本次使用的es是6.5版本的
ElasticSearch介绍
ElasticSearch介绍
- ES是一个使用Java语言并且基于!ucene编写的搜索引擎框架,他提供了分布式的全文搜索功能,提供了一个统一的基于RESTFUl风格的WEB接口,官方客户端也对多种语言都提供了相应的API。
- Lucene:Lucene本身就是一个搜索引擎的底层。
- 分布式:ES主要是为了突出他的横向扩展能力。
- 全文检索:将一段词语进行分词,并且将分出的单个词语统一的放到一个分词库中,在搜索时,根据关键字去分词库中检索,找到匹配的内容。(倒排索引)
- RESTFUL风格的WEB接口:操作ES很简单,只需要发送一个HTTP请求,并且根据请求方式的不同,携带参数的不同,执行相应的功能。
ES和Solr
- Solr在查询死数据时,速度相对ES更快一些。但是数据如果是实时改变的,solr的查询速度会降低很多。ES的查询的效率基本没有变化。
- Solr搭建基于需要依赖zeokeeper来帮助管理。ES本身就支持集群的搭建,不需要第三方的介入。
- 最开始Solr的社区可以说是非常火爆,针对国内的文档并不是很多。在ES出现之后,ES的社区火爆程度直线上升,ES的文档非常健全。
- ES对现在云计算和大数据支持的特别好。
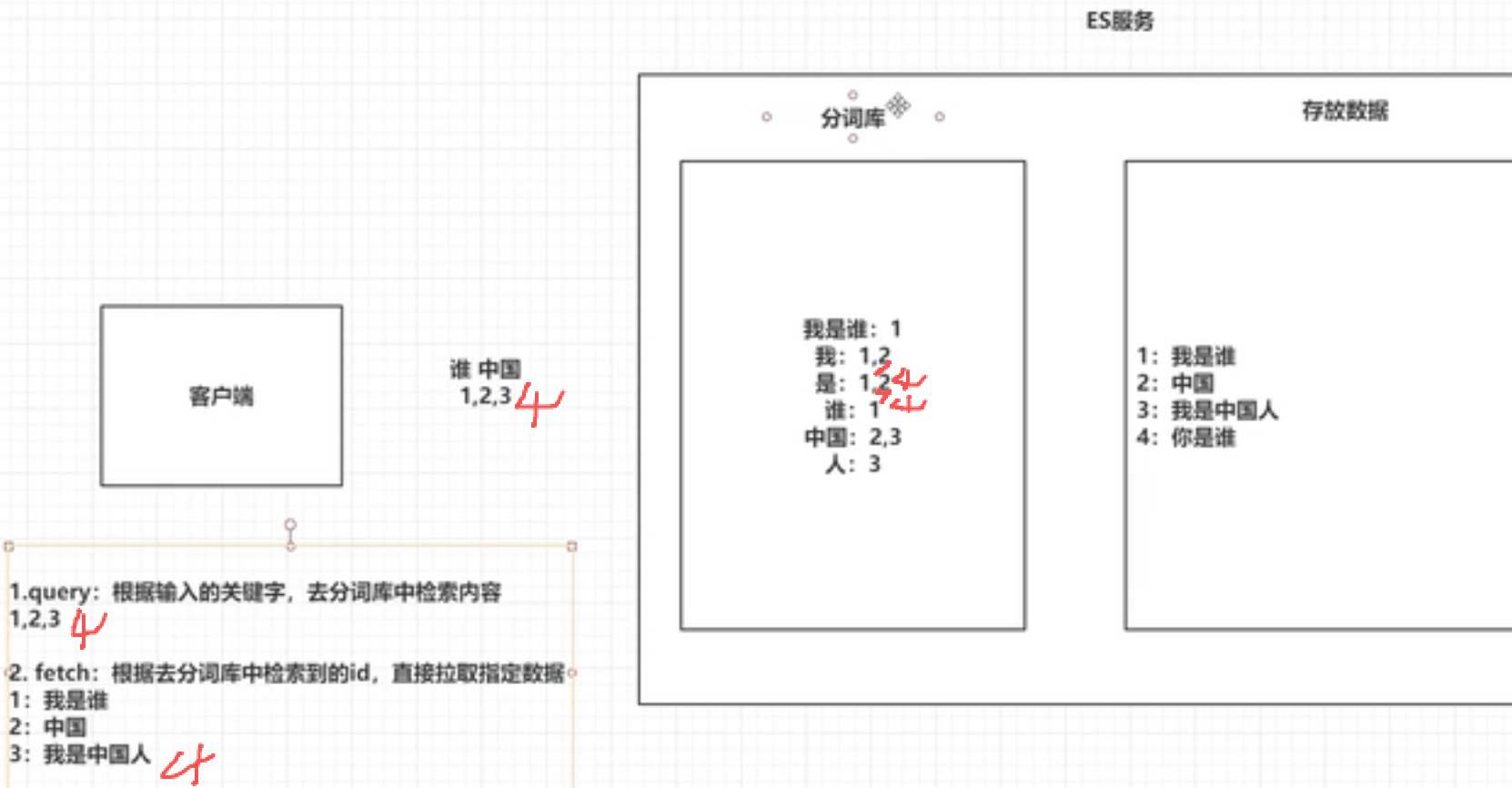
倒排索引
将存放的数据,以一定的方式进行分词,并且将分词的内容存放到一个单独的分词库中当用户去查询数据时,会将用户的查询关键字进行分词,然后去分词库中匹配内容,最终得到数据的id标识。根据id标识去存放数据的位置拉取到指定的数据。
安装
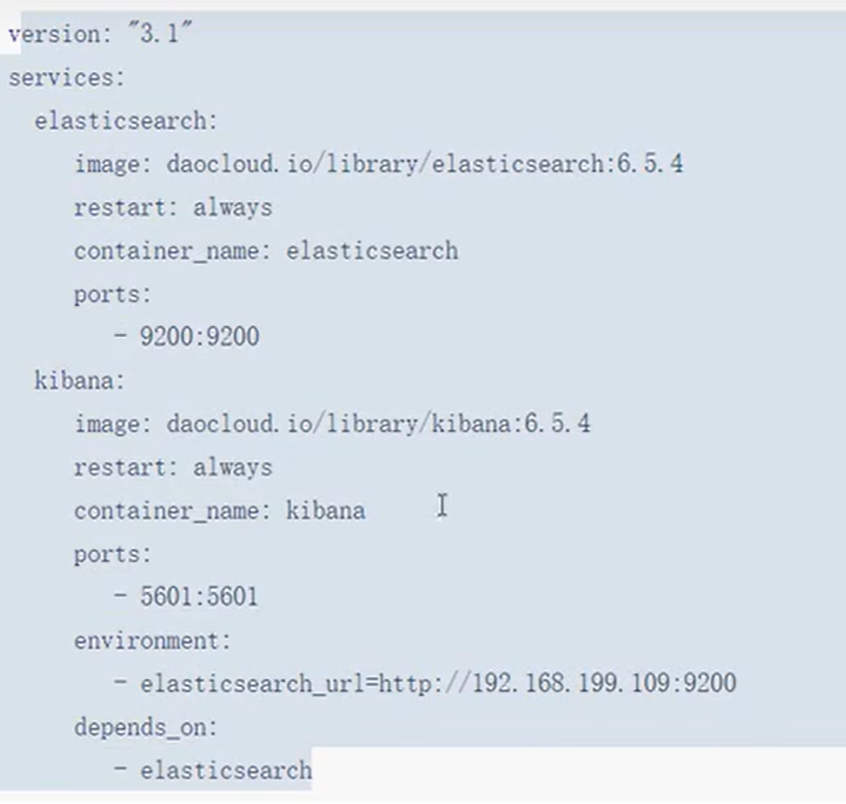
ElasticSearch和kibana
docker compose ymal文件
ik分词器
进入es环境中的bin目录安装
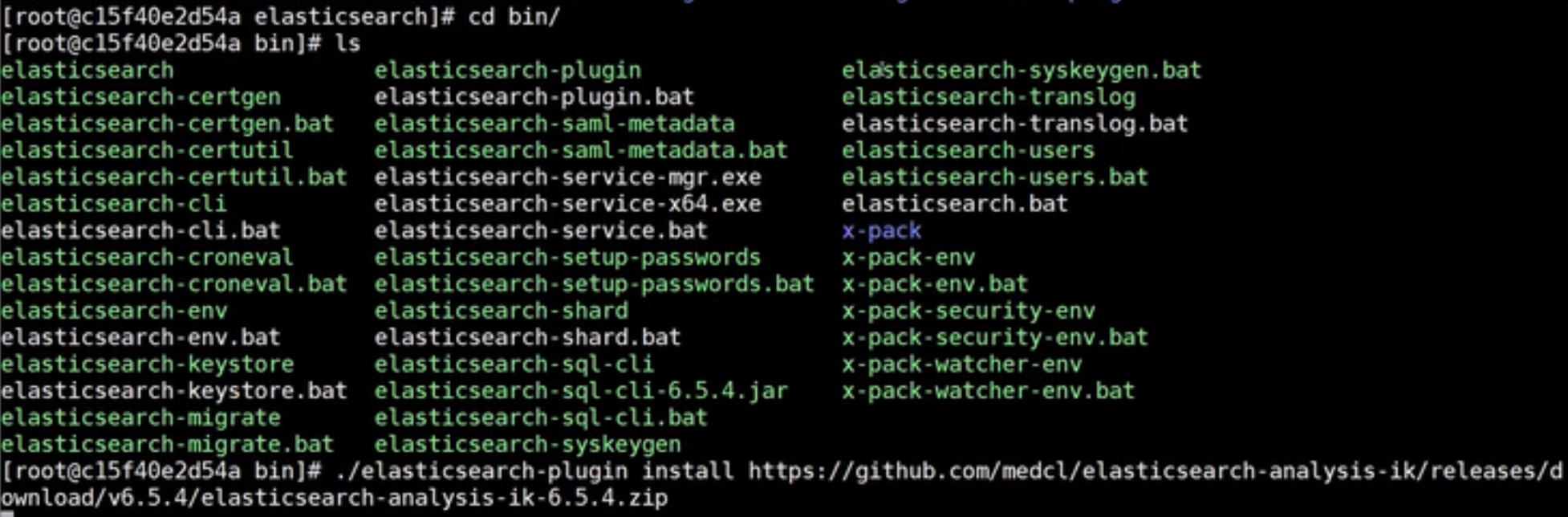
