新策略。 以 DDPG 的 Critic 网络更新为例:

2.3、 为什么 HER 有效?
- 解决稀疏性:通过重构经验,将 "0 奖励" 转化为 "正奖励",使奖励信号密集化;
- 利用失败经验:原本无用的失败轨迹被转化为有效学习样本,提高数据利用率;
- 通用兼容:HER 是 "经验回放增强技术",可与 DDPG、SAC 等多种算法结合,无需修改算法核心。
2.4、公式总结
- 原始经验:
- 重构经验:
- 策略目标:
3、通俗理解
用 "快递员送货" 举例:
- 目标导向任务:快递员(智能体)需要把包裹送到目标地址 g(原定目标),但只有送到 g 才有钱(奖励),中途迷路(失败)则没钱。
- 稀疏奖励问题:快递员第一次送陌生地址,99% 的概率找不到,长期没钱,不知道往哪走。
- HER 的做法:快递员虽然没到 g,但路过了
4、完整代码
python
"""
文件名: 19.1
作者: 墨尘
日期: 2025/7/25
项目名: d2l_learning
备注:
"""
import torch
import torch.nn.functional as F
import numpy as np
import random
from tqdm import tqdm
import collections
import matplotlib.pyplot as plt
class WorldEnv:
def __init__(self):
self.distance_threshold = 0.15
self.action_bound = 1
def reset(self): # 重置环境
# 生成一个目标状态, 坐标范围是[3.5~4.5, 3.5~4.5]
self.goal = np.array(
[4 + random.uniform(-0.5, 0.5), 4 + random.uniform(-0.5, 0.5)])
self.state = np.array([0, 0]) # 初始状态
self.count = 0
return np.hstack((self.state, self.goal))
def step(self, action):
action = np.clip(action, -self.action_bound, self.action_bound)
x = max(0, min(5, self.state[0] + action[0]))
y = max(0, min(5, self.state[1] + action[1]))
self.state = np.array([x, y])
self.count += 1
dis = np.sqrt(np.sum(np.square(self.state - self.goal)))
reward = -1.0 if dis > self.distance_threshold else 0
if dis <= self.distance_threshold or self.count == 50:
done = True
else:
done = False
return np.hstack((self.state, self.goal)), reward, done
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim, action_bound):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.fc3 = torch.nn.Linear(hidden_dim, action_dim)
self.action_bound = action_bound # action_bound是环境可以接受的动作最大值
def forward(self, x):
x = F.relu(self.fc2(F.relu(self.fc1(x))))
return torch.tanh(self.fc3(x)) * self.action_bound
class QValueNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(QValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim + action_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.fc3 = torch.nn.Linear(hidden_dim, 1)
def forward(self, x, a):
cat = torch.cat([x, a], dim=1) # 拼接状态和动作
x = F.relu(self.fc2(F.relu(self.fc1(cat))))
return self.fc3(x)
class DDPG:
''' DDPG算法 '''
def __init__(self, state_dim, hidden_dim, action_dim, action_bound,
actor_lr, critic_lr, sigma, tau, gamma, device):
self.action_dim = action_dim
self.actor = PolicyNet(state_dim, hidden_dim, action_dim,
action_bound).to(device)
self.critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)
self.target_actor = PolicyNet(state_dim, hidden_dim, action_dim,
action_bound).to(device)
self.target_critic = QValueNet(state_dim, hidden_dim,
action_dim).to(device)
# 初始化目标价值网络并使其参数和价值网络一样
self.target_critic.load_state_dict(self.critic.state_dict())
# 初始化目标策略网络并使其参数和策略网络一样
self.target_actor.load_state_dict(self.actor.state_dict())
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),
lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(),
lr=critic_lr)
self.gamma = gamma
self.sigma = sigma # 高斯噪声的标准差,均值直接设为0
self.tau = tau # 目标网络软更新参数
self.action_bound = action_bound
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.actor(state).detach().cpu().numpy()[0]
# 给动作添加噪声,增加探索
action = action + self.sigma * np.random.randn(self.action_dim)
return action
def soft_update(self, net, target_net):
for param_target, param in zip(target_net.parameters(),
net.parameters()):
param_target.data.copy_(param_target.data * (1.0 - self.tau) +
param.data * self.tau)
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions'],
dtype=torch.float).to(self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
