背景介绍
作为医学大模型应用领域的从业者,我持续关注行业最新进展。近期,微软发布的一篇论文 Sequential Diagnosis with Language Models 在医学大模型领域引起了广泛关注。微软在该论文中构建了一个名为 MAI-DxO 的 Agent 应用,在复杂病例诊断方面取得了显著突破。
根据论文数据,MAI-DxO 的诊断准确性达到 85.5%,而人类全科医生的诊断准确性仅为 20% 左右。从表面数据来看,这似乎是一场全方位的碾压。下图中红色点位代表人类医生的平均水平,直观地展现了这一差距。
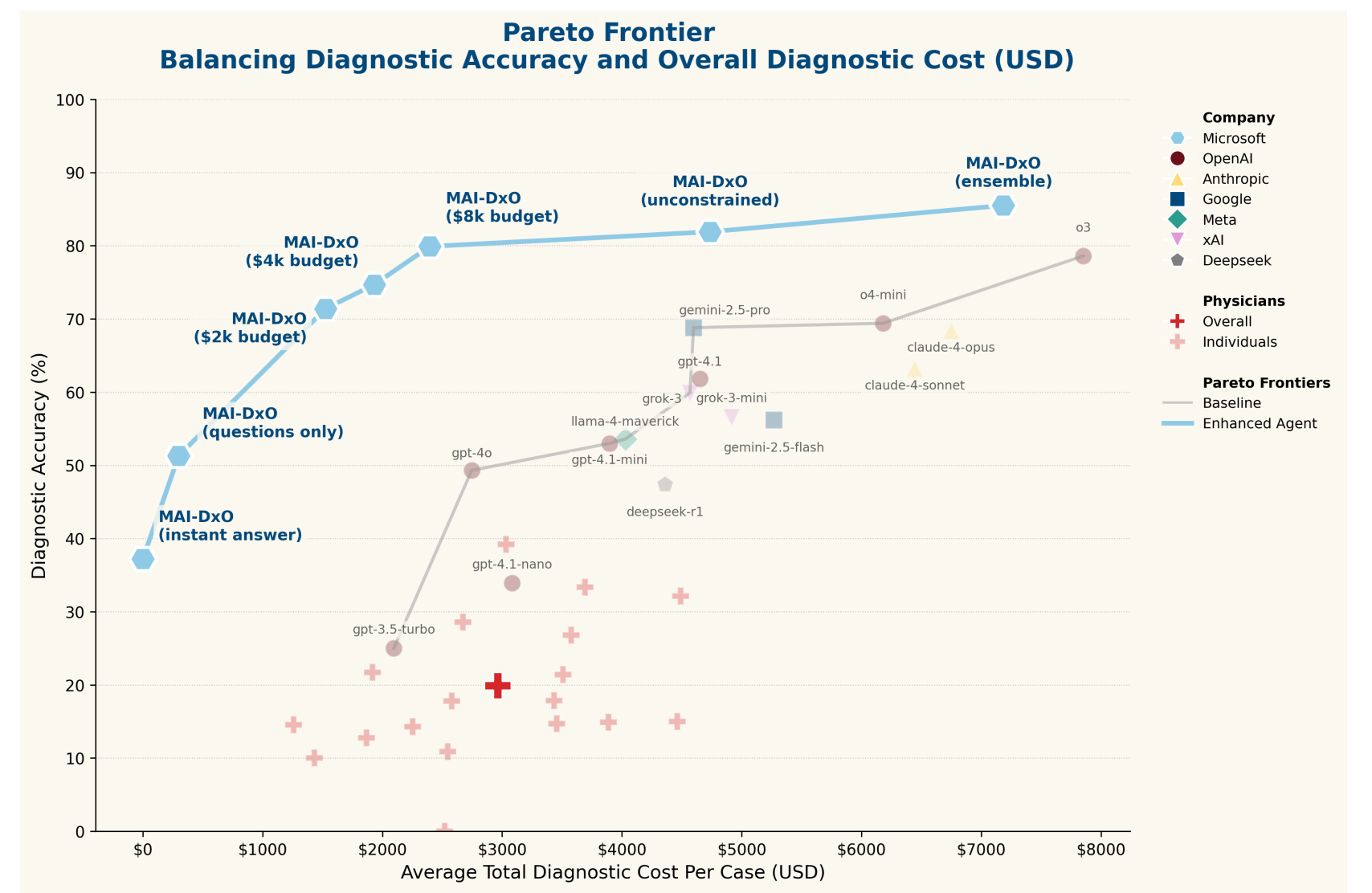
然而,真实情况究竟如何?本文将结合论文内容及具体代码实现,从医学专业视角深入分析 MAI-DxO 的技术方案。
基准测试设计
在深入分析具体方案之前,有必要先了解论文中的测试设计,这也是该研究的一个独特亮点。传统的医学大模型评测往往将复杂病例进行精心包装,包含主诉、现病史、关键检查结果等要素,然后要求模型从预定义的诊断结果列表中选择正确答案。虽然这种测试能够验证大模型的医学推理能力,但与真实临床诊疗流程存在较大差异。
微软在这项研究中引入了一种更贴近真实临床的测试方案------SDBench。这是一个通过真实序贯临床诊疗来评估诊断代理(人类或人工智能)的交互式框架。SDBench 将 304 例来自《新英格兰医学杂志》(NEJM) 临床病理学会议 (CPC) 的病例重新构建为分步诊断流程,其中诊断 Agent 需要自主决定提出哪些问题、安排哪些检查,并自主确定何时做出最终诊断。具体形式如下所示:
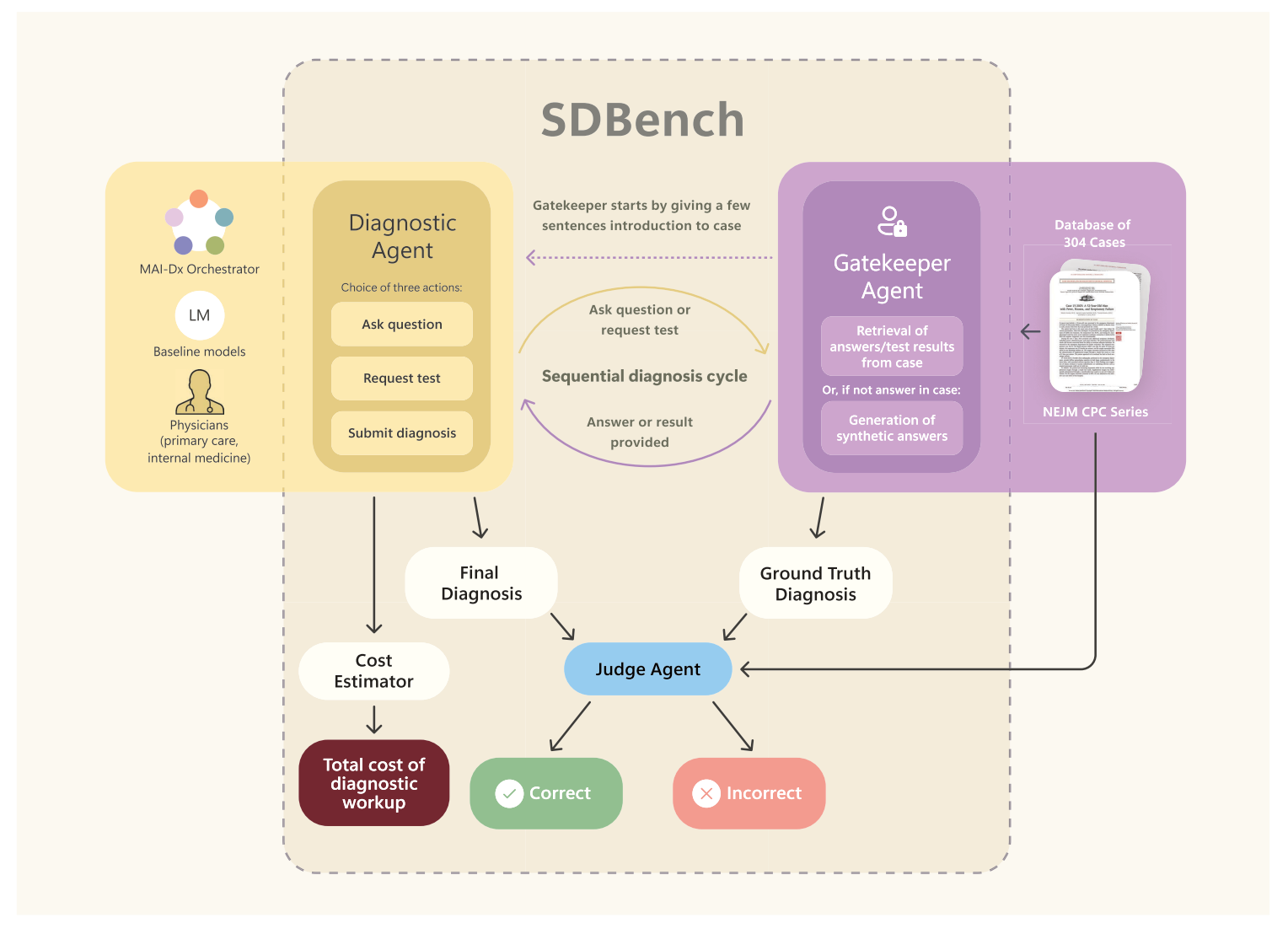
在实际测试中,研究团队构建了一个 GateKeeper Agent,该 Agent 根据真实病例数据对诊断 Agent 提出的问题做出响应。例如,当诊断 Agent 要求进行血常规检查时,GateKeeper Agent 会返回真实病例中的血常规检查结果,从而实现无需人工干预的完整自动化评估。
在单个病例测试中,诊断 Agent 首先接收一段简化的病例主诉信息,随后需要做出判断,决定下一步进行哪些检查,并根据检查结果进行下一轮决策------可以要求继续进行检查,或认为信息充分而给出最终诊断。
