一、Java内存模型(JMM)
JMM(Java Memory Model,Java 内存模型)是 Java 虚拟机规范中定义的一种抽象概念,用于规范 Java 程序中多线程对共享内存的访问规则,解决可见性、原子性和有序性问题,确保 Java 程序在不同硬件和操作系统上都能获得一致的并发行为。
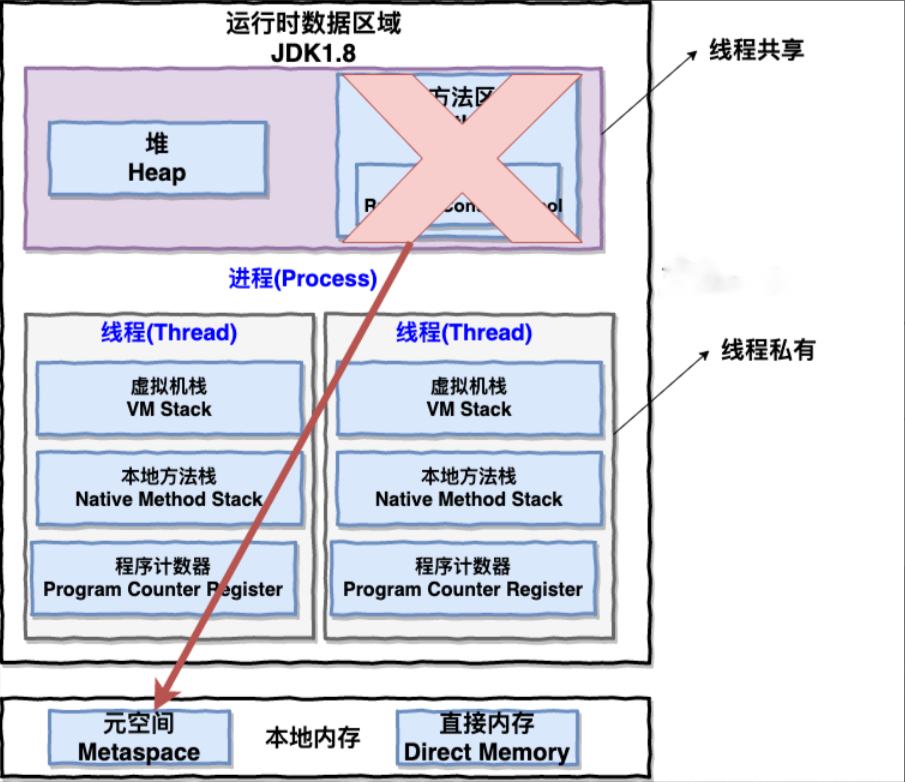
运行时数据区划分
线程私有:程序计数器、本地方法栈、虚拟机栈
线程公有:堆、元空间
程序计数器
字节码解释器在解释执行字节码文件工作时,当需要需要执行一条字节码指令时,可以通过改变程序计数器的值来完成。
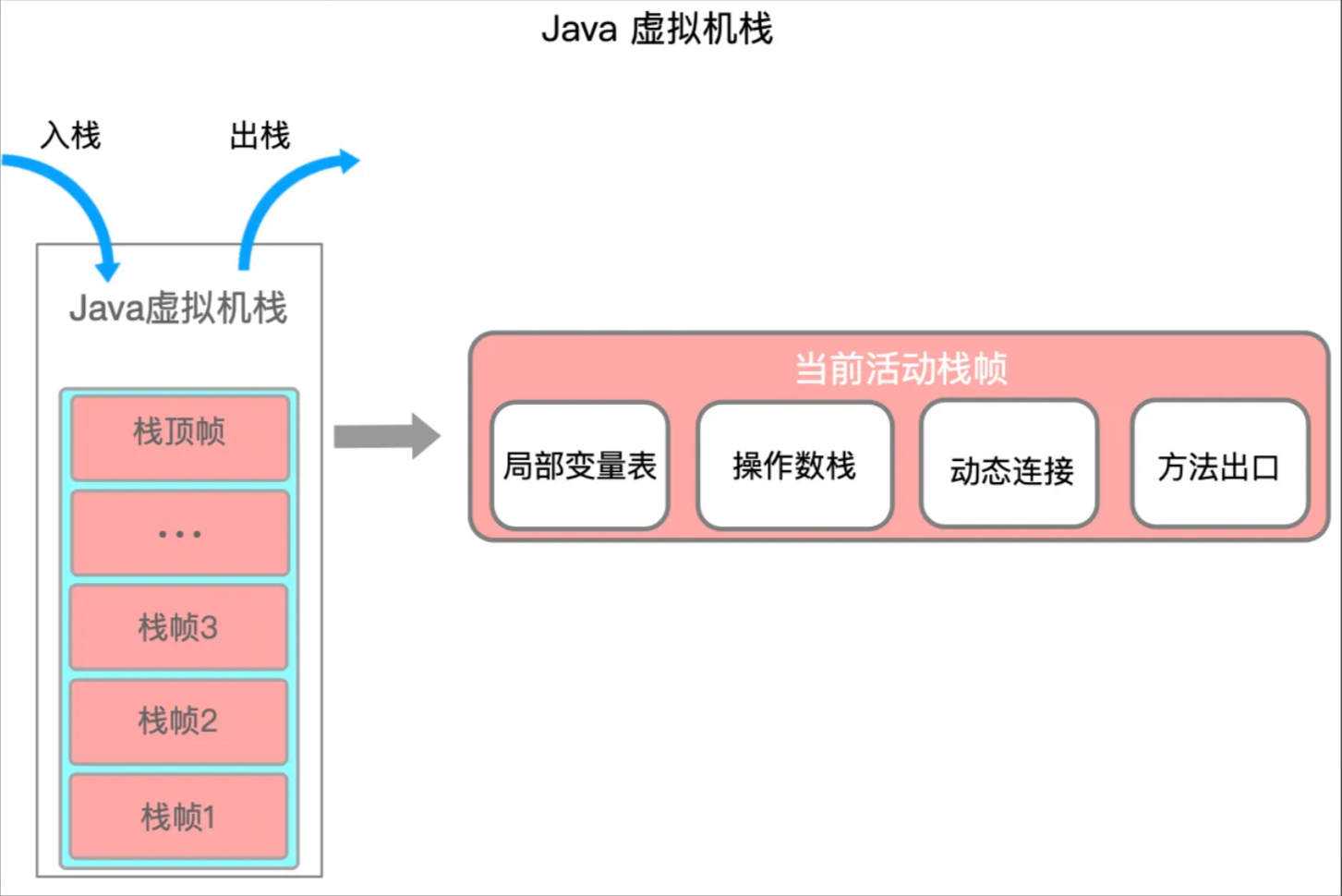
虚拟机栈
虚拟机栈是由一个个栈帧组成,而每个栈帧中都有:局部变量、操作数栈、动态链接、方法出口信息。每个方法调用时都会入栈,每个方法被调用结束后则会出栈,这样可以清楚的看出方法之间的调用关系。
本地方法栈
