文章目录
- 每日一句正能量
- [第五章 HBase分布式数据库](#第五章 HBase分布式数据库)
- 章节概要
- [5.4 深入学习HBase原理](#5.4 深入学习HBase原理)
-
- [5.4.1 HBase架构](#5.4.1 HBase架构)
- [5.4.2 物理存储](#5.4.2 物理存储)
- [5.4.3 寻址机制](#5.4.3 寻址机制)
- [5.4.4 HBase读写数据流程](#5.4.4 HBase读写数据流程)

每日一句正能量
当人循着一条山路走时,只消走错一步就会滚下山坡。一种精神"学说"的基本目的,就是永远处在高度的警惕之中。注意力和机警,就是精神生活帮助我们开发的基本品质。理想的境界乃是同时完善地既宁静又警觉。
第五章 HBase分布式数据库
章节概要
Spark计算框架是如何在分布式环境下对数据处理后的结果进行随机的、实时的存储呢?HBase数据库正是为了解决这种问题而应用而生。HBase数据库不同于一般的数据库,如MySQL数据库和Oracle数据库是基于行进行数据的存储,而HBase则是基于列进行数据的存储,这样的话,HBase就可以随着存储数据的不断增加而实时动态的增加列,从而满足Spark计算框架可以实时的将处理好的数据存储到HBase数据库中的需求。本章将针对HBase分布式数据库的相关知识进行详细讲解。
5.4 深入学习HBase原理
5.4.1 HBase架构
HBase构建在Hadoop HDFS之上,Hadoop HDFS为HBase提供了高可靠的底层存储支持,Hadoop MapReduce为HBase提供高性能的计算能力,Zookeeper为HBase提供稳定服务和容错机制。下面通过一张图介绍一下HBase的整体架构,HBase的整体架构具体如图5-10所示。
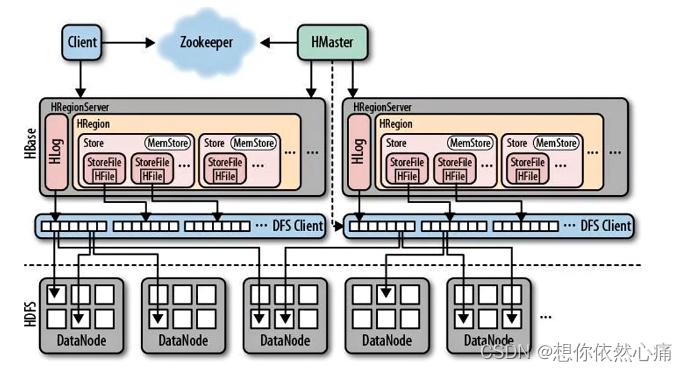
图5-10 HBase架构
在图中,HBase含有多个组件。下面,针对HBase架构中的核心组件进行详细介绍,具体如下:
- Client
即客户端,它通过RPC协议与HBase通信。 - Zookeeper
即分布式协调服务,在HBase集群中的主要作用是监控HRegionServer的状态,将HRegionServer的上下线信息实时通知给HMaster,确保集群中只有一个HMaster在工作 - HMaster
即HBase的主节点,用于协调多个HRegion Server,主要用于监控HRegion Server的状态以及平衡HRegion Server之间的负载。除此之外,HMaster还负责为HRegion Server分配HRegion。
在HBase中,如果有多个HMaster节点共存,提供服务的只有一个Master,其他的Master处于待命的状态。如果当前提供服务的HMaster节点宕机,那么其他的HMaster会接管HBase的集群。
- HRegion Server
即HBase的从节点,它包括了多个HRegion,主要用于响应用户的I/O请求,向HDFS文件系统读写数据。 - HRegion
即HBase表的分片,每个Region中保存的是HBase表中某段连续的数据。 - Store
每一个HRegion包含一或多个Store。每个Store用于管理一个Region上的一个列族。 - MemStore
即内存级缓存,MemStore 存放在store中的,用于保存修改的数据(即KeyValues形式)。当MemStore存储的数据达到一个阀值(默认128MB)时,数据就会被进行flush操作,将数据写入到StoreFile文件。MemStore的flush操作是由专门的线程负责的。 - StoreFile
MemStore中的数据写到文件后就是StoreFile,StoreFile底层是以HFile文件的格式保存在HDFS上。 - HFile
即HBase中键值对类型的数据均以HFile文件格式进行存储。 - HLog
即预写日志文件,负责记录HBase修改。当HBase读写数据时,数据不是直接写进磁盘,而是会在内存中保留一段时间。
5.4.2 物理存储
HBase分布式数据库最重要的就是存储数据,下面, 从四个方面详细介绍HBase的物理存储。
1 Region在行方向上的存储方式
HBase表的数据按照行键RowKey的字典序进行排列,并且切分多个HRegion存储,存储方式如图5-11所示。
