Kafka:Java开发的消息神器,你真的懂了吗?
一、Kafka 是什么鬼?
想象一下,你在网上疯狂剁手后,满心期待着快递包裹的到来。这时候,快递站就像是 Kafka,而你的包裹就是消息。快递站接收来自不同商家(生产者)的包裹,然后等待你(消费者)去取。Kafka 和快递站类似,它是一个分布式消息系统,负责接收、存储和转发消息,在不同的应用程序之间传递数据。
Kafka 是由 Apache 软件基金会开发的一个开源的分布式流处理平台 ,最初是由 LinkedIn 公司开发,后来捐赠给了 Apache。它的诞生,解决了大数据时代数据传输和处理的难题,就像给数据世界搭建了一条超级高速公路,让数据能够快速、高效地流通。
在大数据的世界里,数据就像汹涌的潮水,源源不断地产生。网站的访问日志、用户的操作记录、传感器采集的数据...... 这些数据需要被收集、传输和处理。Kafka 就像是一个超级数据管道,能够高效地处理海量数据的传输和分发,在大数据处理、日志收集、实时数据处理、消息队列等场景中发挥着重要作用。
二、Kafka 的特性,为啥这么牛?
(一)高吞吐量,海量消息轻松应对
Kafka 的高吞吐量就像是一个超级大胃王,能够轻松吃下海量的消息。它每秒可以处理几十万条消息,这得益于它的分布式架构和独特的设计。比如在电商大促期间,大量的订单消息、用户行为消息如潮水般涌来,Kafka 就像一个不知疲倦的搬运工,能够快速地将这些消息接收并存储起来,为后续的处理提供保障。
Kafka 的生产者在发送消息时,并不是一条一条地发送,而是将多条消息收集起来组成一个批次(batch)一起发送,这样就减少了网络开销,大大提高了发送效率 。就好比你去超市买东西,如果每次只买一件商品,那来回跑的次数就多,效率也低;但如果把需要的东西一次性都买齐,装在一个大袋子里带回去,就能节省很多时间和精力。Kafka 的批量发送就类似这个道理。
另外,Kafka 使用磁盘顺序读写来提升性能 。传统的磁盘随机读写就像是在一个大图书馆里随机找一本书,需要花费很多时间在书架间穿梭寻找;而顺序读写则像是按照书架编号依次取书,速度就快多了。Kafka 的消息是不断追加到本地磁盘文件末尾的,这种顺序写入方式极大地提高了写入吞吐量。再加上 Kafka 使用了页缓存(pageCache),它把尽可能多的空闲内存当作磁盘缓存使用,进一步提高了 I/O 效率。生产者把消息发到 broker 后,数据先进入 PageCache,然后再由内核中的处理线程采用同步或异步的方式定期刷盘至磁盘 。消费者消费消息时,也会先从 PageCache 获取消息,获取不到才会去磁盘读取,并且还会预读出一些相邻的块放入 PageCache,方便下一次读取。如果 Kafka producer 的生产速率与 consumer 的消费速率相差不大,那么几乎只靠对 broker PageCache 的读写就能完成整个生产和消费过程,磁盘访问非常少,这就大大提高了吞吐量。
对比其他消息系统,比如 ActiveMQ,它在处理高并发消息时,吞吐量就远不如 Kafka。ActiveMQ 主要侧重于传统的消息队列应用场景,在设计上没有像 Kafka 那样针对高吞吐量进行优化,所以当面对海量消息时,就容易出现性能瓶颈。而 Kafka 凭借其出色的设计,在高并发场景下表现得游刃有余,成为了大数据处理领域的宠儿。
(二)低延迟,消息传输快如闪电
Kafka 的低延迟特性就像是闪电侠,能够以极快的速度传输消息。它的消息传递延迟极低,通常在毫秒级别,这使得它能够满足实时性要求较高的业务场景,比如股票交易、实时监控等。
Kafka 实现低延迟的原理主要有以下几点:首先,前面提到的顺序读写和页缓存机制不仅提高了吞吐量,也对降低延迟起到了重要作用。因为顺序读写和利用页缓存可以快速地读取和写入消息,减少了 I/O 等待时间 。其次,Kafka 采用了零拷贝技术。在传统的数据传输过程中,数据通常需要在用户空间和内核空间之间多次拷贝,这就像在不同的房间之间来回搬运东西,会消耗大量的时间和精力。而零拷贝技术通过优化数据传输路径,减少了数据在用户空间和内核空间之间的多次拷贝,直接在内核空间完成数据的传输,大大提高了数据传输的速度,降低了延迟。
以股票交易系统为例,股票价格的变化瞬息万变,每一秒的价格波动都可能影响投资者的决策。在这样的场景下,Kafka 可以快速地将股票交易数据从数据源传输到各个交易终端和分析系统,让投资者能够及时获取最新的股票价格信息,做出准确的交易决策。如果消息传输延迟过高,投资者可能会因为无法及时获取价格信息而错过最佳的交易时机,造成经济损失。而 Kafka 的低延迟特性就为股票交易系统提供了可靠的保障,确保了交易的及时性和准确性。
(三)持久化,数据安全有保障
Kafka 就像是一个可靠的保险柜,会将消息持久化到磁盘上,确保数据的安全,即使在系统故障时也能恢复数据。这对于很多对数据可靠性要求极高的场景来说,是非常重要的。
Kafka 将消息存储在分区(Partition)中,每个分区是一个有序的、不可变的消息序列 。分区可以分布在不同的服务器上,实现数据的分布式存储和负载均衡。每个分区都有一个对应的日志文件,消息以追加的方式顺序写入日志文件 。这种顺序写入的方式不仅提高了写入性能,也保证了消息的顺序性。
为了进一步确保数据的可靠性,Kafka 采用了副本机制 。每个分区可以有多个副本,其中一个副本为主副本(Leader),其他副本为从副本(Follower)。主副本负责接收和处理生产者发送的消息,并将消息同步到从副本。从副本会定期从主副本拉取消息,以保持与主副本的同步。如果主副本出现故障,Kafka 会自动从从副本中选举一个新的主副本,保证系统的高可用性和数据不丢失。
例如,在一个电商的订单系统中,订单数据是非常重要的业务数据,不能有任何丢失。Kafka 作为消息队列,将订单消息持久化存储,即使在某个服务器出现硬件故障或者软件异常的情况下,通过副本机制,其他副本服务器上仍然保存着完整的订单消息。当故障恢复后,系统可以从这些副本中恢复数据,保证订单处理的完整性,不会因为系统故障而导致订单丢失或数据不一致的情况发生。
(四)可扩展性,随时应对业务增长
Kafka 的可扩展性就像是一个可以无限拼接的积木城堡,能够随时根据业务的增长进行扩展。它的集群可以通过添加节点实现水平扩展,轻松应对不断增长的业务量。
Kafka 采用分布式架构,由多个 Broker 组成集群 。每个 Broker 负责存储一部分 Topic 的 Partition 数据,并处理来自 Producer 和 Consumer 的请求。当业务量增加,现有的集群处理能力不足时,只需要简单地添加新的 Broker 节点,就可以增加集群的处理能力和存储容量。Kafka 会自动将新的分区分配到新添加的节点上,实现负载均衡。
比如一个短视频平台,随着用户数量的快速增长,每天产生的视频上传、点赞、评论等消息量也呈爆发式增长。如果一开始使用的 Kafka 集群规模较小,当消息量超出集群的处理能力时,就可以通过添加新的 Broker 节点来扩展集群。新添加的节点会自动参与到消息的存储和处理中,与原有的节点一起协同工作,共同应对大量的消息处理需求。这样,短视频平台就可以在不影响用户体验的前提下,轻松应对业务增长带来的挑战,保证系统的稳定运行。
三、Kafka 架构大揭秘
(一)核心组件介绍
1. Producer:消息的源头
Producer 就像是一个勤劳的快递员,负责生产消息并将它们发送到 Kafka 集群中。在实际应用中,Producer 可以是各种产生数据的应用程序,比如电商系统中的订单生成模块,每产生一个新订单,就会作为一条消息由 Producer 发送到 Kafka 集群。
在 Java 中使用 Kafka Producer 发送消息,首先需要引入 Kafka 的客户端依赖。如果使用 Maven 项目,可以在pom.xml文件中添加如下依赖:
typescript
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.1</version>
</dependency>然后编写发送消息的代码:
typescript
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
// Kafka集群地址
String bootstrapServers = "localhost:9092";
// 创建KafkaProducer配置
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// 键的序列化器
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 值的序列化器
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 创建KafkaProducer实例
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 要发送的消息
String topic = "my-topic";
String key = "key1";
