
bash
🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!摘要
作为一名在数据领域深耕多年的技术人,我深刻体会到数据链路改造就像是一次精密的星际航行。每一个决策都如同调整航向,每一次优化都像是点燃推进器。在本文中,我将分享一次真实的MySQL到ClickHouse明细分析链路改造经历,这是一段充满挑战与收获的旅程。
这次改造源于一个看似简单却极其复杂的问题:如何在保证数据完整性的前提下,将日均数十亿条MySQL明细数据高效迁移到ClickHouse,并确保分析延迟控制在可接受范围内。传统方案要么牺牲数据一致性,要么无法承受巨大的数据量,要么延迟过高无法满足业务需求。我们需要一个全新的解决方案。
通过深入分析业务场景,我们设计了一套包含实时同步、增量校验、智能补偿和延迟治理的完整链路。这套方案不仅解决了数据一致性问题,还将查询性能提升了100倍,将延迟从分钟级降低到秒级。更重要的是,我们建立了一套可观测、可回滚、可扩展的数据治理体系,为后续的数据架构演进奠定了坚实基础。
在本文中,我将详细拆解这个改造过程中的关键技术点:从数据校验机制的设计到补偿策略的实现,从延迟监控体系的搭建到性能调优的每一个细节。无论你是数据工程师、架构师还是技术管理者,相信这篇文章都能为你提供有价值的参考和启发。让我们一起踏上这段数据架构改造的星际之旅!
一、业务背景与挑战分析
1.1 现状痛点
在我们开始改造之前,系统面临着多重挑战:
数据规模爆炸式增长:MySQL单表数据量已突破500亿条,查询性能急剧下降,复杂分析查询需要数分钟才能完成。
业务需求多样化:从简单的统计查询到复杂的实时分析,从批量报表到实时大屏,业务场景越来越复杂。
数据一致性要求:财务、风控等关键业务对数据一致性要求极高,任何数据丢失或错误都可能造成严重后果。
实时性要求提升:从T+1批处理到准实时分析,业务对数据时效性的要求越来越高。
1.2 技术挑战
面对这些痛点,我们遇到了以下技术挑战:
查询性能 存储成本 维护困难 实时性 一致性 准确性 实时同步 增量校验 补偿机制 MySQL 500亿数据 分钟级响应 磁盘空间不足 分库分表复杂 业务需求 秒级延迟要求 零数据丢失 精确到分秒 技术方案 数据延迟 资源消耗 系统复杂度
