01. 函数调用的本质与组成
在概率架构下,大语言模型的回复是非结构化且不一致的,所以将大语言模型集成到其他系统中,是存在一定风险的,例如下游系统中想要 JSON 数据,但是大语言模型返回了一串文本,会让整个流程崩溃。但是如果能更好控制 响应格式,就可以轻松地将响应下游集成到其他系统中(虽然通过 prompt 也可以实现,但是不稳定)。
其次,我们都知道大语言模型的训练需要大量的计算资源和时间,因此它们的知识库通常是在某个知识点之前的数据集上训练的,例如,GPT-3.5 和 GPT-4 的知识截至 2023 年 10 月,这意味着它们无法提供此后的新消息或事件,为保持时效性,需定期重训模型,单成本高昂且费时。
而 函数调用(Function Calling) 的使用就是为了克服大语言模型的上述缺点,LLM 中的函数调用架构其实也非常简单,本质上是对输入 prompt 的自动拆解,利用拆解出来的参数和自动识别出的函数名称,调用外部资源,然后将返回的外部资源添加到 prompt 之中,再次调用 LLMs,从而得到返回结果,运行流程与架构如下:
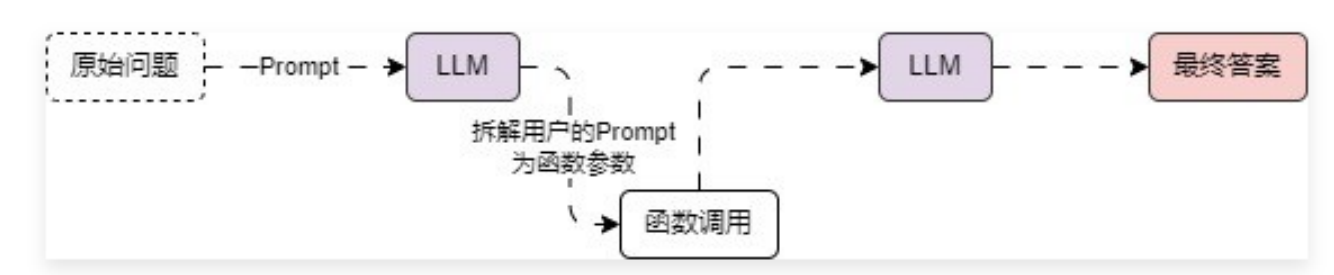
简单来说,函数回调 的作用就是可以更可靠地从大语言模型中获取结构化的数据。
并且目前绝大部分大参数的模型都支持函数调用,而且除了 系统消息、人类消息、AI消息 之外,部分大模型还可以添加 函数/工具消息,即将函数的生成结果单独作为消息传递给大模型,让大模型基于工具消息生成对应的内容,例如 GPT 模型。
- OpenAI 大语言模型聊天接口文档:https://platform.openai.com/docs/api-reference/chat/create
- 百度文心一言函数调用接口文档:ERNIE-Functions-8K - ModelBuilder
对于原生支持 函数调用 大语言模型而言,一般来说会提供多一个除了 prompt 之外的参数,这个参数用于描述 函数调用 的相关参数(并且目前绝大部分 LLM 的函数参数描述格式都保持一致,参考 GPT)。
参数涵盖了函数名字、函数描述、函数参数、函数调用模型等,这样大语言模型才能知道可以调用那些函数。
例如 GPT模型 执行 函数调用 示例
from openai import OpenAI
client = OpenAI()
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": "celsius", "fahrenheit"},
},
"required": "location",
},
}
}
]
messages = {"role": "user", "content": "What's the weather like in Boston today?"}
completion = client.chat.completions.create(
model="gpt-3.5-turbo-16k",
messages=messages,
tools=tools,
tool_choice="auto"
)
print(completion)
例如上方的代码描述了一个函数名为 get_current_weather,该函数的作用是查询指定城市的天气信息,函数拥有两个参数 location 和 unit 分别代表 城市 和 单位,其中 城市 参数是必填的。
当我们提问 What's the weather like in Boston today?(今天波士顿的天气怎么样?) 时,大语言模型会根据传递的 auto 自动检测需要调用函数,于是从 prompt 中提取出对应的函数参数信息,返回的数据如下(多了一个 tool_calls 参数)
{
"id": "chatcmpl-abc123",
"object": "chat.completion",
"created": 1699896916,
"model": "gpt-4o-mini",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "get_current_weather",
"arguments": "{\n\"location\": \"Boston, MA\"\n}"
}
}
]
},
"logprobs": null,
"finish_reason": "tool_calls"
}
],
"usage": {
"prompt_tokens": 82,
"completion_tokens": 17,
"total_tokens": 99
}
}
接下来就可以根据大模型生成的 tool_calls 参数调用对应的函数,从而完成本地特定的函数调用,对于部分大模型来说,还可以将函数结果、前面的历史对话消息传递给大模型,让大模型基于这些信息生成对应的内容。
!IMPORTANT
需要特别注意的是,大语言模型本身的 函数调用 并不会调用我们预定义的 参数,而是仅仅生成我们需要调用的函数的调用参数而已,具体调用函数的动作,需要我们在应用代码中实现。
从上面的示例中,很容易看出,函数调用 = 大语言模型(支持函数调用) + 预定Prompt + 函数/工具参数列表 + 本地调用代码。
02. 函数调用的想象空间
在函数调用的加持下,让大语言模型作为大脑,接入到上下游系统中,就可以实现以往很多实现不了的功能,**实现万物智能化!**例如:
- 用户对着微信说:给我每个女性好友发送一条情真切意的拜年消息,还要带一点小幽默。
- 用户对着富途牛牛:人工智能相关股票,市盈率最低的是哪一个?最近交易量如何?都有那些机构持有?
