01. CRAG 图结构拆解与状态管理
在前面的课时中,我们学习了 CRAG(纠正性索引增强生成) 优化策略,在该优化策略中引入了一个轻量级的评估器用于评估检索到的文档的质量,并根据评估结果触发不同的知识检索动作,其整体运行流程如下:
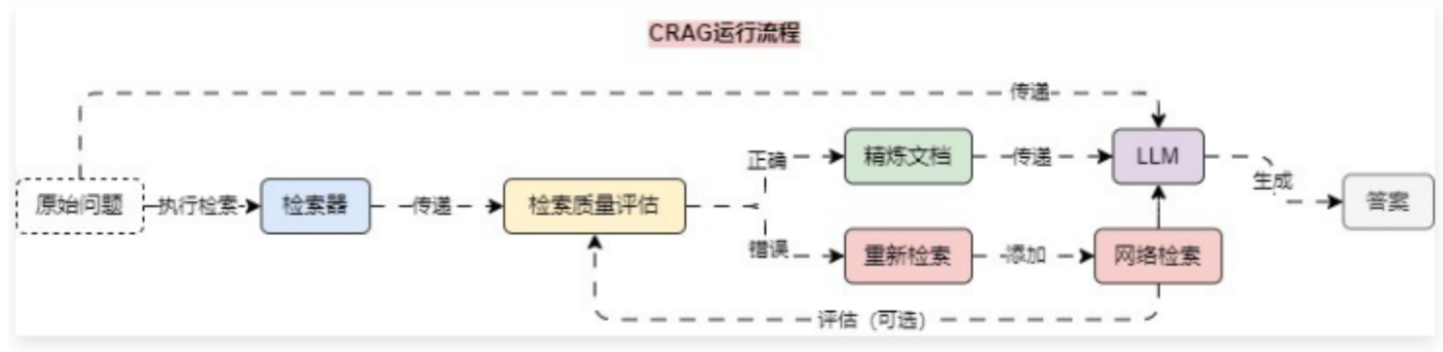
在 CRAG 优化策略中,存在 条件分支,即通过 检索质量评估 后,需要条件选择 精炼文档 亦或者是 网络检索,所以没办法利用 LCEL 表达式进行构建,判断是使用 LCEL 亦或者 LangGraph 来构建程序的标准如下:
- 应用是顺序线性,并且无条件分支、无循环,优先考虑 LCEL 表达式;
- 存在任意条件分支亦或者任意循环,则该部分可以使用 LangGraph 构建,其余部分仍然可以使用 LCEL 表达式进行拼接;
- 在节点组件较多,并且难以提取出 公共数据状态 的情况下,可以优先使用 LCEL 表达式,然后再使用 LangGraph 改造;
而无论是构建 LCEL 亦或者是 LangGraph 应用,其步骤都是大差不差:
- 分析使用 LCEL 还是使用 LangGraph 来实现,亦或者是混合使用。
- 确定整个程序的节点和各个边,涵盖了起点、终点、条件边、循环等。
- 提炼各个节点之间的公共数据,制作 数据状态,确定归纳函数逻辑,亦或者使用覆盖更新的方式。
- 完成应用程序的各个节点函数,并构建图,添加节点。
- 按照应用程序的流向为各个节点添加边,从起点开始,直到结束。
- 编译程序,检测是否需要检查点,是否需要断点等功能。
- 调用程序并提取输出内容。
02. LangGraph 实现示例
在上述的运行流程中,我们将使用 weaviate 向量数据库作为检索器,使用 google_serper 作为网络检索工具,使用 LLM(gpt-4o-mini) 作为检索质量评估器,其实现完整代码
from typing import TypedDict, Any
import dotenv
import weaviate
from langchain_community.tools import GoogleSerperRun
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_weaviate import WeaviateVectorStore
from langgraph.graph import StateGraph
from weaviate.auth import AuthApiKey
dotenv.load_dotenv()
class GradeDocument(BaseModel):
"""文档评分Pydantic模型"""
binary_score: str = Field(description="文档与问题是否关联,请回答yes或者no")
class GoogleSerperArgsSchema(BaseModel):
query: str = Field(description="执行谷歌搜索的查询语句")
class GraphState(TypedDict):
"""图结构应用程序数据状态"""
question: str # 原始问题
generation: str # 大语言模型生成内容
web_search: str # 网络搜索内容
documents: liststr # 文档列表
def format_docs(docs: listDocument) -> str:
"""格式化传入的文档列表为字符串"""
return "\n\n".join(doc.page_content for doc in docs)
1.创建大语言模型
llm = ChatOpenAI(model="gpt-4o-mini")
2.创建检索器
vector_store = WeaviateVectorStore(
client=weaviate.connect_to_wcs(
cluster_url="https://uiufdvagtjkaf9i4ey0a.c0.us-west3.gcp.weaviate.cloud",
auth_credentials=AuthApiKey("zGnUn1q5oI3hQUtmqP4NiRty83LNLqDaGoqw"),
),
index_name="LLMOps",
text_key="text",
embedding=OpenAIEmbeddings(model="text-embedding-3-small"),
)
retriever = vector_store.as_retriever(search_type="mmr")
3.构建检索评估器
system = """你是一名评估检索到的文档与用户问题相关性的评估员。
如果文档包含与问题相关的关键字或语义,请将其评级为相关。
给出一个是否相关得分为yes或者no,以表明文档是否与问题相关。"""
grade_prompt = ChatPromptTemplate.from_messages([
("system", system),
("human", "检索文档: \n\n{document}\n\n用户问题: {question}"),
])
retrieval_grader = grade_prompt | llm.with_structured_output(GradeDocument)