然后重启es
验证
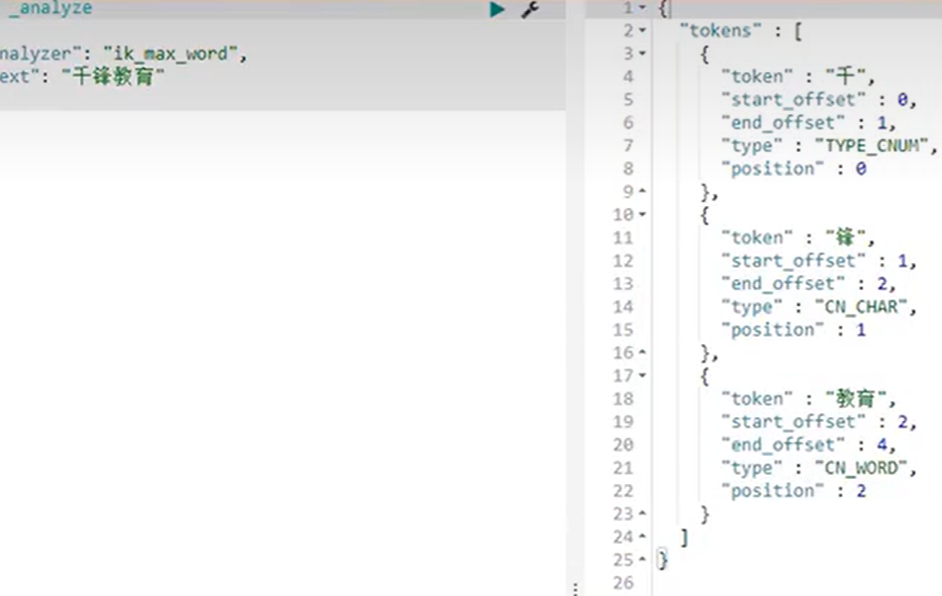
基本操作
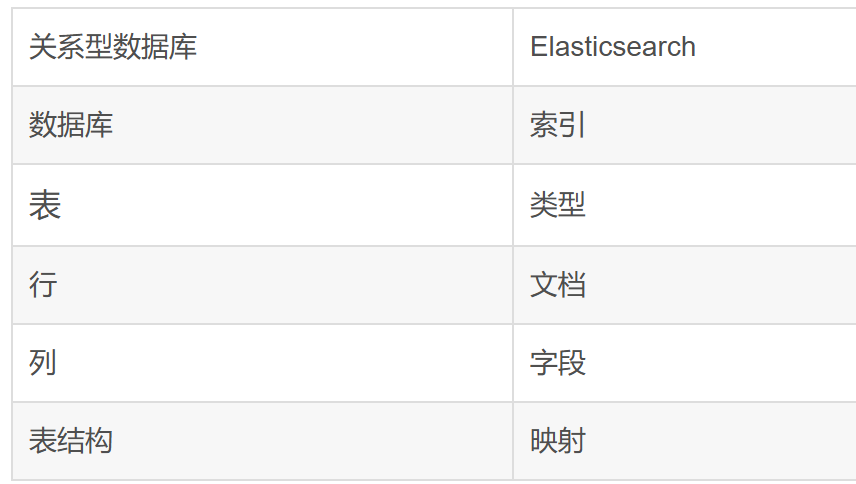
es vs 关系型数据库
索引
- ES的服务中,可以创建多个索引。
- 每一个索引引默认披分成5片存储。
- 每一个分片都会存在至少一个备份分片。备份分片默认不会帮助检索数据,当ES检索压力特别大的时候,备份分片才会帮助检索数据。
- 备份的分片必须放在不同的服务器中。
TYPE
ES5.x版本中,一个Index下可以创建多个TyPE,ES6.x版本一个Index下可以创建一个Type.ES6.x版本中,ES7.x版本中,一个Index下没有Type.
document
相当于关系数据库中的记录
filed
相当于关系数据库中的列
es中restful的语法api
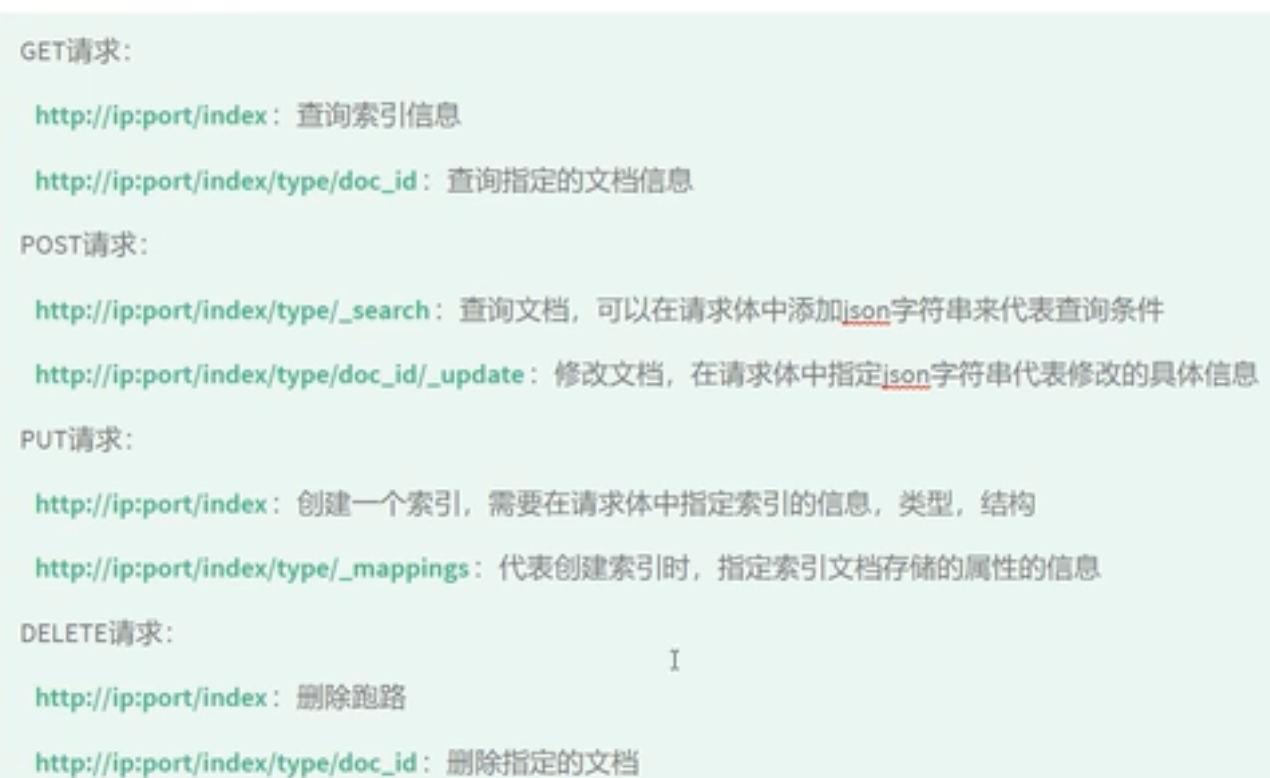
索引操作
建立索引