- 用户对着京东说:我想买一台 65 寸的电视,不要日货,价格在 5000 元左右。
上述的几个需求,都只需要预设好特定的函数/工具,并将函数/工具的参数描述传递给大语言模型, 大语言模型就会从传递的 prompt 中抽取相关的函数参数,接下来直接执行本地函数的调用即可。
又例如像 Self-RAG 优化策略,在该策略的运行流程中,需要让 LLM 自行判断是否需要检索对应的内容,如果需要的话则生成检索内容,否则直接输出内容,同样也可以利用到 函数调用,设置 tool_choice 为 auto,让 LLM 自行做决策即可
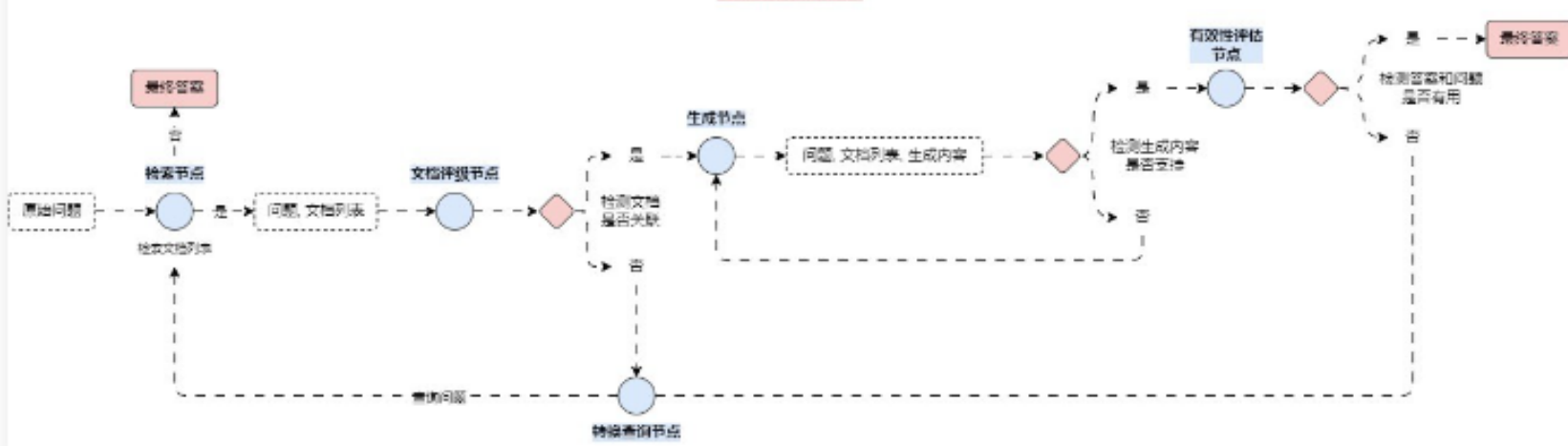
除了单次执行,还可以让 LLM 将需求拆分,拆分成多个任务/函数,让不同的 LLM 执行不同的子任务,并分工合作调用不同的工具/函数,并循环检测输出的内容是否实现了整个任务,最后再将结果输出,恭喜你,发现了目前基于 LLM 构建通用人工智能的路径,这也是 2023 年火爆全网的 AutoGPT 的设计架构基础!