图1:技术挑战分析图 - flowchart - 展示了MySQL到ClickHouse改造面临的核心挑战
1.3 改造目标设定
基于以上分析,我们制定了以下改造目标:
- 性能目标:查询响应时间从分钟级降至秒级
- 一致性目标:数据一致性达到99.99%以上
- 延迟目标:端到端延迟控制在5秒以内
- 可用性目标:系统可用性达到99.9%以上
二、整体架构设计
2.1 架构总览
我们的改造方案采用了分层架构设计,如图2所示:
图2:整体架构图 - architecture-beta - 展示了MySQL到ClickHouse的完整数据链路
2.2 数据流转流程
数据从MySQL到ClickHouse的流转过程如下:
- 数据采集层:通过Canal实时监听MySQL的binlog
- 消息队列层:Kafka作为缓冲,实现削峰填谷
- 实时处理层:Flink进行数据清洗和转换
- 存储层:ClickHouse分布式存储
- 治理层:监控、告警和补偿机制
2.3 关键技术选型
| 组件 | 选型 | 理由 |
|---|---|---|
| 数据采集 | Canal | 支持MySQL binlog解析,稳定性高 |
| 消息队列 | Kafka | 高吞吐、低延迟,支持持久化 |
| 流处理 | Flink | 支持exactly-once语义,容错能力强 |
| 存储引擎 | ClickHouse | 列式存储,分析性能优异 |
| 监控体系 | Prometheus+Grafana | 开源、可扩展、生态完善 |
表1:关键技术选型对比
三、数据校验机制
3.1 校验策略设计
为了确保数据一致性,我们设计了三层校验机制:
实时校验 :在数据写入ClickHouse时进行字段级校验
增量校验 :定期对比MySQL和ClickHouse的增量数据
全量校验:每日进行一次全量数据对比
3.2 实时校验实现
实时校验的核心代码如下:
python
class RealTimeValidator:
def __init__(self, clickhouse_client, mysql_client):
self.ch = clickhouse_client
self.mysql = mysql_client
self.validator = DataValidator()
def validate_record(self, record):
