在AI Agent领域,Deep Research应该算是最早的智能体应用,最初是由Google和OpenAI推出商用版本,后来也出现很多开源的项目。作为一名长期关注智能体架构设计的开发者,我最近深入研究了Langchain AI的Open Deep Research这个项目,本文将从技术角度剖析这个项目的核心实现,并对比分析其历史版本与当前版本的架构差异。
概览
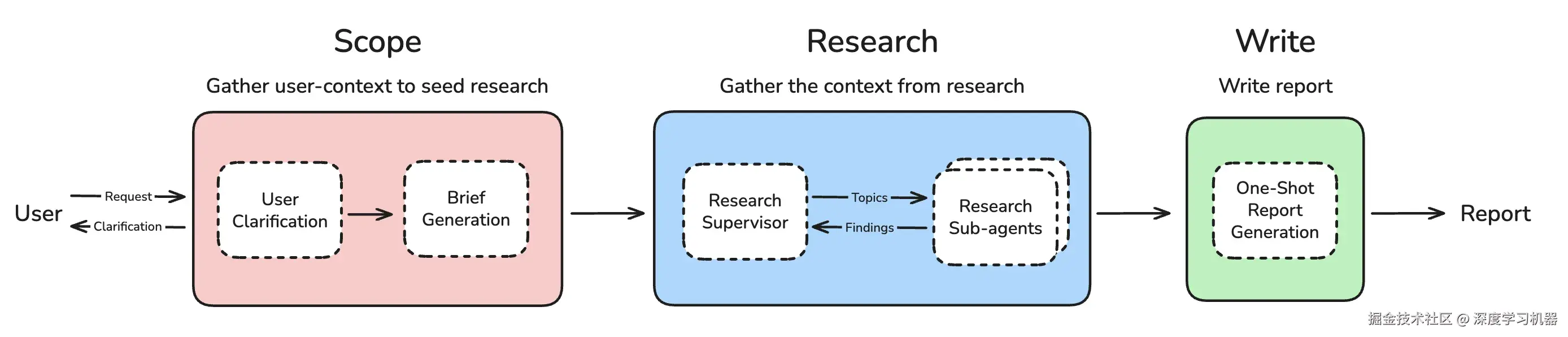
Open Deep Research是一个基于LangGraph构建的开源深度研究Agent,在Deep Research Bench排行榜上取得了第6名的成绩,RACE得分43.44分。项目采用了如下的技术栈:
-
核心框架: LangGraph用于状态图管理
-
模型抽象: LangChain的统一模型接口
-
异步处理: 基于asyncio的并发架构
-
配置管理: Pydantic进行类型安全的配置
-
多模型支持: 支持OpenAI、Anthropic、本地模型等
架构
该项目的架构采用了监督者-研究员模式,分为两个主要组件:
-
监督者(Supervisor):负责研究策略规划和任务分发
-
研究员(Researcher):执行具体的研究任务
状态管理
采用了基于LangGraph的状态管理系统,通过多层状态结构实现复杂的研究流程:
python
def override_reducer(current_value, new_value):
"""Reducer function that allows overriding values in state."""
if isinstance(new_value, dict) and new_value.get("type") == "override":
return new_value.get("value", new_value)
else:
return operator.add(current_value, new_value)
class AgentState(MessagesState):
supervisor_messages: Annotated[list[MessageLikeRepresentation], override_reducer]
research_brief: Optional[str]
raw_notes: Annotated[list[str], override_reducer] = []
notes: Annotated[list[str], override_reducer] = []
final_report: str这种状态管理能够保证精确控制状态更新:
-
状态一致性 :避免重复执行导致的状态污染
-
灵活控制 :同一字段支持累加和覆盖两种更新模式
-
原子操作 :确保状态更新的原子性,防止并发问题
-
向后兼容 :默认保持累加行为,不破坏现有逻辑
状态机设计
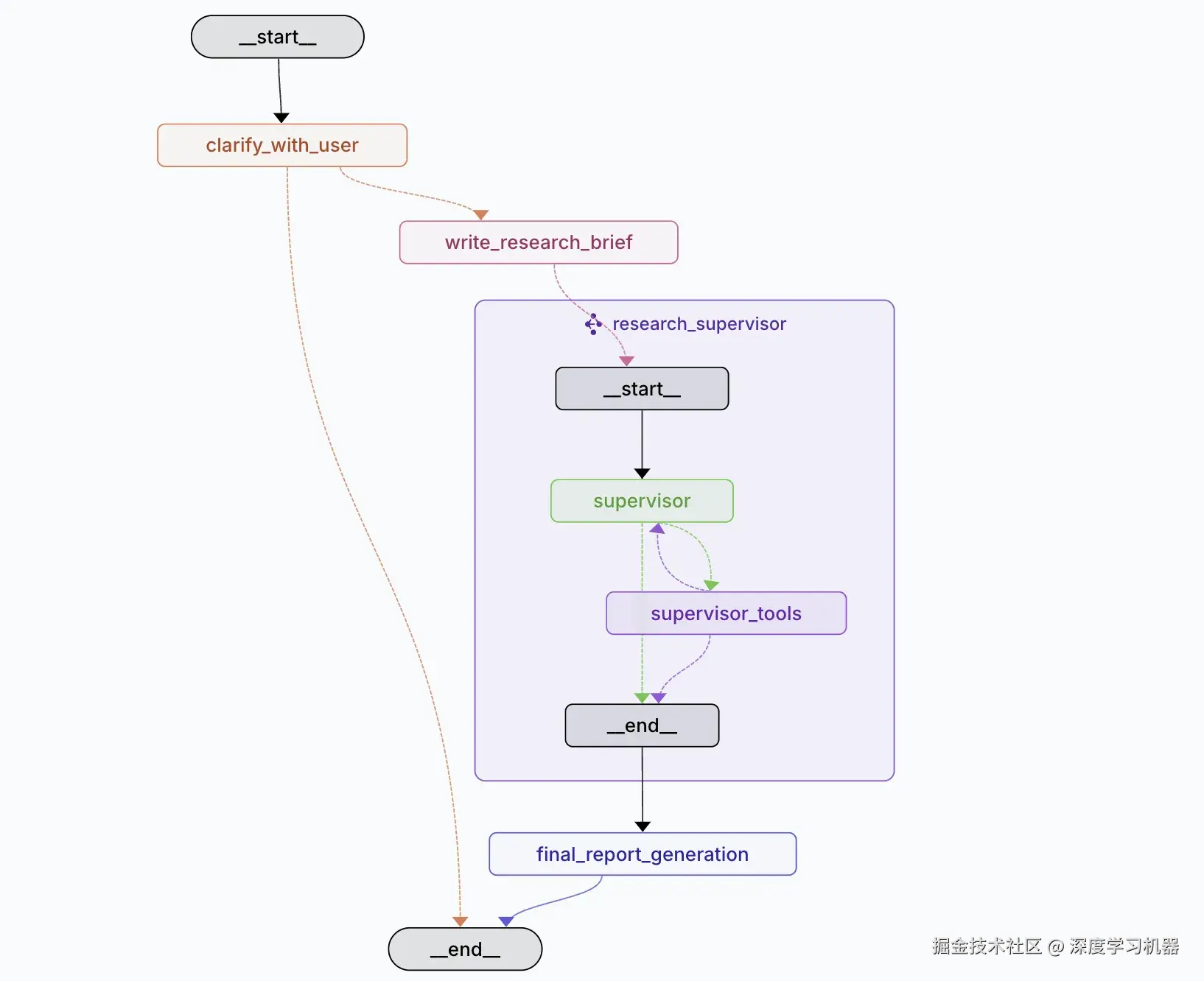
整个研究流程被建模为一个有向状态图,包含以下关键节点:
-
clarify_with_user: 智能问题澄清
-
write_research_brief: 研究简报生成
-
research_supervisor: 监督者
-
supervisor_tools: 工具执行层
-
researcher: 研究员
-
compress_research: 研究结果压缩
-
write_final_report: 最终报告生成
监督者
Supervisor是当前架构的核心,负责研究策略规划和任务分发:
python
async def supervisor(state: SupervisorState, config: RunnableConfig) -> Command[Literal["supervisor_tools"]]:
configurable = Configuration.from_runnable_config(config)
research_model_config = {
"model": configurable.research_model,
"max_tokens": configurable.research_model_max_tokens,
"api_key": get_api_key_for_model(configurable.research_model, config),
"tags": ["langsmith:nostream"]
}
lead_researcher_tools = [ConductResearch, ResearchComplete, think_tool]
research_model = (
configurable_model
.bind_tools(lead_researcher_tools)
