论文题目:Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation(提示深度任何4K分辨率准确的度量深度估计)
会议:CVPR2025
摘要:提示在为特定任务释放语言和视觉基础模型的力量方面发挥着关键作用。我们首次将提示引入深度基础模型,创建了一种新的度量深度估计范式,称为提示深度任意。具体来说,我们使用低成本的激光雷达作为提示来引导Depth Anything模型进行精确的度量深度输出,实现高达4K的分辨率。我们的方法以简洁的快速融合设计为中心,在深度解码器中集成了多个尺度的激光雷达。为了解决包含LiDAR深度和精确GT深度的有限数据集带来的训练挑战,我们提出了一个可扩展的数据管道,包括合成数据LiDAR模拟和真实数据伪GT深度生成。我们的方法在ARKitScenes和scannet++数据集上设置了最新的技术水平,并有利于下游应用,包括3D重建和广义机器人抓取。
源码链接:https://PromptDA.github.io/
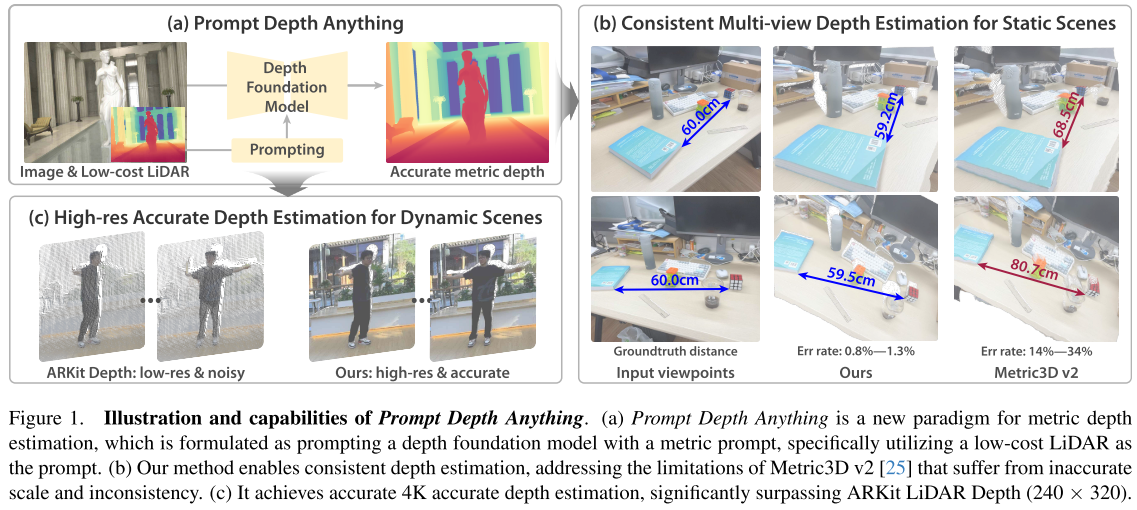
引言:深度估计的新纪元
想象一下,如果我们能像使用ChatGPT那样,通过简单的"提示"就能让AI精确理解三维世界的深度信息,这将为自动驾驶、机器人操作等领域带来怎样的变革?今天要介绍的这篇CVPR 2025论文"Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation",就实现了这样一个令人兴奋的突破。
问题的核心
近年来,深度估计领域涌现出了许多强大的基础模型,如Depth Anything、MiDaS等。这些模型在产生高质量相对深度方面表现出色,但都面临一个共同的致命问题:尺度歧义性。
简单来说,这些模型能告诉你"A比B远",但无法告诉你"A距离你5米,B距离你8米"。这种缺乏绝对尺度信息的问题,严重限制了这些强大模型在实际应用中的价值。
创新思路:将"提示"概念引入深度估计
论文作者受到自然语言处理中提示学习成功的启发,提出了一个革命性的想法:为什么不用"提示"来指导深度基础模型产生精确的度量深度呢?