技术方案详解
下面详细介绍 MAI-DxO 的具体技术实现。整体方案采用现有模型,通过多 Agent 框架编排,构建完整的诊断服务。
方案架构概述
论文中对具体诊疗方案的介绍相对简洁,主要体现在以下架构图中:
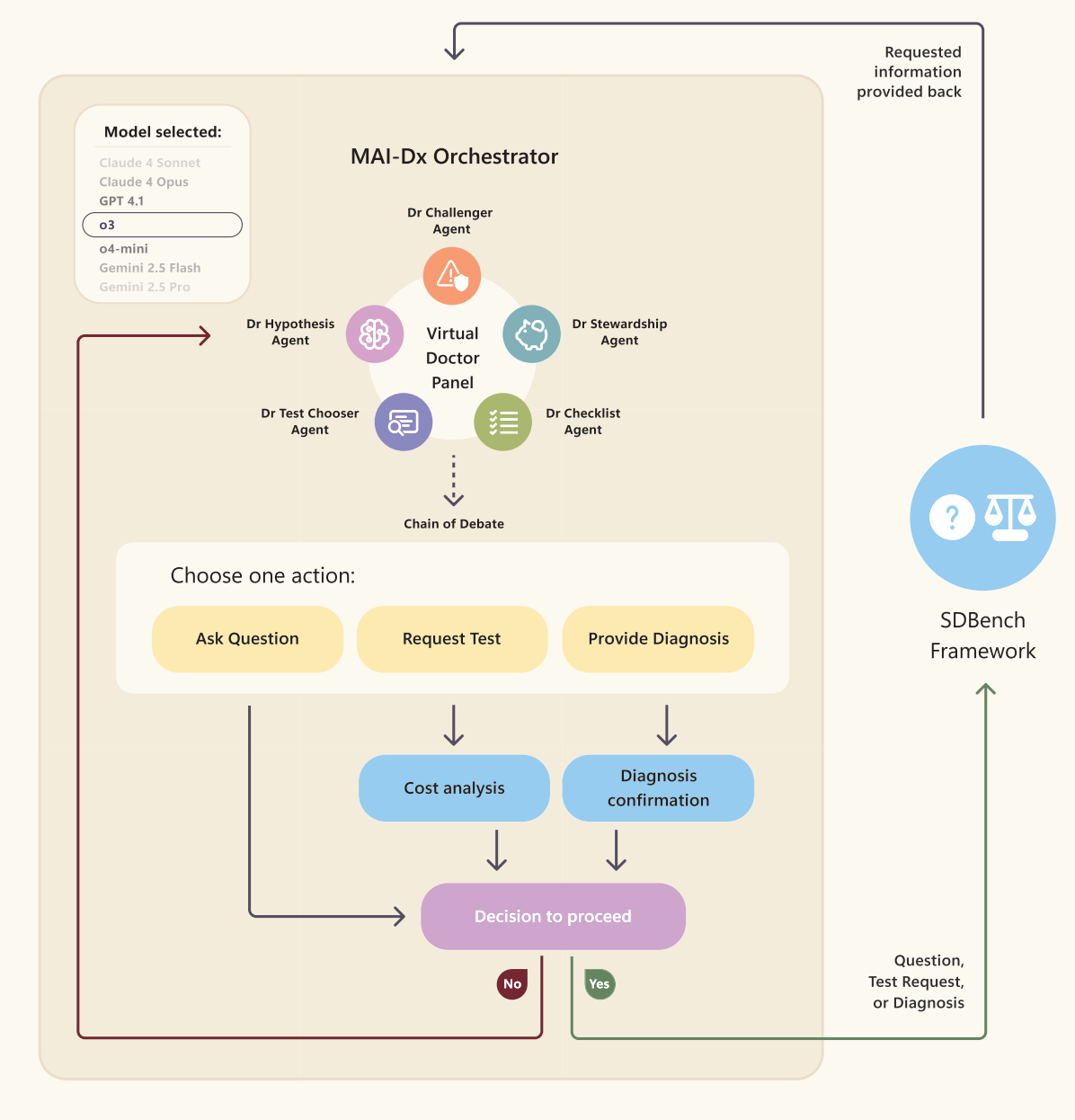
该方案主要由五种不同类型的医学角色构建虚拟诊疗小组,各角色协同完成整个诊疗过程。这种角色设计在一定程度上模拟了真实诊疗流程,有助于减轻个体认知偏差并最大化降低医疗成本。具体角色分工如下:
- Dr Hypothesis Agent:维护基于概率排序的鉴别诊断,列出最有可能的三种情况,并在每次发现新情况后以贝叶斯方式更新概率。
- Dr Test Chooser Agent:每轮最多选择三个诊断检查,最大限度地区分不同的鉴别诊断。
- Dr Challenger Agent:充当质疑者角色,识别潜在的锚定偏差,强调相互矛盾的证据,并提出可能推翻当前主诊断的检查。
- Dr Stewardship Agent:在诊断结果相同的情况下,提出更经济的替代方案,并否决低收益的昂贵测试,从而强制推行注重成本效益的检查。
- Dr Checklist Agent:执行静默质量控制,确保模型生成有效的检查名称,并在整个小组的推理中保持内部一致性。
在医学小组给出相应处理后,最后会经历一轮综合性的辩论(论文中称为 Chain of Debate)达成最终共识,确定下一步行动------可以选择提出问题(模拟询问患者沟通)、安排检查(模拟医生开检查单)或做出诊断(如果确定性超过阈值)。
技术实现细节
目前官方尚未开源完整代码,但开源社区已有一个基于 Swarm 的实现 Open-MAI-Dx-Orchestrator,可以参考该项目了解 MAI-DxO 的基本实现思路。
整体流程设计
从现有代码实现可以看出,整个系统采用多轮 Agent 协作模式。在每轮处理中,首先由小组讨论确定下一步行动,然后与 Gatekeeper Agent 进行交互获取必要信息,直至最终得出诊断结果:
python
def run(self, initial_case_info: str, full_case_details: str, ground_truth_diagnosis: str):
