在高并发系统中,Redis 作为高性能缓存层,能显著提升读取性能、减轻数据库压力。然而,如果使用不当,可能会引发 缓存雪崩、缓存击穿、缓存穿透 等问题,严重时甚至导致数据库崩溃。
本文将深入解析这三大缓存问题的产生原因、影响机制 ,并提供实用的解决方案 ,同时结合 Mermaid 图解 帮助你更直观地理解。
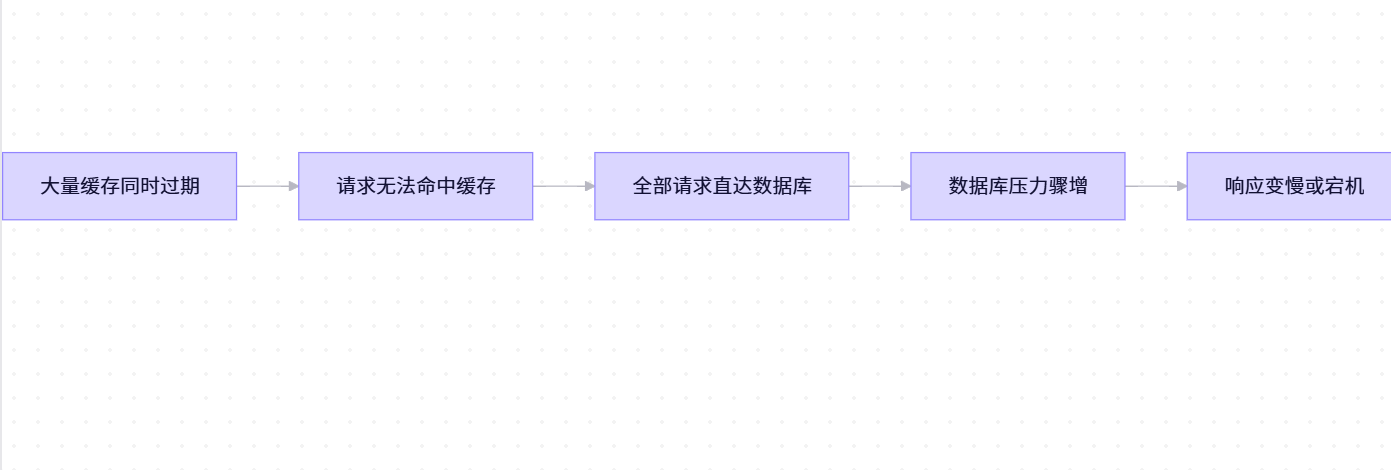
一、缓存雪崩:大量缓存同时失效
📌 什么是缓存雪崩?
缓存雪崩是指在某一时刻,大量缓存数据同时过期或 Redis 服务宕机,导致所有请求直接打到数据库,造成数据库瞬间压力激增,甚至崩溃。
🔍 产生原因
- 大量 Key 设置相同的过期时间 → 同一时间集体失效。
- Redis 节点故障或集群宕机 → 所有缓存不可用。
✅ 应对方案
1. 错峰设置过期时间
避免所有缓存同时失效,可在基础过期时间上加一个随机值(如 5~10 分钟随机偏移)。
Go
// 示例:设置缓存过期时间为 30 分钟 ± 5 分钟
expire := 30*time.Minute + time.Duration(rand.Intn(300))*time.Second