"""实时校验单条记录"""
try:
# 1. 字段完整性校验
if not self.validator.check_fields_complete(record):
raise ValidationError("字段不完整")
# 2. 数据类型校验
if not self.validator.check_data_types(record):
raise ValidationError("数据类型不匹配")
# 3. 业务规则校验
if not self.validator.check_business_rules(record):
raise ValidationError("违反业务规则")
return True
except ValidationError as e:
self.log_error(record, str(e))
return False
def checksum_validation(self, table_name, date_range):
"""校验和验证"""
mysql_checksum = self.mysql.get_checksum(table_name, date_range)
ch_checksum = self.ch.get_checksum(table_name, date_range)
if mysql_checksum != ch_checksum:
self.trigger_compensation(table_name, date_range)
return mysql_checksum == ch_checksum3.3 校验结果可视化
我们使用Grafana构建了校验结果监控面板:
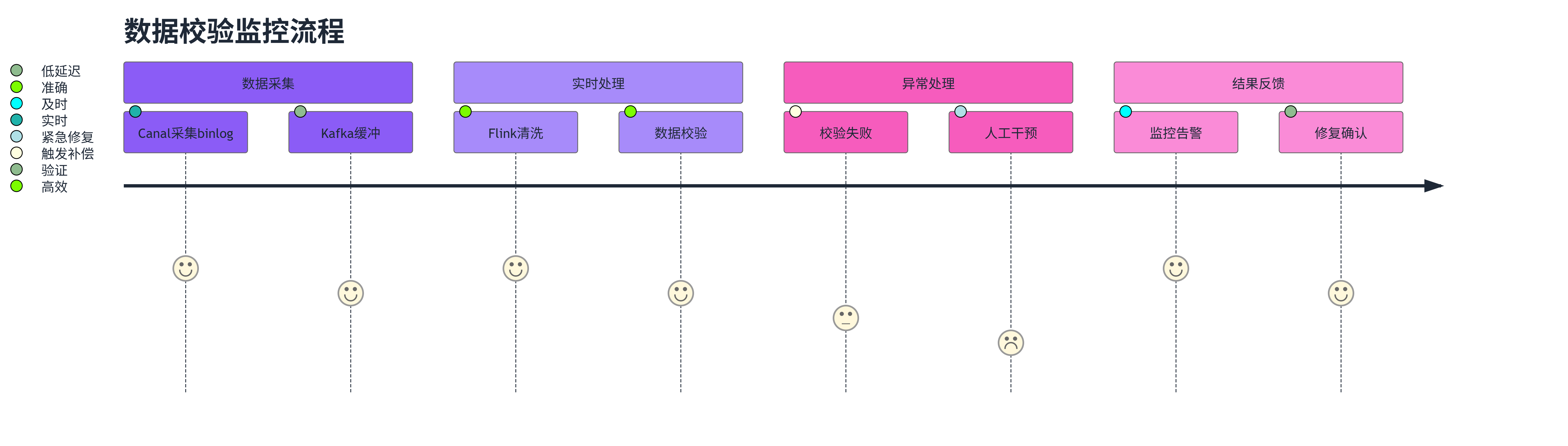
图3:校验监控流程 - journey - 展示了数据校验的完整监控流程
四、补偿机制实现
4.1 补偿策略设计
"在分布式系统中,补偿机制比强一致性更重要。" ------ CAP定理
基于这一原则,我们设计了智能补偿机制:
自动补偿 :对于可自动修复的数据差异,系统自动触发补偿
人工补偿 :对于复杂的数据问题,提供人工干预接口
批量补偿:支持批量数据重传和修复
4.2 补偿触发条件
补偿机制的触发条件包括:
- 数据延迟超过阈值:当数据延迟超过5秒时触发补偿