final_diagnosis = None
for i in range(self.max_iterations):
# 小组讨论确定下一步行动
action = self._run_panel_deliberation(case_state)
if action.action_type == "diagnose":
final_diagnosis = action.content
break
# 与 Gatekeeper Agent 进行交互,获取必要信息
response = self._interact_with_gatekeeper(
action, full_case_details
)
# 最终诊断评分
judgement = self._judge_diagnosis(
final_diagnosis, ground_truth_diagnosis
)单轮处理流程
在单轮处理中,主要是上述五种角色的 Agent 针对当前病例进行针对性处理。与原始论文略有不同的是,实现中构建了一个共识协调员 Agent,用于汇总不同 Agent 的信息并给出最终的下一步行动,充当上述综合性辩论(Chain of Debate)的作用。具体实现如下:
python
def _run_panel_deliberation(self, case_state: CaseState) -> Action:
# Dr Hypothesis Agent:维护基于概率排序的鉴别诊断
hypothesis_prompt = self._get_prompt_for_role(AgentRole.HYPOTHESIS, case_state) + "\n\n" + base_context
hypothesis_response = self._safe_agent_run(
self.agents[AgentRole.HYPOTHESIS], hypothesis_prompt, agent_role=AgentRole.HYPOTHESIS
)
self._update_differential_from_hypothesis(case_state, hypothesis_response)
if hasattr(hypothesis_response, 'content'):