String value = "Hello, Kafka!";
// 创建ProducerRecord对象
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
// 发送消息,这里使用异步发送,并添加回调函数处理结果
producer.send(record, (metadata, exception) -> {
if (exception == null) {
System.out.printf("Message sent to topic %s partition %d offset %d%n",
metadata.topic(), metadata.partition(), metadata.offset());
} else {
System.out.println("Failed to send message: " + exception.getMessage());
}
});
// 关闭生产者
producer.close();
}
}在这段代码中,首先配置了 Kafka 集群的地址以及消息键和值的序列化器 。然后创建了KafkaProducer实例,并构建了一个ProducerRecord对象,包含要发送到的主题、消息的键和值。最后使用producer.send方法异步发送消息,并通过回调函数处理消息发送的结果。如果发送成功,会打印出消息发送到的主题、分区和偏移量;如果发送失败,则会打印出错误信息。
2. Consumer:消息的接收者
Consumer 就像是等待收快递的你,从 Kafka 集群中拉取消息进行消费处理。在实际场景中,Consumer 可以是数据分析系统,从 Kafka 集群中获取用户行为数据进行分析;也可以是订单处理系统,获取订单消息进行后续的订单处理流程。
在 Kafka 中,消费者是以消费组(Consumer Group)的形式工作的 。每个消费组会消费一个或多个主题的消息,并且 Kafka 会确保同一个消费组内,来自同一分区的消息只会被组内的一个消费者消费 。这样就实现了负载均衡和高并发处理。比如有一个电商的订单处理系统,有多个订单处理模块作为消费者组成一个消费组,Kafka 会将订单消息分区后,分配给消费组内的不同消费者进行处理,提高订单处理的效率。
下面是使用 Java 实现 Kafka Consumer 的代码示例:
typescript
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerExample {
public static void main(String[] args) {
// Kafka集群地址
String bootstrapServers = "localhost:9092";
// 消费组ID
String groupId = "my-group";
// 创建KafkaConsumer配置
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
// 键的反序列化器
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 值的反序列化器
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 当没有初始偏移量或当前偏移量无效时,从最早的消息开始消费
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 创建KafkaConsumer实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅主题
String topic = "my-topic";
consumer.subscribe(Collections.singletonList(topic));
try {
while (true) {
// 拉取消息,设置超时时间为100毫秒
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Consumed message with key: %s, value: %s, partition: %d, offset: %d%n",
record.key(), record.value(), record.partition(), record.offset());
}
}
} finally {
// 关闭消费者
consumer.close();
}
}
}在这段代码中,首先配置了 Kafka 集群地址、消费组 ID 以及消息键和值的反序列化器 。然后创建了KafkaConsumer实例,并使用consumer.subscribe方法订阅了指定的主题。在一个无限循环中,通过consumer.poll方法拉取消息,设置超时时间为 100 毫秒 。每次拉取到消息后,遍历消息记录并打印出消息的键、值、分区和偏移量。最后在程序结束时关闭消费者。
3. Broker:消息的存储和管理者
Broker 是 Kafka 集群中的服务器,就像是快递站的仓库,负责存储消息、响应生产者和消费者的请求。一个 Kafka 集群通常由多个 Broker 组成,它们共同协作,实现了 Kafka 的分布式特性和高可用性。
每个 Broker 都存储了部分主题的分区数据,并且以日志文件的形式将消息持久化存储在磁盘上 。当生产者发送消息时,Broker 会接收消息并将其追加到相应的分区日志文件中;当消费者请求消息时,Broker 会从对应的分区日志文件中读取消息并返回给消费者。
Broker 之间也会进行通信和协作,比如在副本同步过程中,从副本(Follower)会定期向主副本(Leader)拉取消息,以保持与主副本的同步。如果主副本所在的 Broker 出现故障,Kafka 会通过选举机制从从副本中选出一个新的主副本,确保系统的正常运行和数据的可用性。
例如,在一个分布式的日志收集系统中,多个应用服务器产生的日志消息由 Producer 发送到 Kafka 集群的不同 Broker 上存储。当数据分析系统需要分析这些日志时,作为 Consumer 向 Broker 请求日志消息,Broker 会根据请求返回相应的日志数据。
4. Topic:消息的分类标签
Topic 是消息的逻辑分类,就像是快递站按照不同的收件地址对包裹进行分类一样。每个消息都属于某个 Topic,生产者在发送消息时需要指定消息所属的 Topic,消费者在订阅消息时也需要指定要消费的 Topic。
在实际应用中,不同的业务场景可以使用不同的 Topic 来区分消息。比如在一个电商系统中,可以创建 "order-topic" 用于存储订单相关的消息,"user-behavior-topic" 用于存储用户行为相关的消息。这样可以方便地对不同类型的消息进行管理和处理。
例如,当用户在电商平台上下单时,订单信息会作为一条消息发送到 "order-topic" 中;而用户的浏览商品、添加购物车等行为数据会发送到 "user-behavior-topic" 中。不同的消费者可以根据自己的需求订阅相应的 Topic 进行消息消费。
5. Partition:Topic 的物理分割
Partition 是 Topic 的物理分区,就像是将一个大的快递区域划分成多个小的分区来进行管理。每个 Topic 可以包含多个 Partition,通过分区机制,Kafka 可以实现数据的分片存储和并行处理,从而提高系统的吞吐量和性能。
每个 Partition 是一个有序的、不可变的消息日志,消息按照追加的方式写入 Partition 。并且每个 Partition 都有一个唯一的标识符,称为分区 ID。生产者在发送消息时,可以根据一定的分区策略将消息发送到指定的 Partition 中。比如可以根据消息的键进行哈希计算,然后根据哈希值将消息分配到相应的 Partition,这样可以保证具有相同键的消息总是发送到同一 Partition 中,从而实现分区内消息的顺序性。
消费者在消费消息时,一个消费组内的多个消费者可以分别消费不同的 Partition,实现并行消费。例如,在一个大数据处理场景中,有一个包含大量用户行为数据的 Topic,通过将其划分为多个 Partition,可以让多个消费者同时从不同的 Partition 中消费数据,大大提高数据处理的速度。
6. Replica:数据备份保障
Replica 是 Partition 的副本,就像是给每个快递包裹都准备了备份,用于保证数据的高可用性和容错性。每个 Partition 可以有多个副本,其中一个副本为主副本(Leader),其他副本为从副本(Follower)。
主副本负责处理生产者和消费者的读写请求,从副本则会定期从主副本拉取消息,保持与主副本的同步 。当主副本所在的 Broker 出现故障时,Kafka 会自动从从副本中选举一个新的主副本,确保数据不丢失并且服务不中断。
例如,在一个金融交易系统中,订单数据的可靠性至关重要。Kafka 通过为订单相关的 Partition 设置多个副本,当某个 Broker 出现故障时,其他副本可以迅速接替工作,保证订单数据的完整性和交易的正常进行。