.with_retry(stop_after_attempt=configurable.max_structured_output_retries)
.with_config(research_model_config)
)监督者具备三种核心工具:
-
ConductResearch: 委派研究任务给子智能体 -
ResearchComplete: 标记研究完成 -
think_tool: 策略思考和反思
并发研究
支持最多5个并发研究单元,通过LangGraph的SendAPI实现:
python
if tool_call["name"] == "ConductResearch":
research_topic = tool_call["args"]["research_topic"]
return Command(
goto="researcher",
update={"supervisor_messages": [tool_message]},
graph=Send("researcher", {
"researcher_messages": [SystemMessage(content=research_system_prompt.format(...))],
"research_topic": research_topic,
"tool_call_iterations": 0
})
)这种设计允许多个研究任务并行执行,显著提升了研究效率。
性能优化
异步并发处理
大量使用异步编程模式,特别是在搜索和总结环节:
python
async def tavily_search_async(
queries: List[str],
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
config: RunnableConfig = None
) -> List[Dict[str, Any]]:
# 并发执行多个搜索查询
tasks = [client.search(query, max_results=max_results, topic=topic, include_raw_content=include_raw_content)
for query in queries]
results = await asyncio.gather(*tasks)内容去重和压缩
为了避免重复处理相同内容,实现了URL级别的去重:
python
# 按URL去重,避免重复处理
unique_results = {}
for response in search_results:
for result in response['results']:
url = result['url']
if url not in unique_results:
unique_results[url] = {**result, "query": response['query']}Token管理策略
实现了智能的token管理,防止超出模型限制:
python
def is_token_limit_exceeded(messages: List[MessageLikeRepresentation], token_limit: int) -> bool:
"""检查消息是否超出token限制"""
total_tokens = sum(len(str(msg)) for msg in messages) # 简化的token计算
return total_tokens > token_limit * 0.8 # 保留20%缓冲区历史实现分析
项目的src/legacy/目录包含两个历史实现,代表了不同的架构思路。
工作流实现(graph.py)
第一个legacy版本采用了经典的Plan-and-Execute模式:
python
# 典型的顺序执行流程
async def generate_report_plan(state: ReportState, config: RunnableConfig):
# 1. 生成报告计划
# 2. 等待人类反馈
# 3. 根据反馈调整
# 4. 逐个生成章节技术特点:
-
交互式规划 :支持
human_feedback节点,允许用户对报告计划进行反馈和调整 -
顺序处理:章节按顺序生成,前一个章节完成后才开始下一个
-
质量优先 :通过
section_grader对每个章节进行质量评估 -
状态简单:使用基础的状态累加,结构相对简单
多智能体实现(multi_agent.py)
第二个legacy版本采用了Supervisor-Researcher架构:
核心设计理念:分布式并行处理模式
python
class ReportState(MessagesState):
sections: list[str] # 报告章节列表