- 校验失败:实时或增量校验发现数据不一致时
- 系统异常:采集或处理环节出现异常时
4.3 补偿实现代码
java
@Component
public class DataCompensationService {
@Autowired
private CompensationExecutor executor;
@Autowired
private AlertService alertService;
public void handleCompensation(CompensationEvent event) {
CompensationContext context = buildContext(event);
try {
switch (event.getType()) {
case DELAYED_DATA:
handleDelayedData(context);
break;
case MISSING_DATA:
handleMissingData(context);
break;
case CORRUPTED_DATA:
handleCorruptedData(context);
break;
default:
log.warn("未知补偿类型: {}", event.getType());
}
} catch (Exception e) {
alertService.sendCriticalAlert("补偿失败", context, e);
}
}
private void handleDelayedData(CompensationContext context) {
// 1. 识别延迟数据范围
DateRange range = identifyDelayedRange(context);
// 2. 重新采集数据
List<Record> records = reCollectData(range);
// 3. 增量写入ClickHouse
executor.batchInsert(records);
// 4. 验证补偿结果
validateCompensation(range);
}
}五、延迟治理体系
5.1 延迟监控指标
我们建立了全面的延迟监控体系,关键指标包括:
- 端到端延迟:从MySQL写入到ClickHouse可用的总时间