next_q_values = self.target_critic(next_states,
self.target_actor(next_states))
q_targets = rewards + self.gamma * next_q_values * (1 - dones)
# MSE损失函数
critic_loss = torch.mean(
F.mse_loss(self.critic(states, actions), q_targets))
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 策略网络就是为了使Q值最大化
actor_loss = -torch.mean(self.critic(states, self.actor(states)))
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
self.soft_update(self.actor, self.target_actor) # 软更新策略网络
self.soft_update(self.critic, self.target_critic) # 软更新价值网络
class Trajectory:
''' 用来记录一条完整轨迹 '''
def __init__(self, init_state):
self.states = [init_state]
self.actions = []
self.rewards = []
self.dones = []
self.length = 0
def store_step(self, action, state, reward, done):
self.actions.append(action)
self.states.append(state)
self.rewards.append(reward)
self.dones.append(done)
self.length += 1
class ReplayBuffer_Trajectory:
''' 存储轨迹的经验回放池 '''
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity)
def add_trajectory(self, trajectory):
self.buffer.append(trajectory)
def size(self):
return len(self.buffer)
def sample(self, batch_size, use_her, dis_threshold=0.15, her_ratio=0.8):
batch = dict(states=[],
actions=[],
next_states=[],
rewards=[],
dones=[])
for _ in range(batch_size):
traj = random.sample(self.buffer, 1)[0]
step_state = np.random.randint(traj.length)
state = traj.states[step_state]
next_state = traj.states[step_state + 1]
action = traj.actions[step_state]
reward = traj.rewards[step_state]
done = traj.dones[step_state]
if use_her and np.random.uniform() <= her_ratio:
step_goal = np.random.randint(step_state + 1, traj.length + 1)
goal = traj.states[step_goal][:2] # 使用HER算法的future方案设置目标
dis = np.sqrt(np.sum(np.square(next_state[:2] - goal)))
reward = -1.0 if dis > dis_threshold else 0
done = False if dis > dis_threshold else True
state = np.hstack((state[:2], goal))
next_state = np.hstack((next_state[:2], goal))
batch['states'].append(state)
batch['next_states'].append(next_state)
batch['actions'].append(action)
batch['rewards'].append(reward)
batch['dones'].append(done)
batch['states'] = np.array(batch['states'])
batch['next_states'] = np.array(batch['next_states'])
batch['actions'] = np.array(batch['actions'])
return batch
if __name__ == '__main__':
actor_lr = 1e-3
critic_lr = 1e-3
hidden_dim = 128
state_dim = 4
action_dim = 2
action_bound = 1
sigma = 0.1
tau = 0.005
gamma = 0.98
num_episodes = 2000
n_train = 20
batch_size = 256
minimal_episodes = 200
buffer_size = 10000
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
random.seed(0)
np.random.seed(0)
torch.manual_seed(0)
env = WorldEnv()
replay_buffer = ReplayBuffer_Trajectory(buffer_size)
agent = DDPG(state_dim, hidden_dim, action_dim, action_bound, actor_lr,
critic_lr, sigma, tau, gamma, device)
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
state = env.reset()
traj = Trajectory(state)
done = False
while not done:
action = agent.take_action(state)
state, reward, done = env.step(action)
episode_return += reward
traj.store_step(action, state, reward, done)
replay_buffer.add_trajectory(traj)
return_list.append(episode_return)
if replay_buffer.size() >= minimal_episodes:
for _ in range(n_train):
transition_dict = replay_buffer.sample(batch_size, True)
agent.update(transition_dict)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
episodes_list = list(range(len(return_list)))
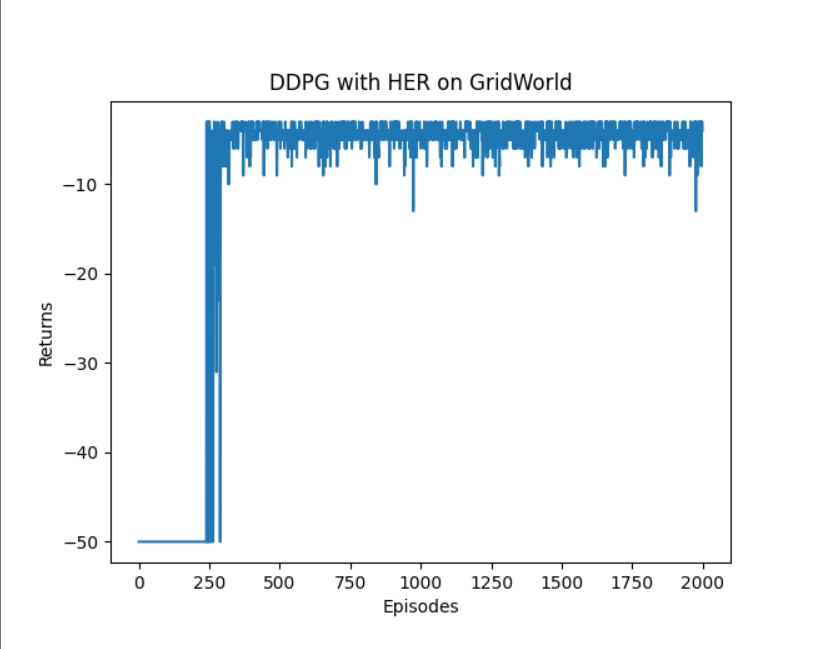
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DDPG with HER on {}'.format('GridWorld'))
plt.show()5、实验结果