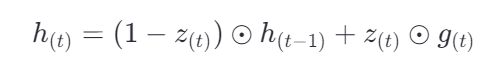LSTM
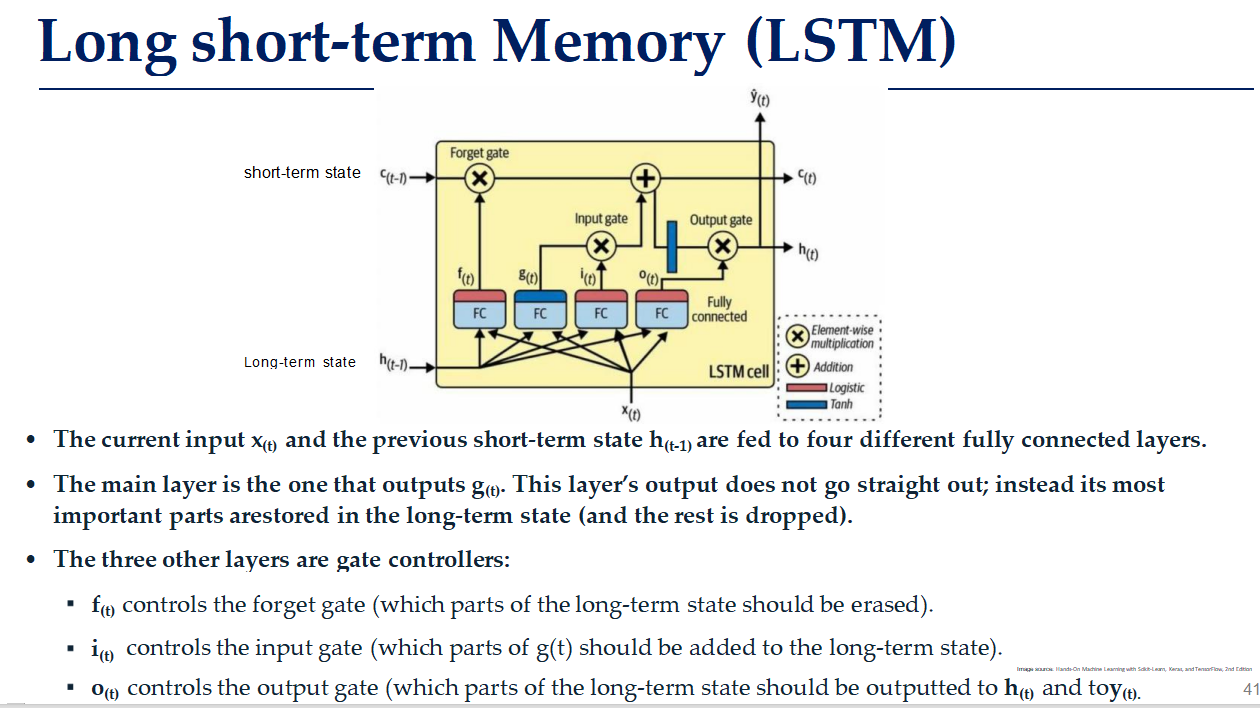
LSTM的基本组成部分
- 输入门(Input Gate):决定哪些新信息应该被添加到细胞状态中。
- 遗忘门(Forget Gate):决定哪些信息应该从细胞状态中丢弃。
- 输出门(Output Gate) :决定哪些信息应该从细胞状态输出到【隐藏状态】(真正输出是y(t))。
- 细胞状态(Cell State):存储长期记忆的信息流。
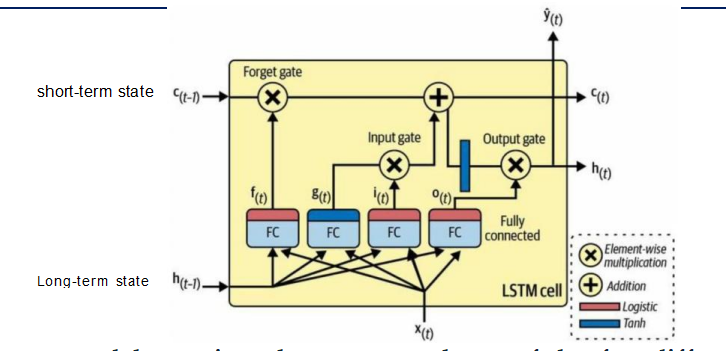
工作流程:
x(t) 是当前时刻的输入,h(t-1) 是前一刻的输入,二者通过全连接层与四个神经元(FC)相连,共同决定了四个函数:f(t),g(t),i(t),o(t)
其中f(t) 控制遗忘门,即由当前输入x(t) 和前一刻h(t-1) 输出决定从**c(t-1)**这个长期记忆中删去哪些东西。
g(t) 是预选细胞状态,也就是要放进长期记忆的备选信息,具体要放哪些进c(t) ,取决于输入门,而输入门也是由当前输入x(t) 和前一刻**h(t-1)**输出决定的。
h(t) 是当前时刻的输出,输出内容是来自细胞状态(长期记忆)的,具体输出什么,也是由当前输入x(t) 和前一刻**h(t-1)**输出决定的。
于是,最终存进长期记忆c(t)的内容就是:
新记忆 = 旧记忆 × 遗忘门 + 新输入 × 输入门
同时我们可以看到还有一个y(t)的箭头,是当前时刻的序列,对于s2s,每一个时刻都需要有一个输出对应输出,而v2s或s2v则不需要。
注意,h(t) 是输出到隐藏状态,它作为中间状态,将上一刻的输入传递给下一刻,保证短期记忆的传递。真正作为当前时刻的输出是这个y(t)。