(二)架构图详解
下面是 Kafka 的架构图:
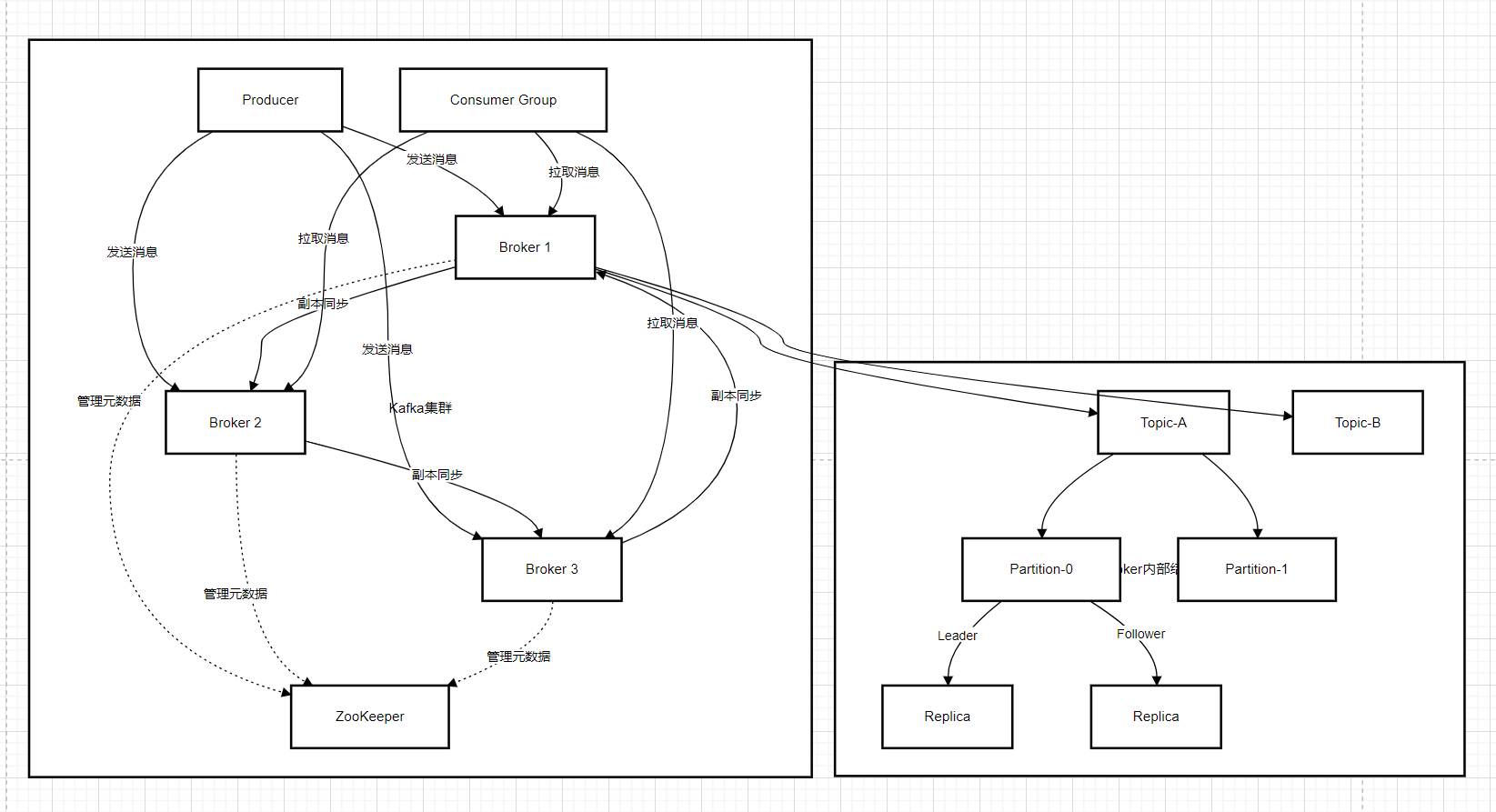
从架构图中可以清晰地看到各个组件之间的交互关系和数据流向:
-
生产者发送消息:Producer 根据配置的分区策略,将消息发送到指定 Topic 的某个 Partition 的 Leader 副本上。例如,一个电商系统的订单生产者,将订单消息发送到 "order-topic" 的某个分区。
-
Broker 存储消息:Broker 接收到消息后,将其追加到对应的 Partition 的日志文件中,并将消息同步给该 Partition 的 Follower 副本。比如,Broker1 接收到 "order-topic" 分区 1 的消息后,存储消息并同步给 Broker2 和 Broker3 上的该分区的 Follower 副本。
-
消费者消费消息:Consumer 向 Kafka 集群发送拉取消息的请求,Kafka 根据消费组的配置和分区分配策略,将消息从相应 Partition 的 Leader 副本返回给 Consumer。例如,一个订单处理系统的消费者,从 "order-topic" 中拉取订单消息进行处理。
-
Zookeeper 协调管理:在传统架构中,Zookeeper 负责管理 Kafka 集群的元信息,如 Broker 列表、Topic 和 Partition 的元数据等 。它还负责选举 Controller(控制节点),Controller 负责管理分区的 Leader 选举等重要工作。虽然 Kafka 正在逐步引入 KRaft 模式来取代 Zookeeper,但在当前很多生产环境中,Zookeeper 仍然发挥着重要作用 。例如,当一个新的 Broker 加入集群时,Zookeeper 会感知到并更新集群的元信息,通知其他组件。
通过这个架构图和上述的交互流程,我们可以直观地理解 Kafka 是如何高效地进行消息的生产、存储和消费,以及如何通过各个组件的协同工作实现分布式、高可用和高性能的特性。
四、Kafka 原理深度剖析
(一)消息生产过程
1. 生产者分区策略
生产者在发送消息时,需要决定将消息发送到 Topic 的哪个 Partition 中,这就涉及到分区策略。Kafka 提供了多种分区策略,每种策略都有其适用场景。
- 随机策略:就像是抽奖一样,随机地将消息分配到各个 Partition 中。这种策略实现简单,但是可能会导致消息分布不均匀,某些 Partition 可能会接收过多的消息,而某些 Partition 则接收较少。例如:
typescript
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Random;
public class RandomPartitioner implements Partitioner {
private final Random random = new Random();
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return random.nextInt(partitions.size());
}
@Override
public void close() {
// 关闭时的操作,这里为空
}
@Override
public void configure(java.util.Map<String, ?> configs) {
// 配置时的操作,这里为空
}
}在这个自定义分区器中,通过Random类生成一个随机数,作为分区的索引,从而实现随机分区。
- 轮询策略:这是 Kafka 的默认分区策略,它就像一个有条不紊的分发员,按照顺序依次将消息分配到各个 Partition 中,保证消息能够均匀地分布在各个 Partition 上,实现负载均衡。例如:
typescript
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
public class RoundRobinPartitioner implements Partitioner {
private final AtomicInteger nextPartition = new AtomicInteger(0);
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
return nextPartition.getAndIncrement() % numPartitions;
}
@Override
public void close() {
// 关闭时的操作,这里为空
}
@Override
public void configure(java.util.Map<String, ?> configs) {
// 配置时的操作,这里为空
}
}在这个轮询分区器中,使用AtomicInteger来记录下一个要使用的分区索引,每次调用partition方法时,通过getAndIncrement方法获取当前索引并自增,然后对分区数量取模,得到要使用的分区索引,从而实现轮询分区。
- 按消息键策略:根据消息的键(Key)来决定分区,具有相同键的消息会被发送到同一个 Partition 中。这种策略可以保证具有相同键的消息在分区内的顺序性,适用于需要保证某些消息顺序处理的场景,比如订单处理,同一个订单的消息需要按顺序处理。例如:
typescript
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
public class KeyHashPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
return Math.abs(key.hashCode()) % numPartitions;
}
@Override
public void close() {
// 关闭时的操作,这里为空
}
@Override
public void configure(java.util.Map<String, ?> configs) {
// 配置时的操作,这里为空
}
}在这个按消息键分区器中,通过对消息键的hashCode取绝对值后对分区数量取模,得到要使用的分区索引,从而保证相同键的消息被发送到同一个分区。
在实际使用中,可以根据业务需求选择合适的分区策略,也可以通过实现Partitioner接口来自定义分区策略。例如,如果业务中需要根据用户 ID 进行分区,保证同一个用户的消息都在同一个分区,可以这样实现:
typescript
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
public class UserIdPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 假设消息的键是用户ID
String userId = (String) key;
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
return Math.abs(userId.hashCode()) % numPartitions;
}
@Override
public void close() {
// 关闭时的操作,这里为空
}
@Override
public void configure(java.util.Map<String, ?> configs) {
// 配置时的操作,这里为空
}
}然后在生产者配置中指定使用这个自定义分区器:
typescript
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 指定自定义分区器
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, UserIdPartitioner.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(props);通过这种方式,就可以根据业务需求灵活地选择和实现分区策略,确保消息在 Kafka 集群中的合理分布和处理。
2. 消息序列化与发送
在 Kafka 中,消息在发送前需要进行序列化,将消息对象转换为字节数组,因为 Kafka 只处理字节数组格式的数据 。序列化的作用主要有两个:一是将消息对象转换为适合在网络中传输和在磁盘上存储的格式;二是可以减少消息的大小,提高传输和存储效率。
Kafka 提供了多种默认的序列化器,如StringSerializer用于将字符串序列化,ByteArraySerializer用于将字节数组序列化等 。在实际应用中,如果默认的序列化器不能满足需求,还可以自定义序列化器。例如,当需要发送自定义的 Java 对象时,就需要自定义序列化器将对象转换为字节数组。