native关键字修饰的本地方法被执行时候,在本地方法栈中创建一个栈帧,用于存放发native本地方法的局部变量、操作数栈、动态链接、方法出口信息。方法执行完毕后,栈帧会释放空间。
堆(Heap)
用于存放对象实例和数组的内存区域。
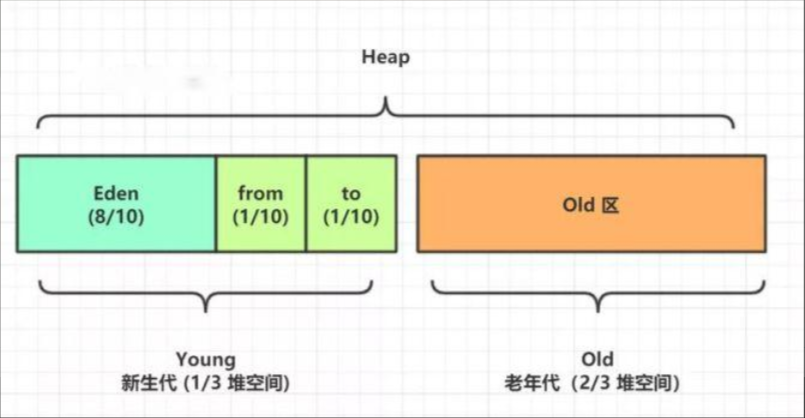
1、新生代、老年代
由于垃圾回收的需要,避免频繁GC所以将堆分为新生代和老年代,其中新生代占1/3,老年代占2/3。而新生代又被分为Eden 和Survivor区(from、to),占比为8:1:1。
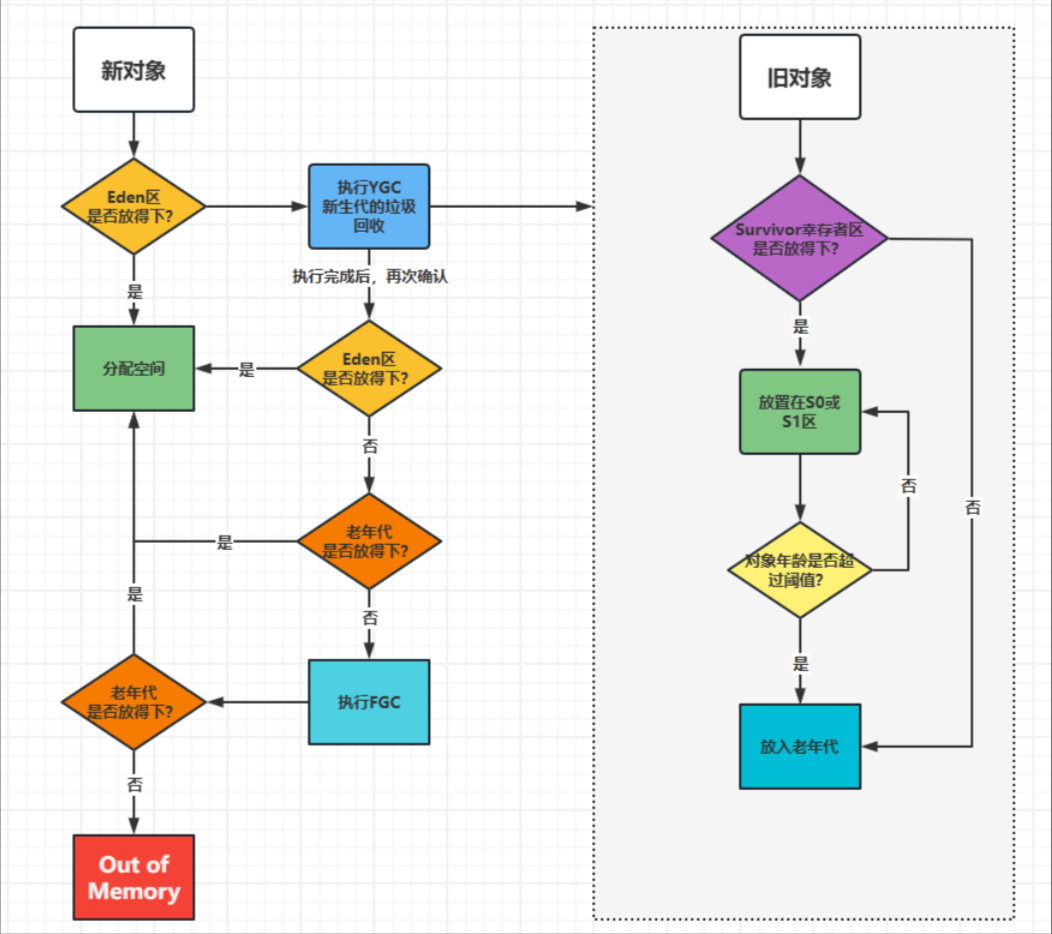
2、对象创建时的内存分配
当创建一个新对象时会先看Eden区有没有空间进行存储,若没有则执行YGC, 执行后若还不能放下则看老年区是否可以放下,如果老年区不能放下,则执行老年区的FGC ,执行后如果还不能不能放下,则会抛出OOM异常。
二、GC垃圾回收器
判读对象是否存活
1、引用计数算法
在对象中添加一个引用计数器,如果对象被引用则+1,如果失去引用则-1,当我们需要判断对象是否存活时,只需看该计算器的值是否为0。该方法不用于java中。