4.RAG检索增强生成
template = """你是一个问答任务的助理。使用以下检索到的上下文来回答问题。如果不知道就说不知道,不要胡编乱造,并保持答案简洁。
问题: {question}
上下文: {context}
答案: """
prompt = ChatPromptTemplate.from_template(template)
rag_chain = prompt | llm.bind(temperature=0) | StrOutputParser()
5.网络搜索问题重写
rewrite_prompt = ChatPromptTemplate.from_messages([
(
"system",
"你是一个将输入问题转换为优化的更好版本的问题重写器并用于网络搜索。请查看输入并尝试推理潜在的语义意图/含义。"
),
("human", "这里是初始化问题:\n\n{question}\n\n请尝试提出一个改进问题。")
])
question_rewriter = rewrite_prompt | llm.bind(temperature=0) | StrOutputParser()
6.网络搜索工具
google_serper = GoogleSerperRun(
name="google_serper",
description="一个低成本的谷歌搜索API。当你需要回答有关时事的问题时,可以调用该工具。该工具的输入是搜索查询语句。",
args_schema=GoogleSerperArgsSchema,
api_wrapper=GoogleSerperAPIWrapper(),
)
7.构建图相关节点函数
def retrieve(state: GraphState) -> Any:
"""检索节点,根据原始问题检索向量数据库"""
print("---检索节点---")
question = state"question"
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def generate(state: GraphState) -> Any:
"""生成节点,根据原始问题+上下文内容调用LLM生成内容"""
print("---LLM生成节点---")
question = state"question"
documents = state"documents"
generation = rag_chain.invoke({"context": format_docs(documents), "question": question})
return {"question": question, "documents": documents, "generation": generation}
def grade_documents(state: GraphState) -> Any:
"""文档与原始问题关联性评分节点"""
print("---检查文档与问题关联性节点---")
question = state"question"
documents = state"documents"
filtered_docs = \[\]
web_search = "no"
for doc in documents:
score: GradeDocument = retrieval_grader.invoke({
"question": question, "document": doc.page_content,
})
grade = score.binary_score
if grade.lower() == "yes":
print("---文档存在关联---")
filtered_docs.append(doc)
else:
print("---文档不存在关联---")
web_search = "yes"
continue
return {**state, "documents": filtered_docs, "web_search": web_search}
def transform_query(state: GraphState) -> Any:
"""重写/转换查询节点"""
print("---重写查询节点---")
question = state"question"
better_question = question_rewriter.invoke({"question": question})
return {**state, "question": better_question}
def web_search(state: GraphState) -> Any:
"""网络检索节点"""
print("---网络检索节点---")
question = state"question"
documents = state"documents"
search_content = google_serper.invoke({"query": question})
documents.append(Document(
page_content=search_content,
))
return {**state, "documents": documents}
def decide_to_generate(state: GraphState) -> Any:
"""决定执行生成还是搜索节点"""
print("---路由选择节点---")
web_search = state"web_search"
if web_search.lower() == "yes":
print("---执行Web搜索节点---")
return "transform_query"
else:
print("---执行LLM生成节点---")
return "generate"
8.构件图/工作流
workflow = StateGraph(GraphState)
9.定义工作流节点
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("generate", generate)
workflow.add_node("transform_query", transform_query)
workflow.add_node("web_search_node", web_search)
10.定义工作流边
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges("grade_documents", decide_to_generate)
workflow.add_edge("transform_query", "web_search_node")
workflow.add_edge("web_search_node", "generate")
workflow.set_finish_point("generate")
11.编译工作流
app = workflow.compile()
print(app.invoke({"question": "能介绍下什么是LLMOps么?"}))
生成内容:
---检索节点---
---检查文档与问题关联性节点---
---文档不存在关联---
---文档不存在关联---
---文档不存在关联---
---文档不存在关联---
---路由选择节点---
---执行Web搜索节点---
---重写查询节点---
---网络检索节点---
---LLM生成节点---
{'question': '什么是LLMOps,能详细解释它的定义、应用和重要性吗?', 'generation': 'LLMOps(Large Language Model Operations)是管理大型语言模型(LLMs)应用的流程和工具的集合,类似于机器学习运维(MLOps)。它涵盖了LLMs的开发、部署、维护和优化,主要包括数据分析、实验跟踪、模型管理等功能。\n\n**应用**:LLMOps用于支持LLM的整个生命周期,包括模型的预训练、微调、部署和监测,以提高语言模型的性能和效率。\n\n**重要性**:随着LLM在各个领域的广泛应用,LLMOps的实施可以确保有效的协作、优化资源使用、提高开发效率并降低风险,从而促使LLM项目成功。', 'web_search': 'yes', 'documents': Document(page_content='LLMOps是Large Language Model Operations的缩写,可以将LLMOps认为是LLMs的MLOps,这也意味着,LLMOps本质上是管理基于LLM的应用的一系列工具和最佳实践 ... LLMOps 的定义\\u200b LLMOps 的完整定义是基于大模型的应用程序的生命周期管理平台或者工具。 大模型的构建主要分为三个阶段: 第一个阶段是预训练阶段 在预训 ... LLMOps 平台为开发人员和团队提供了一个促进协作的环境,它涵盖数据分析、实验跟踪、提示词工程和LLM 管理。它还可为LLM 提供受控的模型转换、部署和监控 ... Missing: 定义、 \| Show results with:定义、. LLMOps(Large Language Model Operations)是一个涵盖了大型语言模型(如GPT系列)开发、部署、维护和优化的一整套实践和流程。LLMOps 的目标是确保 ... LLMOps是一套用于管理数据,微调和适应模型,部署解决方案,并监控性能以获得最佳语言和学习模型(LLM)结果的全面工具。 它为数据科学家,工程师和业务用户提供了一个统一 ... 它的简短定义是LLMOps 是LLM 的MLOps。这意味着LLMOps 是一组工具和最佳实践,用于管理LLM 支持的应用程序的生命周期,包括开发、部署和维护。 悟乙己. LLMOps(Large Language Model Operations)是机器学习运营(MLOps)的演变,专门针对大型语言模型(LLMs)的独特需求和挑战。 LLMOps 超越了MLOps的通用 ... 术语LLMOps代表大语言模型运维,其缩写LLMOps的意思是面向LLM的MLOps,这意味着LLMOps是用于管理LLM驱动的应用程序生命周期(包括开发、部署和维护)的一组 ... 利用MLOps 实现大型语言模型,即LLMOps:多年来,MLOps 已经证明了其增强ML 模型的开发、部署和维护的能力,从而带来更敏捷、更高效的机器学习系统。 MLOps 方法可以实现 ... 一种视角认为LLMOps 是MLOps 在LLM 场景下的直接迁移。主要使用对象还是算法工作人员。这种视角里认为的LLM 全生命周期更多还是强调训练大模型的过程,对 ...')}