查看索引
kibana页面操作
或者
删除索引
kibana页面操作
或者接口

类型


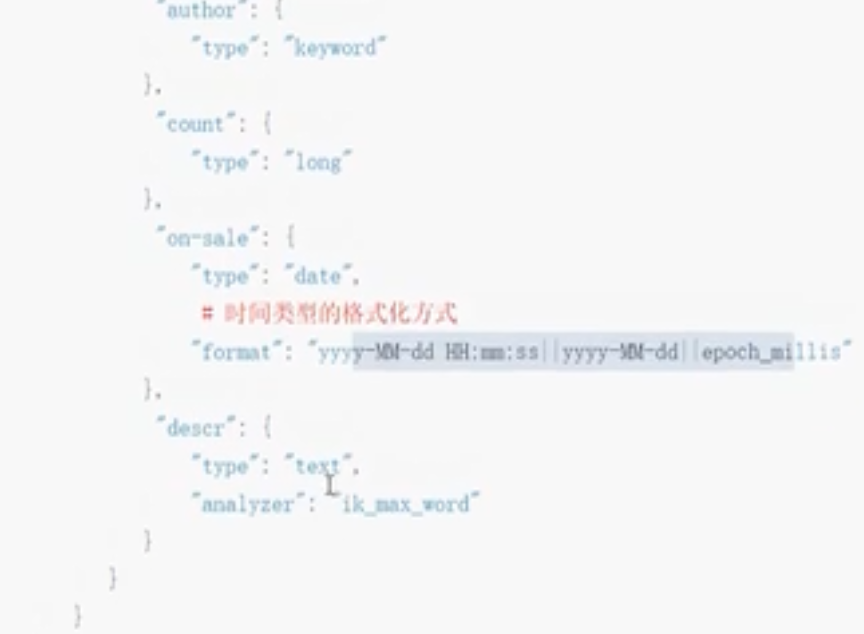
创建索引并指定数据类型

文档操作
文档在ES服务中的唯一标识,_index,_type,_id 三个内容为组合,锁定一个文档,操作时添加还是修改
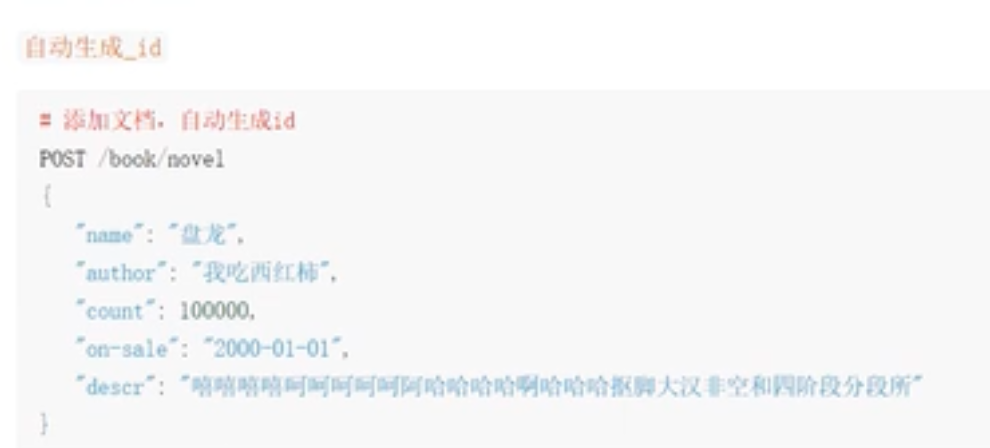
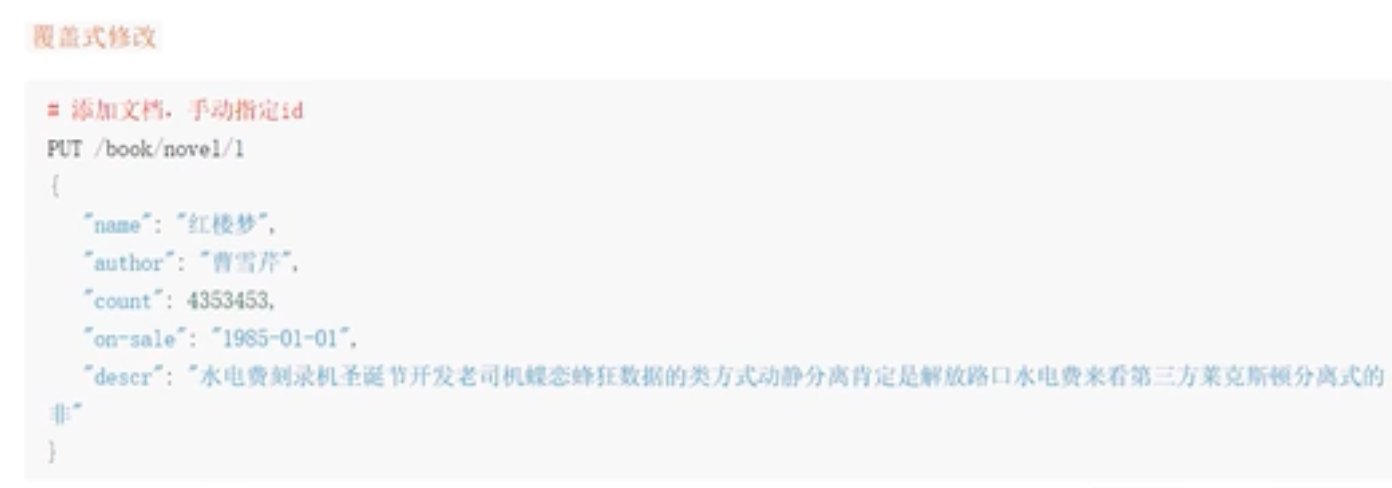
添加文档

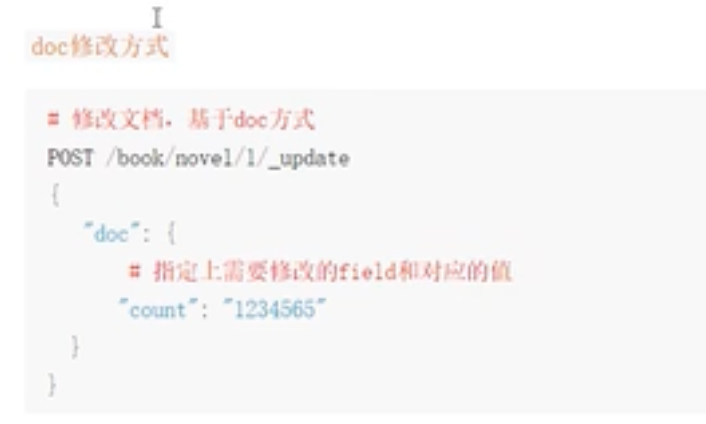
更新文档
删除文档
ElasticSearch各种查询
term和terms查询
term查询
term的查询是代表完全匹配,搜索之前不会对你搜索的关键字进行分词,对你的关键字去文档分词库中去匹配内容。