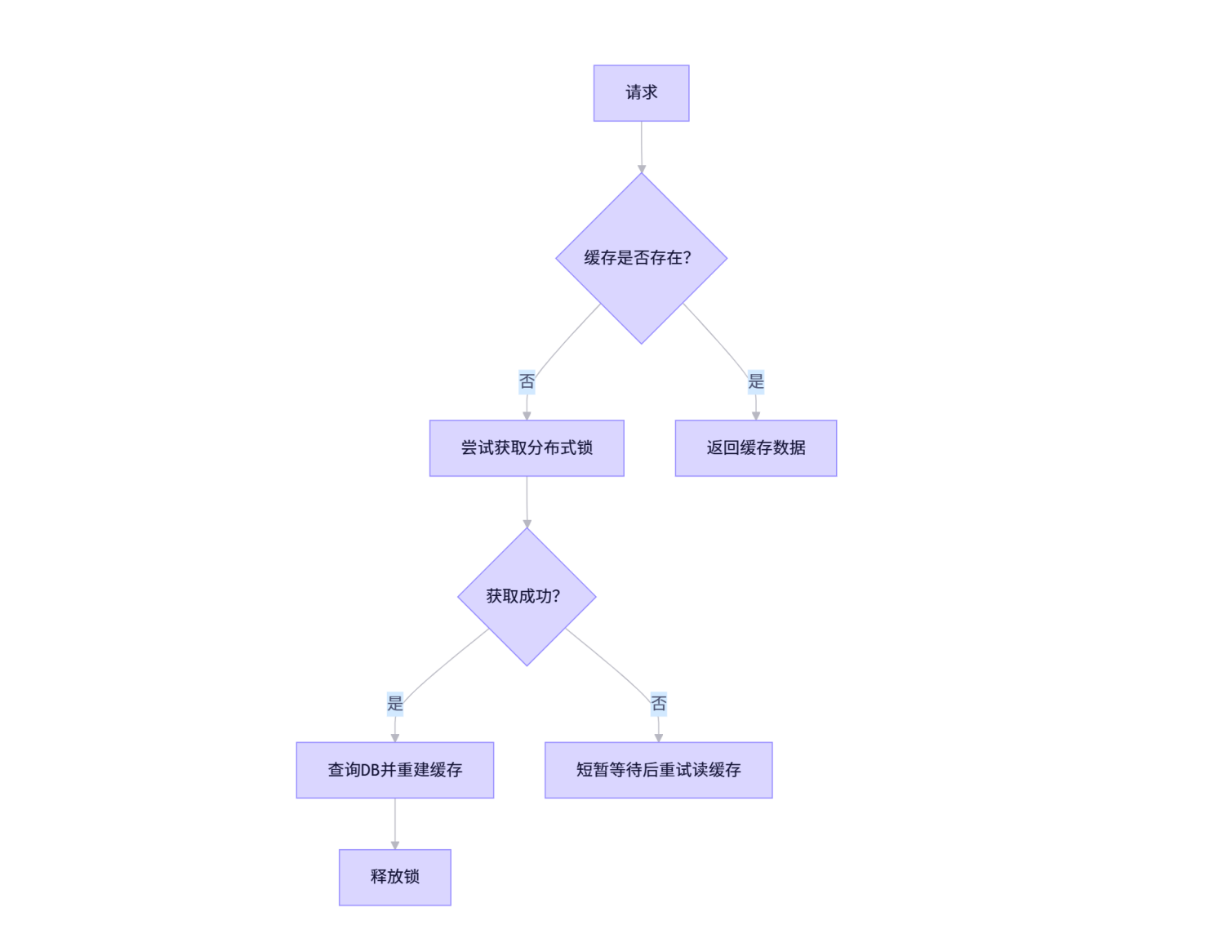
redis.Set(key, value, expire)2. 使用互斥锁防止并发重建
当缓存失效时,只允许一个线程重建缓存,其余线程等待。
3. 构建 Redis 高可用集群
- 使用 主从复制 + 哨兵(Sentinel) 或 Redis Cluster,实现故障自动切换。
- 即使主节点宕机,从节点可接管服务,避免缓存整体失效。
4. 服务降级与限流
- 限流:使用 Nginx、Sentinel 等工具限制每秒请求数。
- 熔断:当数据库压力过大时,暂时拒绝部分请求,返回默认值或提示"系统繁忙"。
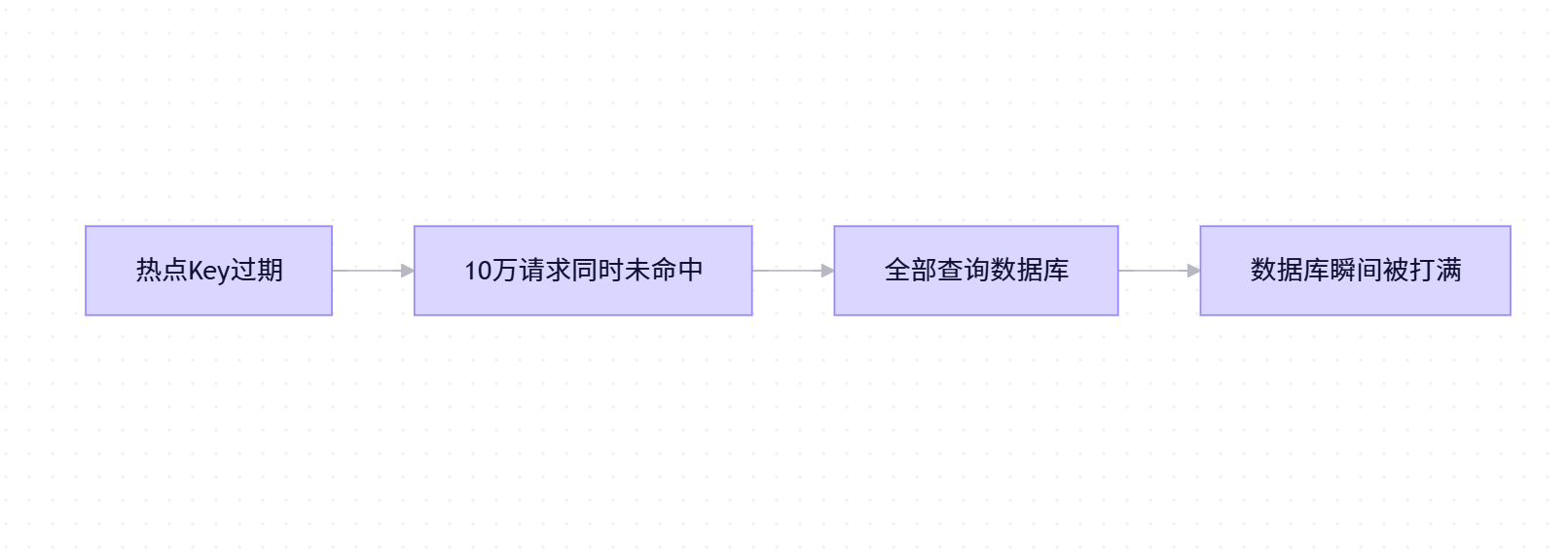
二、缓存击穿:热点 Key 过期引发的冲击
📌 什么是缓存击穿?
缓存击穿是指某个被高频访问的热点 Key 在过期的瞬间,大量并发请求同时无法命中缓存,全部涌向数据库,造成瞬时压力激增。
⚠️ 与雪崩不同:雪崩是"大面积失效",击穿是"单个热点失效"。
✅ 应对方案
1. 为热点数据设置永不过期
- 缓存数据不设置