下面是一个自定义序列化器的示例,假设我们有一个User类:
typescript
import java.io.Serializable;
public class User implements Serializable {
private String name;
private int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}然后实现自定义序列化器:
typescript
import org.apache.kafka.common.serialization.Serializer;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.util.Map;
public class UserSerializer implements Serializer<User> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
// 配置方法,这里可以进行一些初始化操作,暂时为空
}
@Override
public byte[] serialize(String topic, User data) {
if (data == null) {
return null;
}
ByteArrayOutputStream bos = new ByteArrayOutputStream();
try (ObjectOutputStream oos = new ObjectOutputStream(bos)) {
oos.writeObject(data);
return bos.toByteArray();
} catch (IOException e) {
throw new RuntimeException("Failed to serialize User object", e);
}
}
@Override
public void close() {
// 关闭方法,这里可以进行一些清理操作,暂时为空
}
}在生产者中使用这个自定义序列化器:
typescript
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 使用自定义的UserSerializer
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, UserSerializer.class.getName());
KafkaProducer<String, User> producer = new KafkaProducer<>(props);
User user = new User("Alice", 25);
ProducerRecord<String, User> record = new ProducerRecord<>("user-topic", user);
producer.send(record);消息序列化完成后,生产者就会将消息发送到 Kafka 集群。在发送过程中,涉及到两个重要的线程:主线程(main 线程)和发送线程(Sender 线程) 。主线程负责创建消息,并将消息添加到一个双端队列RecordAccumulator中 。发送线程不断从RecordAccumulator中拉取消息,然后将消息发送到 Kafka Broker。
生产者在发送消息时,可以选择同步发送或异步发送 。同步发送时,调用send方法会阻塞当前线程,直到消息被成功发送或发送失败,通过调用get方法可以获取发送结果;异步发送时,调用send方法后会立即返回,不会阻塞当前线程,通过传入回调函数可以在消息发送成功或失败时进行相应的处理。例如:
typescript
// 异步发送消息,带回调函数
producer.send(record, (metadata, exception) -> {
if (exception == null) {
System.out.printf("Message sent to topic %s partition %d offset %d%n",
metadata.topic(), metadata.partition(), metadata.offset());
} else {
System.out.println("Failed to send message: " + exception.getMessage());
}
});
// 同步发送消息
try {
producer.send(record).get();
System.out.println("Message sent successfully");
} catch (InterruptedException | ExecutionException e) {
System.out.println("Failed to send message: " + e.getMessage());
}在实际应用中,异步发送通常更常用,因为它可以提高生产者的吞吐量,避免线程阻塞,让主线程可以继续处理其他任务。而同步发送则适用于对消息发送结果有严格要求,需要确保消息成功发送后再进行后续操作的场景。
(二)消息存储机制
1. 日志结构存储
Kafka 采用日志结构存储消息,每个 Topic 由多个 Partition 组成,每个 Partition 对应一个物理日志文件,消息以追加的方式顺序写入日志文件 。这种存储方式就像是一本不断记录新内容的日记,新的消息不断地被添加到日记的末尾。
日志结构存储有很多优点,首先是顺序写入,磁盘的顺序写入速度远远高于随机写入 。传统的随机写入就像是在一本厚厚的字典中随机查找一个字并修改它,需要花费很多时间在翻页查找上;而顺序写入则像是在一张白纸上依次写下新的内容,速度就快多了。Kafka 的顺序写入方式大大提高了写入性能,减少了磁盘寻道时间,能够高效地处理大量的消息写入。
其次,顺序写入也有利于提高读取性能 。消费者在读取消息时,通常也是按照顺序读取的,这样可以充分利用磁盘的顺序读取优势,快速地从日志文件中获取消息。例如,在一个实时监控系统中,大量的监控数据不断地被写入 Kafka,采用日志结构存储,Kafka 可以快速地将这些数据写入磁盘,并且在数据分析系统需要读取这些数据时,也能快速地将数据返回,保证监控数据的实时性和准确性。
另外,Kafka 还使用了稀疏索引来加速消息的查找 。它为每个日志文件创建了一个索引文件,索引文件中记录了消息的偏移量(Offset)和对应的物理位置 。通过索引文件,Kafka 可以快速定位到指定偏移量的消息,而不需要遍历整个日志文件。比如,当消费者需要获取某个特定偏移量的消息时,Kafka 可以通过索引文件快速找到该消息在日志文件中的位置,然后直接读取该位置的消息,大大提高了消息查找的效率。
2. 数据压缩与分段
为了节省存储空间和网络带宽,Kafka 支持对消息进行压缩 。Kafka 提供了多种压缩算法,如 GZIP、Snappy、LZ4 等 ,每种算法都有其特点和适用场景。
-
GZIP:具有较高的压缩比,能够显著减少消息的大小,但是压缩和解压缩的速度相对较慢 。适用于对存储空间要求较高,对压缩和解压缩速度要求不是特别严格的场景,比如日志归档,日志数据量大,对存储空间要求高,而在归档时对速度要求相对较低。
-
Snappy:压缩和解压缩速度非常快,但是压缩比相对较低 。适用于对实时性要求较高,需要快速处理大量消息的场景,比如实时数据处理,在处理大量实时数据时,快速的压缩和解压缩速度可以保证数据的及时处理。
-
LZ4:在压缩比和速度之间取得了较好的平衡,既具有较高的压缩比,又有较快的压缩和解压缩速度 。适用于大多数场景,是一种比较常用的压缩算法。
Kafka 的压缩是在生产者端进行的,生产者将多条消息收集成一个批次(batch),然后对整个批次进行压缩 。压缩后的批次被发送到 Kafka Broker,Broker 直接存储和转发压缩后的数据,不会对数据进行解压 。当消费者消费消息时,会在消费端对压缩的批次进行解压,得到原始的消息。
例如,在一个电商系统中,大量的订单消息需要发送到 Kafka 进行处理。如果不进行压缩,这些订单消息会占用大量的网络带宽和 Kafka Broker 的磁盘空间。通过在生产者端使用 LZ4 压缩算法对订单消息进行压缩,不仅可以减少网络传输的数据量,降低网络带宽的消耗,还可以减少 Kafka Broker 的磁盘占用,提高系统的整体性能。
除了数据压缩,Kafka 还采用了数据分段存储的方式 。每个 Partition 的日志文件会被分成多个段(Segment),每个段包含一定数量的消息 。当一个段的大小达到一定阈值或者经过一定时间后,会创建一个新的段 。每个段都有一个对应的索引文件,用于加速消息的查找。