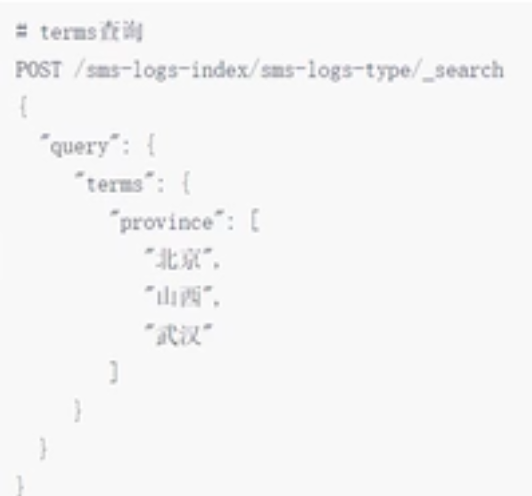
terms查询

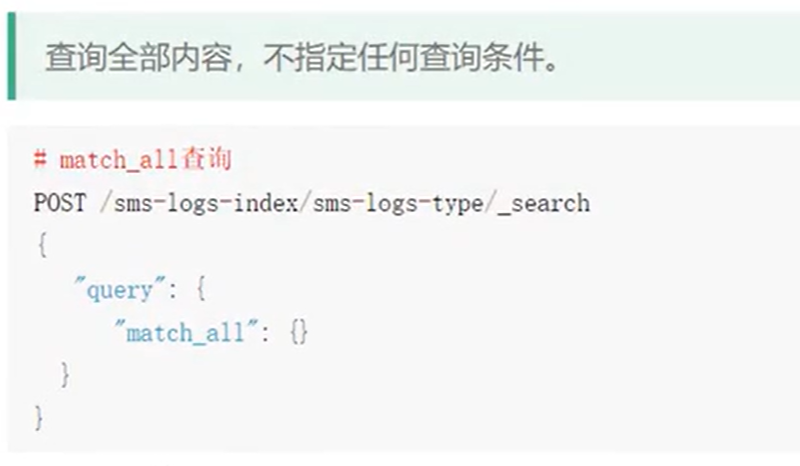
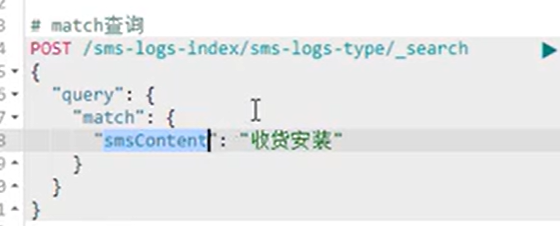
match查询
- match查询属于高层查询,他会根据你查询的字段类型不一样,采用不同的查询方式。
- 查询的是日期或者是数值的话,他会将你基于的字符串查询内容转换为日期或者数值对待。。如果查询的内容是一个不能被分词的内容(keyword),match查询不会对你指定的查询关键字进行分词。
如果查询的内容时一个可以被分词的内容(text),match会将你指定的査询内容根据一定的方式去分词,去分词库中匹配指定的内容。 - match查询,实际底层就是多个term查询,将多个term查询的结果给你封装到了一起
