在【LLM】LLM 中增量解码与模型推理解读一文中对 LLM 常见名词进行了介绍,本文会对 LLM 中评价指标与训练概要进行介绍,本文并未介绍训练实操细节,未来有机会再了解~
一、LLM 如何停止输出
在看 LLM 评价指标前,先看看 LLM 如何停止输出。
大模型常通过以下几种策略控制生成终止:
1.结束符号(EOS Token)
模型生成特殊终止符(如 DeepSeek R1 MoE 中 ID 为 1 的 token)表示回答完成。
Plain
...在物理学领域做出了革命性贡献。[EOS] 2.最大长度限制
预设生成 token 上限(常见值:512/1024/2048),防止无限生成,保障系统资源安全。
3.停止词 / 序列触发
设置 "\n\n""###" 等符号为停止信号,强制结束生成(适用于格式控制)。
4.内容智能判断
- 重复检测:识别循环或冗余内容时自动终止。
- 语义完整性:当回答覆盖查询所有维度(如时间、影响)时停止。
停止机制建议组合使用(如 EOS + 最大长度),确保生成既完整又可控。
综合来看,Decode 阶段的循环机制是大模型实现长文本生成的核心:
- 效率优化:通过 KV 缓存复用大幅降低计算成本;
- 可控生成:多维度停止策略平衡输出质量与资源消耗;
- 语义连贯:自回归模式确保上下文逻辑衔接紧密。
二、LLM 评价指标
常见 LLM 评价指标如下:
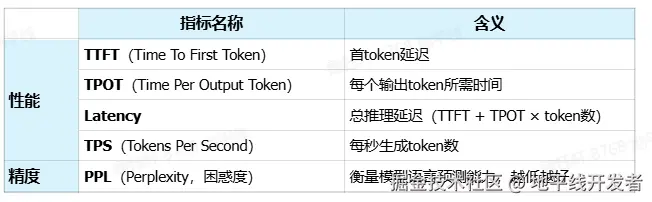
三、LLM 训练概要
本节主要参考: zhuanlan.zhihu.com/p/719730442 zhuanlan.zhihu.com/p/191210110...
- 数据准备:喂给模型"知识"
- 收集数据:从互联网、书籍、论文等获取海量文本(如英文维基百科+书籍+网页)。
- 清洗数据:过滤垃圾、重复内容、有害信息,保留高质量文本。
- 分词(Tokenization):把文本拆成"词语片段"(如用 Byte-Pair Encoding 或 SentencePiece)。
- 模型设计:搭建"大脑"结构
- 选择架构:通常用 Transformer 解码器堆叠(如 GPT 系列)。
- 确定参数量:比如 70 亿、150 亿参数(参数越多,模型越强,但计算成本越高)。
- 预训练(Pre-training):自主学习语言规律
- 任务目标:通过自监督学习预测文本中的缺失部分(如遮蔽语言建模,Masked Language Modeling)
- 自回归(AutoRegressive):根据上文预测下一个词(如 GPT 系列)。
- 掩码预测(Masked Modeling):随机遮蔽部分词,让模型填补空缺(如 BERT)。
- 训练方法:
- 输入一段文本 → 模型预测下一个词 → 计算损失(预测误差) → 反向传播更新参数。
- 重复数万亿次(用 GPU/TPU 集群加速),直到模型学会语言规律。
- 任务目标:通过自监督学习预测文本中的缺失部分(如遮蔽语言建模,Masked Language Modeling)
- 微调(Fine-tuning):定向优化能力 场景化训练:用特定任务的数据(如客服对话、医疗问答)进一步优化模型。
- 监督微调(SFT):人工标注的高质量问答对,教模型生成更准确的回答。
- 强化学习(RLHF):让人类对模型输出打分,通过奖励机制优化(如 ChatGPT 的训练方法)。
- 评估与部署:测试和落地
- 评估指标:用困惑度(Perplexity)、准确率等指标测试模型性能。
- 部署上线:压缩模型(如量化、剪枝),部署到服务器供用户调用。
四、LLM 中学习策略
在上面的训练过程中,提到了"自监督学习"、"强化学习"这几个概念。这些都属于大模型训练过程中的学习策略或者叫学习范式,以下是对不同学习策略的总结和对比:
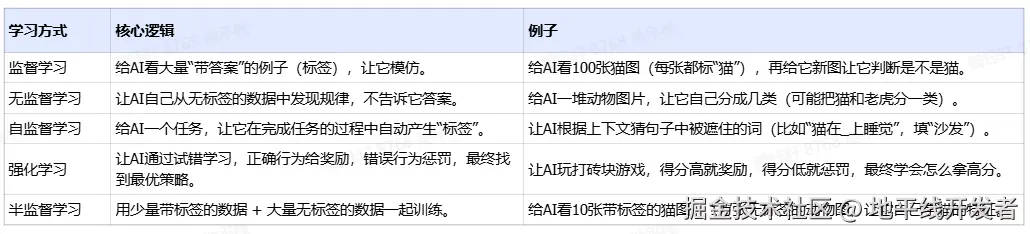
- 监督学习的标签是人工标注的,这是 CNN 这些架构训练模型或算法很常见的方法。标注的意思就是我们喂给模型的数据会被人工提前标注出特征点,比如我们会给很多图片中的汽车做出标记,目的是告诉大模型我们打标签的这些图形就是汽车,让大模型记住它。
- 强化学习不需要大量的人工标注,只是需要设计一个奖励函数,设计好奖励规则,当模型给出的结果是接近目标值的,我们就给一个正反馈或者高的分数。
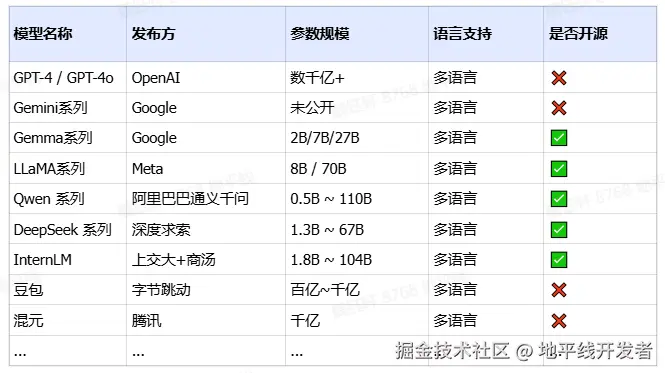
五、常见 LLM 模型
常见 LLM 模型如下表
六、LLM 的挑战与展望
6.1 挑战
- 幻觉现象(Hallucination):生成看似合理但事实错误的内容。
- 推理成本高:内存与计算资源消耗大,部署成本高昂。
- 推理速度慢:长文本响应延迟显著影响用户体验。
- 数据安全与偏见问题:训练数据中可能包含歧视或敏感信息。
6.2 展望
LLM 目前已用于多个场景,例如:
- 文本生成:自动撰写新闻、故事、诗歌。
- 翻译系统:多语言互译,甚至语音到文本。
- 情绪分析:用于品牌情感监测、影评判断。
- 对话机器人:如 ChatGPT,提供自然流畅的对话能力。
- 代码生成:辅助编程任务,生成/解释代码。
近年来也发展出支持图像、语音、视频等多模态输入的 VLM(Vision-Language Models)和 VLA(Vision-Language-Action),可以研究学习的地方非常多。
后续会转到 VLM 的学习~