deliberation_state.hypothesis_analysis = hypothesis_response.content
else:
deliberation_state.hypothesis_analysis = str(hypothesis_response)
# Dr. Test-Chooser Agent:选择最优的诊断检查
test_chooser_prompt = self._get_prompt_for_role(AgentRole.TEST_CHOOSER, case_state) + "\n\n" + base_context
if self.mode == "question_only":
test_chooser_prompt += "\n\nIMPORTANT: This is QUESTION-ONLY mode. You may ONLY recommend patient questions, not diagnostic tests."
deliberation_state.test_chooser_analysis = self._safe_agent_run(
self.agents[AgentRole.TEST_CHOOSER], test_chooser_prompt, agent_role=AgentRole.TEST_CHOOSER
)
# Dr. Challenger Agent:充当质疑者,识别潜在的锚定偏差,强调相互矛盾的证据,并提出可能推翻当前主诊断的检查
challenger_prompt = self._get_prompt_for_role(AgentRole.CHALLENGER, case_state) + "\n\n" + base_context
deliberation_state.challenger_analysis = self._safe_agent_run(
self.agents[AgentRole.CHALLENGER], challenger_prompt, agent_role=AgentRole.CHALLENGER
)
# Dr. Stewardship Agent:评估成本效益,确保在预算内进行诊断
stewardship_prompt = self._get_prompt_for_role(AgentRole.STEWARDSHIP, case_state) + "\n\n" + base_context
if self.enable_budget_tracking:
stewardship_prompt += f"\n\nBUDGET TRACKING ENABLED - Current cost: ${case_state.cumulative_cost}, Remaining: ${remaining_budget}"
deliberation_state.stewardship_analysis = self._safe_agent_run(
self.agents[AgentRole.STEWARDSHIP], stewardship_prompt, agent_role=AgentRole.STEWARDSHIP
)
# Dr. Checklist Agent:质量保证,确保诊断过程符合医学标准
checklist_prompt = self._get_prompt_for_role(AgentRole.CHECKLIST, case_state) + "\n\n" + base_context
deliberation_state.checklist_analysis = self._safe_agent_run(
self.agents[AgentRole.CHECKLIST], checklist_prompt, agent_role=AgentRole.CHECKLIST
)
# Consensus Coordinator Agent:综合所有专家意见,做出最终决策
consensus_prompt = deliberation_state.to_consensus_prompt()
if self.mode == "budgeted" and remaining_budget <= 0:
consensus_prompt += "\n\nBUDGET CONSTRAINT: Budget exceeded - must either ask questions or provide final diagnosis."