match_all
match查询
bool match查询
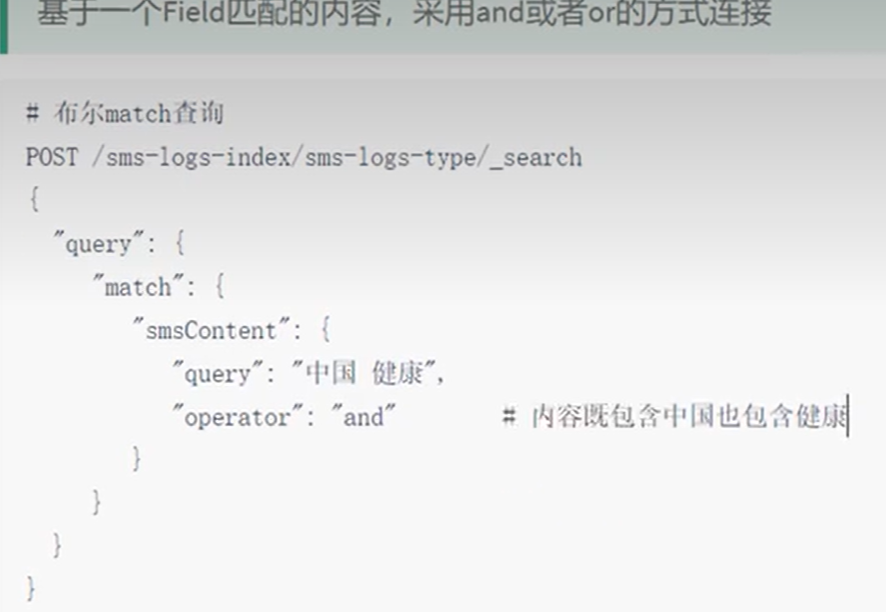
multi_match
其他查询
id查询
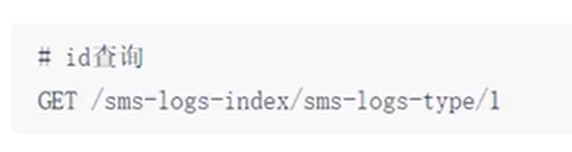
ids查询
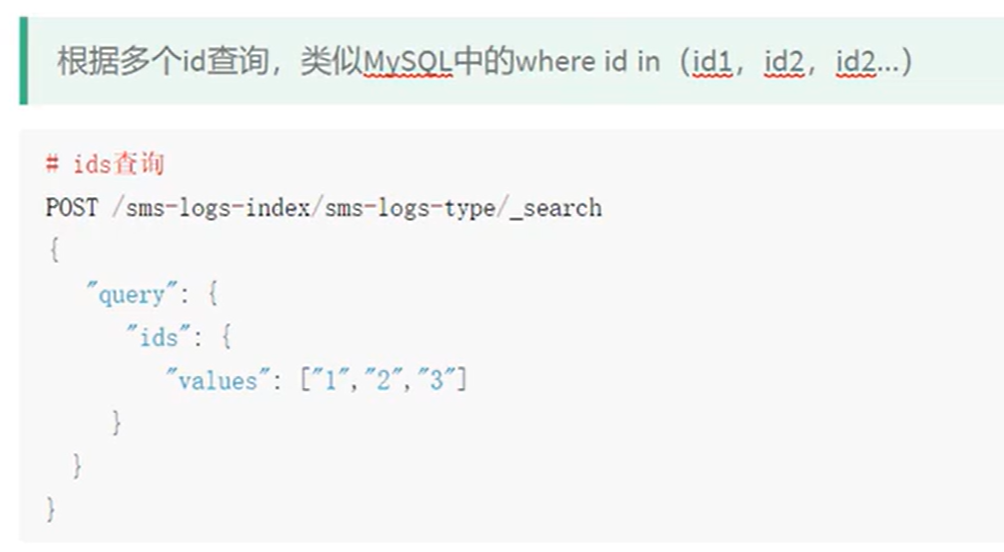
prefix查询
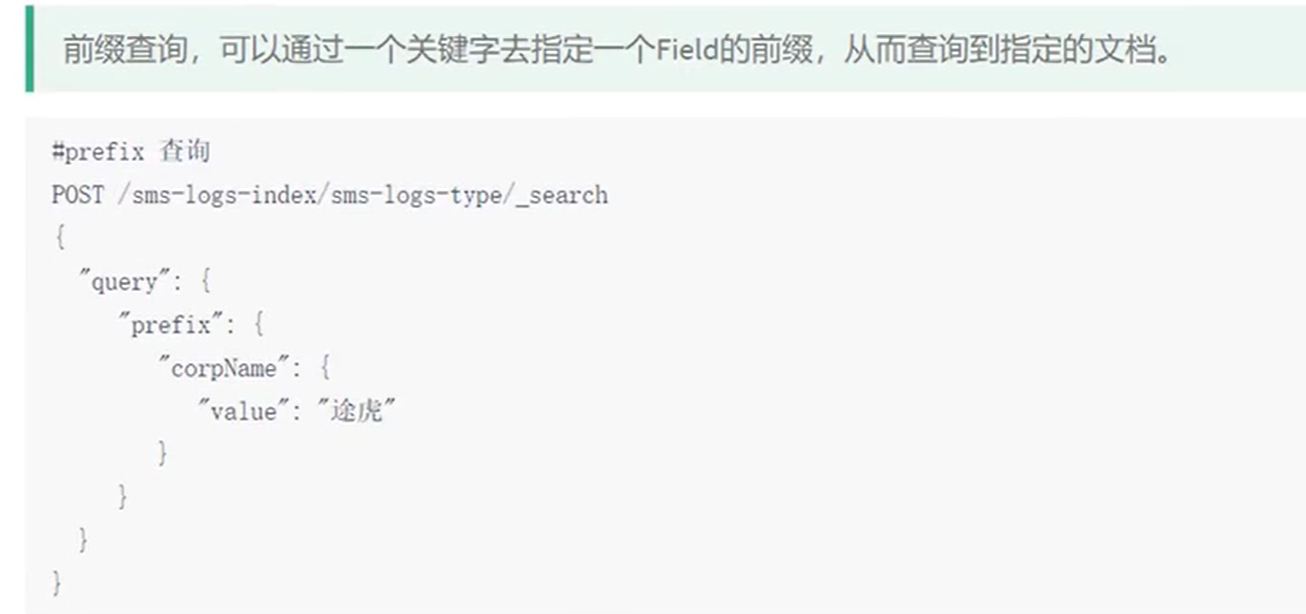
fuzzy查询
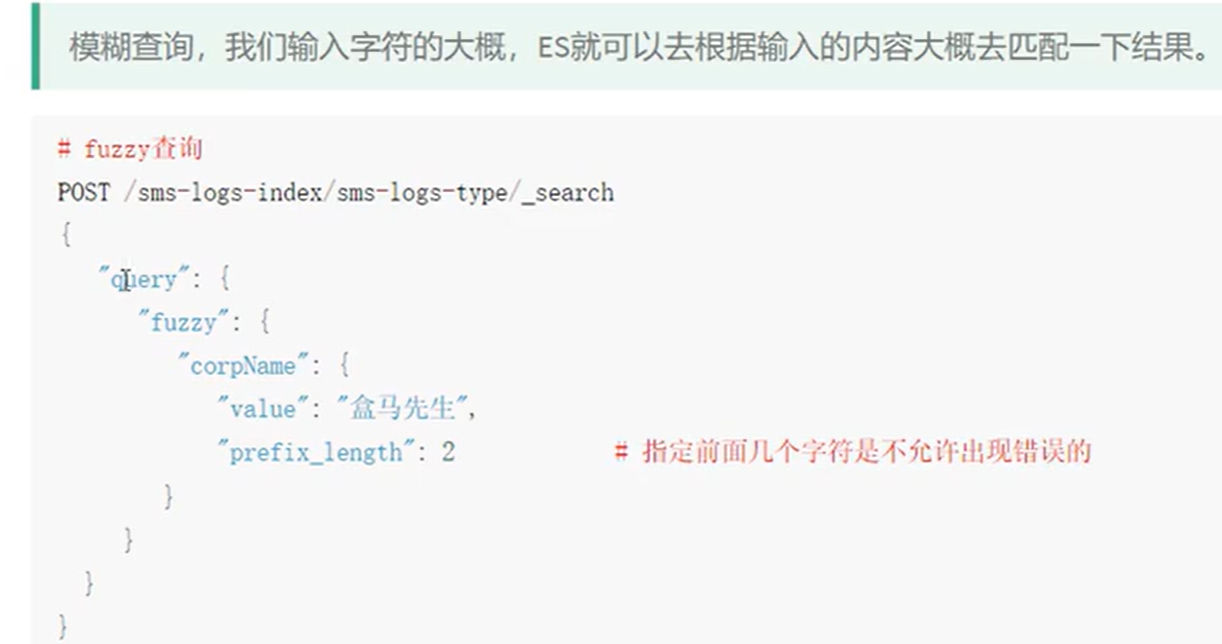
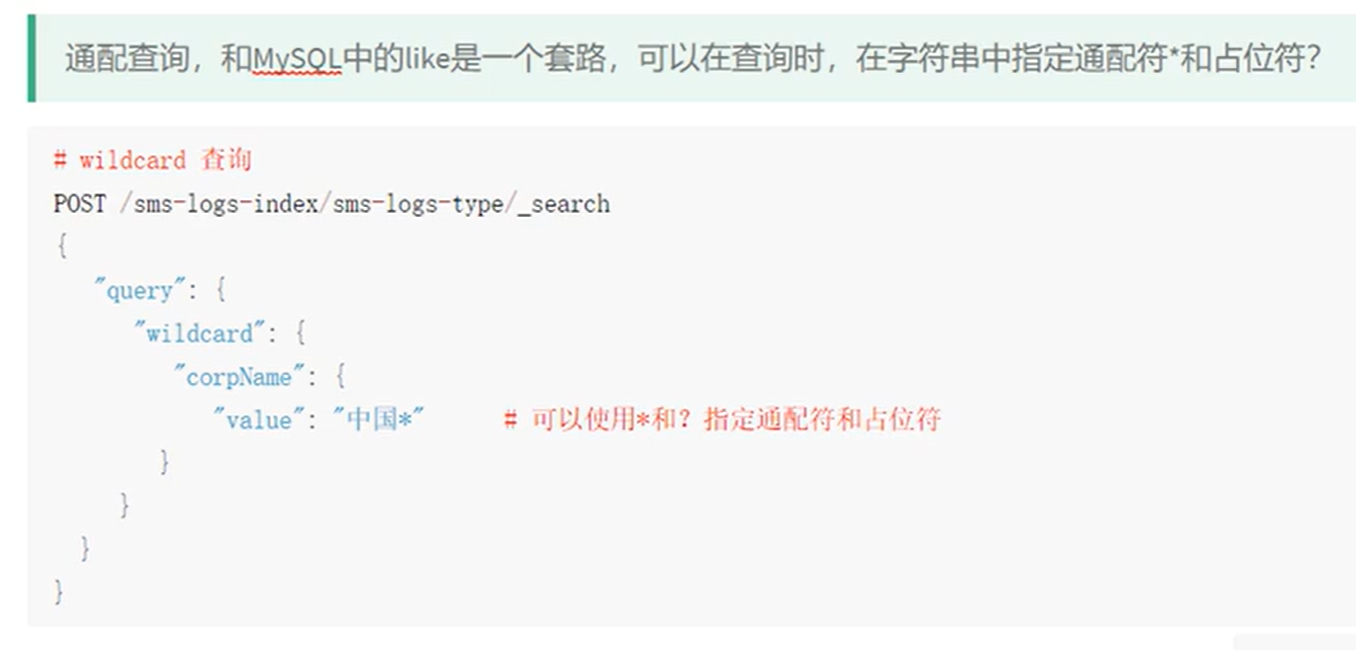
wildcard查询
range查询