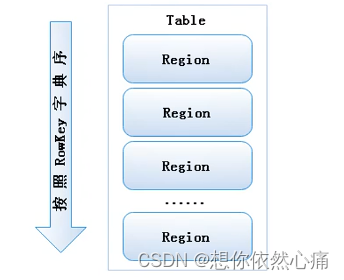
图5-11 Region在行方向上的存储
2 HRegion的切分方式
每个Region存 储的数据是有限的,如果当Region增大到一个阀值(128) 时,会被等分切成两个新的Region切分方式如图5-12所示。
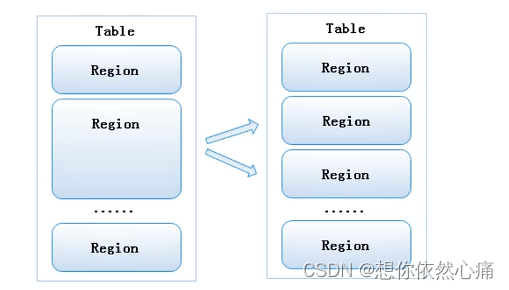
图5-12 HRegion的切分
3 HRegion的分布方式
一个HRegion Server上可以存储多个Region,但是每个Region只能被分布到一个HRegion Server上,分布方式如图5-13所示。
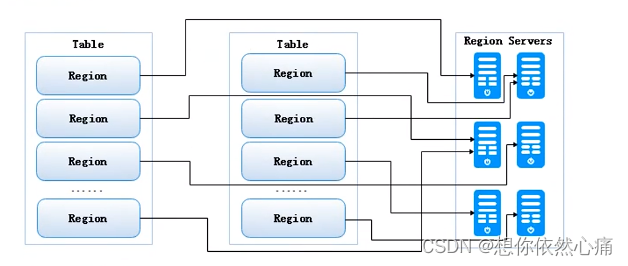
图5-13 HRegion的分布方式
4 HBase表的存储方式
MemStore中存储的是用户写入的数据,一旦MemStore存储达到阈值时,里面存储的数据就会被刷新到新生成的StoreFile中(底层是HFile),该文件是以HFile的格式存储到HDFS上,具体存储方式如图5-14所示。
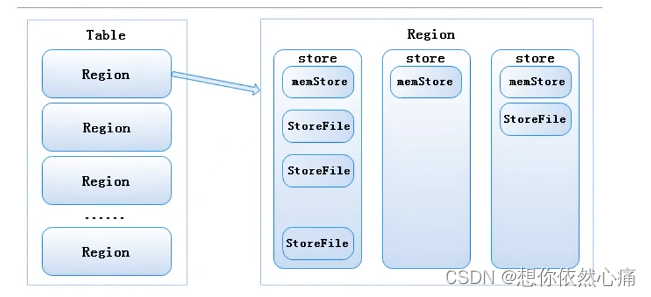
图5-14 HBase表的存储方式
5.4.3 寻址机制
当HBase表查询数据遵循的是寻址机制,接下来,通过一张图来学习一下HBase的寻址机制,具体如图5-15所示。
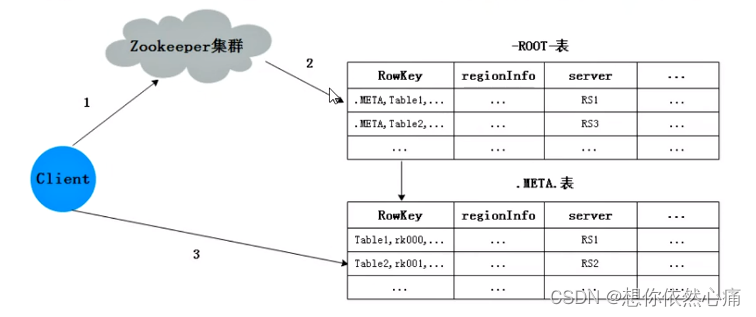
图5-15
在图中,Zookeeper中存储的是ROOT表的数据,而ROOT表中存储的是META表的Region信息,也就是所有RegionServer的地址。接下来,分步骤介绍Hbase的寻址流程,具体如下:
- Client访问ZooKeeper请求行键rk001数据所在RegionServer地址。
- Zookeeper从 --ROOT-表中查询所有表的.MATA.信息。
- META.表将具体存储行键rk001数据的RegionServer的地址返回给Client,相当于Client是从Zookeeper中.MATA.表中查询的RegionServer的地址;
- Client获取到地址后,向该RegionServer发送查询行键为rk001这条数据请求,RegionServer收到请求,就查询行键rk001的Region。
- RegionServer将行键为rk001这条数据的所有信息返回给Client。
在HBase中,有两个比较特殊的表,分别是"-ROOT-"表和".META."表。其中,"-ROOT-"表只有一个Region,且不会进行切分;而".META."表中存储着RegionServer,且RegionServer还可以被切分成多个Region。
5.4.4 HBase读写数据流程
据库最常见的操作就是读写数据,接下来,针对HBase读写数据的流程进行详细介绍。
- 读数据流程
从HBase中读数据的流程其实就是寻址的流程,具体流程如下:
- Client通过ZooKeeper、"-ROOT-"表及".META."表来找到目标数据所在的RegionServer地址(即目标数据所在Region的服务器地址);
- Client通过请求RegionServer地址来查询目标数据;
- RegionServer定位到目标数据所在的Region,然后发出查询目标数据的请求;
- Region先在MemStore中查找目标数据,若查找到则返回;若查找不到,则继续在StoreFile中查找。
- 写数据流程
即存储数据,从客户端把目标数据存储到服务器上。具体流程如下:
- Client根据行键RowKey找到对应的Region所在的RegionServer;
- Client向RegionServer发送提交写入数据的请求;
- RegionServer找到目标Region;
- Region检查数据是否与Schema一致;
- 若Client没有指定版本,则获取当前系统的时间作为数据版本;
- 将更新的记录写入预写日志HLog和MemStore中;
- 判断 MemStore是否已满,若满则进行flush操作,将数据写入StoreFile文件,反之,则直接将数据存入MemStore。
转载自:https://blog.csdn.net/u014727709/article/details/147264031
欢迎 👍点赞✍评论⭐收藏,欢迎指正