门的激活公式
控制遗忘门
即由当前输入x(t) 和前一刻h(t-1) 输出决定从**c(t-1)**这个长期记忆中删去哪些东西。
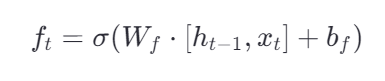
- Wf 是遗忘门的权重矩阵
- bf 是偏置项
- h(t−1),x(t) 表示将 h(t−1) 和 x(t) 拼接成一个向量
- σ 是 sigmoid 激活函数,输出值在 0 到 1 之间,表示"保留多少"的比例
长期记忆候选函数
具体要放哪些进c(t) ,取决于输入门,而输入门也是由当前输入x(t) 和前一刻**h(t-1)**输出决定的。
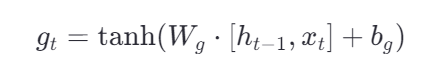
控制输入门
具体输入什么,是由当前输入x(t) 和前一刻**h(t-1)**输出决定的。
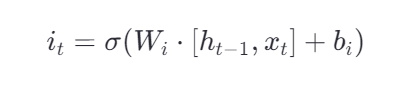
控制输出门
具体输出什么,也是由当前输入x(t) 和前一刻**h(t-1)**输出决定的。
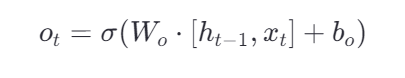
实际的长期记忆 ( 表逐项乘积)
表逐项乘积)
新记忆 = 旧记忆 × 遗忘门 + 新输入 × 输入门
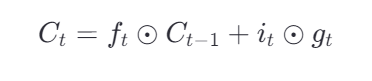
GRU是一种简化版的LSTM,它同样能够处理长期依赖问题,但通过减少门的数量和简化计算过程来提高效率。
GRU
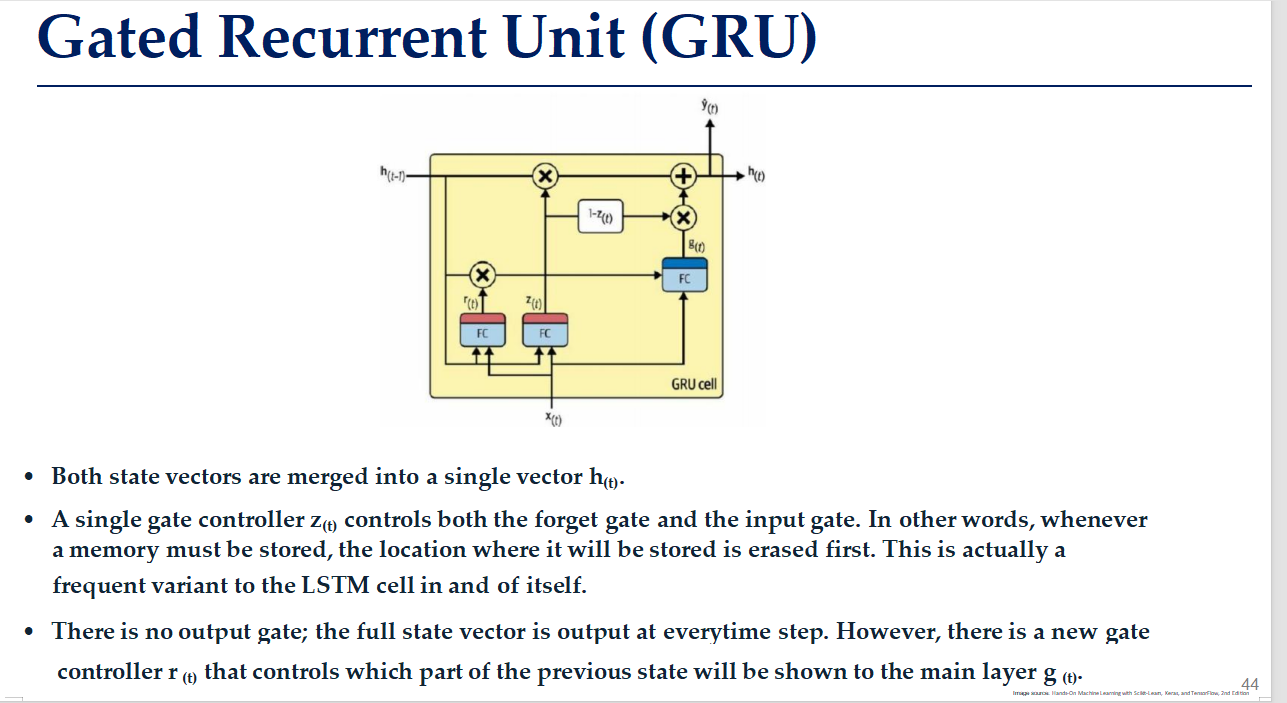
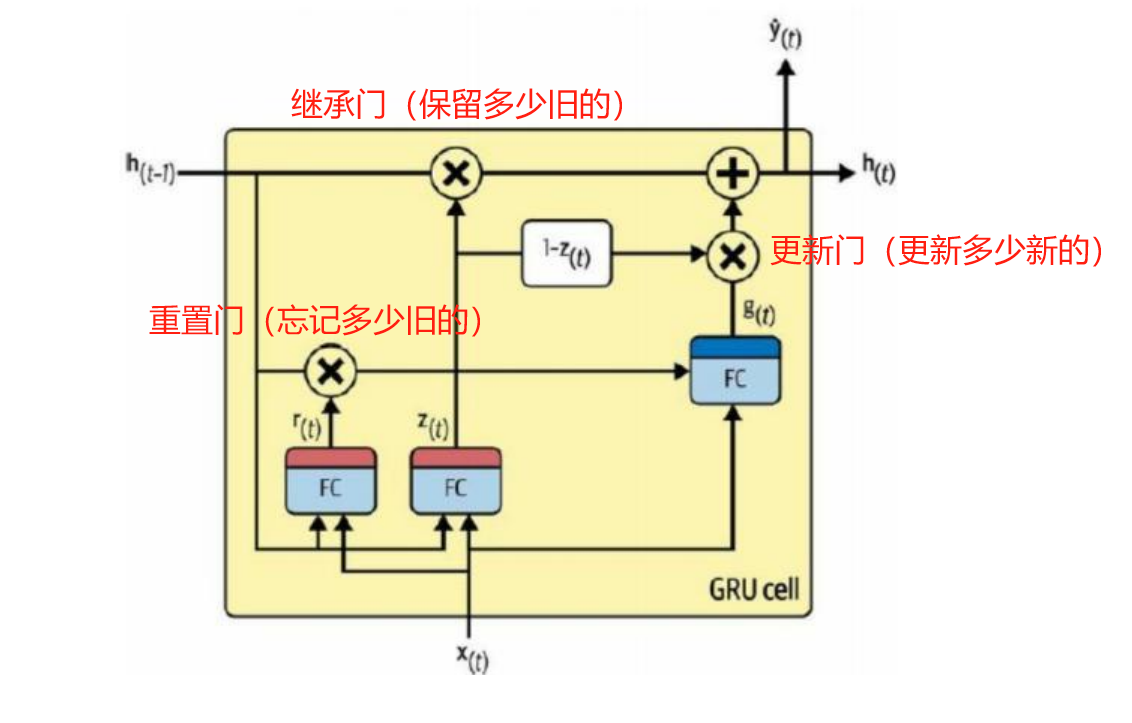
GRU的基本组成部分
