作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
中间件,我给它的定义就是为了实现某系业务功能依赖的软件,包括如下部分:
Web服务器
代理服务器
ZooKeeper
Kafka
RabbitMQ
Hadoop HDFS(本章节)
前面我们介绍了HDFS的安装,在单机版本里面一共启动了3个java进程:
NameNode,DataNode,SecondaryNameNode,下面我们就来分别介绍这3个进程,今天是SecondaryNameNode** 。**
2NN(Secondary NameNode, Secondary NN)是 Hadoop 分布式文件系统(HDFS)中用于辅助 NameNode 管理元数据的重要组件,虽然名称中带有 "NameNode",但它并非 NameNode 的备用节点,核心功能是减轻 NameNode 的负担并优化元数据管理。以下是关于它的详细介绍:
基本概念与核心作用
在 HDFS 中,NameNode 负责存储和管理整个文件系统的元数据(如文件目录结构、文件与数据块的映射关系等),这些元数据的变更会被记录在编辑日志(EditLog) 中,而FsImage 则是元数据的快照(包含某一时刻的完整元数据)。随着集群运行,EditLog 会不断增长,若长期不处理,会导致 NameNode 启动时加载和合并 EditLog 的时间过长,影响系统效率。
2NN 的核心作用是定期合并 EditLog 和 FsImage,生成新的 FsImage 并回传给 NameNode,从而减少 EditLog 的体积,减轻 NameNode 的压力,同时为元数据提供一定的备份能力。
简单来说:NameNode 在运行期间只会写 EditLog,而不会主动将 EditLog 和 FsImage 合并成新的 FsImage。这个合并过程(Checkpoint)需要依赖外部组件完成,比如单机部署下的 SecondaryNameNode。
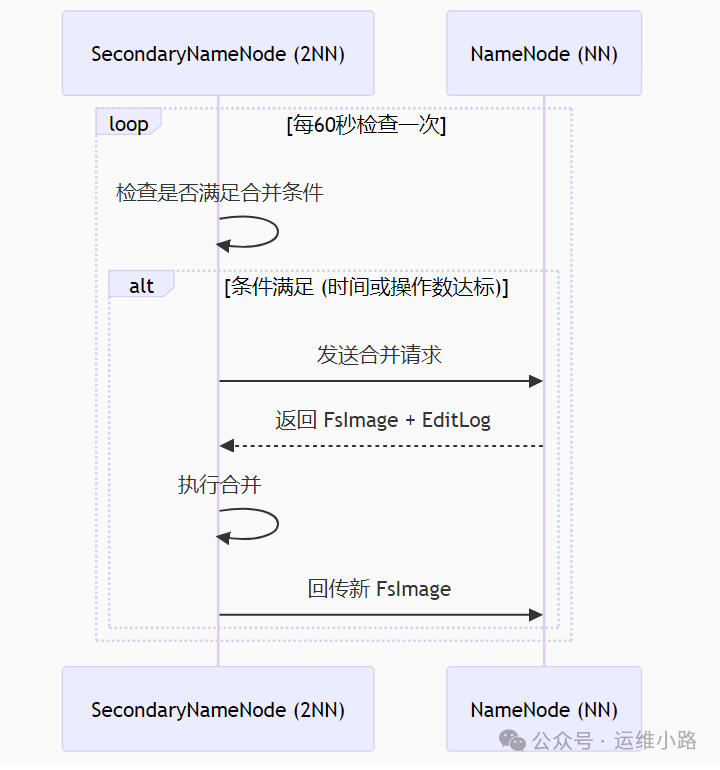
工作机制(合并流程)
2NN 的工作流程主要围绕 "EditLog 与 FsImage 的合并" 展开,具体步骤如下:
请求元数据 :2NN 定期(可通过配置参数 dfs.namenode.checkpoint.period 设定,默认 1 小时)向 NameNode 发送合并请求,NameNode 收到请求后,会暂停向当前 EditLog 写入新的变更,转而创建一个新的 EditLog 文件(如 edits_new),后续的元数据变更会写入这个新文件。
获取元数据文件:NameNode 将当前的 FsImage 和未合并的 EditLog 发送给 2NN。
合并操作 :2NN 将 FsImage 加载到内存,然后逐条执行 EditLog 中的变更操作,生成一个新的 FsImage(fsimage.ckpt)。这个过程相当于将 EditLog 中的增量变更 "固化" 到 FsImage 中,使新的 FsImage 包含最新的元数据状态。
回传新 FsImage :2NN 将合并后的新 FsImage 发送回 NameNode,NameNode 接收后会用它替换旧的 FsImage,并将之前创建的 edits_new 重命名为正式的 EditLog 文件,至此完成一次合并。
通过这一过程,EditLog 会被定期 "清空"(合并到 FsImage 中),避免其无限增长,同时 NameNode 无需自己执行合并操作,节省了计算资源。
同 NameNode 的关系
- 依赖关系:2NN 依赖 NameNode 提供的 FsImage 和 EditLog,自身不参与元数据的实时管理,也不处理客户端请求(所有客户端请求均由 NameNode 处理)。
- 数据同步限制:2NN 仅定期合并元数据,因此它存储的元数据是 "准实时" 的(取决于合并周期),并非与 NameNode 完全同步。
- 非高可用角色:2NN 不能在 NameNode 故障时直接接管其工作(这是 Standby NameNode 的功能)。若 NameNode 故障且未配置高可用(HA),即使有 2NN,也需要手动恢复元数据(从 2NN 拷贝 FsImage 和 EditLog),且可能丢失最后一次合并后的元数据变更。