expire,由后台定时任务主动更新。 - 优点:避免过期瞬间的并发冲击。
- 缺点:数据更新延迟,需确保后台任务可靠。
2. 使用互斥锁重建缓存
与雪崩应对类似,通过加锁保证只有一个线程重建缓存。
Go
func getFromCacheOrDB(key string) (string, error) {
val, err := redis.Get(key)
if err == nil {
return val, nil // 缓存命中
}
// 缓存未命中,尝试加锁
lock := acquireLock(key)
if lock {
defer releaseLock(key)
val, err = db.Query(key)
redis.Set(key, val, 30*time.Minute) // 重新设置
return val, err
} else {
// 等待片刻后重试读缓存
time.Sleep(10 * time.Millisecond)
return redis.Get(key)
}
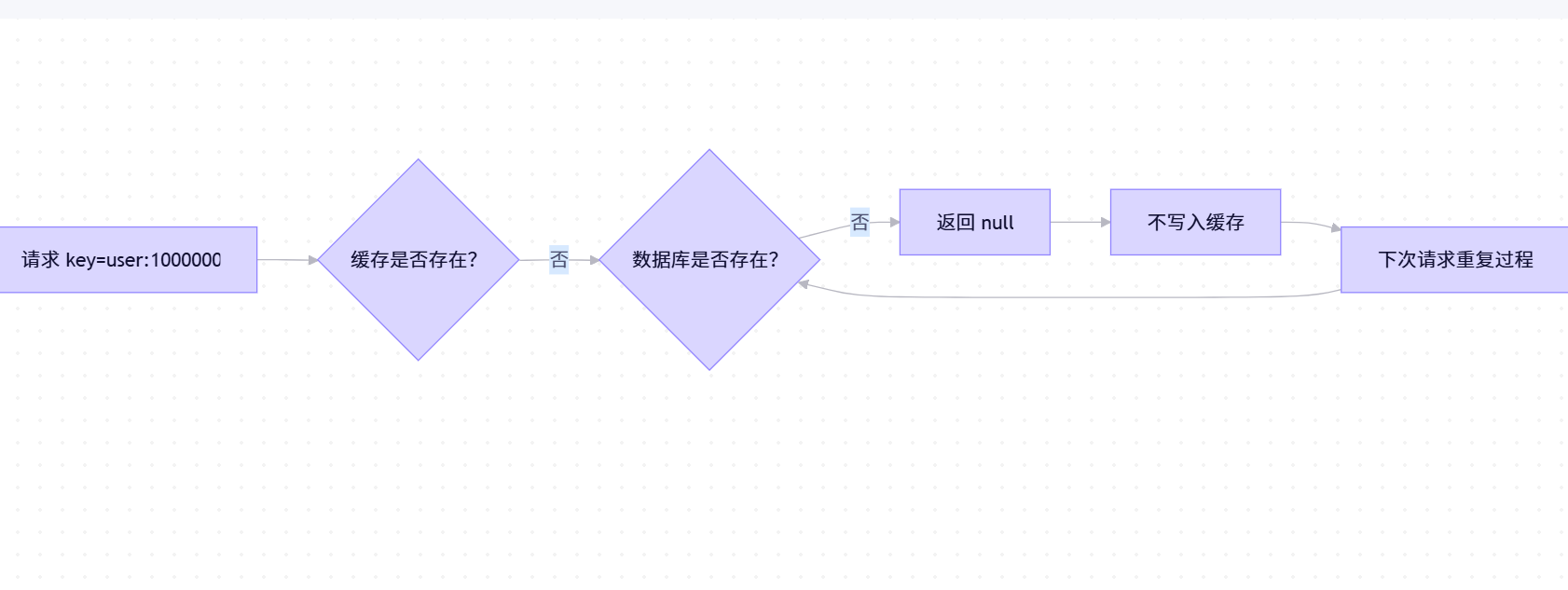
}三、缓存穿透:查询不存在的数据
📌 什么是缓存穿透?