核心创新1:低成本LiDAR作为"度量提示"
作者选择了手机上广泛可用的低成本LiDAR(如iPhone的ARKit深度传感器)作为"度量提示"。这个选择非常巧妙:
- 精确的尺度信息:LiDAR能提供准确的距离测量
- 广泛可用:现在很多智能手机都配备了LiDAR传感器
- 互补性强:LiDAR提供稀疏但准确的深度,RGB图像提供丰富的视觉细节
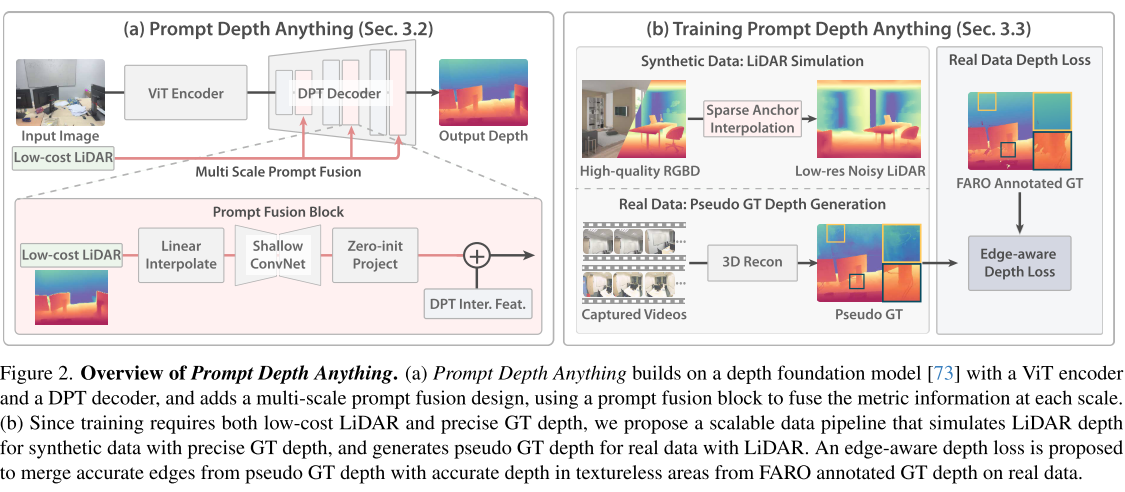
核心创新2:多尺度提示融合架构
论文设计了一个简洁而有效的提示融合架构:
输入图像 → ViT编码器 → DPT解码器(融合LiDAR提示)→ 输出深度
↗
低成本LiDAR ------------------------------------------------------------------------------------------------------------------------------------------------↗在DPT解码器的每个尺度上,系统都会:
- 将LiDAR深度图调整到对应尺度
- 通过浅层卷积网络提取深度特征
- 使用零初始化投影层融合到图像特征中
这种设计的优势:
- 轻量级:仅增加5.7%的计算开销
- 即插即用:完全继承预训练深度基础模型的能力
- 零初始化:确保初始输出与原始基础模型相同
核心创新3:可扩展的训练数据流水线
训练Prompt Depth Anything面临一个挑战:需要同时拥有LiDAR深度和精确GT深度的数据,但这样的数据非常稀少。论文提出了创新的解决方案:
合成数据LiDAR模拟:
- 不是简单下采样,而是使用"稀疏锚点插值"方法
- 模拟真实LiDAR的噪声特性
- 避免模型学习简单的超分辨率
真实数据伪GT生成:
- 使用Zip-NeRF重建高质量深度图
- 解决原始FARO扫描深度图的边缘质量问题
边缘感知深度损失:

L_edge = L1(D_gt, D̂) + λ · L_grad(D_pseudo, D̂)- 结合FARO深度的平坦区域优势和伪GT深度的边缘优势
- 实现最优的监督信号
实验结果:全面超越现有方法
定量结果令人震撼
在ARKitScenes数据集上:
- L1误差:0.0135 vs 最佳竞争对手的0.0153(提升12%)
- RMSE:0.0326 vs 0.0369(提升12%)
在ScanNet++数据集上:
- L1误差:0.0250 vs 0.0326(提升23%)
- 准确率δ0.5:97.81% vs 96.74%
更令人印象深刻的是,零样本模型就能超越其他方法的非零样本性能,充分证明了提示深度基础模型的强大泛化能力。
应用效果显著
3D重建:
- 生成的点云更加完整和准确
- 在复杂室内场景中表现出色
机器人抓取:
- 对透明、镜面反射物体的抓取成功率显著提升
- 在不同距离的物体抓取中表现稳定
技术优势与影响
即时影响
- 实用性强:利用广泛可用的手机LiDAR,降低了应用门槛
- 效率高:ViT-L版本在768×1024分辨率下达到20.4 FPS
- 扩展性好:可以轻松替换不同的深度基础模型和LiDAR传感器
长远意义
- 范式转变:开创了深度估计的"提示时代"
- 启发性强:为其他计算机视觉任务引入提示概念提供了范例
- 产业价值:为AR/VR、自动驾驶、机器人等产业带来直接价值
未来展望
虽然这项工作取得了突破性进展,但仍有改进空间:
- 长距离处理:iPhone LiDAR在远距离物体上噪声较大
- 时间一致性:LiDAR深度的时间闪烁问题需要解决
- 提示扩展:探索其他形式的度量提示(如相机内参、尺度参考物等)