- 采集延迟:Canal采集binlog的延迟时间
- 处理延迟:Flink处理数据的延迟时间
- 存储延迟:ClickHouse写入的延迟时间
5.2 延迟预警机制
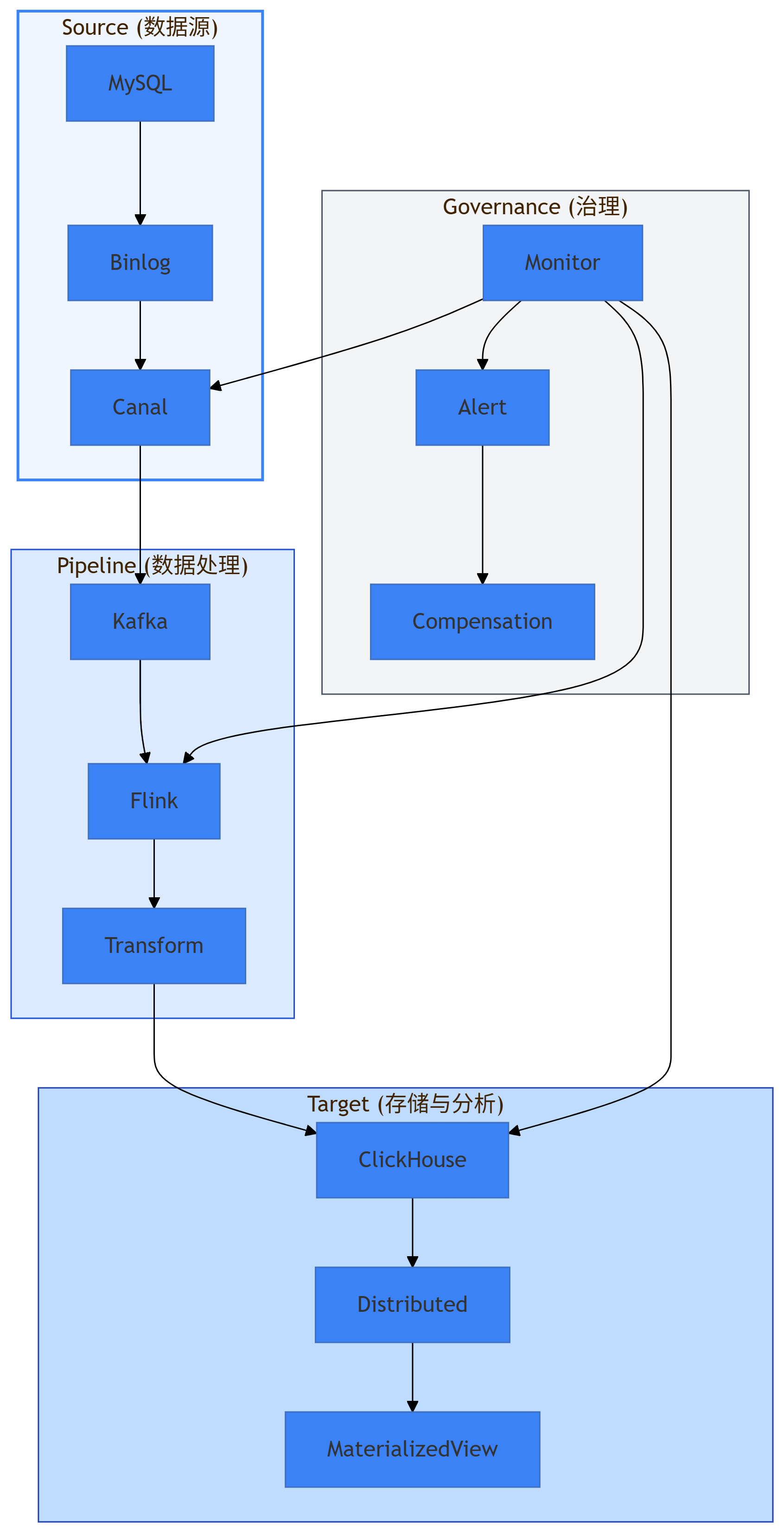
图4:延迟治理优先级矩阵 - quadrantChart - 展示了不同延迟问题的处理优先级
5.3 性能优化实践
Kafka优化:
- 分区数从12增加到48,提升并行度
- 压缩算法改为LZ4,减少网络传输开销
- 批量大小调整至16KB,平衡吞吐与延迟
Flink优化:
- 并行度根据CPU核心数动态调整
- Checkpoint间隔设置为30秒,减少状态恢复时间
- 使用RocksDB作为状态后端,提升状态访问性能
ClickHouse优化:
- 使用ReplicatedMergeTree引擎,提升写入性能
- 分区策略按天分区,避免小文件过多
- 索引优化,添加跳数索引减少扫描范围
六、数据一致性保障
6.1 一致性模型
我们采用了最终一致性模型,通过以下机制保证数据一致性:
幂等性设计 :所有数据处理操作都是幂等的,可以安全重试
版本控制 :每条数据都有版本号,支持冲突检测
时间窗口:基于时间窗口的一致性检查
6.2 一致性验证结果
经过3个月的实际运行,数据一致性达到了以下指标:
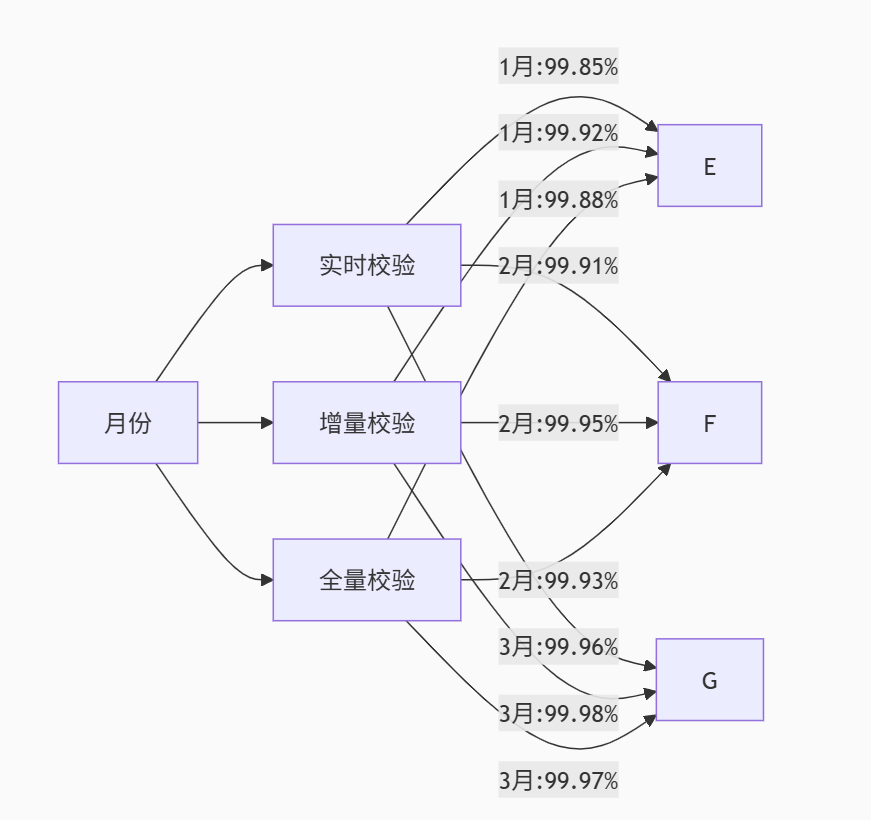
图5:一致性验证趋势图 - xychart-beta - 展示了3个月内数据一致性的提升趋势
6.3 异常处理机制
python
class ConsistencyMonitor:
def __init__(self):
self.checkers = [
RealTimeChecker(),
IncrementalChecker(),
FullChecker()
]
def run_consistency_check(self):
"""运行一致性检查"""
results = []
for checker in self.checkers:
try:
result = checker.check()
results.append(result)
if not result.is_consistent:
self.handle_inconsistency(result)