缓存穿透是指查询一个数据库中也不存在的数据,导致缓存无法命中,每次请求都必须查询数据库。恶意攻击者可能利用此漏洞,构造大量不存在的 Key,持续请求,压垮数据库。
✅ 应对方案
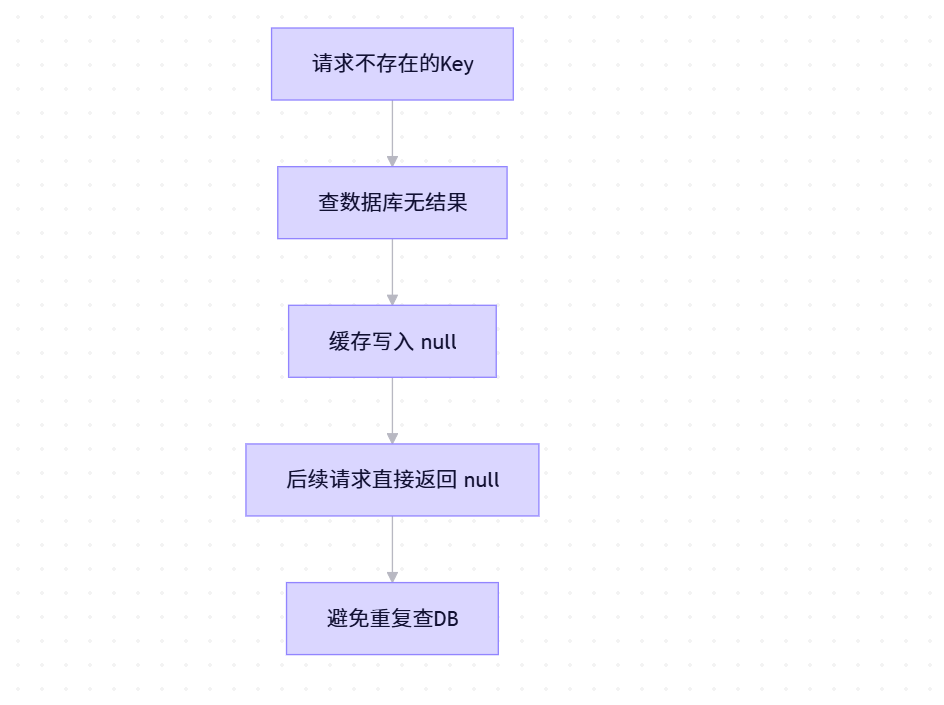
1. 缓存空值(Null Value)
即使数据库查不到,也向缓存写入一个 null 或特殊标记,并设置较短过期时间(如 1~5 分钟)。
Go
val, err := db.Query("user:1000000")
if err != nil {
redis.Set("user:1000000", "null", 2*time.Minute) // 缓存空值
return nil
}
2. 使用布隆过滤器(Bloom Filter)
在访问缓存前,先通过布隆过滤器判断该 Key 是否可能存在。
- 如果布隆过滤器返回"不存在" → 直接拒绝请求。
- 如果返回"可能存在" → 继续查缓存或数据库。
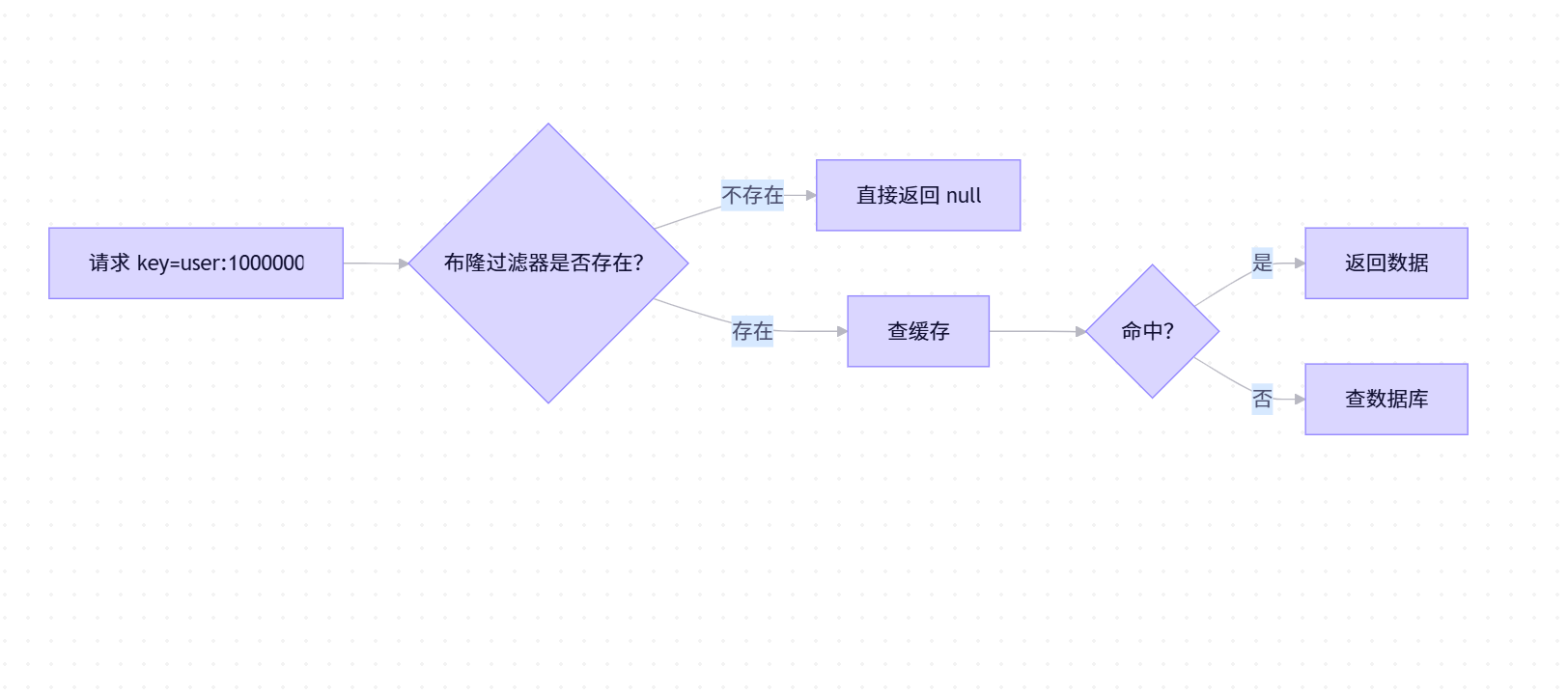