数据分段存储有很多好处,首先可以方便地管理和维护日志文件 。当一个段的消息不再需要时,可以直接删除该段,而不会影响其他段的消息。其次,分段存储也有利于提高消息的读取性能 。当消费者需要读取某个时间段内的消息时,可以直接定位到对应的段,而不需要读取整个日志文件。例如,在一个长时间运行的物联网数据采集系统中,Kafka 会不断地接收大量的传感器数据。通过数据分段存储,Kafka 可以将不同时间段的传感器数据存储在不同的段中。当数据分析系统需要分析某个特定时间段的传感器数据时,Kafka 可以快速地定位到对应的段,读取该段中的数据,提高数据处理的效率。
Kafka 还会定期清理过期的段,以释放磁盘空间 。清理策略可以根据配置的保留时间或日志大小来决定 。当一个段中的消息超过了保留时间或者日志文件的大小超过了配置的限制时,Kafka 会将该段标记为可删除,然后在适当的时候将其删除 。通过这种方式,Kafka 可以有效地管理磁盘空间,确保系统的稳定运行。
(三)消息消费原理
1. 消费者拉取策略
消费者从 Kafka 集群拉取消息是通过主动轮询(Polling)的方式进行的 。消费者会定期向 Kafka 集群发送拉取请求,Kafka 集群根据请求返回相应的消息。这种拉取方式就像是你定期去快递站询问有没有自己的包裹,而不是在快递站一直等待包裹的到来。
消费者在拉取消息时,有几个重要的参数需要关注:
-
拉取频率:消费者拉取消息的频率可以通过配置参数来控制。如果拉取频率过高,会增加网络开销和 Kafka 集群的负载;如果拉取频率过低,可能会导致消息处理延迟。例如,在一个实时数据分析系统中,如果消费者拉取消息的频率过低,就不能及时获取最新的数据进行分析,影响分析结果的实时性。
-
批量拉取 :消费者可以一次拉取多条消息,而不是一条一条地拉取,这样可以减少网络请求次数,提高拉取效率 。通过设置
fetch.max.bytes参数可以控制每次拉取的最大字节数,设置max.poll.records参数可以控制每次拉取的最大消息数量 。比如,在一个处理大量日志数据的场景中,通过批量拉取可以将多个日志消息一次性拉取回来进行处理,减少网络请求的次数,提高日志处理的效率。 -
偏移量(Offset):偏移量是消息在分区中的唯一标识,用于确定消费者拉取消息的位置 。每个分区都有一个独立的偏移量,消费者通过维护自己的偏移量来记录已经消费的消息位置 。当消费者重启或者加入新的消费者时,会根据偏移量来确定从哪里开始继续消费消息。例如,在一个电商订单处理系统中,消费者在处理订单消息时,会记录下已经处理的订单消息的偏移量。当系统出现故障重启后,消费者可以根据之前记录的偏移
五、Kafka 应用场景大放送
(一)日志收集与处理
在当今的数字化时代,各种服务和应用程序就像勤劳的小蜜蜂,不断地产生着海量的日志数据。这些日志数据记录了系统的运行状态、用户的操作行为等重要信息,对于系统的监控、故障排查和数据分析都有着至关重要的作用 。而 Kafka 就像是一个高效的日志收集大师,能够轻松地收集各种服务的日志,将这些零散的日志数据集中起来,然后以统一接口服务的方式开放给各种消费者 。
以一个大型电商平台为例,它的系统中包含了众多的服务,如用户服务、订单服务、支付服务、物流服务等 。每个服务都会产生大量的日志,这些日志分散在不同的服务器上,如果不进行有效的收集和管理,就会像一团乱麻,难以从中获取有价值的信息 。通过使用 Kafka,各个服务可以将自己产生的日志发送到 Kafka 集群中。比如,订单服务在用户下单、取消订单、支付成功等关键操作时,会生成相应的日志消息,并将这些消息发送到 Kafka 的 "order - log - topic" 主题中;用户服务在用户注册、登录、修改个人信息等操作时,也会将日志消息发送到 Kafka 的 "user - log - topic" 主题中 。
Kafka 集群接收这些日志消息后,会将它们存储起来。此时,Kafka 就像是一个巨大的日志仓库,安全地保存着所有的日志数据 。而后续的处理工作就可以交给各种消费者来完成了。其中一个常见的处理方式是将日志存储到 Hadoop 分布式文件系统(HDFS)中,以便进行离线分析 。Hadoop 具有强大的分布式存储和计算能力,能够处理海量的数据 。通过 Kafka Connect 等工具,可以将 Kafka 中的日志数据源源不断地传输到 HDFS 中 。例如,每天晚上电商平台可以对 HDFS 中的日志数据进行批量处理,分析用户的购买行为、订单趋势等,为业务决策提供数据支持 。
除了离线分析,实时分析也是日志处理的重要需求 。这时候,Kafka 就可以与一些实时分析工具或框架相结合,如 ELK(Elasticsearch - Logstash - Kibana)技术栈 。Logstash 作为一个数据收集引擎,能够从 Kafka 集群中读取日志消息,并对消息进行过滤、转换等操作 。然后,将处理后的日志数据发送到 Elasticsearch 中进行存储和索引 。Elasticsearch 是一个分布式搜索引擎,具有高扩展性和快速的搜索能力,能够快速地对日志数据进行检索和分析 。最后,Kibana 作为一个可视化工具,连接到 Elasticsearch,将日志数据以直观的图表、报表等形式展示出来,方便运维人员和数据分析人员进行实时监控和分析 。例如,通过 Kibana 可以实时查看订单服务的请求量、错误率等指标,一旦发现异常情况,能够及时进行处理 。
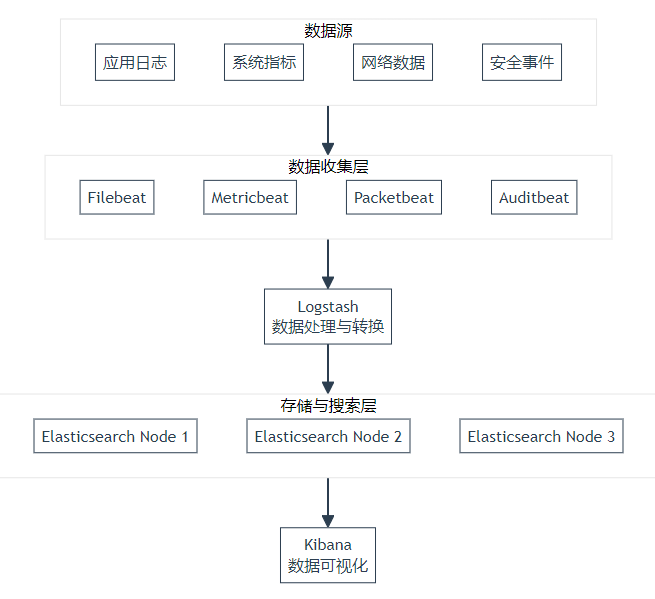
在这个 ELK 架构中,Kafka 扮演着至关重要的角色 。它作为日志数据的中转站,一方面接收来自各个服务的日志消息,保证了日志数据的不丢失和高效传输;另一方面,为 Logstash 提供了稳定的数据源,使得 ELK 能够顺利地进行实时日志分析 。如果没有 Kafka,各个服务直接将日志发送给 Logstash,可能会因为网络波动、Logstash 的负载过高而导致日志丢失或处理不及时 。而 Kafka 的高吞吐量、持久化存储和可扩展性等特性,有效地解决了这些问题,确保了日志收集与处理系统的稳定运行 。
(二)消息队列与解耦
在分布式系统的大家庭中,各个模块就像是独立的个体,它们有着各自的职责和任务,但又需要相互协作来完成整个系统的功能 。然而,直接的模块间调用就像是一根紧紧捆绑的绳子,会导致模块之间的耦合度非常高,牵一发而动全身 。而 Kafka 作为消息队列,就像是一个灵活的信使,能够在模块之间传递消息,实现生产者和消费者的解耦,让各个模块可以独立地发展和演进 。
以一个电商系统中的订单模块和库存模块为例 。在传统的紧密耦合架构下,当用户下单时,订单模块需要直接调用库存模块来检查库存并扣减库存 。这种方式虽然简单直接,但存在很多问题 。比如,如果库存模块出现故障,订单模块也会受到影响,导致用户无法下单;而且,当业务量增加,需要对库存模块进行升级或扩展时,可能会影响到订单模块的正常运行 。
而引入 Kafka 作为消息队列后,情况就大不一样了 。当用户下单时,订单模块会将订单消息发送到 Kafka 的 "order - topic" 主题中,然后就可以继续处理其他任务,而不需要等待库存模块的响应 。库存模块作为消费者,从 "order - topic" 主题中订阅消息,当它接收到订单消息后,再进行库存检查和扣减库存的操作 。这样,订单模块和库存模块之间就实现了异步通信和解耦 。订单模块不需要关心库存模块的具体实现和运行状态,库存模块也可以独立地进行升级和扩展,而不会影响到订单模块 。
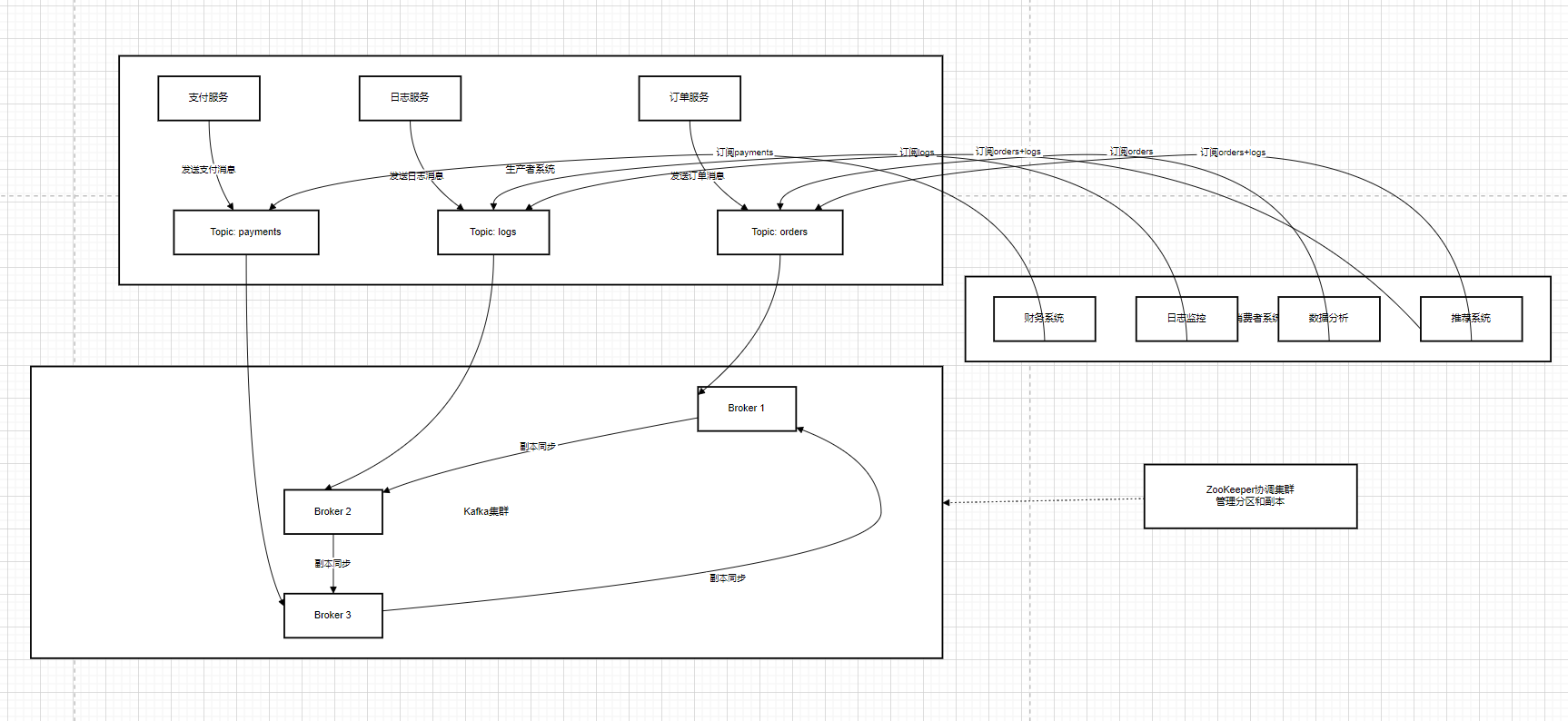
在这个过程中,Kafka 就像是一个缓冲池,它可以缓存订单消息 。当订单模块产生订单消息的速度过快,超过了库存模块的处理能力时,Kafka 可以暂时存储这些消息,避免消息的丢失 。等库存模块有能力处理时,再从 Kafka 中拉取消息进行处理 。这就提高了系统的可靠性和稳定性,使得系统能够更好地应对高并发的业务场景 。
除了订单模块和库存模块,在分布式系统中还有很多其他的模块之间也可以通过 Kafka 进行解耦 。比如,支付模块和订单模块之间,当用户支付成功后,支付模块可以将支付结果消息发送到 Kafka,订单模块从 Kafka 中获取消息,然后更新订单状态 。这样,支付模块和订单模块之间就实现了松耦合,各自可以独立地进行开发、测试和部署 。通过 Kafka 的消息队列和异步通信机制,分布式系统中的各个模块可以更加灵活、高效地协作,提高了系统的可扩展性和稳定性,为业务的发展提供了有力的支持 。
(三)用户活动跟踪
在互联网的世界里,用户就像是舞台上的演员,他们在 Web 或 App 上的每一个动作,如浏览、点击、搜索等,都像是一场精彩的表演 。而 Kafka 就像是一个忠实的记录者,能够将用户的这些活动信息记录下来,为后续的分析和应用提供丰富的数据资源 。
以一个在线购物 App 为例,当用户打开 App 时,就会产生一个 "用户打开 App" 的活动消息;用户浏览商品列表时,会产生 "用户浏览商品" 的消息,消息中可能包含浏览的商品 ID、浏览时间等信息;当用户点击某个商品查看详情时,会生成 "用户点击商品详情" 的消息;如果用户进行搜索操作,还会产生 "用户搜索" 的消息,包含搜索关键词等内容 。这些用户活动消息会被各个服务器收集起来,并发送到 Kafka 的 "user - activity - topic" 主题中 。
