两大法宝
将PyTorch比作一个工具箱
dir()函数:了解工具箱里有什么东西
实战
python
dir(torch.cuda)
Out[10]:
['Any',
'BFloat16Storage',
'BFloat16Tensor',
'BoolStorage',
...]help()函数:了解工具的用法和作用(注意help内函数去掉())
python
help(torch.cuda.is_available)
Help on function is_available in module torch.cuda:
is_available() -> bool
Return a bool indicating if CUDA is currently available.启动jupyter notebook时注意若pytorch位于D盘,进去jupyter notebook时要在后面加上D:
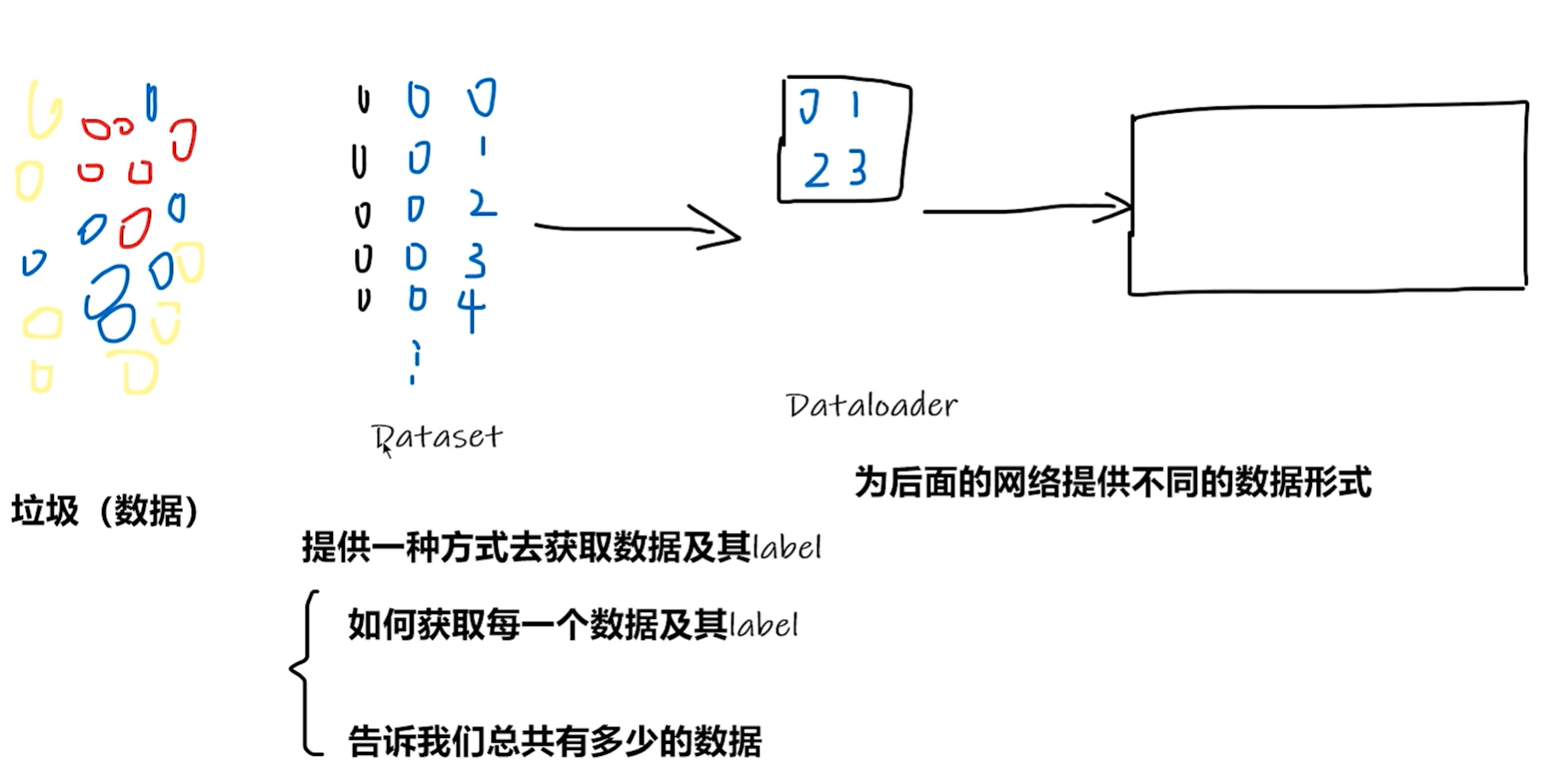
数据加载
pycharm项目终端安装opencv(然而视频并没有用到)
数据的一些读取方式
python
from PIL import Image
img_path = "D:\\PyTorch_learning\\dataset\\train\\ants\\0013035.jpg"
img = Image.open(img_path)
img.size
img.show()实战代码
from torch.utils.data import Dataset # 从PyTorch导入Dataset类,用于创建自定义数据集
from PIL import Image # 从PIL库导入Image类,用于处理图像
import os # 导入os模块,用于处理文件路径
class MyData(Dataset): # 定义一个名为MyData的类,继承自Dataset
def __init__(self, root_dir, label_dir): # 初始化方法,接收两个参数:根目录和标签目录
self.root_dir = root_dir # 保存根目录到类的实例变量
self.label_dir = label_dir # 保存标签目录到类的实例变量
self.path = os.path.join(self.root_dir, self.label_dir) # 拼接根目录和标签目录,得到完整路径
self.img_path = os.listdir(self.path) # 获取该路径下所有文件的列表,保存为图像路径列表
def __getitem__(self, idx): # 定义获取元素的方法,接收索引idx作为参数
img_name = self.img_path[idx] # 根据索引获取图像文件名
# 拼接完整的图像文件路径
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path) # 打开图像文件,得到图像对象
label = self.label_dir # 标签就是当前的标签目录名(ants或bees)
return img, label # 返回图像和对应的标签
def __len__(self): # 定义获取数据集长度的方法
return len(self.img_path) # 返回图像路径列表的长度,即图像的数量
root_dir = "dataset/train" # 定义根目录路径:数据集的训练集目录
ants_label_dir = "ants" # 定义蚂蚁图像的标签目录名
bees_label_dir = "bees" # 定义蜜蜂图像的标签目录名
ants_dataset = MyData(root_dir, ants_label_dir) # 创建蚂蚁数据集实例
bees_dataset = MyData(root_dir, bees_label_dir) # 创建蜜蜂数据集实例
train_dataset = ants_dataset + bees_dataset # 将蚂蚁和蜜蜂数据集合并成一个训练数据集
img, label = train_dataset[123]
img.show() # 展示蚂蚁图片
print(label)
img, label = train_dataset[124]
img.show() # 展示蜜蜂图片
print(label)