缺点:可能会出现循环引用的情况,从而出现死锁。也就是a引用了b,b也引用了a。
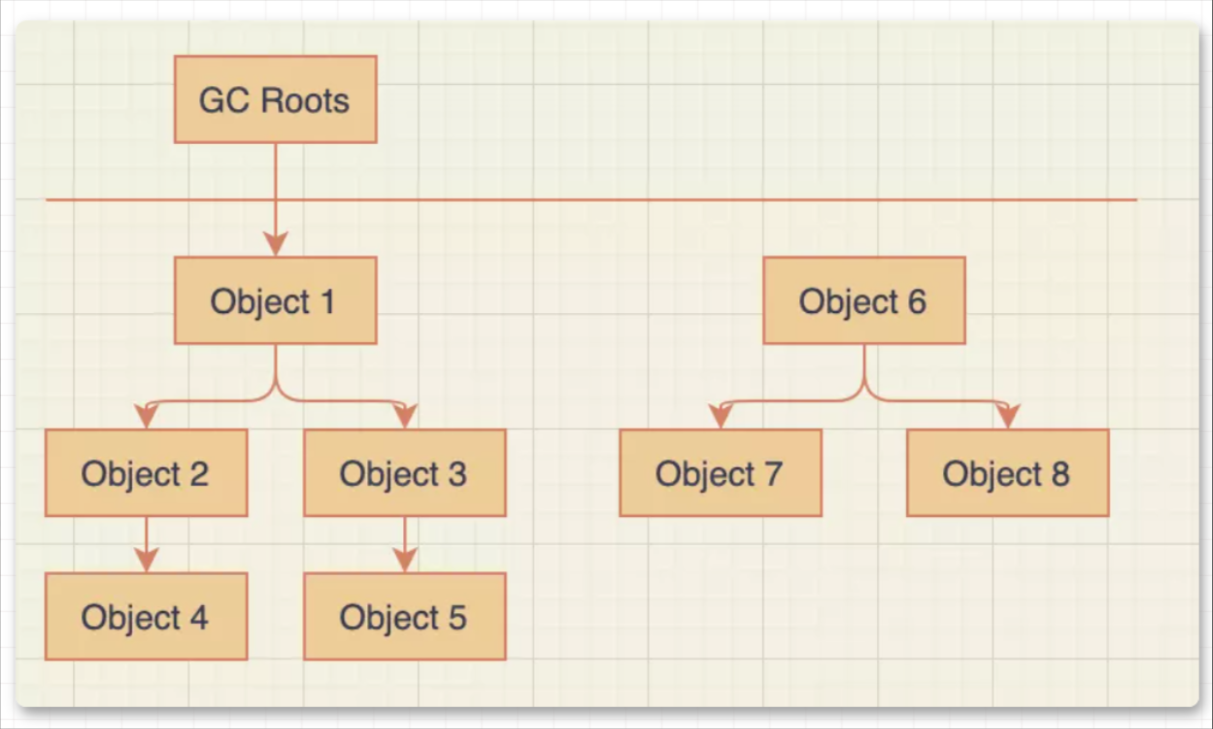
2、可达性分析算法
通过定义一系列的" GC Roots "的根结点来作为开始结点集,当需要判断对象是否存活时,则从根结点向下遍历,没有被遍历到的则是可以被回收的垃圾对象。该方法用于java中。
3、java中四种引用类型
- 强引用
最常见的引用类型,直接通过 new 关键字创建的对象引用。
java
// 强引用
Object object = new Object();强引用它永远不会被GC回收,当我们需要他被回收时,我们可以对其进行弱化。
java
// 弱化
object = null;- 软引用
该引用类型可以根据内存的大小来判断是否进行GC回收,当内存充足时不进行回收,当内存不足时进行回收。
java
// 软引用
SoftReference<Object> softRef = new SoftReference<>(new Object());