✅ 布隆过滤器优点:空间效率高、查询快;缺点:存在极低误判率(可接受)。
四、如何保证数据库和缓存的一致性
Cache Aside 策略
Cache Aside 策略分为"读策略"和"写策略"。
写策略步骤
- 更新数据库:首先更新数据库中的数据。
- 删除缓存:更新成功后,删除对应的缓存数据,以便下次读取时重新加载最新的数据。
读策略步骤
- 检查缓存:首先检查缓存中是否存在所需数据。
- 缓存命中:如果缓存命中,则直接返回缓存数据。
- 缓存未命中:如果缓存未命中,则查询数据库,并将查询结果写入缓存。
通过以上策略,可以在一定程度上保证数据库和缓存的一致性。
总结
在使用 Redis 作为缓存层时,我们需要充分考虑可能出现的问题,如缓存雪崩、缓存击穿和缓存穿透,并采取相应的应对措施。通过合理设置过期时间、使用互斥锁、构建高可用集群、限制非法请求、使用布隆过滤器等方法,可以有效地缓解这些问题,提高系统的稳定性和性能。同时,采用 Cache Aside 策略可以保证数据库和缓存的一致性,进一步提升系统的可靠性。
希望本文能帮助你更好地理解和掌握 Redis 缓存的相关知识。