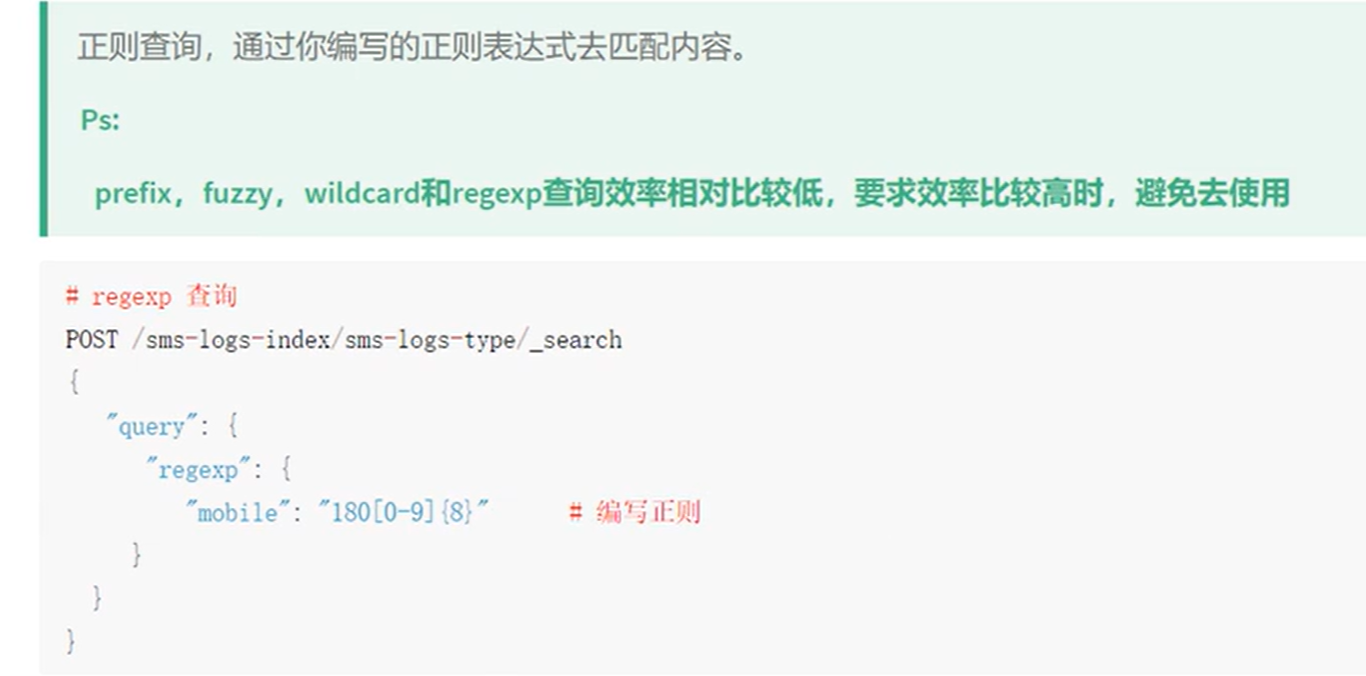
regexp查询
深分页scroll
现将用户指定的关键进行分词。
ES对from+size是有限制的,from和size二者之和不能超过1W原理:
-
from+size在ES查询数据的方式:
第一步现将用户指定的关键进行分词。
第二步将词汇去分词库中进行检索,得到多个文档的id。
第三步去各个分片中去拉取指定的数据。耗时较长。
第四步将数据根据score进行排序。耗时较长。
第五步根据from的值,将查询到的数据舍弃一部分。
第六步返回结果。
-
ScrolI+size在ES查询数据的方式(不适合实时数据):
第一步现将用户指定的关键进行分词。
第二步将词汇去分词库中进行检索,得到多个文档的id。
第三步将文档的id存放在一个ES的上下文中。
第四步根据你指定的size去ES中检索指定的数据,拿完数据的文档id,会从上下文中移除。
第五步如果需要下一页数据,直接去ES的上下文中,找后续内容。
第六步循环第四步和第五步