Object obj = softRef.get(); // 获取软引用指向的对象- 弱引用
该引用类型无论是否内存充足只要发生GC就会被回收。例如:ThreadLocal中应用了弱引用
如果不使用对象后没有及时进行销毁,当发生GC时就会出现大量的null-value的键值对,从而导致发生OOM。
java
// 弱引用
WeakReference<Object> weakRef = new WeakReference<>(new Object());
Object obj = weakRef.get(); // 获取弱引用指向的对象- 虚引用
虚引用主要用来跟踪对象被垃圾回收的活动,可以在垃圾收集时收到一个系统通知。
java
// 虚引用
ReferenceQueue<Object> queue = new ReferenceQueue<>();
PhantomReference<Object> phantomRef = new PhantomReference<>(new Object(), queue);垃圾回收算法
复制算法
将内存空间划分为 两个相等的区域(如 From 空间和 To 空间),每次只使用其中一个区域:
- 当该区域内存用完时,将存活对象复制到另一个区域。
- 清空原区域的所有内存,完成垃圾回收。
缺点:
- 内存利用率低:需要预留一半内存空间,实际可用内存仅为总空间的 50%。
- 当存活对象较多时,复制成本高。
标记---清除算法
主要分两个阶段进行:
- 标记阶段:从根对象(如栈变量、静态变量)出发,遍历所有可达对象,并标记为 "存活"。
- 清除阶段:扫描整个堆内存,将未被标记的对象(即垃圾)回收,并释放其占用的内存空间。
缺点:
- 内存碎片化:回收后会产生大量不连续的内存碎片,可能导致后续无法分配大对象。
- 效率较低:需要遍历两次内存(标记和清除)。
标记---整理算法
主要分两个阶段进行:
- 标记阶段:同标记 - 清除算法,标记所有存活对象。
- 整理阶段:将所有存活对象向内存一端移动,然后直接清理边界外的所有内存(即垃圾对象占用的空间)。
缺点:
- 性能开销大:需要移动对象,涉及内存复制,成本较高。
总结:由于不同算法的逻辑有所不同,所以他们的用处也有所不同。由于在新生代中的对象总是朝生夕灭,所以通常我们会使用复制算法进行垃圾回收;而老年代中的对象可以长期存活,所以我们通常适用标记---整理和标记清除算法。
垃圾收集器
Serial收集器(新生代)
该收集器主要对新生代的垃圾进行收集清理,采用" 复制"算法进行实现。
Serial Old收集器(老年代)
该收集器主要对老年代的垃圾进行收集清理,采用" 标记---整理"算法进行实现。
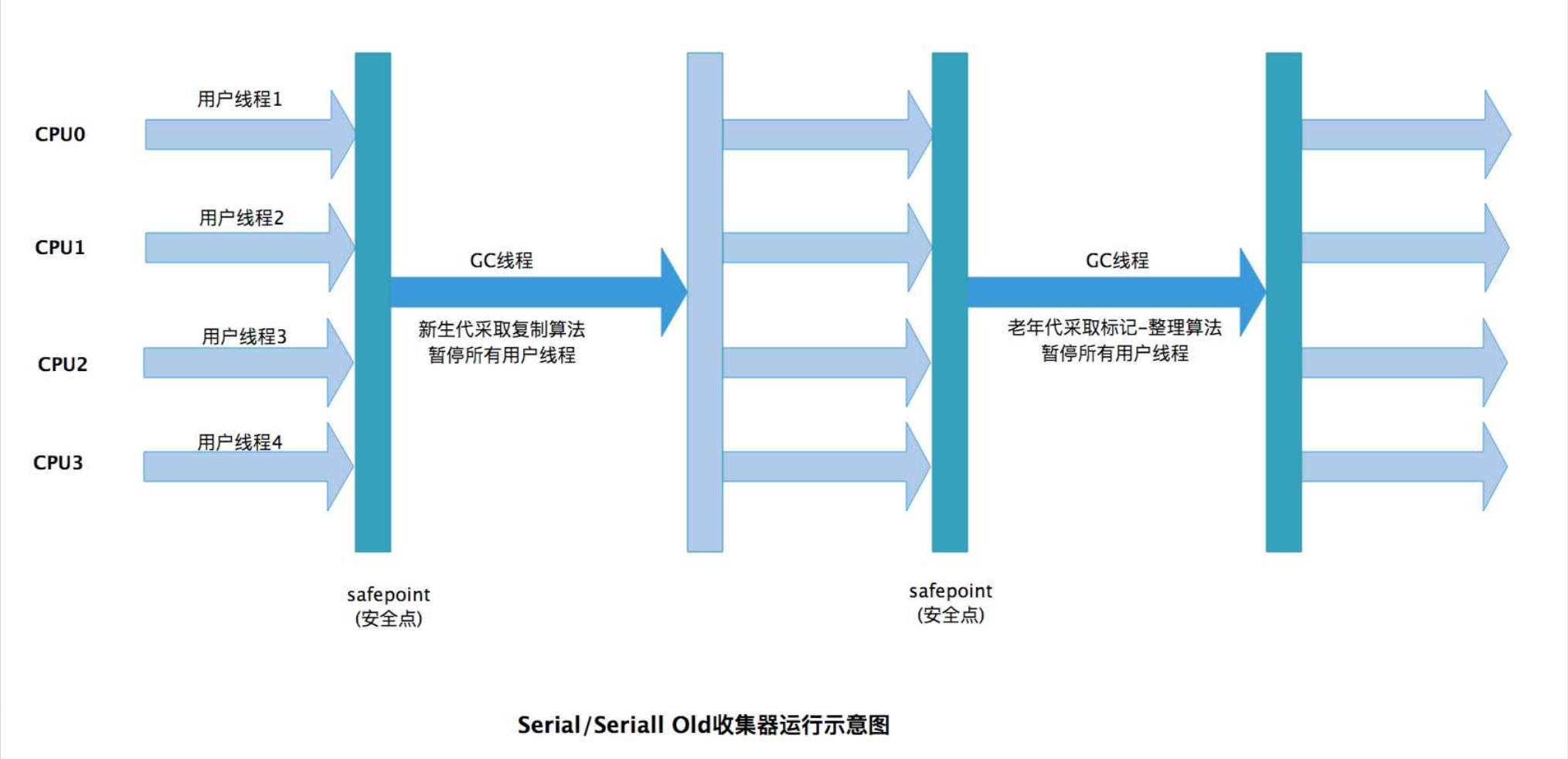
他们两个是串行收集器,也可以理解为单线程收集器,但在进行GC时会发生STW所以现在一般不使用。
Parallel Scavenge收集器(新生代)
该收集器主要对新生代的垃圾进行收集清理,采用" 复制"算法进行实现。
Parallel Old收集器(老年代)
该收集器主要对老年代的垃圾进行收集清理,采用" 标记---整理"算法进行实现。
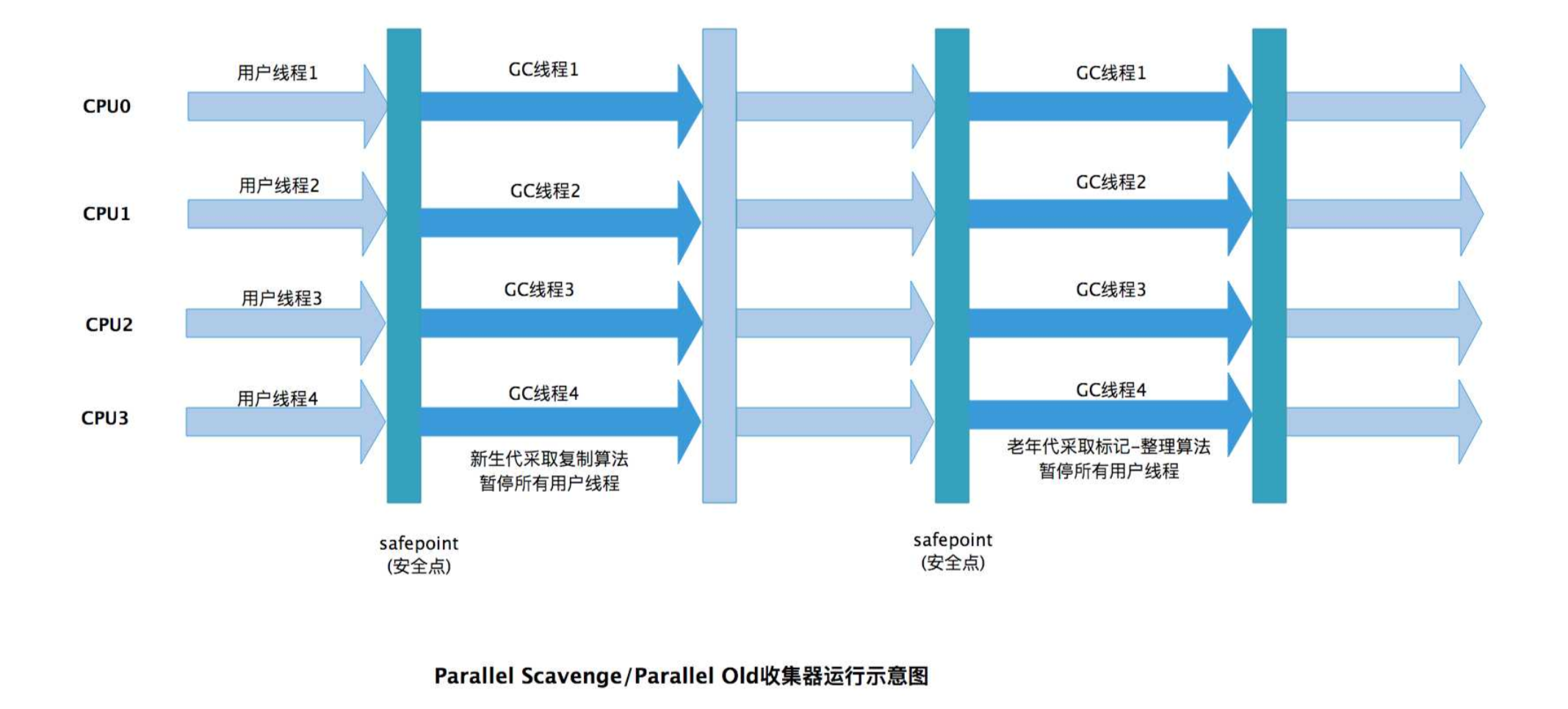