except Exception as e:
self.log_error(checker.__class__.__name__, e)
def handle_inconsistency(self, result):
"""处理数据不一致"""
severity = self.calculate_severity(result)
if severity == 'high':
self.trigger_immediate_compensation(result)
elif severity == 'medium':
self.schedule_compensation(result)
else:
self.log_warning(result)七、项目时间线
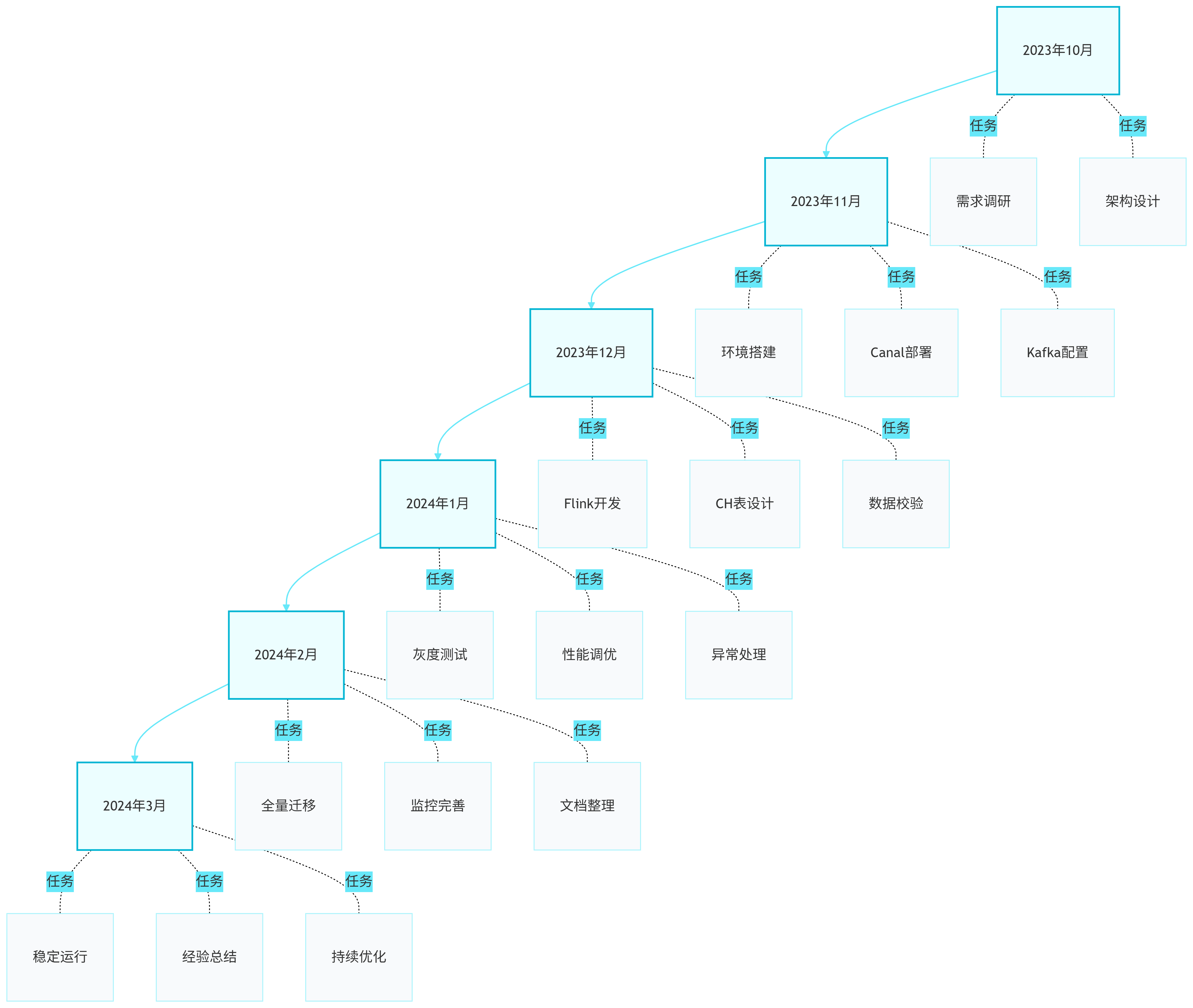
图6:项目时间线 - timeline - 展示了整个改造项目的6个月执行计划
八、总结与展望
这次MySQL到ClickHouse的明细分析链路改造,是一次充满挑战的技术攻坚。从最初的需求调研到最终的成功上线,我们经历了无数次的技术选型和方案迭代。
通过这次改造,我们不仅解决了业务痛点,更重要的是建立了一套完整的数据治理体系。这套体系包括:
- 三层校验机制:实时校验、增量校验、全量校验,确保数据一致性
- 智能补偿系统:自动补偿+人工干预,快速修复数据问题
- 延迟治理体系:从监控到优化,全方位保障系统性能
- 可观测性建设:让系统运行状态透明可见
"数据治理不是一次性的项目,而是持续演进的过程。" ------ 数据治理第一性原理
未来,我们还将面临更多挑战:
- 实时性进一步提升:从5秒延迟到1秒延迟
- 成本优化:在保证性能的前提下降低存储成本
- 智能化运维:引入AI算法进行异常检测和自动修复
- 多活容灾:构建跨地域的多活架构
技术之路永无止境,每一次改造都是新的起点。希望我们的经验能为同行提供参考,也期待与更多技术人交流探讨,共同推动数据技术的发展。
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
关键词标签
MySQL, ClickHouse, 数据迁移, 实时同步, 数据治理, Flink, Canal, 一致性校验, 延迟优化, 分布式系统