Kafka 收集到这些用户活动数据后,就可以发挥其强大的作用了 。首先,通过对这些数据进行实时监控分析,可以了解用户的实时行为 。比如,通过监控 "用户点击商品详情" 的消息数量和频率,可以知道哪些商品受到用户的关注,从而及时调整商品的推荐策略,将热门商品推荐给更多的用户 。再比如,通过分析 "用户搜索" 的关键词,可以了解用户的需求和兴趣点,为商品的优化和推广提供方向 。
其次,利用这些用户活动数据还可以构建用户画像 。用户画像就像是用户在数字世界中的一张全方位照片,通过收集用户的基本信息、行为数据、偏好数据等,对用户进行多维度的刻画 。在构建用户画像的过程中,Kafka 中的用户活动数据起着关键的作用 。例如,通过分析用户浏览和购买的商品类别,可以了解用户的消费偏好;通过分析用户的登录时间和使用频率,可以了解用户的活跃程度和使用习惯 。将这些信息整合起来,就可以构建出一个详细的用户画像,为精准营销、个性化推荐等提供有力的支持 。比如,电商平台可以根据用户画像,向用户推荐他们可能感兴趣的商品,提高用户的购买转化率 。
(四)运营指标监控
在分布式应用的庞大体系中,各种运营指标就像是系统的 "健康指标",反映着系统的运行状态和性能表现 。Kafka 就像是一个高效的 "数据快递员",在收集和传输运营监控数据方面发挥着重要作用,确保这些关键数据能够及时、准确地传递到需要的地方 。
以一个大型分布式电商应用为例,它包含了众多的服务节点,如 Web 服务器、应用服务器、数据库服务器等 。每个服务节点都会产生各种运营指标数据,比如 Web 服务器的 CPU 利用率、内存使用情况、网络流量、请求响应时间等;应用服务器的并发用户数、业务处理吞吐量、错误率等;数据库服务器的磁盘 I/O 读写速率、查询执行时间等 。这些指标数据对于监控系统的性能、发现潜在问题以及进行性能优化都非常重要 。
为了收集这些运营指标数据,通常会在各个服务节点上部署采集器(agent) 。这些采集器就像是一个个小侦探,负责收集所在节点的各种指标数据 。然后,采集器将收集到的指标数据发送到 Kafka 集群中 。比如,Web 服务器上的采集器会定时采集 CPU 利用率和内存使用情况等数据,并将这些数据封装成消息发送到 Kafka 的 "web - server - metrics - topic" 主题中;应用服务器上的采集器会收集并发用户数和业务处理吞吐量等数据,发送到 "app - server - metrics - topic" 主题中 。
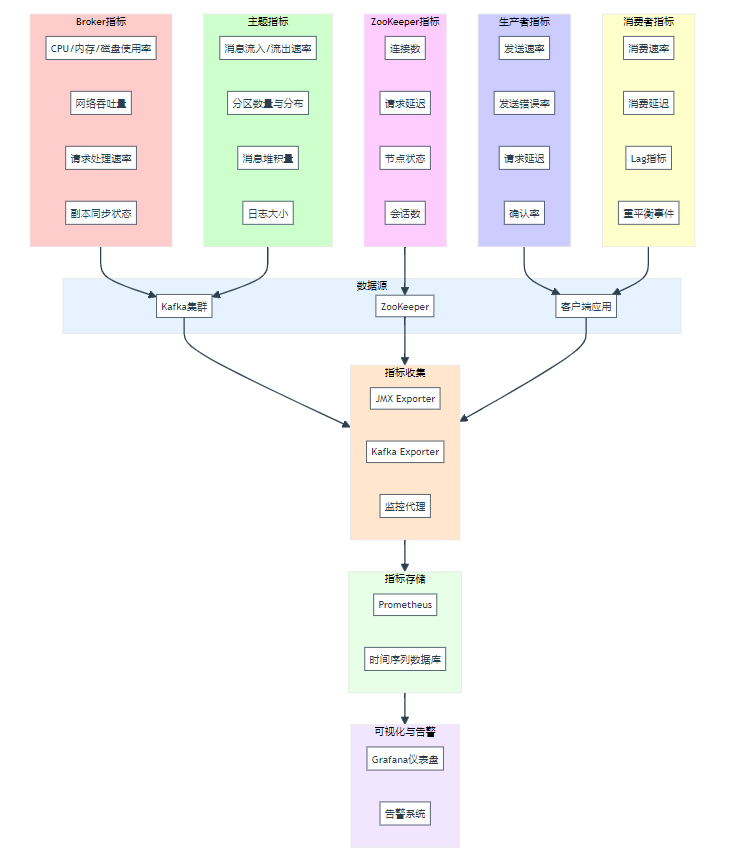
Kafka 集群接收这些指标数据消息后,会将它们存储起来,并等待被消费 。监控系统和报警系统作为消费者,从 Kafka 集群中订阅相应的主题 。监控系统可以实时获取这些指标数据,并以直观的图表、仪表盘等形式展示出来,让运维人员和管理人员能够实时了解系统的运行状态 。例如,通过监控系统可以实时查看各个 Web 服务器的 CPU 利用率曲线,如果发现某个服务器的 CPU 利用率持续过高,可能意味着该服务器负载过重,需要进一步排查原因并进行优化 。
报警系统则会根据预设的阈值对指标数据进行判断 。当某个指标数据超过阈值时,报警系统就会触发报警 。比如,当应用服务器的错误率超过 5% 时,报警系统会立即发送邮件或短信通知相关人员,以便及时采取措施解决问题,避免问题进一步恶化影响系统的正常运行 。通过 Kafka 在运营指标监控中的应用,能够实现对分布式应用的全面、实时监控,及时发现和解决问题,保障系统的稳定、高效运行 。
(五)流式处理
在大数据处理的领域中,实时数据流就像是奔腾不息的河流,源源不断地产生着各种数据 。Kafka 在流处理中扮演着关键的角色,它就像是这条数据河流的 "中转站",为实时数据流的处理和分析提供了强大的支持 。当 Kafka 与 Spark Streaming、Flink 等流处理框架结合时,就像是组成了一个强大的 "数据处理战队",能够对实时数据流进行高效的处理和分析 。
以一个实时电商数据分析的场景为例,用户在电商平台上的各种实时行为数据,如商品浏览、添加购物车、下单、支付等,都会作为实时数据流发送到 Kafka 集群中 。这些数据被发送到 Kafka 的 "ecommerce - stream - topic" 主题中,Kafka 负责接收、存储和转发这些数据,确保数据的不丢失和高效传输 。
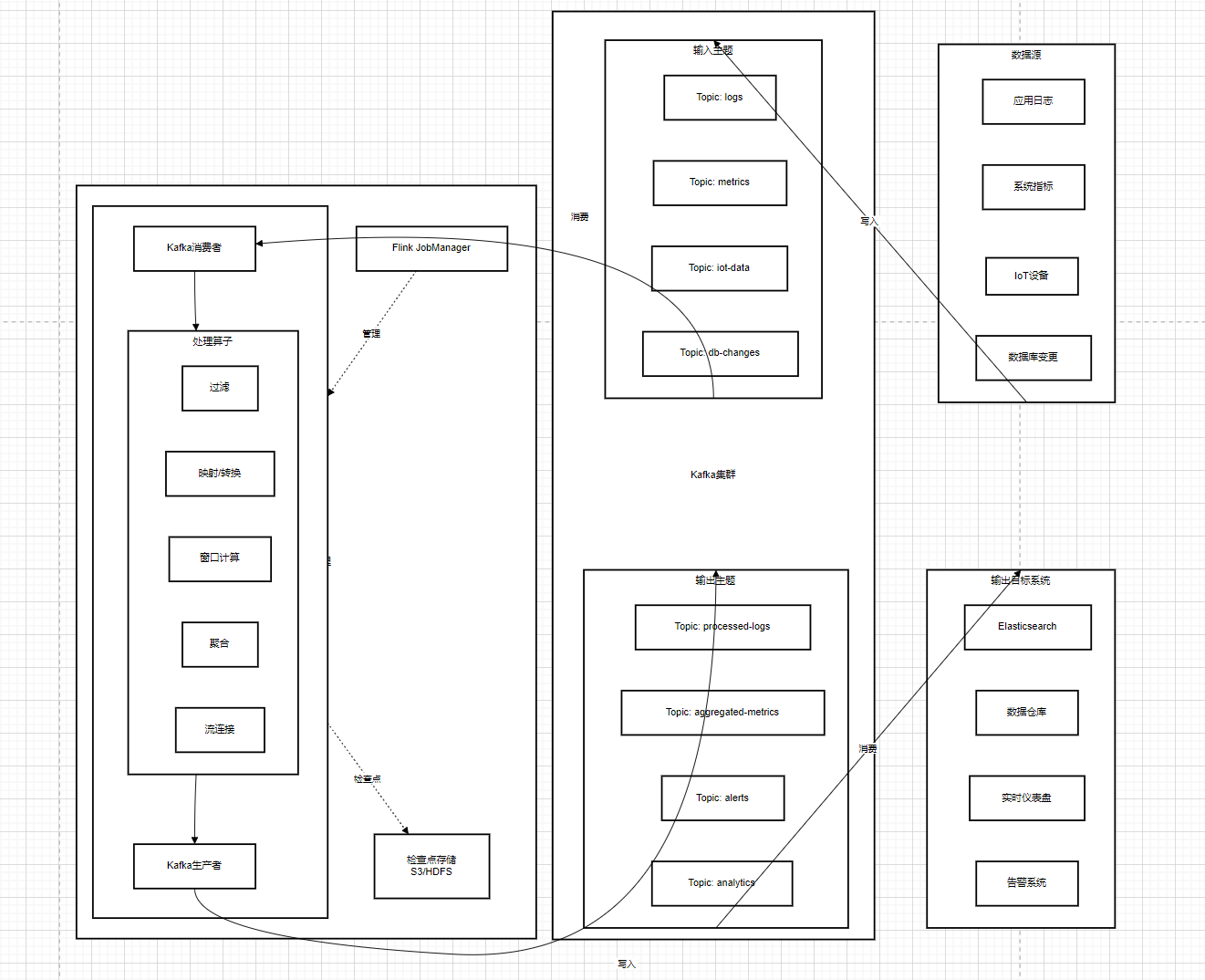
Flink 作为流处理框架,从 Kafka 的 "ecommerce - stream - topic" 主题中读取实时数据流 。Flink 就像是一个智能的 "数据加工工厂",它可以对这些实时数据进行各种复杂的处理和分析操作 。比如,Flink 可以对用户的浏览行为数据进行实时统计,计算出每个商品的浏览量和浏览时长,从而了解用户对不同商品的关注度;通过对添加购物车和下单的数据进行关联分析,可以计算出购物车到订单的转化率,帮助电商平台了解用户的购买意愿和购买行为的转化情况;还可以根据用户的支付数据,实时统计不同支付方式的占比,以及不同时间段的支付金额,为电商平台的运营决策提供实时的数据支持 。
在这个过程中,Kafka 与 Flink 之间的协作非常紧密 。Kafka 为 Flink 提供了稳定的数据源,保证了实时数据流的持续供应 。而 Flink 则充分发挥其强大的流处理能力,对 Kafka 中的数据进行高效的处理和分析 。通过这种结合,电商平台可以实时了解用户的行为和业务的运行情况,及时做出决策和调整 。比如,当发现某个商品的浏览量突然增加,但下单量却很少时,电商平台可以及时调整该商品的推荐策略或进行促销活动,提高用户的购买转化率 。
除了电商场景,在物联网、金融、社交网络等众多领域,Kafka 与流处理框架的结合都有着广泛的应用 。例如,在物联网领域,大量的传感器会实时产生各种数据,如温度、湿度、压力等 。这些数据通过 Kafka 传输到流处理框架中,进行实时的数据分析和处理,实现对设备的实时监控和故障预警 。在金融领域,股票交易数据、银行转账数据等实时数据流通过 Kafka 与流处理框架结合,可以实现实时的风险监控和交易分析 。通过 Kafka 在流处理中的重要作用,能够实现对实时数据流的高效处理和分析,为各个领域的业务发展提供有力的数据支持 。
六、Java 操作 Kafka 实战
(一)环境搭建
在开始使用 Java 操作 Kafka 之前,我们得先把环境搭建好,这就好比盖房子得先把地基打好。下面是详细的搭建步骤:
1. 安装 Java 环境:
Kafka 是基于 Java 开发的,所以首先要确保你的机器上安装了 Java 环境。如果你还没安装,可以从Oracle 官网下载最新的 Java Development Kit(JDK)。下载完成后,按照安装向导的提示进行安装即可。安装完成后,打开命令行,输入java -version,如果能正确显示 Java 的版本信息,那就说明安装成功啦。
2. 下载 Kafka:
你可以从Apache Kafka 官网下载 Kafka 的二进制包。选择适合你操作系统的版本,比如kafka_2.13-3.5.1.tgz(这里的2.13是 Scala 的版本,3.5.1是 Kafka 的版本)。下载完成后,将压缩包解压到你想要安装的目录,比如/usr/local/kafka。
3. 配置 Kafka:
进入 Kafka 的安装目录,找到config文件夹,里面有几个重要的配置文件,我们主要关注server.properties。打开这个文件,你会看到很多配置项,下面是一些常见的配置项及其说明:
-
broker.id:每个 Kafka Broker 在集群中都有一个唯一的 ID,用于标识自己。在单机环境下,默认设置为0即可;如果是集群环境,每个 Broker 的broker.id必须不同。 -
listeners:指定 Kafka Broker 监听的地址和端口,默认是PLAINTEXT://``localhost:9092。如果你想让其他机器也能访问你的 Kafka,需要将localhost改为你的机器 IP 地址。 -
log.dirs:Kafka 存储消息日志的目录。你可以根据自己的磁盘空间和需求,指定一个合适的目录,比如/data/kafka-logs。注意,这个目录必须提前创建好,并且 Kafka 进程对该目录要有读写权限。 -
zookeeper.connect:Kafka 依赖 Zookeeper 来管理集群状态和元数据。这里指定 Zookeeper 的连接地址和端口,格式为host1:port1,host2:port2,...。在单机环境下,如果你的 Zookeeper 也在本地运行,默认是localhost:2181。
配置完成后,保存文件。如果你对其他配置项感兴趣,可以查阅 Kafka 的官方文档,里面有更详细的说明。
4. 启动 Kafka:
在启动 Kafka 之前,需要先启动 Zookeeper。如果你使用的是 Kafka 自带的 Zookeeper,可以在 Kafka 的安装目录下执行以下命令启动 Zookeeper:
typescript
bin/zookeeper-server-start.sh config/zookeeper.propertiesZookeeper 启动后,会在控制台输出一些日志信息。然后,在另一个终端窗口中,执行以下命令启动 Kafka:
typescript
bin/kafka-server-start.sh config/server.propertiesKafka 启动成功后,也会在控制台输出一堆日志信息。如果没有报错,那就说明 Kafka 已经成功启动啦!
5. 添加 Maven 依赖:
如果你使用 Maven 来管理项目依赖,在你的项目pom.xml文件中添加以下依赖:
typescript
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.1</version>
</dependency>这样,Maven 就会自动下载 Kafka 的客户端库及其依赖项。如果你使用 Gradle,对应的依赖配置如下:
typescript
implementation 'org.apache.kafka:kafka-clients:3.5.1'到这里,Java 操作 Kafka 的环境就搭建好啦!是不是感觉也没那么复杂?接下来,我们就可以开始编写代码,体验 Java 与 Kafka 的交互之旅啦!
(二)生产者代码实现
环境搭建好后,我们就可以开始编写 Java 代码,实现 Kafka 生产者啦。生产者的主要职责就是将消息发送到 Kafka 集群中指定的主题(Topic)。下面是一个完整的 Kafka 生产者示例代码:
typescript
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
// Kafka集群地址
String bootstrapServers = "localhost:9092";
// 要发送的主题
String topic = "my-topic";
// 创建Kafka生产者配置
Properties props = new Properties();
// 指定Kafka集群地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// 键的序列化器,将键转换为字节数组,这里使用StringSerializer将字符串类型的键进行序列化
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 值的序列化器,将值转换为字节数组,这里使用StringSerializer将字符串类型的值进行序列化
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 创建Kafka生产者实例
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 发送10条消息
for (int i = 0; i < 10; i++) {
// 消息的键
String key = "key-" + i;
// 消息的值
String value = "message-" + i;
// 创建ProducerRecord对象,包含主题、键和值
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
// 发送消息,这里使用异步发送,并添加回调函数处理结果
producer.send(record, (metadata, exception) -> {
if (exception == null) {
System.out.printf("Message sent to topic %s partition %d offset %d%n",
metadata.topic(), metadata.partition(), metadata.offset());
} else {
System.out.println("Failed to send message: " + exception.getMessage());
}
});
}
// 关闭生产者,释放资源
producer.close();
}
}代码解释:
-
配置生产者属性:
首先创建一个
Properties对象,用于配置 Kafka 生产者的属性。BOOTSTRAP_SERVERS_CONFIG指定了 Kafka 集群的地址,生产者会通过这个地址连接到 Kafka 集群。KEY_SERIALIZER_CLASS_CONFIG和VALUE_SERIALIZER_CLASS_CONFIG分别指定了消息键和值的序列化器。因为 Kafka 在网络中传输的是字节数组,所以需要将消息的键和值进行序列化。这里我们使用StringSerializer,它会将字符串类型的键和值转换为字节数组。 -
创建生产者实例:
使用配置好的属性创建
KafkaProducer实例。这个实例就是我们用来发送消息的工具。 -
发送消息:
在一个循环中,创建
ProducerRecord对象,它包含了要发送到的主题、消息的键和值。然后使用producer.send方法发送消息。这里我们使用的是异步发送方式,send方法会立即返回,不会阻塞当前线程。同时,我们传入了一个回调函数,当消息发送完成后,Kafka 会调用这个回调函数,并将发送结果(metadata)和可能出现的异常(exception)传递给回调函数。如果发送成功,exception为null,我们可以从metadata中获取消息发送到的主题、分区和偏移量;如果发送失败,exception不为null,我们可以打印出错误信息,方便调试。 -
关闭生产者:
在消息发送完成后,调用
producer.close方法关闭生产者,释放相关资源。这一步很重要,否则可能会导致资源泄漏。
运行这段代码后,你会在控制台看到每条消息发送的结果。如果一切正常,你会看到消息被成功发送到指定的主题和分区,并打印出相应的偏移量。如果发送过程中出现错误,也会打印出错误信息,你可以根据错误信息排查问题。
(三)消费者代码实现
有了生产者发送消息,自然就需要消费者来接收和处理消息啦。下面是一个使用 Java 编写的 Kafka 消费者示例代码:
typescript
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerExample {
public static void main(String[] args) {
// Kafka集群地址
String bootstrapServers = "localhost:9092";
// 消费者组ID
String groupId = "my-group";
// 要消费的主题
String topic = "my-topic";
// 创建Kafka消费者配置
Properties props = new Properties();
// 指定Kafka集群地址
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// 指定消费者组ID
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
// 键的反序列化器,将字节数组转换为键,这里使用StringDeserializer将字节数组反序列化为字符串类型的键
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 值的反序列化器,将字节数组转换为值,这里使用StringDeserializer将字节数组反序列化为字符串类型的值
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 当没有初始偏移量或当前偏移量无效时,从最早的消息开始消费
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 创建Kafka消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅主题
consumer.subscribe(Collections.singletonList(topic));
try {
while (true) {
// 拉取消息,设置超时时间为100毫秒
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Consumed message with key: %s, value: %s, partition: %d, offset: %d%n",
record.key(), record.value(), record.partition(), record.offset());
}
}
} finally {
// 关闭消费者,释放资源
consumer.close();
}
}
}代码解释:
-
配置消费者属性:
同样创建一个