他们两个是多线程收集器,但在进行GC时会发生STW,但相对于前面性能会好很多。但是该收集器主要强调系统的吞吐量,所以会很容易出现系统上线后,内存占用过高的情况。
CMS收集器(老年代)
该收集器是一个基于" 标记---清除 "算法实现,是一种获取最短回收停顿(STW)为目标的收集器,它可以实现让收集线程和用户线程并发。
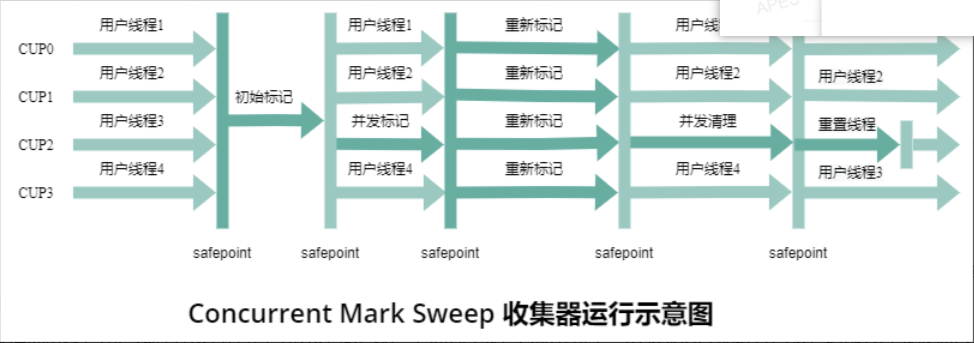
CMS 的执行过程分为四个主要阶段:
-
初始标记(Initial Mark, STW): 通过 GC Roots标记直接关联到根对象的存活对象。
-
**并发标记(Concurrent Mark):**与应用线程并发执行,遍历所有可达对象并标记存活对象。
-
**重新标记(Remark, STW):**修正并发标记期间因应用线程修改引用导致的标记错误。
-
并发清除(Concurrent Sweep) 特点:无需暂停,但可能产生 "浮动垃圾"(即在清除阶段新产生的垃圾,需等到下一次 GC 处理)。