action_dict = self._get_consensus_with_retry(consensus_prompt)
action = Action(**action_dict)
action = self._validate_and_correct_action(action, case_state, remaining_budget)
return action循证医学流程对比分析
近期我阅读了循证医学相关著作 从症状到诊断:循证学指导,其中详细描述了常规循证医学的诊疗流程,具体如下所示:
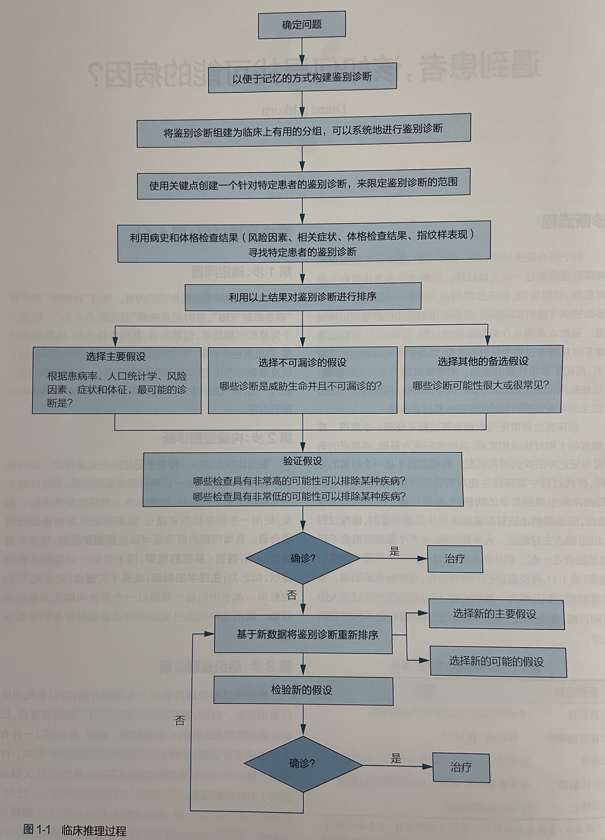
虽然医学的循证医学流程看起来较为复杂,但整体流程经过抽象简化后如下所示:

将 MAI-DxO 的流程进行抽象简化,并与对应的 Agent 关联起来,可以看到流程如下所示:

通过对比分析可以看出,MAI-DxO 是对当前人类循证医学诊断流程的模拟,并在常规循证医学角色基础上进行了扩展:引入了 Dr Challenger Agent 来发现逻辑偏差与遗漏信息,引入了 Dr Stewardship Agent 来进行检查成本控制。整体流程设计符合医学逻辑,体现了对真实诊疗过程的深度理解。
总结与展望
本文对 MAI-DxO 进行了深入分析,该框架整体设计符合医学逻辑,从现有结果来看,针对复杂病例的诊断,大模型确实展现出了一定优势。然而,这是否意味着大模型在疾病诊断方面能够真正超越人类医生呢?
当前医学知识体系极其复杂,任何单一医生能够掌握的知识都相对有限,因此科室的专业化分工是十分必要的。在复杂病例中,往往需要涉及多个科室的协作,而目前的测试主要针对全科医生或初级保健医生,这些医生远不能代表人类医生的最高水准。如果人类在特定病例中启用多学科会诊,预期准确性应该仍优于 MAI-DxO 框架。
尽管如此,MAI-DxO 确实是一个优秀的跨学科诊断框架,与人类医生结合使用,应该能够带来显著的辅助作用。未来,随着技术的不断发展和医学知识的持续积累,这类 AI 辅助诊断系统有望在提高医疗效率、降低误诊率方面发挥越来越重要的作用。