GFSS General Few-Shot Segmentation
- 任务实现方式与zero-shot有所不同
- 本篇论文只涉及同一个模态 (图像),训练过程中,novel class有几个图像提供,提供k个就称之为k-shot。
- 先从图像中提取class prototype ,然后这个原型向量作为查询,与图像的patch嵌入计算相似度,然后得到最后的掩码矩阵。
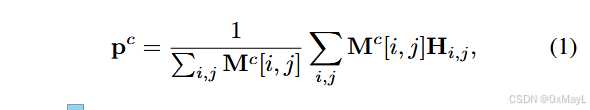
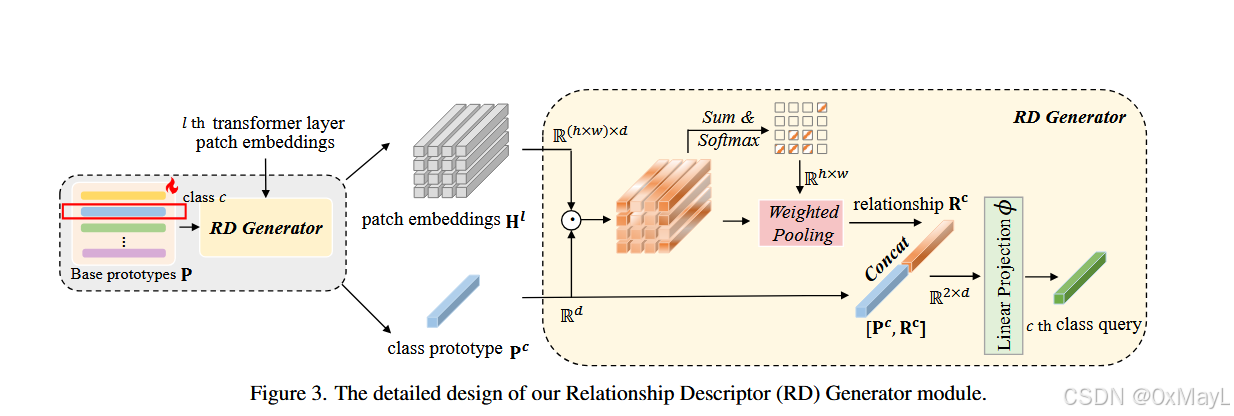
RD
-
先对patch嵌入和原型作逐元素乘法,然后赋予其特定权重。权重就是二者的相似度分数。
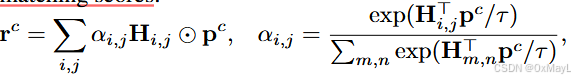
-
从VIT中提取多个patch嵌入,拼接在一起,经过线性层作为key,value。
-
拼接多个VIT layer的RD和类别原型向量,经过线性层作为query。
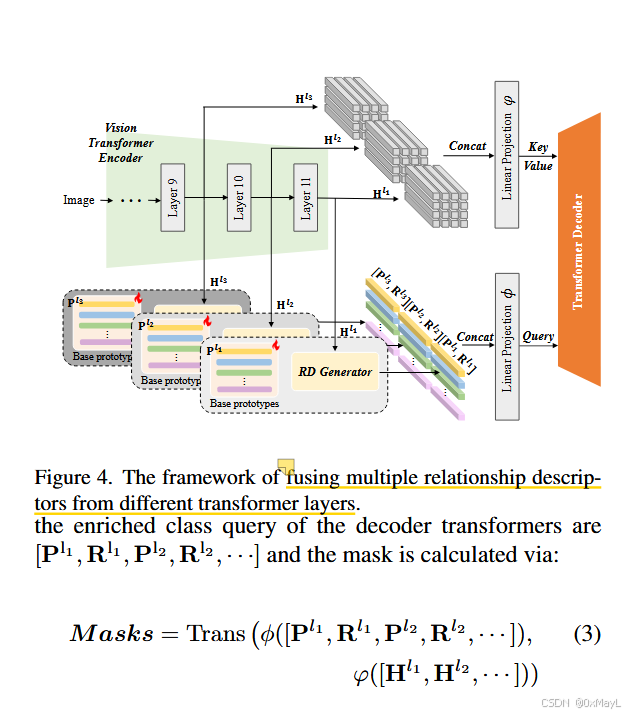
局限
依赖ViT单模态能力、计算成本高、对小样本噪声敏感。