Properties对象来配置 Kafka 消费者。BOOTSTRAP_SERVERS_CONFIG指定 Kafka 集群地址,消费者通过这个地址连接到集群。GROUP_ID_CONFIG指定消费者组 ID,同一消费者组内的消费者会共同消费主题的消息,并且 Kafka 会保证同一个分区的消息只会被组内的一个消费者消费,实现负载均衡。KEY_DESERIALIZER_CLASS_CONFIG和VALUE_DESERIALIZER_CLASS_CONFIG分别指定消息键和值的反序列化器,将从 Kafka 接收到的字节数组转换为 Java 对象。AUTO_OFFSET_RESET_CONFIG配置了消费者在没有初始偏移量或当前偏移量无效时的行为,这里设置为earliest,表示从最早的消息开始消费;如果设置为latest,则从最新的消息开始消费。 -
创建消费者实例:
使用配置好的属性创建
KafkaConsumer实例。 -
订阅主题:
使用
consumer.subscribe方法订阅要消费的主题。这里我们订阅了一个名为my-topic的主题。如果要订阅多个主题,可以将主题列表传递给subscribe方法。 -
拉取并处理消息:
在一个无限循环中,使用
consumer.poll方法拉取消息。poll方法会阻塞当前线程,直到有新消息到达或者超时。这里我们设置超时时间为 100 毫秒。每次拉取到消息后,会返回一个ConsumerRecords对象,它包含了多个ConsumerRecord,每个ConsumerRecord代表一条消息。我们遍历这些消息,并打印出消息的键、值、分区和偏移量。 -
关闭消费者:
当程序结束时,调用
consumer.close方法关闭消费者,释放资源。
运行这段代码后,消费者会持续从指定的主题中拉取消息,并在控制台打印出消息的内容。你可以在生产者代码中多发送一些消息,然后观察消费者的输出,看看是否能正确接收和处理消息。
(四)常见问题与解决方案
在使用 Java 操作 Kafka 的过程中,可能会遇到一些问题。下面是一些常见问题及其解决方案:
1. 连接超时:
-
问题描述 :生产者或消费者在连接 Kafka 集群时,出现连接超时错误,提示类似于
org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms.。 -
可能原因:
-
Kafka 集群地址配置错误,比如 IP 地址或端口号错误。
-
Kafka 集群没有正常启动,或者网络连接存在问题。
-
防火墙阻止了生产者或消费者与 Kafka 集群的通信。
-
-
解决方案:
-
检查
bootstrap.servers配置,确保 Kafka 集群地址正确无误。 -
确认 Kafka 集群已经成功启动,并且各个 Broker 之间通信正常。可以通过 Kafka 自带的命令行工具(如
kafka-topics.sh)来检查集群状态。 -
检查防火墙设置,确保生产者和消费者所在的机器能够访问 Kafka 集群的端口(默认是 9092)。如果是在云服务器上,还需要检查安全组规则。
-
2. 消息丢失:
-
问题描述:生产者发送的消息在 Kafka 集群中丢失,消费者无法消费到。
-
可能原因:
-
生产者发送消息时没有正确处理错误,比如在异步发送时,没有在回调函数中处理发送失败的情况。
-
Kafka 的副本同步出现问题,导致消息还未同步到其他副本,主副本就发生了故障,从而消息丢失。
-
生产者设置了不合理的
acks参数。acks参数表示生产者在收到多少个副本的确认后才认为消息发送成功。如果设置为0,生产者不会等待任何确认,消息可能会因为网络问题而丢失;如果设置为1,生产者只等待主副本的确认,当主副本确认后但还未同步到其他副本时主副本故障,消息也可能丢失;只有设置为all或-1,生产者才会等待所有同步副本的确认,这样可以最大程度保证消息不丢失,但会影响性能。
-
-
解决方案:
-
在生产者发送消息时,正确处理回调函数中的错误,确保在发送失败时进行适当的重试或其他处理。
-
确保 Kafka 集群的副本同步正常,可以通过监控工具(如 Kafka Manager)查看副本的同步状态。同时,合理设置
replication.factor(副本因子)和min.insync.replicas(最小同步副本数),保证数据的可靠性。 -
根据业务需求,合理设置生产者的
acks参数。如果对消息可靠性要求极高,建议设置为all或-1,并适当调整retries(重试次数)和retry.backoff.ms(重试间隔时间)参数。
-
3. 重复消费:
-
问题描述:消费者多次消费到同一条消息。
-
可能原因:
-
消费者在消费消息后,没有及时提交偏移量(offset),导致在重新启动或发生再均衡(rebalance)时,从上次未提交的偏移量开始消费,从而重复消费。
-
自动提交偏移量时,提交的时机不当。比如在消息还未处理完成时就提交了偏移量,当消费者重启后,会从已提交的偏移量开始消费,导致之前未处理完的消息被重新消费。
-
-
解决方案:
-
如果使用手动提交偏移量,确保在消息处理完成后再提交偏移量。可以使用
commitSync(同步提交)或commitAsync(异步提交)方法。同步提交会阻塞当前线程,直到提交成功;异步提交不会阻塞线程,但需要注意处理回调函数中的错误。 -
如果使用自动提交偏移量,合理设置
enable.auto.commit(是否开启自动提交)和auto.commit.interval.ms(自动提交间隔时间)参数。确保在消息处理完成后,再进行自动提交,避免消息处理过程中提交偏移量。
-
4. 分区分配不均:
-
问题描述:在消费者组中,各个消费者分配到的分区数量不均衡,导致部分消费者负载过高,部分消费者负载过低。
-
可能原因:
-
消费者组中的消费者数量与主题的分区数量不匹配。比如消费者数量大于分区数量,就会有部分消费者空闲;消费者数量小于分区数量,就会导致部分消费者需要处理多个分区的消息,负载过高。
-
分区分配策略设置不合理。Kafka 提供了多种分区分配策略,如 Range、RoundRobin、Sticky 等,如果策略设置不当,可能会导致分区分配不均。
-
-
解决方案:
-
根据主题的分区数量,合理调整消费者组中的消费者数量,尽量使消费者数量与分区数量保持一致,或者是分区数量的整数倍,以实现负载均衡。
-
根据业务需求,选择合适的分区分配策略。如果希望分区分配更加均匀,可以使用 RoundRobin 策略;如果希望尽量保持之前的分区分配结果,减少不必要的再均衡,可以使用 Sticky 策略。可以通过在消费者配置中设置
partition.assignment.strategy参数来指定分区分配策略。
-
七、总结与展望
在 Java 开发的广阔天地中,Kafka 无疑是一颗耀眼的明星,凭借其卓越的性能和丰富的特性,为开发者们解决了诸多数据传输与处理的难题 。它就像是一位神通广大的超级英雄,在大数据处理、消息队列、日志收集、实时数据处理等多个领域大显身手,成为了分布式系统架构中不可或缺的一部分 。
通过对 Kafka 的深入学习,我们了解到它的高吞吐量、低延迟、持久化存储和可扩展性等特性,这些特性使得 Kafka 能够轻松应对各种复杂的业务场景 。在架构方面,Kafka 的 Producer、Consumer、Broker、Topic、Partition 和 Replica 等核心组件相互协作,构建了一个高效、可靠的分布式消息系统 。从原理上看,消息的生产、存储和消费过程都有着精妙的设计,分区策略、序列化机制、日志结构存储等技术细节,都体现了 Kafka 的强大之处 。
在实际应用中,Kafka 在日志收集与处理、消息队列与解耦、用户活动跟踪、运营指标监控和流式处理等场景中发挥着关键作用 。它就像是一条无形的纽带,将各个业务系统紧密地连接在一起,实现了数据的高效流通和共享 。通过 Java 操作 Kafka 的实战,我们也掌握了如何在项目中实际运用 Kafka,从环境搭建到生产者和消费者的代码实现,再到常见问题的解决,这些实践经验都将为我们今后的开发工作提供有力的支持 。
Kafka 的发展前景一片光明 。随着大数据和分布式系统技术的不断发展,Kafka 也在持续演进 。在流处理能力方面,KSQL 和 Kafka Streams 将不断增强,能够处理更加复杂的流处理任务,为实时数据处理提供更强大的支持 。在云原生支持方面,Kafka 与 Kubernetes 等容器编排工具的集成将更加紧密,使得 Kafka 在云原生环境中的部署和管理更加便捷,能够更好地适应云计算时代的发展需求 。同时,Kafka 在多租户支持、运维和监控工具、存储引擎等方面也将不断优化和改进,以满足企业日益增长的业务需求 。
对于广大 Java 开发者来说,Kafka 是一个值得深入学习和掌握的技术 。它不仅能够提升我们在分布式系统开发方面的能力,还能为我们打开大数据处理的大门,让我们在数据驱动的时代中抢占先机 。希望大家通过本文的学习,对 Kafka 有更深入的了解,并在实际项目中充分发挥 Kafka 的优势,创造出更加高效、可靠的分布式系统 。让我们一起搭乘 Kafka 这趟技术快车,驶向大数据和分布式系统开发的未来!