- 重置门(Reset Gate):决定哪些过去的信息需要被"遗忘"。
- 更新门(Update Gate) :决定我要用新信息替换掉多少旧记忆。
- 继承门 (Inheritate Gate) :决定我要保留多少旧记忆。
- 候选状态(Candidate State):基于当前输入和上一时刻的状态计算出的新状态候选值
工作流程:
在 GRU 中,h(t) 既是短期记忆,也承载了长期依赖信息。
旧记忆h(t-1) 与当前输入**x(t)**进入后经过两个全连接神经元。
第一个神经元由旧记忆和当前输入决定了遗忘函数r(t) ,即从旧记忆**h(t-1)**中遗忘哪些内容。
经过第一个神经元的旧记忆会和当前输入全连接(右侧)得到预选更新内容g(t)。具体更新哪些内容,要由1-z(t)决定。
第二个神经元由旧记忆和当前输入决定了更新函数z(t) ,即要用新信息替换掉多少旧记忆(不是删去)。
那么1-z(t)就是要保留多少旧记忆。
因此预选更新内容g(t)经过保留门(右侧)就会往记忆中加入保留的内容。
因此,往记忆中加入的就是保留的旧记忆(右侧)和更新的新记忆(中间直上)。
更新公式就是
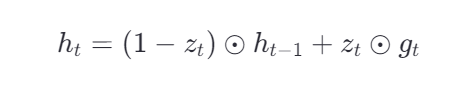

门的激活公式
控制重置门(遗忘门)
决定在计算候选状态时,上一时刻的隐藏状态 **h(t−1)**中有多少信息需要被保留
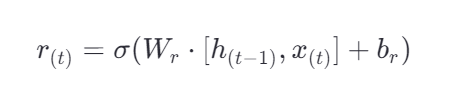
控制继承门
z(t)决定我要保留多少旧记忆。
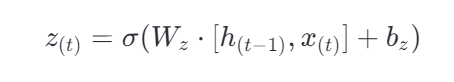
计算候选状态 g(t)
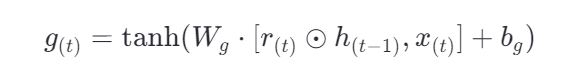
控制更新门
1-z(t)
更新隐藏状态 h(t)