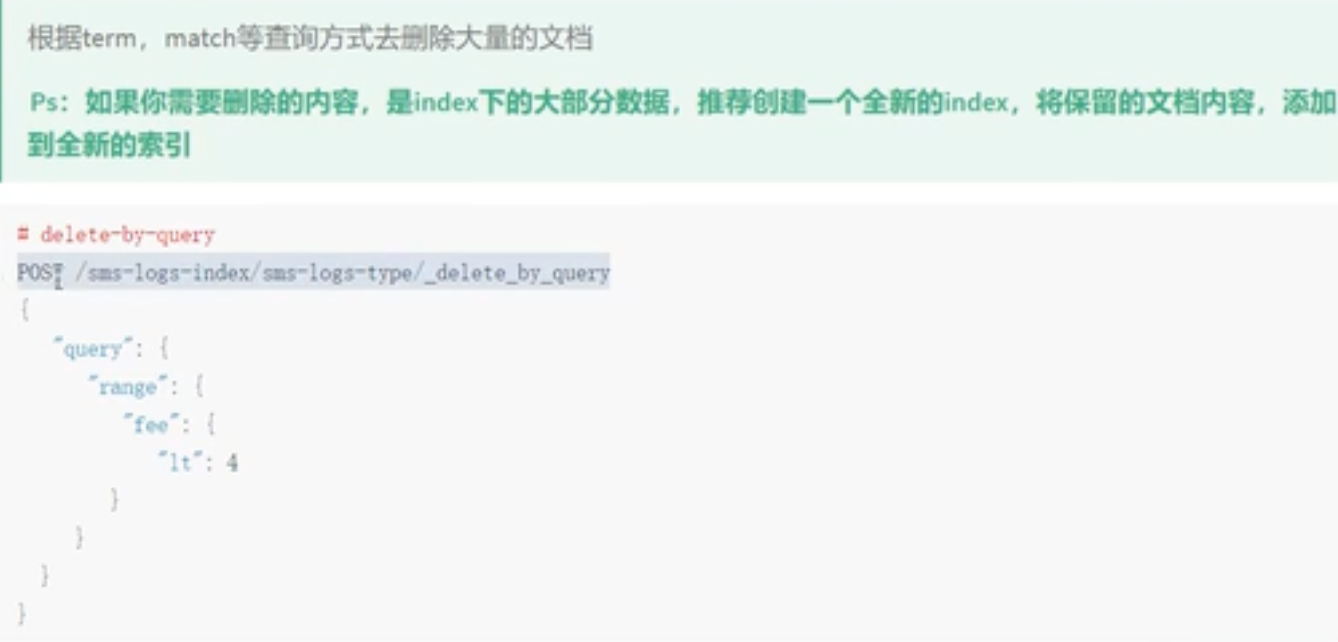
delete-by-query
复合查询
bool查询



boosting查询


filter查询
- query,根据你的查询条件,去计算文档的匹配度得到一个分数,并且根据分数进行排序,不会做缓存的。
- filter 根据你的靠询条件去查询文档,不去计算分数,而且fter会对经常被过滤的数据进行缓存。

高亮查询


聚合查询
ES的聚合查询和MySQL的聚合査询类型,ES的聚合查询相比MYSQL要强大的多,ES提供的统计数据的方式多种多样。

去重计数
,即cardinality,第一步先将返回的文档中的一个指定的field进行去重,统计一共有多少条

range查询
统计一定范围内出现的文档个数,比如,针对某一个Field的值在 0-100,100-200,200-300之间文档出现的个数分别是多少。
范围统计可以针对普通的数值,针对时间类型,针对ip类型都可以做相应的统计。
range, date_range,ip_range

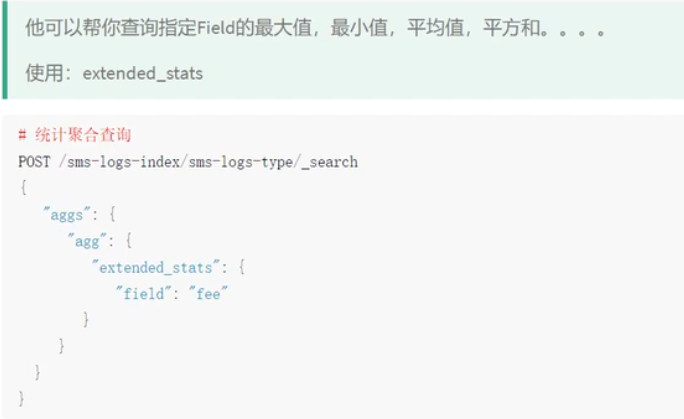
统计聚合查询
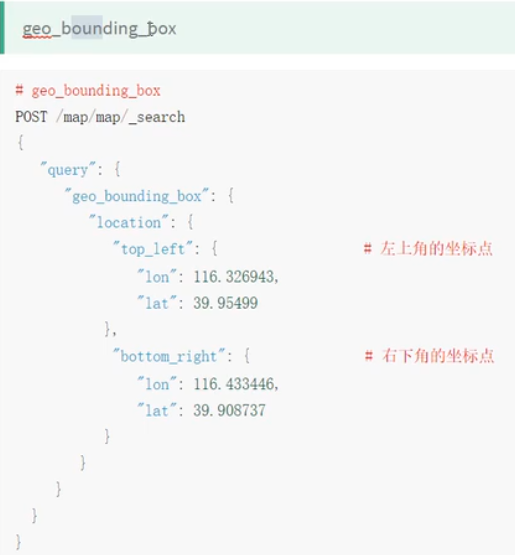
地图经纬度搜索
ES中提供了一个数据类型 geg_point,这个类型就是用来存储经纬度的。创建一个带geg_point类型的索引,并添加测试数据