由于该 标记---清除 算法所以会产生大量的内存空间碎片导致,空间的浪费;而且在并发清除的时候可能会产生浮动垃圾。
G1收集器(老年代)
该搜集器主要针对大内存的机器,它采用局部性的收集思想将一块大内存划分为若干大小相同的独立区域(Region),再讲这些独立的区域收集成一个回收集合,再进行处理。
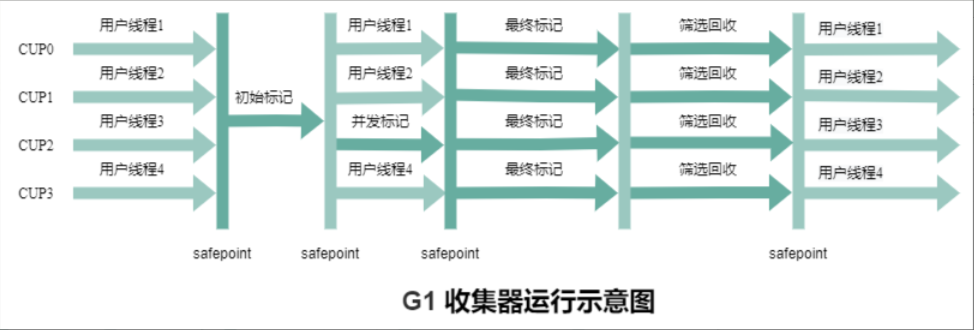
G1 的垃圾回收周期主要分为以下阶段:
-
初始标记(Initial Mark, STW): 通过 GC Roots标记直接关联到根对象的存活对象。
-
**并发标记(Concurrent Marking):**与应用线程并发执行,遍历所有可达对象并标记存活对象。
-
**最终标记(Final Mark, STW):**处理并发标记期间的引用变化(即未被标记的新对象),完成标记过程。
-
**筛选回收(Cleanup and Evacuation, STW):**根据 Region 的回收价值(垃圾占比)排序,选择部分 Region 进行回收。