completed_sections: Annotated[list[Section], operator.add] # 并行累加
final_report: str
source_str: Annotated[str, operator.add] # 源内容累加
# 并行研究团队
research_builder = StateGraph(SectionState, output=SectionOutputState)
supervisor_builder.add_node("research_team", research_builder.compile())技术特点:
- 真正的多智能体:Supervisor和多个Researcher智能体独立运行
- 并行执行:多个章节可以同时研究和生成
- MCP集成:广泛支持Model Context Protocol,可接入外部工具
- 状态累加 :使用
operator.add进行状态累加,简单但可能产生冗余
架构演进分析
1. 状态管理的优化
Legacy版本问题:
python
# 简单的状态累加,容易产生冗余
completed_sections: Annotated[list[Section], operator.add]当前版本改进:
python
# 精确的状态控制,避免重复累积
# 同一字段支持累加和覆盖两种更新模式,根据具体场景选择
supervisor_messages: Annotated[list[MessageLikeRepresentation], override_reducer]2. 工具调用的结构化
历史版本中的工具调用相对简单,而最新版本引入了更复杂的工具绑定机制,针对研究场景进行深度优化:
python
# 当前版本:结构化工具绑定
lead_researcher_tools = [ConductResearch, ResearchComplete, think_tool]
research_model = (
configurable_model
.bind_tools(lead_researcher_tools)
.with_retry(stop_after_attempt=configurable.max_structured_output_retries)
.with_config(research_model_config)
)3. 错误处理和重试机制
最新版本在多个层面实现了robust的错误处理:
python
# 结构化输出重试
.with_structured_output(ClarifyWithUser)
.with_retry(stop_after_attempt=configurable.max_structured_output_retries)
# Token限制检查
if is_token_limit_exceeded(researcher_messages, model_token_limit):
researcher_messages = remove_up_to_last_ai_message(researcher_messages)4. 配置系统的演进
最新版本采用了更加灵活的配置系统:
python
class Configuration(BaseModel):
# 支持多种搜索API
search_api: SearchAPI = Field(default=SearchAPI.TAVILY)
# 细粒度的模型配置
summarization_model: str = Field(default="openai:gpt-4.1-mini")
research_model: str = Field(default="openai:gpt-4.1")
compression_model: str = Field(default="openai:gpt-4.1")
final_report_model: str = Field(default="openai:gpt-4.1")这种设计允许针对不同任务使用不同的模型,实现了成本和性能的平衡。
结论
随着LLM的能力越来越强,Agent设计中更多决策权会交给模型,但是在Deep Research这种场景下,好像还是以工作流作为基本实现思路会更加合适一些,用于确保生成研究内容的质量下限。
Open Deep Research的核心优势在于其分层架构的精妙平衡:
-
状态管理的精确性 :通过
override_reducer机制避免了传统累加模式的状态污染问题,这在长时间运行的研究任务中尤为重要 -
并发策略的智能化:不同于固定并发数的简单方案,其动态调整机制能根据任务复杂度优化资源使用
-
成本控制的细粒度:分层模型选择策略在保证质量的同时有效控制了运营成本
对于正在构建类似系统的开发者而言,Open Deep Research的模块化设计理念、异步并发策略,以及多模型协同,都值得借鉴。